Pix2Struct: Screenshot Parsing as Pretraining for Visual Language Understanding (ICML 2023)
Paper Review
목록 보기
23/51

Pix2Struct: pretrained image-to-text model
Introduction
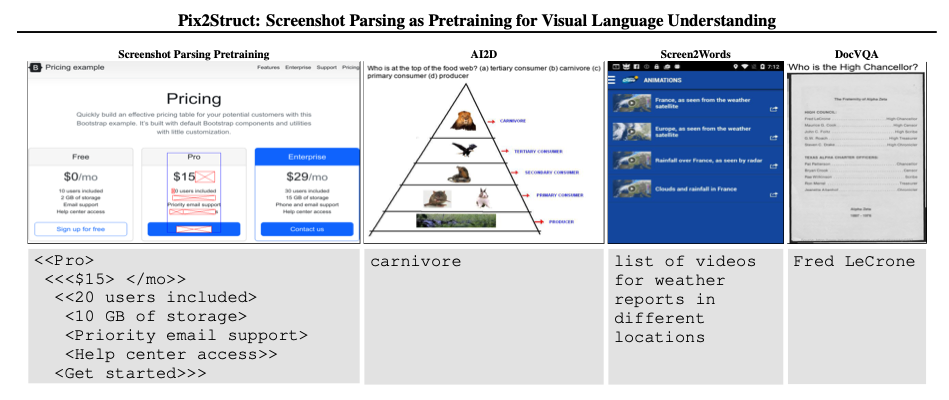
- 이전 연구에서 Image와 text는 different channel로 분리
- visually-situated-language은 두 modal이 퍼져있고, 상호작용 함
- 이전 연구들은 모두 scattered (task specific한 방법론)
- 이는 general 하게 적용할 수 없음
- OCR과 같은 외부 시스템을 이용할 시에는 complexity, limit adaptability 등 여러 문제가 존재
- Pix2Struct는 단순히 pixel input을 html-based parse output으로 학습
- 이를 통해 text, images, layout를 골고루 학습
- ViT를 통해 왜곡을 예방 (human reader를 위해)
- fine-tuning시에 VQA, Bounding Box 등 다른 input을 학습
- modality combination problem을 해결
- Summary
- Introduce General-purpose Visually situated language understaning
- Propose screenshot parsing pretraining objective based on HTML source of web pages
- Introduce varuable-resolution input representation to ViT
Method
Background
- 우리는 single pretrained model을 fine-tuning해 wider variety of task와 domain에 적용시키려 함
- Input은 raw pixel이며, output은 text in the form of token sequences (Donut과 유사)
- Visual 계에서의 T5 모델을 생성하고자 함
- Large unsupervised pretraining을 통해 power를 챙김
- pixel-only langauge model의 시도는 매우 적음
- 최적화의 어려움
- 무거운 text input을 위해서는 고해상도 이미지 처리가 요구됨
Architecture
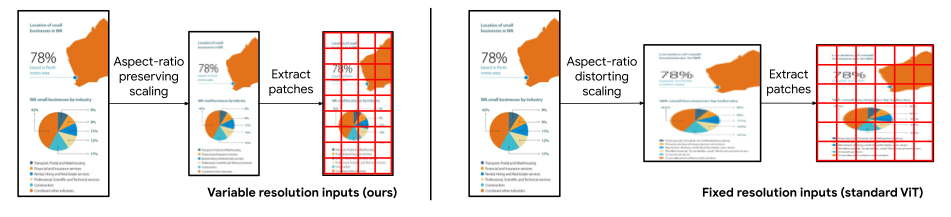
- image encoder text decoder based on ViT
- 기존 연구와 유사하지만 robust to various forms를 충족시키기 위해 input representation을 change 함
- 기존 ViT는 patch representation 추출 전 predefined 해상도로 extracting을 진행
- 이는 두 가지 undesirable effect를 가져옴
- 실제 비율을 왜곡시킴
- 고 해상도에서의 downstream task에서 잘 작동하지 않음 (익숙하지 않기에)
- 이는 두 가지 undesirable effect를 가져옴
- 우리는 up or down으로만 scaling하여 maximul number of patch를 추출
- 또한 2 차원의 positional embedding을 통해 해상도 변화에 따른 모호함을 해결하려 함
- 이에따라 가로 세로 ratio에 robust
- 해상도, sequence length에 따른 change에 robust
Pretraining
- pretraining의 목표는 underlying structure를 잘 represent 하는 것
- input image와 target text의 self-supervised pair가 필요
- HTML과 screenshot을 같이 수집
Screenshot parsing inputs & outputs
- 스크린샷과 HTML은 pretraining 과정에서 dense learning signal을 위해 modified
- 이 수정은 의미론적 정보의 보존과 decoder sequence length 사이의 합리적 trade-off
- HTML DOM tree를 응축함
- visible elements를 보유하거나, 그의 자손 노드만 남김
- 노드가 visible element가 없고, single child를 보유할 때 singleton child with any grandchildren으로 변경
- 각 노드에선, filename과 대체 text로 표현되는 정보만을 남김
- predefined sequence length에 따라 선형화된 subtree로 부터 decoder sequence length를 결정
- Bounding Box는 스크린샷에서 chosen된 subtree를 보여줌
- Better context modeling을 위해 BART-like를 채용
- 50%를 masking
Comparison to existing pretraining strategies

- 우리의 screenshot parsing은 pretraining siganl을 연결
- parse의 unmasking 복원은 OCR과 유사
- 위 figure에서 <C++>을 예측하는 것
- masked parts를 복원하는 것은 masked language model과 유사 (BERT)
- 위 figure에서 ,를 예측하는 것
- image의 alter text를 복원하는 것은 image captioning과 유사
- 위 figure에서 img_alt=C++를 예측하는 것
- parse의 unmasking 복원은 OCR과 유사
Warming up with a reading curriculum

- Direct하게 row pixel image를 text로 변환하려면 instable and slow learning
- warmup stage를 가진다면 이를 해결!
- random color, font의 text를 단순히 decoding
Finetuning
- Text에서의 T5처럼 raw image input을 잘 반영하기 위한 fine tuning
- Captioning은 가장 straightforward, 우리는 Bounding box 내부를 captioning 하는 것에 집중
- VQA에서 multi-modal model은 질문을 text channel에서 수신
- 우리는 HTML header에 이를 삽입
- visual modal을 통해 image와 text를 jointly하게 파악
- 이 전략은 단순히 모든 input을 concat하는 strategy로 GPT 등 NLP Task에서 자주 사용됨
- Image에서 또한 long-range에 효과적으로 대응할 수 있게 해줌
- Multiple choice에 경우 header에 모든 답변을 삽입
- RefExp는 가장 복잡한 시나리오
- Natural Language가 가리키는 UI Component를 찾는 것
- 우리는 여러개의 candidate를 choosing 후, True와 false로 labeling하여 이를 training
- 추론 시에는 가장 true일 확률이 높은 candidate를 채택
Experimental Setup
Benchmarks
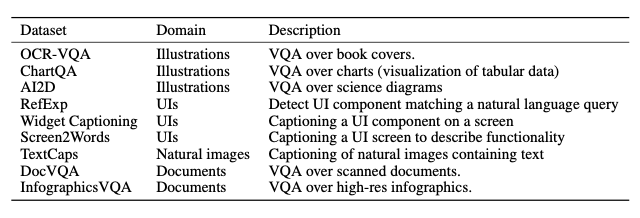
- 우리는 Pix2Struct를 총 4개의 도메인에서 평가
* illustrations, user interfaces, natural images, documents- Original paper의 evaluation metric을 사용해 평가
Implementation and Baselines
- Base model과 Large model
- BooksCorpus로 동일하게 warmup
