Chain-of-Experts: When LLMs Meet Complex Operations Research Problems (ICLR 2024)
Paper Review
목록 보기
34/51

Introduction
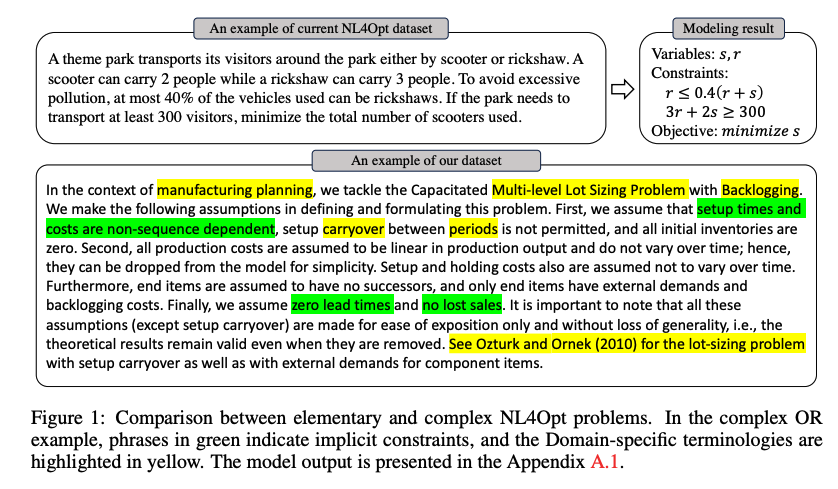
- Complex decision-making problem인 OR
- NL4Opt는 text OR problem을 input, math formulation을 output으로 받는 dataset, but challenging
- 본 논문에서는 real-world industrial demand에 맞는 complex OR problem을 해결하고자 함
- figure와 같이 기존 데이터 셋은 풀이에 필요한 정보가 함축되어 있어, LLM이 한번에 solving하기에 어려움
- 또한 domain specific knowledge를 알아야 풀 수 있는 경우도 다수
- 본 논문에서는 multiple LLM agents를 통해 ochestrating하여 complex OR problem을 풀고자 함
Comparison with other LLM-based reasoning
- CoT, SC, ReAct등 다양한 prompting schemes를 통해 LLM에 접근하는 시도는 물론 유효함
- 다만 single-agent LLM에 경우, complex OR problem에서는 큰 효과를 발휘하지 못함
- 한 LLM으로 implicit constraints, external knowledge prerequisites, long reasoning chain 등의 multiple challenge를 동시에 tackle할 수 없음
- 우리의 CoE (Chain-of-Experts)는 multi-expert collaboration을 통해 single LLM-based approach에 비해 더 효과적임을 실험을 통해 보임
Contribution
- NL4Opt를 더 challenging한 level로 학습하여, model이 함축적인 정보를 파악하게 만듬
- complex OR problem에 대한 첫 번째 LLM-based approach
- Multi-agent framework CoE를 통해 정교한 problem solving을 가능케 함
- 새로운 OR 데이터셋인 ComplexOR을 개발 및 실험을 통해 CoE가 LLM-based 8 approach를 능가함을 보여줌
Related Work
NL4Opt Problems
- NL4Opt는 OR problem description을 수학 공식으로 변환하는데 집중함
- 이전 연구에서는 중간 representation을 거치는 Bard-based model, correction에 집중하는 Edit-based model의 two-stage framework를 채택하였음
- 이후 text generator를 ensemble, rule-based processing prompt guided generation 등의 방법론이 등장
Proposed Method
Expert Design
- 우리의 reasoning framework에서 expert는 specialized agent based on LLM
- 각 expert는 할당된 역할에 따라 일련의 4개 step을 밟음
Step 1: In-context Learning
- Top-K retrieval을 통해 LLM의 in-context learning을 facilitate
- 이 step은 optional하기에, knowledge base가 필요하지 않은 task에서는 제외됨
Step 2: Reasoning
- CoT, SC 등을 이용해 specific role에 따르는 reasoning task를 진행
Step 3: Summarize
- LLM의 token limitation을 고려하여 summarization
- 이 step에서의 정보 손실은 유의미하기에, certain expert에서는 진행하지 않음
Step 4: Comment
- Solo Performance Prompting에 영감을 받아, 각 agent가 comment를 남기고 자세한 suggestion을 남김
- 각 agent의 communication을 가능케하고 건설적으로 만듬
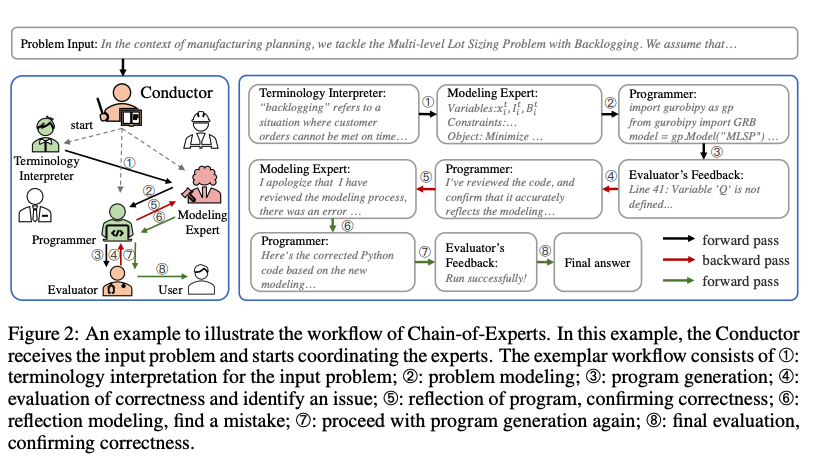
The Workflow of Chain-Of-Experts
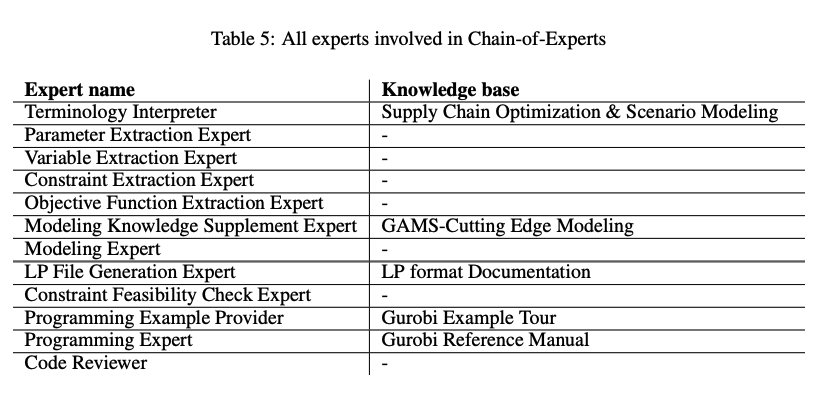
- 다음 11개의 expert를 initialize
- 이 expert를 효과적으로 coordinate하기 위한 conductor가 존재하여, iterative하고 dynamic하게 expert를 선정한 뒤 forward thought chain을 진행
- 이후 backward reflection procedure를 진행하여 feedback signal을 보냄
Forward Thought Construction
- : problem description
- : ith Expert
- : t-th reasoning step의 comment들의 집합
- 기존 강화학습에서는 다량의 데이터셋이 필요하지만, LLM을 통해 training-free approach
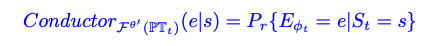
- Conductor의 policy를 만들어, t-step에 필요한 expert를 선정 및 prompt template를 제시함

- optimal policy를 위해 prompt engineering을 한 뒤, comment set을 다음과 같은 reasoning step을 통해 update
- 이후 이전 comments 와 c를 concat하여 을 obtain
- 고정된 step 이후에 모든 CoE framework는 종료되고, 모든 comment가 summarize되어서 final answer 를 생성
Backward Reflection
- backward reflection mechanism은 CoE가 external feedback을 이용해 collaboration을 조정가능케 함
- problem execution environment를 통해 boolean value 와 summary of feedback 가 생성되고, 가 true일 경우 iterative하게 last expert부터 backpropagate가 진행
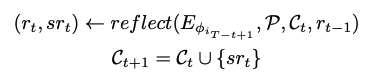
- Expert의 mistake가 없거나, all experts가 reflected됬을 경우 backward reflection을 종료
- 이후 순차적으로 forward process가 진행됨
- Reflexion과 다른 점은, 우리의 모델은 system level에서 multiple expert와 recursive하게 진행됨 (Reflexion은 single LLM)
Implementation Details
- Algorithm

Initialization (lines 1-2)
- set of comments 를 initialize
- stack 는 selected expert를 store하여 forward, backward path를 보증해줌
Forward Thought Construction (lines 4-9)
- Conductor에 의해 순차적으로 Expert 선정
- 각 Expert는 그들의 comment를 global comment set에 저장
- Fixed Step N까지 진행 됨
- line 10에 보이는 것과 같이, 한 forward construction이 완료되면 reducer가 all comment를 summarize하여 final answer를 generate
- comment set은 numerous한 정보를 함축하고 있기에, 이를 함축하는 reducer는 매우 중요한 역할
Backward Reflection (lines 11-20)
- solution이 획득되면, evaluator가 feedback을 받아 자연어로 convert하여 평가
- expert는 reverse order로 iterate하게 자문을 받아 틀린 comment를 stack에서 제거
- backward process는 self-reflection으로 mistake가 발견될 때 까지, 혹은 first expert에 도달할 때 까지 진행
Iterative Improvement (loop in line 3)
- satisfactory solution이 달성될 때 까지, maximum number of trial 까지 forward, backward가 진행 됨
Experiments
Dataset
LPWP
- NL4Opt의 LP problem
- problem description, parameter, variables, linear constraints, objective function으로 구성
ComplexOR
- 3명의 OR 전문가의 도움을 받아 만든 데이터셋
- 37가지 diversified source로 problem을 구성
Model Setup and Performance Metrics
- GPT-3.5-turbo 사용
- temperature를 0.7로 한 뒤, five trial의 average를 metric으로 사용
- LLM이 manual하게 정답을 평가하는 것을 불가능함으로, automate code evaluation process를 사용
- 정확도를 위해 accuracy, 엄격한 metric으로 compile error rate, error를 만나거나 unsolvable model 혹은 non-linear contstraints에 대응하기 위한 runtime error rate 총 3가지의 metric 사용
Baselines
- NIPS competition 1st place인 tag-BART와 CoT, Progressive Hint, Tree-of-Thought, Graph-of-Thought, ReAct, Reflexion, Solo Performance Prompting을 사용
Overall Performance on LPWP and Complex OR
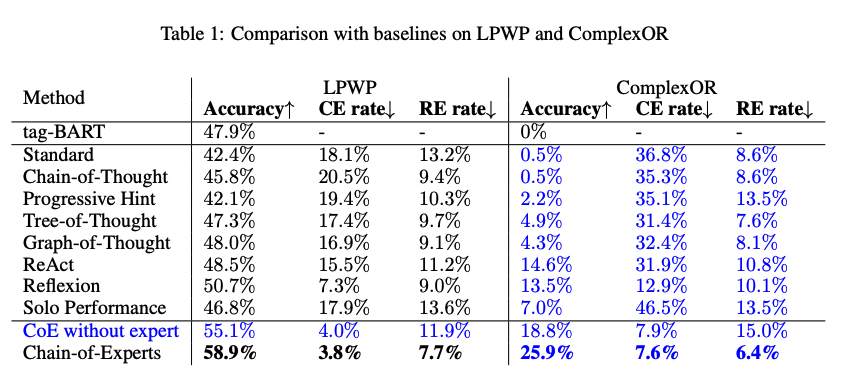
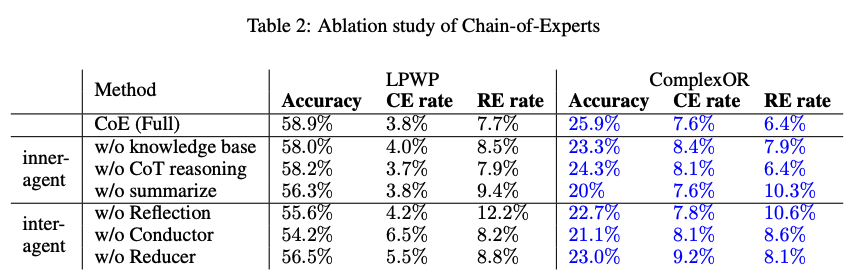
Ablation Study
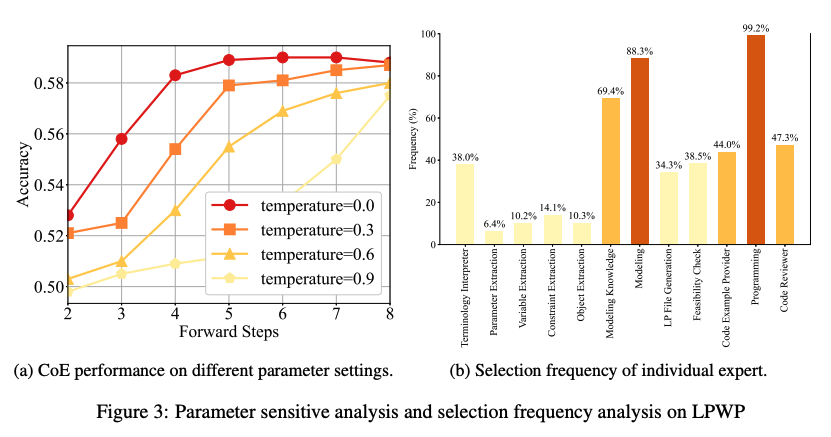
Parameter Sensitivity Analysis
Other LLMs as Base Reasoning Model
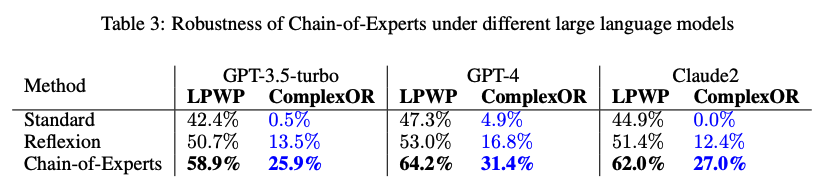
Experimental Analysis of Expert Selection Frequency
- Conductor의 expert 선정으로 합리성과 설명 가능성을 확인 가능
- LPWP dataset에서는, Programming Expert와 Modeling Expert가 가장 빈번한 expert로 선정됨
- 이는 OR problem을 해결하는데 modeling과 programming을 이해하는 것이 가장 중요하다는 것
- 가장 적게 선정된 expert는 parameter, variable, constraints, objective function extrctor로 이는 LLM이 충분히 problem을 이해한다는 반증
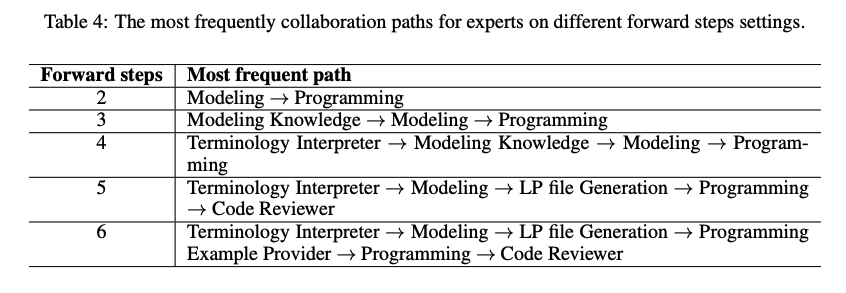
- 더 나아가, 빈번한 collaboration path를 통해 어떤 expert들이 긴밀히 협력하는지 확인할 수 있음
- 특히 forward path가 6인 경우, collaboration path는 real world workflow와 유사함을 확인할 수 있음
Conclusion
- CoE - conductor orchestrating a group of LLM-based expert via forward thought construction and backward reflection mechanism
- New dataset ComplexOR !
