
Abstract
- 구성요소와 관계들을 저차원의 벡터 공간으로 임베딩 시켜, 지식 그래프의 기반이 되고 학습하기 쉬운 모델 TransE를 제시
- Relationship(관계)를 저차원의 임베딩된 구성요소관 translation(전환)으로 해석
Modeling multi-relational data
- Multi-relational data refers to directed graphs
- 원래 그래프의 node 쌍이 (head, label, tail) = 로 notating 됨
- head와 tail간의 관계가 바로 label
- 기존 데이터와 다르게 locality가 여러 정보를 가질 수 있다 (edge -> label)
- 다양한 논문들의 결과로, 복잡하고 이질적인 multi-ralational data에서 단순하면서도 적절한 모델링을 통해 accuracy와 scalability의 절충점을 찾을 수 있음이 확인 됨
Relationships as translations in the embedding space
- 우리의 모델 TransE는 entities를 저차원의 임베딩 벡터로 학습하고, relationship (label)을 transaltions in the embedding space 로 표현함
- 이 접근은 단순히 적은 수의 파라미터 (하나의 entity와 ralationship이 속한 저차원 벡터)에 의존함
- 이는 다음과 같은 motivation에서 기반
- 지식그래프에서 흔히 볼 수 있는 계층적 관계는 translation을 통해 잘 표현 됨
- 노드 타입이 다른 1 - to -1 관계 또한 translation을 통해 잘 표현 됨
- 우리의 모델은 실험에서 SOTA를 달성함 (real world link prediction on KBs)
Translation-based model
- (set of entities)
- (set of relationships)
- 우리는
- energy of triplet
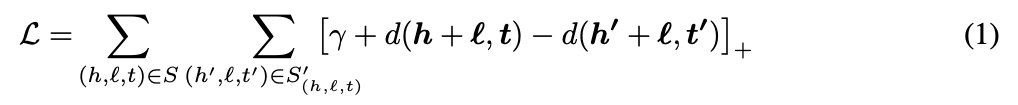
- 다음 식을 minimize
- denote positive part of x
- is a margine hyperparameter
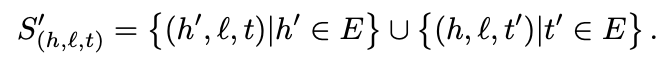
- set of corrupted triplets is a negative sample (head or tail replaced by a random entity)

- 다음 알고리즘을 통해 최적화
Related work
Compare to SE
- SE에 비해 표현력은 낮음
- 다만 낮은 표현력에도 불구하고, 실험적으로 SE보다 더 나은 성능
- 이는 두 가지 이유로 보임
- 우리의 모델이 보다 직접적으로 관계성 propertie에 접근함
- Embedding 모델에서 최적화의 어려움
- 따라서 SE에서의 더 나은 표현력은, 곧 더 나은 성능을 의미하는 것이 아닌 underfitting에 가까움
Drawbacks
- TransE는 2 way interaction을 표현하는데 단점을 가짐
- 심지어 head, tail, label의 3-way depednecies가 큰 경우, 거의 실패함 (1 to many, many to many 등)
내 결론
Head와 Relation을 더한 벡터는 Tail과 가까워야 한다
