문제 상황
현재 프로젝트 리스트 조회 API에서 성능 개선이 필요한 상황입니다.
목표는 퍼센타일 95% 응답시간(p95)을 500ms 이하로 만드는 것입니다.
기존 프로젝트 리스트 조회 API는 다음과 같은 구조를 가지고 있었습니다.
1. (1차) 필터링용 ID 리스트 조회
2. (2차) 필터링된 ID 중 정렬 및 페이지네이션 수행
3. (3차) 최종 ID 리스트로 Fetch Join으로 세부정보 모두 조회
4. (4차) DTO 매핑이 방식은 일단 동작은 하지만, 다음과 같은 심각한 성능 문제가 존재했습니다.
기존 구조의 문제점
| 문제 | 설명 |
|---|---|
| 쿼리 3번 왕복 | 필터링 → 정렬 → 상세조회 각각 별도 쿼리 |
| 3차 조회(fetchProjectsWithDetails) 쿼리 과다 | LEFT JOIN 6개(fetch join) + DISTINCT → 조인 폭발 위험 |
| 페이지네이션 ID 기준 | Project가 1:N 관계(TechStack, DevPosition)라 Fetch Join 시 row 수 곱해짐 |
| Having 사용 | Having 절은 무조건 성능이 나쁨 (데이터 모은 뒤 필터링) |
기존 코드가 튜닝 불가능한 이유
기존 코드는 다음과 같은 구조적 한계가 있었습니다.
| 항목 | 문제 |
|---|---|
| fetch join | 프로젝트 + member + techStack + devPosition + like 등을 한방에 조인해서 가져옴 |
| select distinct | 조인된 row 수만큼 결과가 중복 발생 (row 폭발) |
| TPS 확장 불가 | 데이터가 조금만 많아져도 서버/DB 메모리 초과 |
| 인덱스 튜닝 의미 없음 | 문제는 인덱스가 아니라 "조인된 데이터량 자체"였음 |
즉, 튜닝으로 해결될 문제가 아니라, 애초에 데이터 모델과 조회 구조가 잘못 설계된 상태였습니다.
쿼리 튜닝이나 인덱스 추가로는 본질적인 개선이 불가능했습니다.
구조 개선 방향
기존 구조를 다음과 같이 변경했습니다.
1. (1차) 필터 조건이 있는 경우: JOIN + GROUP BY + HAVING으로 전체 ID 조회 → Java에서 페이징
2. (1차) 필터 조건이 없는 경우: count 쿼리 + offset/limit로 ID 조회 (DB 단 페이징)
3. (2차) 선별된 ID 기반으로 기본 정보 Projection 조회
4. (3차) techStacks 이미지 URL은 별도 batch 조회로 조회 후 결합
5. (4차) DTO 생성 시 techStack 정보 결합하여 최종 응답 구성적용한 구체적 전략은 다음과 같습니다:
- Fetch Join 제거
- 정렬 기준을 Enum으로 분리하여 재사용성과 안정성 확보
- 필터 조건 유무에 따라 쿼리 경로 분기 처리 (count() + offset/limit 적용)
- 필요한 데이터만 Projection
- batch 조회 분리 (recruitmentCount, techStacks)
- group by + having 필터 조건 최적화 가능성 확보
이렇게 개선하면 다음과 같은 장점이 생깁니다.
| 항목 | 장점 |
|---|---|
| 필요한 필드만 선택 | 불필요한 데이터 없이 DTO 바로 조회 |
| batch 조회 분리 | 필요한 id만 뽑고 세부 조회를 분리 |
| 네트워크 부하 감소 | 응답 크기 최소화 |
| TPS 선형 확장 가능 | 요청 수가 늘어나도 급격히 느려지지 않음 |
| 인덱스 튜닝 가능 | where in, group by 대상에 인덱스 최적화 가능 |
📌 코드 예시
실제 코드에선 필터 유무에 따라 두 가지 방식으로 ID를 조회합니다.
// 필터 조건 있을 경우: 전체 ID 조회 후 Java에서 skip/limit
if (hasTechStack || hasDevPosition) {
List<Long> allMatchingIds = queryFactory
.select(PROJECT.id)
.from(PROJECT)
.leftJoin(PROJECT.projectTechStacks, PROJECT_TECH_STACK)
.leftJoin(PROJECT.projectDevPositions, PROJECT_DEV_POSITION)
.where(whereBuilder)
.groupBy(PROJECT.id)
.having(
hasTechStack ? PROJECT_TECH_STACK.techStack.id.countDistinct().eq((long) techStackIds.size()) : null,
hasDevPosition ? PROJECT_DEV_POSITION.developmentPosition.id.countDistinct().eq((long) devPositionIds.size()) : null
)
.fetch();
total = allMatchingIds.size();
filteredIds = allMatchingIds.stream()
.skip(pageable.getOffset())
.limit(pageable.getPageSize())
.toList();
} else {
// 필터 없을 경우: DB에서 바로 offset/limit + count
total = queryFactory
.select(PROJECT.count())
.from(PROJECT)
.fetchOne();
filteredIds = queryFactory
.select(PROJECT.id)
.from(PROJECT)
.orderBy(sort.getOrderSpecifier(PROJECT))
.offset(pageable.getOffset())
.limit(pageable.getPageSize())
.fetch();
}
}정렬 기준은 Enum으로 추상화해 재사용성과 가독성을 높였습니다.
public enum SearchProjectSort {
// 좋아요 순 정렬
LIKE {
@Override
public OrderSpecifier<?> getOrderSpecifier(QProject project) {
NumberTemplate<Long> likeCountExpr = Expressions.numberTemplate(Long.class,
"(select count(l1.id) from Like l1 where l1.project.id = {0})", project.id);
return likeCountExpr.desc();
}
},
// 생성일 순 정렬
CREATED_AT {
@Override
public OrderSpecifier<?> getOrderSpecifier(QProject project) {
return project.createdAt.desc();
}
};
public abstract OrderSpecifier<?> getOrderSpecifier(QProject project);
}
💬 전체 구현 코드는 GitHub PR에서 확인하실 수 있습니다.
개선 결과
※ 본 측정은 로컬 개발 환경(MacBook, Docker 기반 MySQL)에서 진행되었으며, 서버 리소스(CPU, 메모리 등) 한계로 인해 실제 서비스 환경과는 차이가 있을 수 있습니다.
개선 전에는 하나의 API를 사용하는 3개 시나리오에서 p95가 모두 1300~1500ms 수준이었습니다.

리팩터링된 구조로 코드를 개선한 이후, 모든 시나리오에서 p95가 대폭 감소하여 500ms 목표를 훨씬 초과 달성했습니다.
| 시나리오 | 개선 전 p95 | 개선 후 p95 |
|---|---|---|
| 정렬 only(createdAt) | 1295ms | 28ms |
| 정렬 only(like) | 1483ms | 145ms |
| 필터 조건 + 좋아요 정렬 | 1468ms | 71ms |

TPS 변화
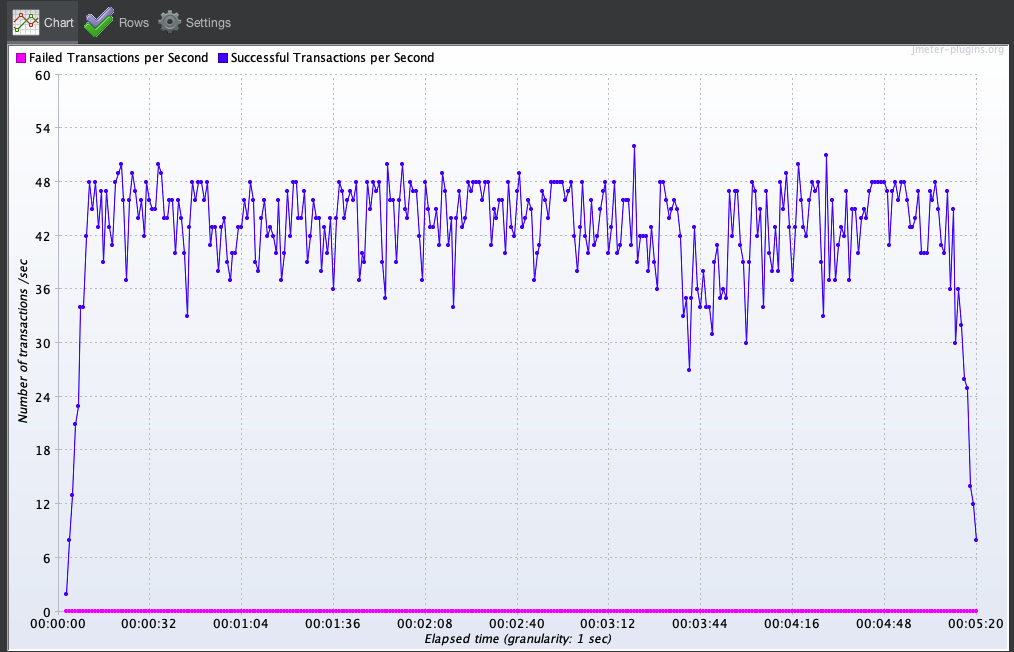
TPS(초당 처리량) 역시 함께 향상되었습니다.
개선 전에는 TPS가 10 수준으로 제한되었지만, 개선 후에는 최대 60 TPS까지 도달했습니다.
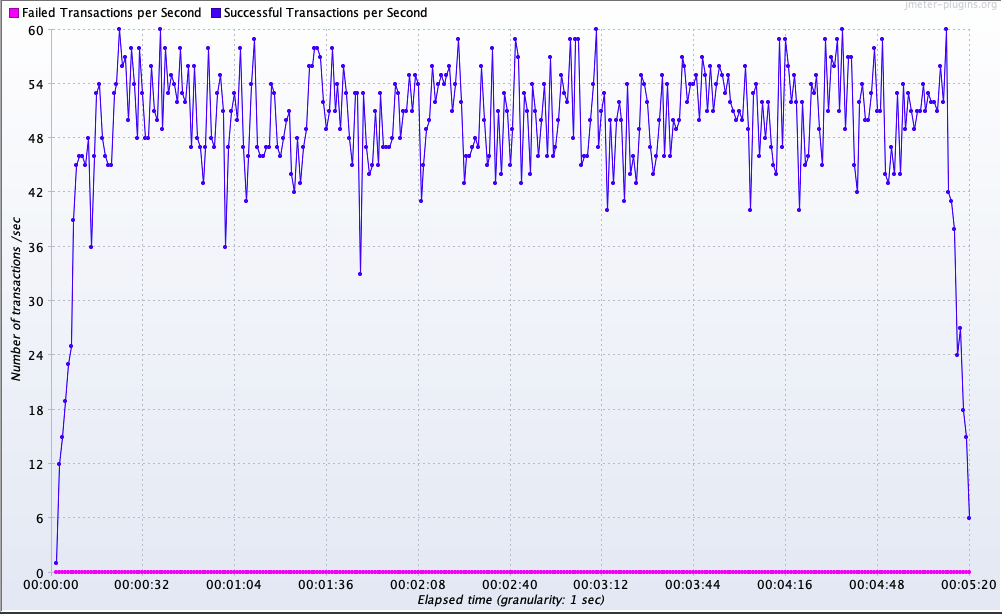
응답 성능뿐만 아니라, 처리 가능량 자체가 대폭 늘어난 결과이며, 실제 트래픽 증가에도 안정적으로 대응 가능한 기반을 마련했습니다.
결론
- 기존 구조는 fetch join + 3단계 쿼리로 인해 과도한 DB I/O, row 폭발, TPS 저하가 있었습니다.
- 쿼리 경로를 필터 조건에 따라 분기 처리하고, 조건 없는 경우 DB단에서 바로 count + 페이징,
조건 있는 경우 having 조건 통과 후 Java에서 페이징으로 전략을 나눠 처리했습니다. - 정렬 기준을 Enum화하고, 쿼리 분기 구조를 명확히 하여 유지보수성과 확장성 또한 크게 향상되었습니다.
- 리팩터링 후 p95는 최대 145ms, TPS는 최대 60으로,
당초 목표였던 p95 500ms 이하를 모든 시나리오에서 안정적으로 달성했습니다.
- 목표를 달성했기 때문에 추가 튜닝은 하지 않았습니다. 서버에서의 측정 이후 필요시 추가 튜닝 예정입니다.
