📌 데이터란?
수, 단어, 이미지, 영상 등의 형태로 된 의미 단위를 일컫습니다.
📌 데이터베이스란?
컴퓨터 시스템에 저장된 정보나 데이터를 모두 모아 놓은 집합을 의미합니다.
데이터는 DBMS(Database Management System)으로 제어하고 관리합니다.
MySQL, Oracle, Access 등이 DBMS의 종류입니다.
즉, 데이터가 저장된 하드에어를 부르는 말이기도 하면서, 데이터베이스를 관리하는 시스템 자체를 통칭합니다.
📌 데이터베이스를 사용하는 이유
-
데이터를 오래 저장하고 보존할 수 있습니다.
→ 메모리에 저장할 경우 데이터를 오래 보존할 수 없습니다. -
데이터를 체계적으로 보존하고 관리할 수 있습니다.
→ 원하는 자료를 쉽게 읽어낼 수 있어야 의미있는 정보라고 할 수 있습니다.
📌 관계형 데이터 베이스 (RDBMS)
Relational Database Management System으로 관계형 데이터 모델에 기초를 둔 데이터베이스 시스템을 가리킵니다.
관계형 데이터란 데이터가 서로 상호 관련성을 가진 형태로 표현한 데이터를 의미합니다.
- 모든 데이터를 2차원 테이블로 표현할 수 있습니다. (엑셀과 같은 형태)
-
columns
데이터를 구분하는 항목입니다.
데이터베이스의 구조가 되는 부분으로 설계를 가장 먼저 해야되는 부분입니다. -
rows
데이터의 실질적인 값을 가리킵니다.
primary key고유 키를 갖고 있으며 이 값을 갖고 특정 데이터를 참조하고 찾을 수 있습니다.
- 각각의 테이블은 서로 상호 관련성을 가지고 연결될 수 있습니다.
- 관계 유형
- 일대일 관계 : 주민등록번호,, 중복이 없어 테이블을 합쳐도 상관없는 관계
- 일대다 관계 : 게시글 <> 유저,,
- 다대다 관계 : 영화 <> 영화배우,, 양쪽으로 일대다 관계인 경우
정규화
중복되는 셀 값을 분리하여 테이블을 작성합니다.
row에는 하나의 값만 들어갈 수 있기 때문에 2개 이상의 값이 들어가는 경우 정규화 단계를 거칩니다.
✅ 정규화 (Normalization)
테이블 간의 중복된 데이터를 허용하지 않겠다
제 1정규화
Atomic Columns 하나의 고유한 값만 가져야합니다.
즉 한개의 column에는 하나의 row 데이터만 있어야 합니다.
여러 데이터가 있다면, 테이블의 row 수를 늘리면서 데이터의 중복을 제거해야주어야 합니다.
제 2정규화
No Partial Dependencies 부분 종속성이 없어야 합니다.
테이블에서는 prime key를 제외한 column 항목은 key와 관련이 있어야 한다는 의미입니다.
관련이 없는 항목이 있다면 다시 테이블을 소분해 줄 방법을 찾아봐야겠습니다.
제 3정규화
No Transitive Dependencies 이행 종속성이 없어야 합니다.
이행 종속성이란? A → B이고 B → C 일 때 A → C 인 경우를 가리킵니다.
테이블을 소분해주었는데도, 테이블 내에 위의 관계가 눈에 들어오시나요?
그렇다면 또 다시 테이블을 분리해줍시다.
우선, A → B인 테이블_1을 하나 만들어줍니다.
그 다음 B → C인 테이블_2을 또 하나 만들어줍니다.
여기서 테이블_1의 B를 foreign key로 설정하여 테이블_2에서 참조할 수 있게 해줍니다.
✅ 실습 - Starbucks Modelling
스타벅스 코리아 음료페이지 모델링 실습입니다.
구현 사항은 다음과 같습니다.
음료 카테고리 영양 정보 알러지 음료 이미지 음료 설명 신상 여부
1. 관계 설정
- 카테고리 ↔ 음료 (일대다 관계)
- 음료 ↔ 음료 이미지 (일대일 관계)
- 음료 ↔ 음료 설명 (일대일 관계)
- 음료 ↔ 신상 여부 (일대일 관계)
- 음료 ↔ 영양 정보 (일대다 관계)
- 음료 ↔ 알러지 (다대다 관계)
2. 테이블 구현하기
모든 테이블의 prime key는 id입니다.
- 카테고리:
Category{ id, category_item } - 음료:
Bevarages{id, beverage_name, beverage_seasonal, beverage_new } - 음료 이미지:
Image{ id, img_url } - 음료 설명 :
Desc{ id, desc } - 영양 정보:
Nutrition{id, sugar, kcal, protein, caffeine, Na, saturated_fat} - 알러지 :
Allergy{id, allergy_item } - 음료-알러지 :
Beverage_Allergy{id, allergy_id, beverage_id }
3. Diagram
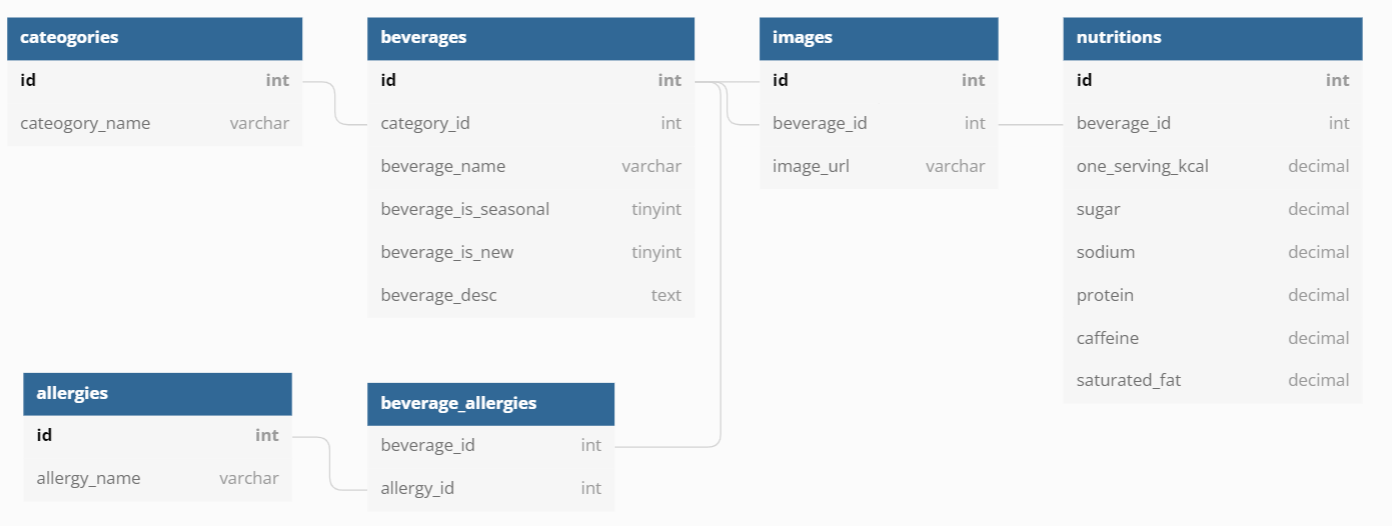
ERD는 백엔드의 청사진이라고 할 수 있습니다.
다른 개발자가 내 코드를 보고 이해할 수 있게 쓴 코드가 좋은 코드라고 하죠?
ERD 역시 마찬가지입니다.
테이블을 설정하면서 여러 규칙이 있는데요, 우선 세가지만 알아보겠습니다:
1) table명 (class명)은 복수형으로 작성합니다.
2) 다대다 관계에 있는 테이블 사이의 중간테이블은 camelCase 혹은 snake_case로 맞추어 줍니다.
3) field 명을 보고 어떤 데이터를 가리킬 수 있는지 정보를 담고 있어야 합니다.
4. 보완사항 (2022-05-31 이후~ )
정규화 사진 설명 추가하기
시작부터 어떻게 모델링을 할 것인가?
일대일 관계 내의 column에서 긴 문자열을 갖는 항목에 대한 분리 필요성?
다대다 관계의 정규화에 대한 이해
