위의 백엔드 커리어 로드맵에서 필요하다고 생각하는 부분만 정리해보았습니다.
NoSQL 데이터베이스 - MongoDB
MongDB는 NoSQL(사람마다 부르는 경우가 다른데 non sql, not only sql의 약어로 대부분 생각하고 비관계형을 지칭할 때 사용한다.)로 분류되는 크로스플랫폼(소프트웨어가 둘 이상의 플랫폼을 지원하는 것을 뜻하는 용어) 도큐먼트 지향 데이터베이스 시스템이다.
MySQL처럼 전통적인 데이블-관계 기반의 RDBMS(관계형 데이터베이스를 만들고 업데이트하고 관리하는데 사용하는 프로그램)가 아니며 SQL(데이터베이스 시스템에서 자료를 처리하는 용도로 사용되는 구조적 데이터 질의 언어)을 사용하지 않는다.
이름의 mongo는 humongous를 줄인 표현이다. 즉 ‘겁나 큰 DB’라는 뜻이다.
자바스크립트 런타임으로는 모질라의 SpiderMonkey를 사용한다.
전자 상거래 플랫폼 - 모든 자체 채널들에 기능과 서비스를 제공하는 이 플랫폼은 회사가 빠르게 새로운 앱을 설계 배포하면서도 지속적인 고객 경험을 제공
소셜 기술 기업 - 1,000곳이 넘는 클라이언트들의 소셜 활동을 저장. 스프링클러의 몽고DB 플랫폼은 분당 300만 건 이상의 트랜젝션을 처리한다. 또 매달 최소 한가지 주요 기능 및 100종 이상의 일반 기능을 선보일 수 있도록 지원.
게임 퍼블리셔 - 몽고DB로 이전하기 전까지 관계형 데이터베이스를 이용했으며, 이로 인해 확장성에 어려움을 겪었다. 이 기업은 멀티-테넌트 서비스로서의 데이터베이스를 채택함으로써 데이터베이스 인스턴스들을 통합해 성능과 안정성 향상을 가져왔다.
사용자들을 위해 회의 스케줄을 잡는 인공지능 기반의 개인 비서 서비스 - 몽고DB는 전체 인공지능 플랫폼을 위한 기록 시스템을 담당하면서 자연어 프로세싱, 지도 학습, 애널리틱스, 이메일 커뮤니케이션 등 모든 서비를 지원
특징
신뢰성 : 서버 장애에도 서비스는 계속 동작
확장성 : 데이터와 트래픽 증가에 따라 수평확장 가능
유연성 : 여러 가지 형태의 데이터를 손쉽게 저장
Index 지원 : 다양한 조건으로 빠른 데이터 검색
장점
Schema-less구조 : 다양한 형태의 데이터 저장 가능, 데이터 모델의 유연한 변화 가능(데이터 모델 변경, 필드 확장 용이)
Read/Write 성능이 뛰어남
Scale Out 구조 : 많은 데이터 저장이 가능, 장비 확장이 간단함
JSON 구조 : 데이터를 직관적으로 이해 가능
사용 방법이 쉽고, 개발이 편리함
더 깊은 데이터베이스 지식 - 트랜잭션
데이터베이스에서 데이터에 대한 하나의 논리적 실행단계를 트랜잭션이라고 한다.
더 이상 쪼갤 수 없는 업무 처리의 최소 단위. 거래내역이라고도 한다.
Ex) A라는 사람이 B라는 사람에게 1,000원을 지급하고 B가 그 돈을 받은 경우, 이 거래 기록은 더 이상 작게 쪼갤 수가 없는 하나의 트랜잭션을 구성한다. 만약 A는 돈을 지불했으나 B는 돈을 받지 못했다면 그 거래는 성립되지 않는다. 이처럼 A가 돈을 지불하는 행위와 B가 돈을 받는 행위는 별개로 분리될 수 없으며 하나의 거래내역으로 처리되어야 하는 단일 거래이다.
데이터베이스의 트랜잭션이 안전하게 수행되기 위해서는 ACID 조건을 충족해야한다.
트랜잭션은 데이터베이스 서버에 여러 개의 클라이언트가 동시에 액세스 하거나 응용프로그램이 갱신을 처리하는 과정에서 중단될 수 있는 경우 등 데이터 부정합을 방지하고자 할 때 사용한다.
트랜잭션 연산 및 상태
Commit 연산 - 한 개의 논리적 단위(트랜잭션)에 대한 작업이 성공적으로 끝났고 데이터베이스가 다시 일관된 상태에 있을 때, 이 트랜잭션이 행한 갱신 연산이 완료된 것을 트랜잭션 관리자에게 알려주는 연산이다.
Rollback 연산 - Rollback 연산은 하나의 트랜잭션 처리가 비정상적으로 종료되어 데이터베이스의 일관성을 깨뜨렸을 때, 이 트랜잭션의 일부가 정상적으로 처리되었더도 트랜잭션의 원자성을 구현하기 위해 이 트랜잭션이 행한 모든 연산을 취소하는 연산이다.
Rollback시에는 해당 트랜잭션을 재시작하거나 폐기한다.
아래의 구조와 같이 실행한다.
활동
부분 완료 실패
완료 철회
더 깊은 데이터베이스 지식 - ACID
데이터베이스 트랜잭션이 안전하게 수행된다는 것을 보장하기 위한 성질을 가리키는 약어이다. 여러 개의 작업을 하나로 묶은 실행 유닛을 말한다.
위의 트랜잭션이 ACID라는 특성을 가지고 있다.
ACID는 데이터베이스 내에서 일어나는 하나의 트랜잭션의 안정성을 보장하기 위해 필요한 성질이다.
ACID는 주식거래, 금융업에서 중점적으로 사용되며 주식거래, 금융업에서는 관계형 데이터베이스를 이용한다.
관계형 데이터베이스를 사용하면 데이터베이스와 상호 작용하는 방식을 정확하게 규정할 수 있기 때문에, 데이터베이스에서 데이터를 처리할 때 발생할 수 있는 예외적인 상황을 줄이고 데이터베이스의 무결성을 보호할 수 있다.
Atomicity(원자성) - 원자성이란 시스템에서 한 트랜잭션의 연산들이 모두 성공하거나 반대로 전부 실패되는 성질을 말한다. 하나의 트랜잭션이 더 이상 작게 쪼갤 수 없는 최소한의 업무 단위이다.
Consistency(일관성) - 트랜잭션이 완료된 결괏값이 일관적인 DB 상태를 유지하는 것. 시스템이 가지고 있는 고정요소는 수행 전과 후의 상태가 같아야 하며 트랜잭션의 작업 처리 결과가 항상 일관성이 있어야 한다는 것으로 트랜잭션이 진행되는 동안 데이터베이스가 변경되더라도 업데이트된 데이터베이스로 트랜잭션이 진행되는 것이 아니라, 처음 트랜잭션을 진행하기 위해 참조한 데이터베이스로 진행된다. 이렇게 함으로써 각 사용자가 일관성 있는 데이터를 볼 수 있는 것이다.
Isolation(격리성, 고립성) - 하나의 트랜잭션 수행시 다른 트랜잭션의 작업이 끼어들지 못하도록 보장하는 것이다. 즉, 트랜잭션 끼리는 서로를 간섭할 수 없다. 트랜 잭션이 실행하는 도중에 변경한 데이터는 이 트랜잭션이 완료될 때까지 다른 트랜잭션이 참조하지 못하게 하는 특성이다.
Durability(지속성) - 트랜잭션이 정상적으로 종료된 다음에는 영구적으로 데이터베이스에 작업의 결과가 저장되어야 한다. 지속성은 트랜잭션의 성공 결과 값은 장애 발생 후에도 변함없이 보관되어야 한다더 깊은 데이터베이스 지식 - ORM
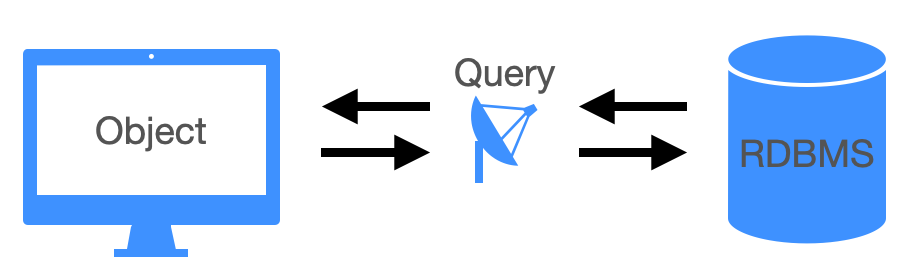
ORM(Object Relational Mapping) 은 아래의 사진으로 한번에 정리가 가능합니다.
기존의 DBMS 와 통신하는 것이 Query 문이라면, 이 ORM 은 이 Query 를 대체해서 사용하는 친구라고 보셔도 무방합니다.
그림상으로 표현하면 위와 같습니다.
즉, ORM 은 Object 를 RDBMS, 관계형 데이터베이스와 매핑을 해주는 도구입니다.
즉 ORM 이 없는 상태라면, 데이터를 DB에 삽입하기위해 "INSERT INTO~" query 구문이 실행되도록 작성하거나, 삭제할 경우 "DELETE", 업데이트를 위한 "UPDATE" Query 문을 하나씩 작성했다면, ORM 은 이러한 Query 문을 생략하게 끔 도와주는 도구라고 생각하시면 되겠습니다.
즉 Query 문을 직관적인 method 로 구현하고, 사용자가 Query 문을 잘 사용하지 못하더라도, ORM 을 활용하면 구현이 가능합니다.
하지만 이 ORM은 바로 한가지의 전제를 두고 사용이 되어야 합니다.
"OOP", 즉 객체지향 프로그래밍 관점으로 접근해야 합니다.
일반적으로 RDBMS는 Table , OOP 는 Class 개념으로 접근하게 됩니다.
하지만 Object 와 Relational 은 불일치가 조금씩 발생할 수 밖에 없습니다.
즉 이 ORM 을 사용하게 되면, RDBMS 접근을 OOP 관점에서 접근이 가능하게 됩니다. 즉, ORM 을 사용함으로서 Object 간의 관계를 기반하여 SQL Query 문을 사용함으로써 개선할 수 있습니다.
또한 SQL 문을 직접 작성하지 않아도 Object 를 사용해서 간접적으로 RDBMS 를 다룰 수 있습니다.
2. ORM 장점 및 단점
1)ORM의 장점
ORM은, 작성자 본인의 입장에서는 단점보다는 장점이 더 많은 Tool 이라고 생각이 됩니다.
몇가지 정리해보도록 하겠습니다.
직관적인 코드 작성
생산성 향상
재사용 및 유지보수 편의성
Query 문을 보면, 적지 않은 구문의 길이를 나타냅니다. 하지만 ORM 은 이를 "method" 화를 시켜서 사용하기 때문에, 작성이나, 사용측면에서 매우 직관적이라고 할 수 있습니다.
그만큼의 시간, Code Read time 만큼이나, 다른 것에 집중할 수 있으니, 이 점 하나만으로도 직관성+생산성을 모두 잡은 것이라고 할 수 있습니다.
SQL Query 문은 절차에 따라 순서에 맞게 접근이 되야하지만, ORM 은 객체지향적인 접근으로 보다 직관적인 사용이 가능합니다.
그리고 ORM 은 특정 DB에 종속성이 있지 않습니다.
즉 MySQL 에 맞는 ORM 은 A, MongoDB 에 맞는 ORM은 "C" 가 아니라, ORM은 어느 DB에서도 독립적으로 동작할 수 있습니다. 그러므로 이를 잘 사용한다면 Design Pattern, 즉 위에서 잠시 언급한 "MVC Pattern" 에서는 Object 와 Model 간의 관계를 보다 손쉽게 정의가 가능합니다.
그리고 독립적 작성이니만큼, Object를 재활용 할 수도 있습니다.
이를 통해 OOP 측면에서는 작성자 입장에서는 Object 자체에 집중할 수 있기 때문에, 효율성 측면에서도 장점이 있다고 할 수 있습니다.
2)ORM의 단점
사실 이제 막 배우는 단계이기때문에, ORM에 관련된 여러 글을 읽어보고, 이론적인 접근으로 단점을 구술하는 것이라,
제 글이 답이 아닐수 있습니다.
1. 설계 단계에서부터 공을 들여야 합니다.
만약 설계단계와 구현단계에서 구현이 어긋날 경우, 일관성이 무너질 뿐 아니라 코드 전체에서 문제가 발생할 수 도 있습니다.
예를들어, 기존의 SQL Query 구문으로 구현된 System 일 경우, ORM 으로 변경할 경우, 완전히 새롭게 설계하는 것 만큼 기존의 Query 구문에 연결된 것들을 Object 로 바꾸는 과정만 해도 생산성저하는 둘째치고, 리스크가 적지 않을 것입니다.
2. 단점이라고 보기 어려울수도 있지만, System 을 객체지향적 관점으로 올바르게 보지 못할 경우, Persistence, 즉 영속성의 대한 개념 접근이 이루어지지 않으면 ORM 사용은 쉽지 않은 사용이 될 수 있습니다. 영속성의 대한 개념을 간단하게 정리하면 "데이터를 생성한 Application 이 종료되어도 데이터가 유지되는 특성" 입니다. 즉 Cache 나 Session, Cookie 같은 것이 아니라, DB에 영구히 저장되는 과정이라고 할 수 있습니다.
3. 속도적인 문제도 발생할 수 있습니다. 구현자체는 되었더라도, 올바르지 않게 구현된 경우, 속도저하의 문제도 발생할 수 있습니다. 더 깊은 데이터베이스 지식 - N+1 문제
JPA를 사용하다 보면 의도하지 않았지만 여러 번의 select문이 순식간에 여러 개가 나가는 현상을 본 적이 있을 것이다. 이러한 현상을 N+1문제라고 부른다.
N+1문제란 - 연관 관계가 설정된 엔티티를 조회할 경우에 조회된 데이터 개수 만큼 연관 관계의 조회 쿼리가 추가로 발생하여 데이터를 읽어오는 현상이다. 간단하게 설명하면 1번의 쿼리를 날렸을 때 의도하지 않은 N번의 쿼리가 추가적으로 실행되는 것을 의미한다.
언제 발생하는지 - JPA Repository를 활용해 인터페이스 메소드를 호출할 때(Read 시)
누가 발생시키는지 -1:N 또는 N:1 관계를 가진 엔티티를 조회할 때 발생하고
어떤 상황에 발생되는지 - JPA Fetch 전략이 EAGER 전략으로 데이터를 조회하는 경우
- JPA Fetch 전략이 LAZY 전략으로 데이터를 가져온 이후에 연관 관계인 하위 엔티티를 다시 조회하는 경우 발생하고
왜 발생하는지 - JPA Repository로 find 시 실행되는 첫 쿼리에서 하위 엔티티까지 한번에 가져오지 않고, 하위 엔티티를 사용할 때 추가로 조회하기 때문에
- JPQL은 기본적으로 글로벅 Fetch 전략을 무시하고 JPQL만 가지고 SQL을 생성하기 때문에.
EAGER(즉시로딩)인 경우
1. JPQL에서 만든 SQL을 통해 데이터를 조회.
2. 이후 JPA Fetch 전략을 가지고 해당 데이터의 연관 관계인 하위 엔티티들을 추가 조회
3. 2번 과정으로 N+1문제 발생
LAZY(지연 로딩)인 경우
1. JPQL에서 만든 SQL을 통해 데이터를 조회
2. JPA에서 Fetch 전략을 가지지만, 지연 로딩이기 때문에 추가 조회는 하지 않음
3. 하지만, 하위 엔티티를 가지고 작업하게 되면 추가 조회가 발생하기 때문에 결국 N+1 문제 발생
N+1문제 해결방법
해결 방법에는 여러 방법들이 있는데 FetchJoin과 Entity Graph 두 가지 방법을 알아보겠다.
1. Fetch Join(패치 조인)
N+1 자체가 발생하는 이유는 한쪽 테이블만 조회하고 연결된 다른 테이블은 따로 조회하기 때문이다.
미리 두 테이블을 Join하여 한 번에 모든 데이터를 가져올 수 있다면 애초에 N+1 문제가 발생하지 않을 것이다. 그렇게 나온 해결 방법이 FetchJoin 방법이다.
두 테이블을 Join하는 쿼리를 직접 작성하는 것이다. 그리고 JPQL을 직접 지정해준다.
- 단점
- 쿼리 한번에 모든 데이터를 가져오기 때문에 JPA가 제공하는 Paging API 사용 불가능(Pageable 사용불가)
- 1:N 관계가 두 개 이상인 경우 사용 불가
- 패치 조인 대상에게 별칭(as) 부여 불가능
- 번거롭게 쿼리문을 작성해야 함
2. Entity Graph
Entity Graphd의 attributePaths는 같이 조회할 연관 엔티티명을 적으면 된다. ,(콤마)를 통해 여러 개를 줄 수도 있다.
Fetch join과 동일하게 JPQL을 사용해 Query문을 작성하고 필요한 연관관계를 Entity Graph에 설정하면 된다.
비교
Fetch Join과 Entity Graph의 출력되는 쿼리르 보면
Fetch Join의 경우 inner join을 하는 반면에 Entity Graph는 outer join을 기본으로 한다.
(기본적으로 outer join보다 inner join이 성능 최적하에 더 유리하다.) 이를 보았을 때 Entity Graph는 굳이 사용하지 않을 것 같다 왜냐면 JPQL을 사용할 경우 그냥 쿼리 뒤에 join fetch만 붙여주면 되는데 번거롭게 어노테이션과 그 속성을 추가할 필요가 없기 떄문이다.
주의점
Fetch join과 Entity Graph는 공통적으로 카테시안 곱(두 테이블 사이에 유효 join 조건을 적지 않았을 때 해당 테이블에 대한 모든 데이터를 전부 결합하여 테이블에 존재하는 행 개수를 곱한만큼의 결과 값이 반환되는 것)이 발생하여 중복이 생길 수 있다.
해결방안
이런 중복 발생 문제를 해결하기 위한 방법은 다음과 같다.
1. JPQL에 DISTINCT를 추가하여 중복 제거
2. OneToMany 필드 타입을 Set으로 선언하여 중복 제거
- Set은 순서가 보장되지 않는 특징이 있지만, 순서 보장이 필요한 경우 LinkedHashSet을 사용한다.)
카테시안 곱 피하기 - 카테시안 곱이 일어나는 Cross Join은 JPA 기능 때문이 아니라, 쿼리의 표현에서 발생하는 문제이다.
Cross join이 일어나는 조건은 간단하다.
Join 명령을 했을 때 명확한 join 규칙이 주어지지 않았을 때 (* join 이후 on 절이 없을 때, db는 두 테이블의 결합한 결과를 내보내야겠고, 조건이 없으니 M*N으로 모든 경우의 수를 출력하는 것이다.) JPA는 사용자가 보내준 코드를 해석해서 최적의 sql 문장을 조립하는데, 이 때 코드가 얼마나 연관관계를 명확히 드러냈냐에 따라 발생 할 수도 안 할 수도 있다.
Fetch Join과 Entity Graph 기능은 ‘Cross Join을 만들어라’ 나 ‘Inner Join을 만들어라’ 가 아니고, ‘연관관계 데이터를 미리(EAGER) 함께 가져와라’ 이다.
JPA 프레임워크로부터 특정한 방향(흔히 inner join)으로 최적화된 쿼리를 유도하려면, 프레임워크가 이해할 수 있는 연관관계와 상황을 코드로 적절히 전달하면 된다.
이 때 FetchJoin, FetchType.EAGER, Entity Graph 등이 최적화된 쿼리를 유도하는 데 도움을 주는 것이다.
더 깊은 데이터베이스 지식 - 데이터베이스 정규화
정규화는 이상현상이 있는 릴레이션을 분해하여 이상현상을 없애는 과정이다. 이상현상이 존재하는 릴레이션을 분해하여 여러 개의 릴레이션을 생성하게 된다. 이를 단계별로 구분하여 정규형이 높아질수록 이상현상은 줄어들게 된다.
정규화의 기본 목표는 테이블 간에 중복된 데이터를 허용하지 않는다는 것이다.
중복된 데이터를 허용하지 않음으로써 무결성을 유지할 수 있으며, DB의 저장 용량 역시 줄일 수있다.
정규화의 장점
- 데이터베이스 변경 시 이상현상을 제거할 수 있다.
- 정규화된 데이터베이스 구조에서는 새로운 데이터 형의 추가로 인한 확장 시, 그 구조를 변경하지 않아도 되거나 일부만 변경해도 된다.
- 데이터베이스와 연동된 응용 프로그램에 최소한의 영향만을 미치게 되어 응용프로그램의 생명을 연장시킨다.
정규화의 단점
- 릴레이션의 분해로 인해 릴레이션 간의 JOIN 연산이 많아진다.
- 질의에 대한 응답 시간이 느려질 수도 있다. 데이터의 중복 속성을 제거하고 결정자에 의해 동일한 의미의 일반 속성이 하나의 테이블로 집약되므로 한 테이블의 데이터 용량이 최소화되는 효과가 있다.
- 따라서 데이터를 처리할 때 속도가 빨라질 수도 있고 느려질 수도 있다.
- 만약 조인이 많이 발생하여 성능 저하가 나타나면 반정규화를 적용할 수도 있다.
정규화를 알아보기 전에 이상현상과 함수 종속성에 대해서 꼭 알아야 한다.
이상현상
- 삽입 이상 : 튜플 삽입 시 특정 속성에 해당하는 값이 없어 NULL을 입력해야 하는 현상
- 삭제 이상 : 튜플 삭제 시 같이 저장된 다른 정보까지 연쇄적으로 삭제되는 현상
- 갱신 이상 : 튜플 갱신 시 중복된 데이터의 일부만 갱신되어 일어나는 데이터 불일치 현상
함수 종속성
- 함수 종속성은 어떤 속성 A의 값을 알면 다른 속성 B의 값이 유일하게 정해지는 관계를 종속성이라고 한다.
- A -> B로 표기하며 A를 B의 결정자라고 한다.
- A -> B이면 A는 B를 결정한다고 하고, B는 A에 종속한다라고 한다.
제1 정규화
- 제 1정규화란 테이블의 컬럼이 원자값을 갖도록 테이블을 분해하는 것이다.
그리고 이와 같은 규칙들을 만족해야 한다.
1. 각 컬럼이 하나의 속성만을 가져야 한다.
2. 하나의 컬럼은 같은 종류나 타입의 값을 가져야 한다.
3. 각 컬럼이 유일한 이름을 가져야 한다.
4. 칼럼의 순서가 상관없어야 한다.
제2 정규화
- 제1 정규화를 진행한 테이블에 대해 완전 함수 종속을 만족하도록 테이블을 분해하는 것이다. 여기서 완전 함수 종속이라는 것은 기본키의 부분집합이 결정자가 되어선 안된다는 것을 의미한다.
그리고 이와 같은 규칙들을 만족해야 한다.
1. 1정규형을 만족해야 한다.
2. 모든 컬럼이 부분적 종속이 없어야 한다. == 모든 칼럼이 완전 함수 종속을 만족해야 한다.
제3 정규화
- 제2 정규화를 진행한 테이블에 대해 이행적 종속을 없애도록 테이블을 분해하는 것이다.
여기서 이행적 종속이라는 것은 A -> B, B -> C가 성립할 때 A -> C가 성립되는 것을 의미한다.
그리고 이와 같은 규칙들을 만족해야 한다.
1. 2정규형을 만족해야한다.
2. 기본키를 제외한 속성들 간의 이행 종속성이 없어야 한다.
BCNF 정규화
- 제3 정규화를 진행한 테이블에 대해 모든 결정자가 후보키가 되도록 테이블을 분해하는 것이다.
그리고 BCNF는 제3 정규형을 좀 더 강화한 버전으로 이와 같은 규칙들을 만족해야 한다.
1. 3정규형을 만족해야 한다.
2. 모든 결정자가 후보키 집합에 속해야 한다.
제4 정규화 이상
보통 정규화는 BCNF 까지만 하는 경우가 많다. 그 이상 정규화를 하면 정규화의 단점이 나타날 수도 있다.
더 깊은 데이터베이스 지식 - 인덱스와 그 작동 원리
인덱스는 추가적인 쓰기 작업과 저장 공간을 활용하여 데이터베이스 테이블의 검색 속도를 향상시키기 위한 자료구조이다.
목적
- RDBMS에서 검색속도를 높이기 위한 기술이다.
- Table의 Column을 색인화 한다.
인덱스 관리
DBMS는 index를 항상 최신의 정렬된 상태로 유지해야 원하는 값을 빠르게 탐색할 수 있다.
인덱스가 적용된 Column에 insert, update, delete가 수행된다면 다음과 같은 연산을 추가적으로 해주어야 한다.
- insert : 새로운 데이터에 대한 인덱스를 추가한다.
- delete : 삭제하는 데이터의 인덱스를 사용하지 않는다는 작업을 진행한다.
- update : 기존의 인덱스를 사용하지 않는 것으로 처리하고, 갱신된 데이터에 대해 인덱스를 추가한다.
과정
Table을 생성하면 MYD, MYI FRM 3개의 파일이 생성된다.
- FRM : 테이블 구조가 저장되어 있는 파일
- MYD : 실제 데이터가 있는 파일
- MYI : index 정보가 들어가 있는 파일
Index를 사용하지 않는 경우 MYI파일은 비어져 있다. 인덱싱하는 경우, MYI 파일이 생성된다. 이후 사용자가 Select 쿼리로 index를 사용하는 Column을 탐색시 MYI파일의 내용을 검색한다.
장점
- 테이블을 조회하는 속도와 그에 따른 성능을 향상시킬 수 있다.
- 기존 where문을 사용할 때 테이블 전체를 조건과 비교하는 Full Table Scan 작업이 필요한데, 인덱스 사용시 데이터가 정렬된 형태로 있기 때문에 데이터를 빠르게 찾을 수 있다.
- 전반적인 시스템의 부하를 줄일 수 있다.
단점
- 인덱스를 관리하기 위해 DB의 약 10%에 해당하는 저장공간이 필요하다.
- 인덱스를 관리하기 위해 추가 작업이 필요하다.
- 인덱스를 잘못 사용할 경우 오히려 성능이 저하되는 역효과가 발생할 수 있다.
사용하면 좋은 경우
- Where절에서 자주 사용되는 Column
- 외래키가 사용되는 Column
- Join에 자주 사용되는 Column
Index 사용을 피해야 하는 경우
- Data 중복도가 높은 Column
- DML(데이터 조작언어)이 자주 일어나는 Column
동작원리
데이터 블록이 10만개 있다고 가정할 때 SELECT문 실행시
server process가 구문 분석 과정을 마친 후 database buffer cache 에 조건이 부합하는 데이터가 있는지 확인
해당 정보가 buffer cache에 없다면 디스크 파일에서 조건에 부합하는 블럭을 찾아서 database buffer cache에 가져온 뒤 사용자에게 보여줌
이 때 인덱스가 없으면 10만개를 전부 database buffer cache 로 복사한 후 풀스캔으로 찾게 되는데
index가 있는 경우 where절의 조건 컬럼이 인덱스 키로 생성되어있는지 확인 후 인덱스에 조건에 부합하는 정보가 어떤 ROWID를 가지고 있는지 확인 후 ROWID에 있는 블럭을 찾아가 해당 블럭만 buffer cache에 복사한다.API - 인증
인증은 누가 서비스를 사용하는지를 확인하는 절차이다.
쉽게 생각하면 웹 사이트에 사용자 아이디와 비밀번호를 넣어서 사용자를 확인하는 과정이 인증이다.
API도 마찬가지로 API를 호출하는 대상 (단말이 되었던 다른 서버가 되었던 사용자가 되었건) 확인하는 절차가 필요하다.
스프링 시큐리티에서는 인증을 who are you? 라고 표현하고 인가를 what are you allow to do? 라는 문장으로 비유하고 있다.
인가(Authorization)
인가는 해당 리소스에 대해서 사용자가 그 리소스를 사용할 권한이 있는지 확인하는 권한 체크 과정이다.
예를 들어서, /users 라는 리소스가 있을 때, 일반 사용자 권한으로는 내 사용자 권한만 볼 수 있지만, 관리자 권한으로는 다른 사용자 정보를 볼 수 있는 것과 같은 권한의 차이를 의미한다.
네트워크 레벨 암호화
인증과 인가 과정이 끝나서 API를 호출하게 되면, 네트워크를 통해서 데이터가 오가는데, 해커나 누군가 중간에서 이 네트워크 통신을 낚아채 (감청) 데이터를 볼 수 없게 할 필요가 있다.
이를 네트워크 프로토콜단에서 처리하는 것을 네트워크 암호화라고 하는데, HTTP에서의 네트워크 암호화는 일반적으로 HTTPS 기반의 프로토콜을 사용한다.
메시지 무결성 보장
메시지 무결성이란, 메시지가 해커와 같은 외부 요인에 의해서 중간에 변조가 되지 않게 방지하는 것을 말한다.
무결성을 보장하기 위해서 많이 사용하는 방식은 메시지에 대한 서명(Signature)를 생성해서 메시지와 같이 보내고 검증하는 방식이다.
예를 들어 메시지 문자열이 있을 때, 이 문자열에 대한 해시 코드를 생성해서 문자열과 함께 보내고 이 받은 문자열로 생성한 해시 코드를 문자열과 함께 온 해시 코드와 비교하는 방법이다.
만약에 문자열이 중간에 변조되었으면 원래 문자열과 함께 전송된 해시 코드와 맞지 않기 때문에 메시지가 중간에 변조되었는지 확인할 수 있다.
메시지 무결성의 경우 앞에서 언급한 네트워크 레벨의 암호화를 완벽하게 사용한다면 외부적인 요인(해커)에 의해서 메시지를 해석당할 염려가 없으므로 사용할 필요가 없다.
메시지 본문 암호화
네트워크 레벨의 암호화를 사용할 수 없거나, 또는 이를 신뢰할 수 없는 상황에서 추가로 메시지 자체를 암호화하는 방법을 사용한다.
이는 애플리케이션 단에서 구현하는데, 전체 메시지를 암호화하는 방법과 특정 필드만 암호화하는 방식 두 가지로 접근할 수 있다.
전체 메시지를 암호화할 경우 암호화에 드는 비용이 많은 뿐더러 중간에 API Gateway를 통해서 메시지를 열어보고 메시지 기반으로 라우팅 변환 작업이 어렵기 때문에 일반적으로 전체 암호화보다는 보안이 필요한 특정 필드만 암호화하는 방식을 사용한다.
인증(Authentication) 방식의 종류
API에 대한 인증 방식은 여러 가지 방식이 있으며 각 방식에 따라 보안 수준과 구현 난도가 달라서 각 방식의 장단점을 잘 이해하여 서비스 수준에 맞는 적절한 API 인증 방식을 선택하도록 할 필요가 있다.
- API 키 방식
가장 기초적인 방법은 API 키를 이용하는 방법이다.
API 키(Key)란 특정 사용자만 알 수 있는 일종의 문자열이다.
API를 호출하고자 할 때, 개발자는 API 제공사의 포탈 페이지에서 API 키를 발급 받고 API를 호출 할 때 API 키를 메시지 안에 넣어 호출한다.
서버는 메시지 안에서 API 키를 읽어서 이 API를 누가 호출한 API인지를 인증하는 흐름이다.
모든 클라이언트가 같은 API 키를 공유하기 때문에, 한번 API 키가 노출되면 전체 API가 뚫려버리는 문제가 있으므로 높은 보안 인증이 필요할 때에는 권장하지 않는다.
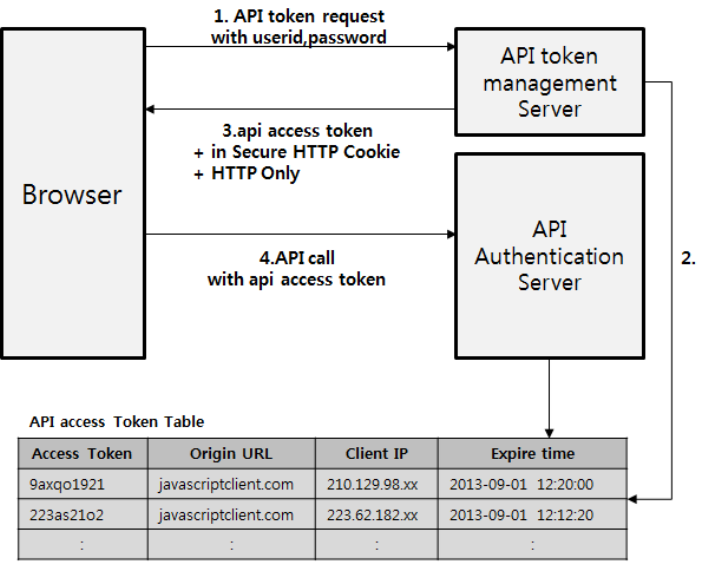
- API 토큰 방식은 아래와 같다
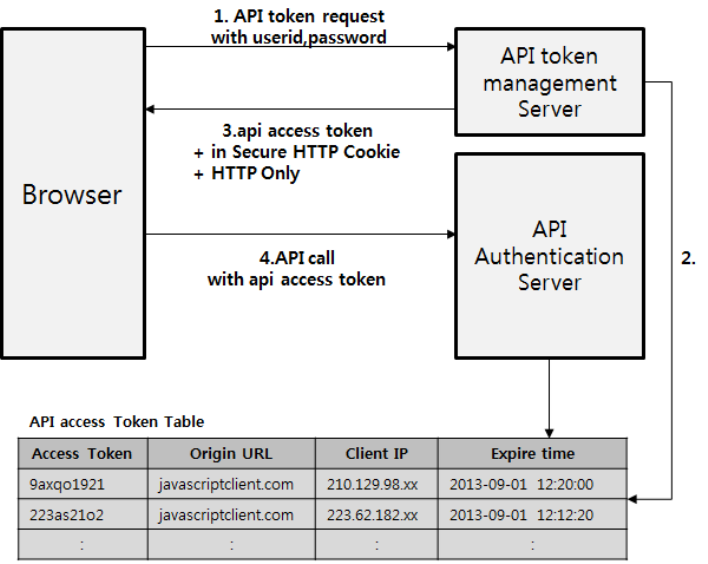
API 토큰(Token)을 발급하는 방식이 있는데, ID, 비빌번호 등으로 사용자를 인증한 다음에 그 사용자가 API 호출에 사용할 기간이 유효한 API 토큰을 발급해서 API 토큰으로 사용자를 인증하는 방식이다.
매번 API 호출 시 사용자 ID, 비밀번호를 보내지 않고 API 토큰을 사용하는 이유는 사용자 비밀번호는 주기적으로 바뀔 수 있기 때문이고, 매번 네트워크를 통해서 사용자 ID와 비밀번호를 보내는 것은 보안상 사용자 계정 정보를 탈취당할 가능성이 크기 때문에 API 토큰을 별도로 발급해서 사용하는 것이다.
API 토큰을 탈취당하면, API를 호출할 수는 있지만, 반대로 사용자 ID와 비밀번호는 탈취당하지 않는다.
사용자 비밀번호를 탈취당하면 일반적으로 사용자들은 다른 서비스에도 같은 비밀번호를 사용하는 경우가 많아서 연쇄적으로 공격을 당할 가능성이 커진다. 따라서 이러한 연쇄적인 피해를 최소화 할 수 있다.
위의 그림을 보면 다음과 같은 형태로 인증이 이루어진다.
1. API 클라이언트가 사용자 ID, 비밀번호를 보내서 API 호출을 위한 API 토큰을 요청한다.
2. API 인증 서버는 사용자 ID, 비밀번호를 바탕으로 사용자를 인증한다.
3. 인증된 사용자에 대해서 API 토큰을 발급한다 (유효시간을 가지고 있다.)
4. API 클라이언트는 이 API 토큰으로 API를 호출한다. API 서버는 API 토큰이 유효한지를 API 토큰 관리 서버에 문의하고 API 토큰이 유효하면 API 호출을 받아들인다.
- 클라이언트 인증 추가
추가적인 보안 강화를 위해서 사용자 인증 뿐만 아니라, 클라이언트 인증 방식을 추가할 수 있다.
페이스북은 API 토큰을 발급 받도록 사용자 ID, 비밀번호 뿐만 아니라, Client ID와 Client Secret이라는 것을 같이 입력받도록 하는데, Client ID는 특정 앱에 대한 등록 ID이고 Client Secret은 특정 앱에 대한 비밀번호로, 앱을 등록하면 앱 별로 발급되는 일종의 비밀번호이다.
API 토큰을 발급 받을 때, Client ID와 Client Secret을 이용하여 클라이언트 앱을 인증하고, 사용자 ID와 비밀번호를 추가적으로 받아서 사용자를 인증하여 API 액세스 토큰을 발급한다.
- IP 화이트 리스트를 이용한 터널링
만약 API를 호출하는 클라이언트의 API가 일정하다면 사용할 수 있는 손쉬운 방법인데, 서버 간의 통신이나 타사 서버와 자사 서버 간의 통신 같은 경우에 API 서버는 특정 API URL에 대해서 들어오는 IP 주소를 화이트 리스트로 유지하는 방법이 있다.
API 서버 앞단에 HAProxy나 Apache와 같은 웹 서버를 배치하여서 특정 URL로 들어올 수 있는 IP 목록을 제한하거나 아니면 전체 API가 특정 서버와의 통신에만 사용된다면 아예 하드웨어 방화벽 자체에 들어올 수 있는 IP 목록을 제한할 수 있다.
설정만으로 가능한 방법이기 때문에, 서버간의 통신이 있을 때 적용할 것을 권장한다.
- Bi-directional Certification (Mutual SSL)
보통은 HTTPS 통신을 할 때, 서버에 공인 인증서를 놓고 단방향으로 SSL을 제공하는데, Bi-directional Certification (양방향 인증서 방식) 방식은 클라이언트에도 인증서를 놓고 양방향으로 SSL을 제공하면서 API 호출에 대한 인증을 클라이언트의 인증서를 이용하는 방식이다.
구현 방법이 가장 복잡한 방식이기는 하지만, 공인 기관에서 발생된 인증서를 사용한다면 API를 호출하는 쪽의 신원을 확실하게 할 수 있고 메세지까지 암호화되기 때문에, 가장 높은 수준의 인증을 제공한다.
이런 인증 방식은 일반 서비스에서는 사용되지 않으며 높은 인증 수준을 제공하는 몇몇 서비스나 특정 서버 통신에 사용하는 것이 좋다.
- Claim 기반의 JWT 방식
- Claim 기반 토큰의 개념
OAuth에 의해서 발급되는 access_token은 랜덤 문자열로, 토큰 자체에는 특별한 정보를 가지고 있지 않은 일반적인 스트링 형태이다.
따라서 access_token을 통해서 사용자와 연관된 정보를 구별하여 이를 허용해주는 구조인데, 서버 입장에서는 토큰을 가지고 그 토큰과 연관된 정보를 서버 쪽에서 찾아야 한다.
하지만 JWT는 Claim 기반이라는 방식을 사용하는데, Claim은 사용자에 대한 프로퍼티나 속성을 말한다.
토큰 자체가 정보를 가지는 방식인데, JWT는 이 클레임을 JSON을 이용해서 정리한다.
이 토큰을 이용해서 요청을 받는 서버나 서비스 입장에서는 이 서비스를 호출한 사용자에 대한 추가 정보는 이미 토큰 안에 다 들어가 있기 때문에, 다른 곳에서 가져올 필요가 없다는 장점이 있다.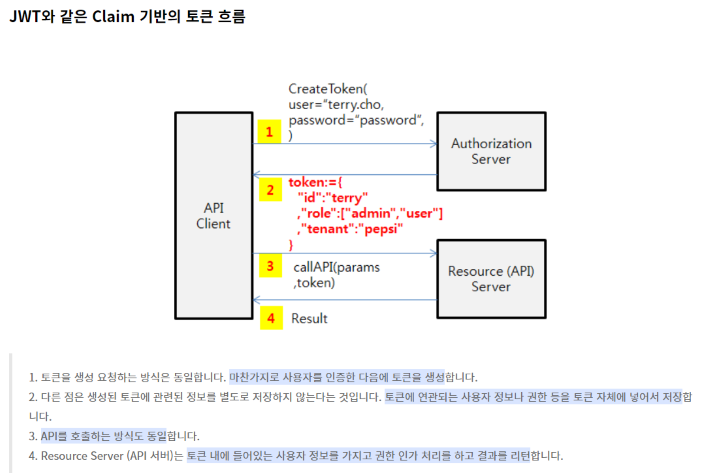
결과적으로 토큰을 생성하는 단계에서는 생성된 토큰을 별도로 서버에서 유지할 필요가 없으며, 토큰을 사용하는 API 서버 입장에서는 API 요청을 검증하기 위해서 토큰을 가지고 사용자 정보를 별도로 계정 시스템 등에서 조회할 필요가 없다는 것이다.
JWT는 이 JSON Claim을 Base64로 인코딩하여 HTTP 헤더에 쉽게 넣을 수 있으며, JSON 기반이기 때문에 파싱과 사용이 쉽다.
결과적으로 Claim 기반의 토큰은 토큰 자체가 정보를 담음으로써 토큰으로 서비스나 API 접근을 제어할 때, 별도의 작업이 서버에서 필요하지 않으며, 토큰 자체를 서버에서 관리할 필요가 없어서 구현이 상대적으로 단순해진다.
- JWT의 단점
길이 : Claim에 넣는 데이터가 많아질 수록 JWT 토큰의 길이가 길어진다. API 호출에 사용할 시에 호출마다 헤더에 붙어서 가야하기 때문에 길이가 길다는 것은 그만큼 네트워크 대역폭 낭비가 심하다는 것이다.
한번 발급된 토큰은 값을 수정하거나 폐기가 불가 : JWT는 토큰 내에 모든 정보를 다 가지고 있기 때문에 한 번 발급된 토큰에 대한 변경은 서버에서는 더는 불가능하다. 예를 들어서, 토큰을 잘못 발행해서 삭제하고 싶더라도 서명만 맞으면 맞는 토큰으로 인식하기 때문에 서버에서는 한번 발급된 토큰의 정보를 바꾸는 일이 불가능하다.
따라서 만약 JWT를 사용한다면 만료 시간(Expire Time)을 꼭 명시적으로 두도록 하고 Refresh Token등을 이용하여 중간마다 토큰을 재발행하도록 해야한다.
암호화 : JWT는 기본적으로 Claim에 대한 정보를 암호화하지 않는다, 단순히 Base64로 인코딩만 하기 때문에, 중간에 패킷을 가로채거나 기타 방법으로 토큰을 취득했으면 토큰 내부 정보를 통해서 사용자 정보가 노출될 가능성이 있다. 따라서 이를 보완하는 방법으로 토큰 자체를 암호화하는 방법이 있고, JSON을 암호화하기 위한 스펙으로는 JWE가 있다.API - REST**(로이 필딩의 논문 참조)
REST는 Representational State Transfer의 줄임말입니다. REST는 클라이언트가 서버 데이터에 액세스하는 데 사용할 수 있는 GET, PUT, DELETE 등의 함수 집합을 정의합니다. 클라이언트와 서버는 HTTP를 사용하여 데이터를 교환합니다.
REST API의 주된 특징은 무상태입니다. 무상태는 서버가 요청 간에 클라이언트 데이터를 저장하지 않음을 의미합니다. 서버에 대한 클라이언트 요청은 웹 사이트를 방문하기 위해 브라우저에 입력하는 URL과 유사합니다. 서버의 응답은 웹 페이지의 일반적인 그래픽 렌더링이 없는 일반 데이터입니다.
REST API는 다음과 같은 네 가지 주요 이점을 제공합니다.
통합
API는 새로운 애플리케이션을 기존 소프트웨어 시스템과 통합하는 데 사용됩니다. 그러면 각 기능을 처음부터 작성할 필요가 없기 때문에 개발 속도가 빨라집니다. API를 사용하여 기존 코드를 활용할 수 있습니다.
혁신
새로운 앱의 등장으로 전체 산업이 바뀔 수 있습니다. 기업은 신속하게 대응하고 혁신적인 서비스의 신속한 배포를 지원해야 합니다. 전체 코드를 다시 작성할 필요 없이 API 수준에서 변경하여 이를 수행할 수 있습니다.
확장
API는 기업이 다양한 플랫폼에서 고객의 요구 사항을 충족할 수 있는 고유한 기회를 제공합니다. 예를 들어 지도 API를 사용하면 웹 사이트, Android, iOS 등을 통해 지도 정보를 통합할 수 있습니다. 어느 기업이나 무료 또는 유료 API를 사용하여 내부 데이터베이스에 유사한 액세스 권한을 부여할 수 있습니다.
유지 관리의 용이성
API는 두 시스템 간의 게이트웨이 역할을 합니다. API가 영향을 받지 않도록 각 시스템은 내부적으로 변경해야 합니다. 이렇게 하면 한 시스템의 향후 코드 변경이 다른 시스템에 영향을 미치지 않습니다.API - JSON API
클라이언트가 ‘요청’을 보내고 서버가 ‘응답’을 하는 과정에서 데이터가 담길 수 있는데, 그 데이터에 넣을 수 있는 ‘기능’에는 여러 가지 형식이 있다. 이 형식을 표준화 하기 위해서 공통적인 형식을 채택해 사용한다. 구 중 하나인 ‘JSON’에 대하여 설명하겠다. 과거에는 ‘XML’이라는 형식이 널리 쓰였다.
JSON은 Douglas Croockford가 널리 퍼뜨린 Javascript 객체 문법을 따르는 문자기반의 데이터 포맷이다. JSON이 Javascript 객체 문법과 매우 유사하지만 딱히 Javascript가 아니더라도 JSON을 읽고 쓸 수 있는 기능이 다수의 프로그래밍 환경에서 제공된다.API - gRPC
이 서비스들 간의 소통 필요하다.
마이크로서비스 간의 교환되는 메시지 수는 엄청나게 많고 빠른 소통이 좋다
개발자는 핵심 로직구현만 집중하도록 하고 소통은 프레임워크에게 맡긴다.
gRPC = High-performance Open-source Feature-rich Framework
- originally developed by Google
- 지금은 Cloud Native Computing Foundation 파트 (CNCF - like 쿠버네티스)
- gRPC 메시지는 기본적으로 Protobuf(이진형식)로 인코딩 된다. -> 송수신 효율적이지만 사람이 못읽는다.
gRPC는 Protocol Buffers를 통해 클라이언트 코드와 서버 인터페이스 코드를 생성한다.
옵션에 따라 생성하는 언어 변경 가능하다.
하나의 proto 파일을 사용해서 go, python, java, swift 등 다양한 언어의 서버/클라이언트 코드를 생성할 수 있다.
gRPC 작동원리는 아래와 같다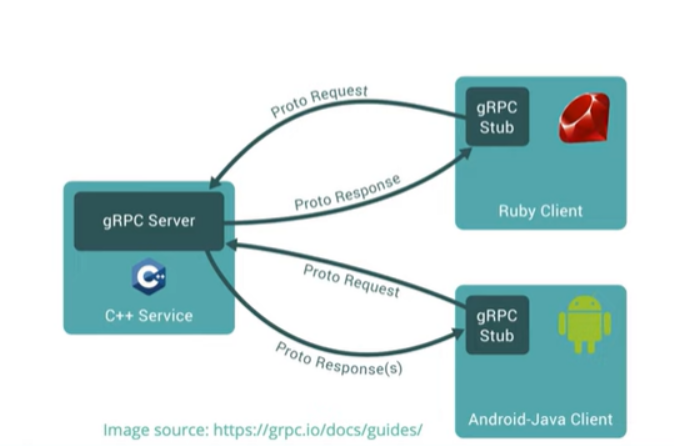
1. 클라이언트는 stub 생성 (서버랑 같은 메소드 제공)
2. stub는 gRPC 프레임워크를 호출 (내부 네트워크를 통해서 호출)
3. 클라이언트와 서버는 서로 상호작용을 위해 stubs 사용 >>> 서로의 코어 서비스 로직의 권한만 필요)
GRPC 한계
브라우저에서 gRPC 서비스 직접 호출이 불가능하다
- gRPC-Web 사용 (양방향 스트리밍 불가, 서버 스트리밍 제한적)
- RESTful JSON Web API에서 HTTP 메타데이터로 .proto 파일에 주석으로 gRPC 서비스 사용 (애플리케이션 = json web api, gRPC 둘다 지원)캐시 - CDN
1. CDN 설명 정리
https://www.phonesreview.co.uk/2017/09/01/content-delivery-network-cdn-works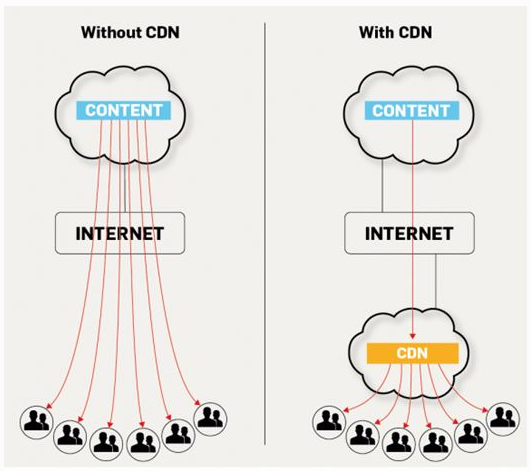
콘텐츠 전송 네트워크 ( CDN은 ) 분산 서버 (시스템입니다 네트워크 페이지 및 기타 웹 제공) 컨텐츠를 사용자, 웹 페이지의 원점과의 지리적 위치를 기반으로 사용자, 콘텐츠 전달 서버. … 또한 CDN 은 트래픽 급증으로부터 보호를 제공합니다.
비슷한 말로 CDN (Content Delivery Network)은 더 빠른 전송과 고 가용성 콘텐츠를 제공하는 것을 목적으로하는 전 세계적으로 분산 된 웹 서버 네트워크입니다. 콘텐츠는 CDN 전체에 복제되므로 한 번에 여러 위치에 존재합니다. 더 나은 성능 외에도 CDN은 콘텐츠 제공 업체의 원본 인프라에서 직접 제공되는 트래픽을 오프로드하여 콘텐츠 제공 업체의 비용을 절감 할 수 있습니다. 콘텐츠 전송 네트워크 (CDN)는 콘텐츠 전송을 담당하는 인터넷의 투명한 백본입니다. 우리가 알든 모르 든 우리 모두는 매일 CDN과 상호 작용합니다. 뉴스 사이트의 기사를 읽거나 온라인 쇼핑을하거나 YouTube 동영상을 보거나 소셜 미디어 피드를 읽을 때.
간단히 말해서 CDN의 목적은 사용자 경험을 개선하고보다 효율적인 네트워크 리소스 활용을 제공하는 것입니다. 미디어 회사 및 전자 상거래 공급 업체와 같은 콘텐츠 제공 업체는 CDN 운영자에게 콘텐츠를 청중, 즉 최종 사용자에게 제공하기 위해 비용을 지불합니다. 차례로 CDN은 데이터 센터에서 서버를 호스팅하기 위해 ISP, 통신사 및 네트워크 운영자에게 비용을 지불합니다.
고속 연결을 사용하는 사용자는 특히 라이브 이벤트를 볼 때 또는 호스팅 서버에서 멀리 떨어져있는 경우 끊김 현상, 로딩 지연 및 품질 저하를 경험합니다. CDN은 이미지 지터를 유발하는 지연 문제를 최소화하고 전송 속도를 최적화하며 각 뷰어에 대해 사용 가능한 대역폭을 최대화합니다.
2. CDN 의 핵심 (위치 와 cache)
CDN은 위치와 cache에 의해서 성능이 좌우된다.
CDN의 기능은 Nginx 로도 구현이 가능하다.
정적 파일은 S3 storage에 넣고 바니쉬나 redis로 캐시기능을 대처 할 수 있긴하다.
- dig (nslookup) = Domain Information Groper
- DNS
3. CDN 캐싱방식 (static, dynamic)
- Static Caching
사용자의 요청이 없어도 Origin Server에 있는 Content를 운영자가 미리 Cache Server에 복사함
따라서 사용자가 Cache Server에 접속하여 Content를 요청하면 무조건 그 Content는 Cache Server에 있음 (100% Cache Hit)
대부분의 국내 CDN에서 이 방식을 사용함 (예. Pooq 동영상 스트리밍/다운로드, NCSOFT 게임파일 다운로드 등)
- Dynamic Caching
최초 Cache Server에는 Content가 없음
사용자가 Content를 요청하면 해당 Content가 있는지 확인하고, 없으면(Cache Miss) Origin Server로 부터 다운로드 받아(Cache Fill) 사용자에게 전달해 줌
이후 동일 Content를 요청 받으면 저장(캐싱)된 Content를 사용자에게 전달(Cache Hit)
각 Content는 일정 시간(TTL)이 지나면 Cache Server에서 삭제될 수 있고, 혹은 Origin Server를 통해 Content Freshness 확인 후에 계속 가지고 있을 수 있음
Akamai, Amazon과 같은 Global CDN 업체, 그리고 Cisco나 ALU의 통신사업자향 CDN 장비 솔루션에서 이 방식을 지원함
- Route53 GEO location
client DNS로 구분해서 web서버 리다이렉트 기능 이다.
CDN에서 제공하는 기능은 아님 (중국만 호출됐을때 web 2번은 중국으로만 보낼수 있으니 트래픽 제어 가능)
web1 = deafult, web2 = 중국DNS만 호출
location : default => china 변경하면 성능개선
- cloudfront 압축(gzip)방식 적용
자바스크립트, css 위주로 하며 Nginx에서 처리도 가능하다.
최대 80% 페이지 로딩속도 개선, 비용개선, 데이터 전송비용 절감
https://aws.amazon.com/ko/blogs/korea/new-gzip-compression-support-for-amazon-cloudfront/캐시 - 서버사이드(Redis)
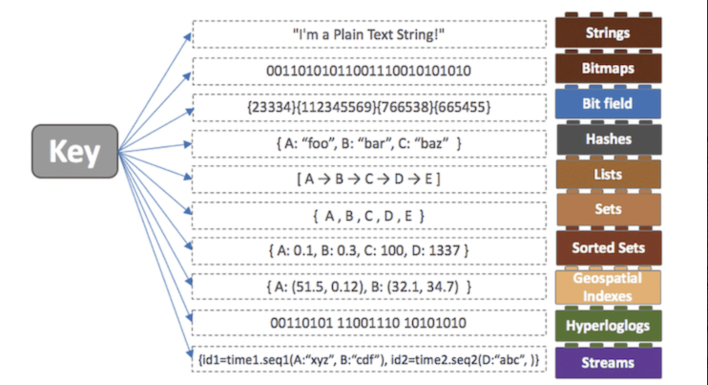
Key-Value 형태로 저장되는 NoSQL로, 인메모리 데이터베이스이다. 디스크가 아닌 컴퓨터의 주 메모리에 데이터를 저장하기 때문에 보다 빠른 데이터 검색이 가능하다.
특징
1. 다양한 자료구조 지원은 위의 그림과 같다
- String, Set, Sorted Set, Hash, List 등의 다양한 자료구조를 지원하여 개발 편의성이 좋아지고 난이도는 낮아진다.
2. 지속성 지원
- 디스크 없이 주 메모리에만 저장하는 Memcached 와는 달리 영속성 지원을 위해 데이터를 디스크에 저장할 수 있다. 따라서 서버가 내려가더라도 디스크에 저장된 데이터를 읽어서 메모리에 로딩한다. 디스크에 저장하는 방식은 순간적으로 메모리에 저장된 데이터 전체를 디스크에 저장하는 RDB(Snapshotting) 방식과 Redis의 Write/Update 연산을 모두 log파일에 기록하는 형태인 AOF(Append On File) 방식이 있다.
3. 읽기 성능 증대를 위한 서버 측 복제 지원
- Redis를 사용하는 서버가 충돌할 경우 전체 데이터베이스의 초기본을 복사받는 마스터/슬레이브 복제를 지원한다.
장점
- 데이터 입력/삭제가 MySQL 보다 10배 빠르다.
- 메모리를 활용하면서 데이터를 영속적으로 보존할 수 있다.
- 명시적으로 삭제 또는 expires를 설정하지 않으면 데이터가 삭제되지 않는다.
- 스냅샷 기능을 제공하여 메모리 내용을 .rdb 파일로 저장하여 특정 시점으로 복구할 수 있다.
- Master-Slave 형태로 여러개의 서버를 띄울 수 있어, 데이터 손실 위험성을 줄일 수 있다.
Master-Slave 구조
Redis 에서는 실행 중인 노드가 다운되더라도 실시간으로 다른 노드에 데이터를 복사하여 계속 서비스되도록 할 수 있다. 이러한 replication은 Master-Slave 구조로 구성할 수 있는데, 실제 운영 서비스에서는 노드가 물리적으로 다른 곳에 위치해있는 것을 권장한다.
Slave 노드가 실행될 서버의 redis.conf 파일을 아래와 같이 설정해주면 slave 노드를 구성할 수 있다.
# redis.conf
replicaof 127.0.0.1 7000 # replicaof <master ip> <master port>
repl-ping-replica-period
10repl-timeout 60
Master 노드에서 데이터를 추가하는 경우 Slave노드에서도 해당 데이터를 조회할 수 있으며, Slave 노드는 Read-Only 이기 때문에 데이터 생성 명령어를 실행할 경우 오류가 발생한다.
- Master 노드가 다운되었을 경우의 Slave 노드의 로그
-> Master 노드에 sync를 보내 연결을 시도. slave 노드에서는 데이터를 여전히 조회할 수 있음.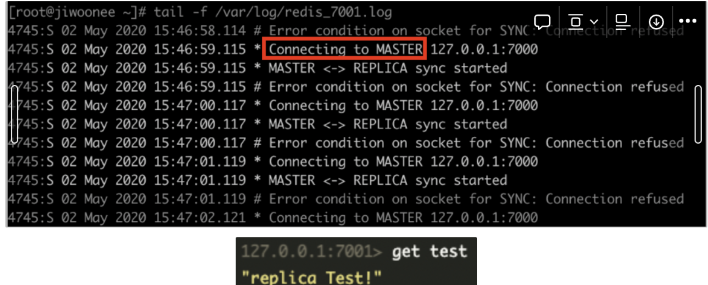
- Master 노드가 다시 살아났을 경우의 Slave 노드의 로그
-> Master 노드에 연결되어 복제를 계속함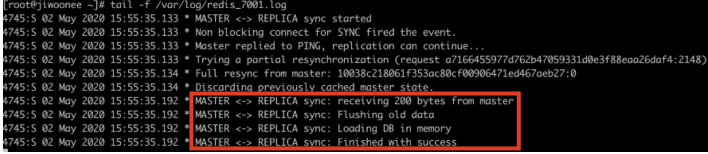
이렇게 Master-Slave 노드의 구조로 서비스 안정성을 높일 수 있다. 하지만 Slave 노드는 읽기 동작만 가능하기 때문에 제대로된 서비스를 보장하기 어렵다. 이런 상황을 위해 Slave 노드가 여러 개인 경우 그 중 하나를 Master 노드로 승격시킬 수 있다.
지속성
(1) RDB
주기적 스냅 방식인 snapshot 방식과 유사하며 쓰기 작업은 바이너리파일로 저장된다. 이 방식은 백업에 적합하며 하나의 rdb 파일을 Amazon S3와 같은 데이터 센터에 전송할 수 있다. 수동 또는 지정된 시간마다 실행시킬 수 있으며 데이터 손실이 발생할 때 복구된다. AOF보다 파일 크기가 작지만 로딩 속도는 더 빠르다.
생성 및 로드는 save , bgsave 명령어를 사용한다.
- save (동기화)
메인 프로세스가 RDB파일이 생성을 수행하며 파일 쓰기 작업동안에는 클라이언트의 명령을 수행할 수 없다.
예시)
# redis.conf
save 600 10 # 600초 동안 10번 이상 키 변경 발생 시 데이터베이스에 백업
- bgsave (비동기)
하위 프로세스가 백그라운드로 RDB 파일 생성을 실행하므로 RDB파일 쓰기 작업 중에도 레디스 서버는 클라이언트의 명령을 처리할 수 있다.
캐시 용도로만 쓸 경우 save 설정은 "" 로 해주는 것이 권장된다. stop-write-on-bgsave-error 를 비활성화 해주어야 한다. (yes인 경우 RDB파일 저장에 실패 시 Redis에 쓰기 작업을 할 수 없음)
(2) AOF
서버에서 실행되는 모든 명령을 추적하고 서버가 재부팅된 후 별도의 명령어 없이 로그를 기반으로 데이터베이스를 재구성한다. 입력/수정/삭제 명령이 실행될 때 기록된다. 로그가 쌓이는 것이기 때문에 파일 크기는 계속 커지며 파일 크기 제한에 따라 기록이 중단될 수 있고, 레디스 서버 시작 시 로드가 지연될 수 있다. 이 경우 파일 크기가 100 퍼센트 이상 커질 시 주기적으로 rewrite하여 크기를 줄여야한다.
보통 AOF를 기본으로, RDB를 부차적으로 사용하며 AOF 는 everysec마다 실행, rewrite를 사용한다. (다만 캐시용으로만 쓰이는 경우 appendonly는 비활성화 하는 것이 좋음) Master 노드 자동 재시작 시 AOF 없이 RDB 파일만 있는 경우 slave 노드도 마스터와 같이 몇분 전 RDB 파일의 데이터들을 받게 된다.
# redis.conf
appendonly yes # AOF 활성화. 해당 설정이 yes이면 aof 파일을 먼저 읽고 no이면 rdb 파일을 먼저 읽음. 해당 값이 yes이고 aof 파일이 없는 경우 rdb 파일을 읽지 않음.
appendfilename "appendonly.aof" # 파일명 지정. 경로는 지정 불가appendfsync # AOF 기록 시점
auto-aof-rewrite-percentage 100 # 파일 크기가 100프로 이상 커지면 rewrite 자동실행
auto-aof-rewrite-min-size 64mb # aof파일 크기가 64이하이면 rewrite 실행하지 않음캐시 - 클라이언트 사이드
HTTP 헤더를 통한 브라우저 캐싱 모든 브라우저는 HTML 페이지 자바스크립트 파일 및 이미지와 같은 웹 문서의 임시 저장을 위해 HTTP 캐시(웹 캐시)의 구현을 제공하고 있다. 이는 서버 응답이 올바른 HTTP 헤더 지시자를 제공하여 브라우저가 응답을 캐싱할 수 있는 시기와 지속 기간을 지시할 때 사용된다 장점
리소스가 로컬 캐시로부터 빠르게 로드되기 때문에 사용자 경험이 향상된다. 요청이 네트워크를 통해 전송되지 않기 때문에 왕복 시간(RTT, Round Trip Time)이 발생하지 않는다
애플리케이션 서버 및 파이프라인의 다른 구성 요소에 대한 부하가 줄어든다
불필요한 대역폭에 대한 지불 비용이 줄어든다
캐시 컨트롤
- https://developer.mozilla.org/ko/docs/Web/HTTP/Headers/Cache-Control
️캐시 - 활용
캐시 저장 방식 지침
- 자주 사용되며 변경 빈도가 낮은 데이터를 선정한다.
- In-memory DB인 만큼 언제든 데이터가 유실될 가능성이 있다는 것을 염두 (디스크에 저장함으로써 지속성을 유지할 수 있지만 캐싱을 위한 성능으로는 적합하지 않다. Replication을 할 경우 성능에 영향이 가지 않도록 어느정도 기간을 설정해야함으로 데이터 정합성도 깨질 우려 있다)
캐시 제거 방식 지침
- 캐시 데이터는 영구 저장소(e.g., 데이터베이스)의 데이터와 반드시 동기화 되어야 함 → 캐시 구성시 만료 정책 필요하다.
- 기간이 만료되면 캐시에서 삭제되고 영구 저장소에서 데이터를 읽어와 새로 저장한다.
- 만료 주기가 너무 짧으면 성능 저하, 너무 길면 데이터 정합성 문제 또는 메모리 부족 문제가 발생할 수 있다.
- 대규모 트래픽 환경에서 TTL이 너무 짧으면 cache stampede 현상이 일어날 수 있음. 여러 환경에서 특정 키를 조회하려는 순간 key의 만료시간이 지났다면 영구 저장소에 한꺼번에 데이터 조회 요청을 하며 duplicated read가 발생하게 되고, 조회한 데이터를 또 캐싱하는 duplicated write이 발생 → 성능 저하 및 요청 병목으로 서비스 장애로 이어질 가능성이다.
캐시 공유 방식 지침
- 캐시는 여러 인스턴스에서 공유하도록 설계되기 때문에 한 인스턴스가 수정한 데이터를 다른 인스턴스의 변경으로 덮어씌우지 않도록 해야함 → 데이터 정합성을 위한 확인 절차 필요하다.
- 캐시된 데이터 업데이트 직전에 데이터가 조회된 이후로 수정되지 않았는지 확인하거나 업데이트 전 Lock을 걸어 정합성을 유지한다.
- Lock을 거는 방식의 경우 조회 업무를 처리하는 프로세스에 대기열이 생기는 단점이 있음. 따라서 데이터 크기가 작아 빠르게 수정 가능하거나 빈번하게 수정이 일어나는 경우 적합하다.
- 업데이트 전 변경 여부를 확인하는 방식의 경우 업데이트가 드물고 충돌이 발생하지 않는 경우에 적합하다. 변경 여부 확인 후 변경되지 않았다면 즉시 수정, 변경 되었다면 변경 여부를 애플리케이션에서 결정하도록 해야한다.
캐시 가용성 방식 지침
- 캐싱은 데이터 조회 성능을 확보하기 위함이므로 데이터 영속성은 영구 저장소에 위임하는 것이 바람직하다.
- 또한 캐시 서버가 다운되거나 서비스가 불가능할 때도 전체 서비스에는 문제가 없어야 한다.
캐싱 전략
(1) 지연로딩 (Lazy Loading)
- 데이터 요청이 들어온 경우 캐시를 우선 확인하여 데이터가 있으면 반환하고 없으면 DB나 API에 접근하여 데이터를 가져와 캐싱하는 방법이다.
- 요청받은 데이터만 캐시에 저장하므로 효율성이 증대되며 캐싱되지 않은 데이터를 DB에서 가져오므로 cache miss에 치명적이지 않다.
- 캐시에 없는 데이터 조회 시 (1) 캐시 조회 (2) DB 조회 (3) 캐시에 저장 이 세 단계를 거치게 되므로 캐시 미스가 많이 발생할 수록 지연이 발생한다.
- 초기 데이터는 항상 캐시 미스가 발생한다는 점을 고려하여 미리 DB의 데이터를 캐시에 넣어주는 cache warming 작업이 필요하다.
- 읽기 작업이 많은 경우 적합하다.
(2) Read Through
- 데이터 조회 시 캐시만 조회하며 캐시 미스가 발생한 경우 DB에서 데이터를 가져와 캐싱. 지연로딩 방식과 비슷하지만 지연로딩은 캐시 미스 시 앱(서버)가 직접 DB를 조회하는 반면 Read Through는 캐시가 DB를 조회한다.
- 초기 데이터는 항상 캐시 미스가 발생하므로 cache warming 작업을 해주거나 DB에 데이터 저장 시 캐시에도 쿼리를 수행하도록 설정할 수 있다.
(3) Write Through
- 데이터 생성/수정 시 캐시와 DB에 모두 쓰기 작업을 한다.
- 데이터가 항상 최신 상태를 유지할 수 있다.
- 데이터 생성/수정 시 항상 캐시와 DB를 모두 히트하게 되므로 성능이 저하되고 사용되지 않는 데이터가 캐싱되므로 리소스 낭비가 발생한다.
- 새로운 노드가 발생할 경우 데이터를 찾지 못할 수 있다. (데이터가 최신 상태이므로 읽기 작업에서는 무조건 cache만 읽기 때문.)
- 데이터가 유실되면 안되는 경우에 적합하다.
(4) Write Around
- 데이터 생성/수정 요청이 들어오면 DB에만 저장하고 데이터가 읽힐 때에만 캐싱하는 전략이다.
- Lazy Loading 방식과 잘 쓰이는 쓰기 전략이다.
- Write Through 보다 속도가 빠르지만 데이터 저장 시 DB에만 저장하기 때문에 데이터 정합성 문제 발생한다.
- 데이터가 한번 쓰여지면 잘 읽히지 않는 실시간 로그 및 실시간 채팅의 경우 우수한 성능을 보인다.
- 데이터 최신성을 보장하기 위해서는 캐시 entry를 무효화하거나 더 적절한 쓰기 전략을 적용하는 것이 좋다.
(5) Write Back
- 데이터 Insert 작업이 많이 일어나는 경우 생성될 데이터를 캐시에만 저장해놓았다가 DB에 한꺼번에 쿼리를 실행하여 배치하기 위한 전략이다.
- 쓰기 작업이 빈번한 경우에 적합하다.
- 캐시를 해두었다가 한꺼번에 디스크에 저장하므로 데이터 유실 위험성이 있다.
- Read Through 방식과 결합하여 가장 최근에 업데이트 또는 조회된 데이터를 항상 캐시에서 활용할 수 있도록 하는 혼합형 워크로드에 적합하다.
TTL(Time-To-Live)
- 각 전략에 TTL을 적용하면 이점을 더 극대화할 수 있다.
- Key의 만료시간을 설정하여 만료시간이 지나면 자동으로 삭제한다.
- Lazy Loading: 만료시간이 되면 데이터가 삭제되어 캐시 미스 발생 → 데이터 최신 상태 유지 가능하다.
- Write Through: 업데이트 되지 않은 데이터를 자동 삭제하여 메모리 이득을 볼 수 있다.테스트 - 통합(integration) 테스트, 단위(unit) 테스트, 기능(functional) 테스트
- 유닛 테스트: 함수 하나하나와 같이 코드의 작은 부분을 테스트하는 것
- 통합 테스트: 서로 다른 시스템들의 상호작용이 잘 이루어 지는지 테스트하는 것
- 기능 테스트: 사용자와 어플리케이션의 상호작용이 원활하게 이루어지는지 테스트하는 것
슬라임이라는 몬스터가 있고 유저가 슬라임을 때려잡는 상황이다. 이때 다음과 같은 함수가 있다고 가정하자.
- 유저가 슬라임에게 달려가는 Move 함수
- 유저가 슬라임을 공격하는 Attack 함수
- 슬라임을 때려잡은 후 전리품을 수집하는 Gather 함수
유닛 테스트는 Move, Attack, Gather 함수가 잘 동작하는지 (여러 가지 입력 값을 줘봐서 제대로 된 출력 값이 나오는지)
함수 하나하나를 테스트를 하는 것에 비유할 수 있다.
통합 테스트는 유저가 슬라임을 때려잡고 전리품을 수집할 텐데 실제로 데이터베이스에 수집한 전리품이 잘 들어갔는지 테스트를 하는 것에 비유할 수 있다.
기능 테스트는 유저가 슬라임에게 달려가 슬라임을 때려잡고 전리품을 수집하는 하나의 과정이 제대로 수행되었는지 테스트하는 것에 비유할 수 있다.
유닛 테스트(Unit Test)
유닛 테스트는 전체 코드 중 작은 부분을 테스트하는 것이다. (예를 들어, 함수 하나하나 개별로 테스트 코드를 작성하는 것) 만약 테스트에 네트워크나 데이터베이스 같은 외부 리소스가 포함된다면 그것은 유닛 테스트가 아니다.
또한, 유닛 테스트는 매우 간단하고 명확하여야 한다.
기본적으로 테스트를 위한 입력 값을 주어서 그에 대한 함수의 출력 값이 정확 한지 아닌지를 판단하는 것이 유닛 테스트라 할 수 있다.
코드의 설계가 별로 좋지 못하다면 유닛 테스트를 작성하기도 어려워진다.
따라서 함수(메소드) 하나하나 테스트 코드를 작성하는 유닛 테스트는 좀 더 나은 코드를 만들 수 있도록 도와준다.
비유하자면, 유닛 테스트는 척추에 비유할 수 있다.
유닛 테스트를 사용한다면 좋은 코드를 디자인할 수 있을 뿐만 아니라 어떤 함수(메소드)에 변화가 생겼을 때 그 함수가 안전하게 수행되는지를 보장해주고 같은 함수(메소드)를 다른 종류의 테스트에서도 적용하기 쉽게 만들어 준다.
유닛 테스트는 빈번히 일어나는 버그를 막는데도 뛰어난 역할을 한다.
코드 일부분에 문제가 있을 경우 아무리 많이 문제 있는 부분을 수정하려 해도 수정한 부분의 코드가 또 문제를 일으키고.. 문제가 문제를 낳는 경우가 대부분이다.
이럴 때 버그가 있는지 없는지 체크하는 유닛 테스트를 만들어 둠으로써 이러한 문제를 쉽게 해결할 수 있다.
통합 테스트(Integration Teset), 기능 테스트(Functional Teset)는 이벤트의 흐름에 이상이 없는지 테스팅하는데 좋은 반면, 유닛 테스트는 어떠한 부분에 문제가 있고 고칠 부분이 어디인지 명확하게 해 줄 때 좋다.
정리하자면, 테스트 중심 개발(test-driven development) 일 때 유닛 테스트는 꼭 작성해야 하며, 코드의 디자인을 개선해주고 나중에 코드의 리팩토링이 필요할 때 어떤 부분을 완전히 분리할 필요 없이 깔끔하게 해 준다.
통합 테스트(Integration Test)
통합 테스트는 이름에서 의미하는 바와 같이 각각의 시스템들이 서로 어떻게 상호작용하고 제대로 작동하는지 테스트하는 것을 의미한다.
통합 테스트는 유닛 테스트와 비슷한데, 큰 차이점이 하나 있다. 유닛 테스트는 다른 컴포넌트들과 독립적인 반면 통합 테스트는 그렇지 않다.
예를 들자면 유닛 테스트에서 데이터베이스에 접근하는 코드는 실제 데이터 베이스와 통신하는 것은 아니지만, 통합 테스트는 실제 통신해야 한다.
통합 테스트는 유닛 테스트만으로 충분하다고 느끼지 못할 때 사용된다.
때때로 두 개의 다른 분리된 시스템끼리 잘 통신하고 있는지 증명하고 싶을 때가 있는데(예를 들어 나의 앱과 데이터 베이스가 제대로 상호작용하고 있는지...) 이것을 통합 테스트라 한다.
통합 테스트는 대게 유닛 테스트를 작성하는 것보다 복잡하고 오랜 시간이 걸린다. (데이터베이스를 세팅할 때, 설정 파일을 읽어 오는 과정이라던가 데이터베이스가 잘 세팅되었는지 확인하는 과정이라던가)
따라서 통합 테스트가 꼭 필요한 것이 아니면 유닛 테스트를 작성하는데 집중하는 것이 좋다.
기능 테스트(Functional Test)
기능 테스트는 E2E 테스트(E2E Test) 혹은 브라우저 테스트(Browser Test)라고 불리며 모두 같은 의미다.
기능 테스트는 어떤 어플리케이션이 제대로 동작하는지 완전한 기능을 테스트하는 것을 의미한다.
예를 들어, 어떤 웹 어플리케이션을 기능 테스트한다고 가정해보면 브라우저 자동화 도구를 사용해 특정한 페이지를 클릭한다던가 하는 것이 기능 테스트라 할 수 있다.
유닛 테스트를 사용하여 개별의 함수가 제대로 동작하는지 확인하고 통합 테스트를 통해 서로 다른 시스템이 잘 상호작용 하는지 확인할 수 있다.
기능 테스트는 이와 완전히 다른 레벨에 있다고 생각하면 된다.
유닛 테스트는 수백 가지가 있을 수 있지만 기능 테스트는 그렇지 못하다.
기능테스트는 작성하기 매우 어렵고 높은 복잡성을 가지고 있기 때문에 많은 시간이 걸린다. (웹 어플리케이션을 가정하면 기능 테스트는 실제 사용자 상호 작용을 시뮬레이션하므로 페이지 로딩 시간조차도 기능 테스트의 한 요인이 된다)
위와 같은 이유로 기능 테스트를 매우 세밀하게 나눠서 하면 좋지 못하다.
대신 기능 테스트는 사용자와 앱의 상호작용을 테스트하고 싶을 때 유용하다. (예를 들어, 회원 가입과 같이 브라우저에서 앱의 특정 흐름을 수동으로 테스트하는 경우)
회원 가입에 대한 기능 테스트라 하면 유저가 회원가입을 마치고 "저희 사이트에 회원 가입하게 된 것을 축하드립니다."라는 페이지를 올바르게 출력해줄 것을 보장해주어야 한다.CI/CD
사용자에게 우리가 만들어낸 프로젝트를 배포했는데 어떠한 동작이 올바르게 동작하지 않아 문제가 발생했다고 가정해보자.
개발자들에게는 비상이 걸릴 것이다. 급한 프로젝트일수록 더욱 빠르게 문제를 수정해야만 한다. 수정을 했으면 다시 컴파일, 빌드, 배포하는 과정을 통해 수정된 코드가 제대로 동작하는지 테스트하고 검증할 필요가 있다. 이 과정들은 시간도 많이 걸리고 실수하기도 쉽다.
수정된 코드에 문제가 다시 생기면 또 다시 과정을 반복해야한다. 이를 위해서 CI/CD가 생겨났다.
CI (Continuous Integration)
CI는 지속적 통합이라는 뜻으로 개발을 진행하면서도 품질을 관리할 수 있도록 하는 것으로 여러 명이 하나의 코드에 대해서 수정을 진행해도 지속적으로 통합하면서 관리할 수 있음을 의미한다.
CI가 나오기 전까지는 위와 같이 개발을 끝마치고 배포가 되어야만 코드에 오류는 없는지, 올바르게 동작하는지를 검증하며 코드 품질을 관리할 수 있었다.
CI를 적용하게 되면 각자의 개발자가 자신의 구현해야 할 기능을 구현하면 된다. 이후 완성이 되면 main 브랜치와 통합하고 코드가 잘 빌드되는지 보고, 올바르게 동작하는지 테스트하며 코드에 버그가 있다면 해결한다.
하지만 개발자가 직접 코드를 병합하고 빌드, 테스트를 검증하는 것은 시간이 많이 소요될 뿐만 아니라 귀찮고 그 양도 프로젝트의 크기가 커질수록 많아질 수밖에 없다.
이를 자동화하면 개발자가 빌드와 테스트를 직접 하지 않고도 수정한 코드를 브랜치에 병합하기만 하면 자동으로 빌드와 테스트를 검증할 수 있다.
개발자가 단위별로 구현한 부분을 병합할 때마다 자동화된 빌드와 테스트가 트리거되어 실행된다. 결과를 통해 우리는 어떤 부분에서 문제가 있는지 배포 전에 확인할 수 있고, 배포가 완성된 후에야 버그를 수정할 수 있던 기존의 문제를 빠르고 정확하게 해결할 수 있다.
결과적으로 버그를 신속하게 찾아 해결할 수 있을 뿐 아니라, 소프트웨어 품질을 개선하고 새로운 소프트웨어 업데이트를 검증하고 릴리즈하는데에 걸리는 시간을 단축할 수도 있다.
요약하자면 CI의 간단한 순서는 아래와 같다.
1. 개발자가 구현한 코드를 기존 코드와 병합한다.
2. 병합된 코드가 올바르게 동작하고 빌드되는지 검증한다.
3. 테스트 결과 문제가 있다면 수정하고 다시 1로 돌아간다. 문제가 없다면 배포를 진행한다.
CD(Continuous Deployment)
이제 지속적 통합을 거친 코드에 대해서 신뢰할 수 있고 바로 배포할 수 있다.
CD는 지속적 배포로 소프트웨어가 항상 신뢰 가능한 수준에서 배포될 수 있도록 관리하자는 개념으로 지속적 제공(Continuous Delivery)로 사용되기도 한다.
지속적 제공은 CI를 통해서 새로운 소스코드의 빌드와 테스트 병합까지 성공적으로 진행되었다면, 빌드와 테스트를 거쳐 github과 같은 저장소에 업로드하는 것을 의미한다.
지속적 배포는 이렇게 성공적으로 병합된 내역을 저장소뿐만 아니라 사용자가 사용할 수 있는 배포환경까지 릴리즈하는 것을 의미한다.
지속적 배포에서는 지속적 통합을 통해 빌드한 소스코드를 테스트 가능한 알파나 베타 버전으로 만든다. 이 버전에서 테스트를 수행해 문제가 발생하면 수정한 뒤 정식 버전으로 배포를 진행한다.
대표적인 CI/CD의 방법으로는 Travis와 Jenkins가 있다.
Jenkins 서버를 구축하는 순서에 대해서 알아보겠다.
Jenkins 구축하기
1. 자신의 서버에 알맞게 Jenkins를 설치한다.
2. 설치된 Jenkins에 접속해 기본적인 설정을 한다.
플러그인을 설치하고 user를 등록한다. 접속할 url도 지정한다.
3. Jenkins 관리에서 자신의 프로젝트에 알맞는 설정을 한다. 다양한 plugin을 추가할 수 있다.
4. 새로운 job을 추가해 Jenkins에게 부여하고 싶은 일을 지정한다. 여기서 다양한 파이프라인을 줄 수 있다.
개발 ‘ 설계 원칙 - SOLID
객체지향 설계 5원칙 SOLID
객체 지향 설계의 정수라고 할 수 있는 5원칙이 집대성됐는데, 바로 SOLID 이다.
• SRP(Single Responsibility Principle): 단일 책임 원칙
• OCP(Open Closed Priciple): 개방 폐쇄 원칙
• LSP(Listov Substitution Priciple): 리스코프 치환 원칙
• ISP(Interface Segregation Principle): 인터페이스 분리 원칙
• DIP(Dependency Inversion Principle): 의존 역전 원칙
각 원칙에 대해서는 정리가 잘 된 글을 보는게 좋다고 생각하여 링크를 올려놓았다.
SRP(Single Responsibility Principle): 단일 책임 원칙
OCP(Open Closed Priciple): 개방 폐쇄 원칙
LSP(Listov Substitution Priciple): 리스코프 치환 원칙
ISP(Interface Segregation Principle): 인터페이스 분리 원칙
DIP(Dependency Inversion Principle): 의존 역전 원칙
개발 설계 원칙 - SOLID
위에서 Jenkins 설명하면서 작성해놓았다.
개발 설계 원칙 - KISS
KISS 원칙은 "Keep It Simple Stupid!", "Keep It Short and Simple", "Keep It Small and Simple"의 첫 글자를 따서 만든 약어다.
이를 설명하자면, 소프트웨어를 설계하는 작업이나 코딩을 하는 행위에서 되도록이면 간단하고 단순하게 만드는 것이 좋다는 원리로 소스 코드나 설계 내용이 '불필요하게' 장황하거나 복잡해지는 것을 경계하라는 원칙이다.
단순할수록 이해하기 쉽고, 이해하기 쉬울수록 버그가 발생할 가능성이 줄어든다. 이는 곧 생산성 향상으로 연결된다. 작업이 불필요하게 복잡해지는 것을 항상 경계해야 한다.개발 * 설계 원칙 - YAGNI
YAGNI 원칙은 "You Ain't Gonna Need It"의 첫 글자를 따서 만든 약어다. 풀어쓰자면 "필요한 작업만 해라"이다.
프로그램을 작성하다 보면, 현재는 사용하지 않지만 확장성을 고려해서 미리 작업해 놓은 것들이 있다. 그런 작업들을 하지 말라는 원칙이다.
현재는 사용하지 않는, 미래 어느 시점에 사용될지도 모를 코드를 작성해놓으면 코드가 불필요하게 장황해진다.
게다가 설계나 환경이 변경되었을 때 수정해야 하는 코드의 양이 늘어나게 된다.
설계나 환경이 바뀌었는데 이렇게 미리 작업해 놓은 코드를 수정하지 않았다면? 나중에 그 코드에서 버그를 발생시킨다.
그러니 당장 필요한 작업에 집중하고 쓸데없는 작업은 하지 말라는 것이다.개발 * 설계 원칙 - DRY
DRY 원칙은 "Do not Repeat Yourself"의 첫 글자를 따서 만든 약어다. 풀어쓰자면, "반복하지 마라"다.
소스 코드에서 동일한 코드가 반복이 된다는 것은 잠재적인 버그의 위협을 증가시킨다.
반복되는 코드 내용이 변경될 필요가 있는 경우, 반복되는 모든 코드에 찾아가서 수정을 해야 한다.
이 과정에서 실수가 발생한다면 버그가 발생하게 된다.
프로젝트의 규모가 커질수록 반복되는 코드로 인한 유지 보수 오버헤드가 커진다.
때문에 작은 프로젝트라도 코드를 반복해서 사용하지 않는 습관이 중요하다.아키텍쳐 패턴 - 모놀리식 애플리케이션
모놀리식 아키텍처는 소프트웨어 프로그램의 전통적인 모델로, 자체 포함 방식이며 다른 애플리케이션과 독립적인 통합된 유닛으로 만들어진다. “모놀리스"라는 단어는 거대하고 빙하 같은 것을 의미하는 경우가 많은데, 소프트웨어 설계의 모놀리식 아키텍처도 크게 다르지 않다. 모놀리식 아키텍처는 모든 비즈니스 관련 사항을 함께 결합하는 하나의 코드 베이스를 갖춘 대규모의 단일 컴퓨팅 네트워크다. 이러한 종류의 애플리케이션을 변경하려면 코드 베이스에 액세스하고 서비스 측 인터페이스의 업데이트된 버전을 구축 및 배포하여 전체 스택을 업데이트해야 합니다. 이로 인해 업데이트에 제한이 많고 시간이 오래 걸린다.
프로젝트 초기에는 코드 관리, 인지 오버헤드 및 배포의 용이성 면에서 모놀리스가 편리할 수 있습니다. 모놀리스에서 모든 것을 한꺼번에 릴리스할 수 있기 때문이다.
모놀리식 아키텍처의 장점
다양한 요인에 따라, 조직에 모놀리식 아키텍처 또는 마이크로서비스 아키텍처가 도움이 될 수 있다. 모놀리식 아키텍처를 사용하여 개발하는 가장 큰 장점은 애플리케이션이 하나의 코드 베이스에 기반을 두어서 단순하기 때문에 개발 속도가 빠르다는 것이다.
모놀리식 아키텍처의 장점에는 다음이 포함된다.
손쉬운 배포 – 실행 파일 또는 디렉토리가 하나여서 배포가 더 쉽다.
개발 – 하나의 코드 베이스로 애플리케이션을 구축하여 개발이 더 쉽다.
성능 – 중앙 집중식 코드 베이스 및 리포지토리에서는 대부분 하나의 API만으로 마이크로서비스에서 여러 API가 수행하는 것과 동일한 기능을 수행할 수 있다.
테스트 간소화 – 모놀리식 애플리케이션은 하나의 중앙 집중식 장치이므로 분산된 애플리케이션보다 엔드투엔드 테스트를 더 빠르게 수행할 수 있다.
간편한 디버깅 – 모든 코드가 한 곳에 있으므로 요청을 따라가서 문제를 찾기가 더 쉽습니다.
모놀리식 아키텍처의 단점
Netflix의 경우에서 볼 수 있듯이, 모놀리식 애플리케이션은 규모가 너무 커지고 확장이 어려워지면 더 이상 효과적이지 않습니다. 하나의 기능을 조금만 변경하려고 해도 전체 플랫폼을 컴파일하고 테스트해야 하기 때문에, 오늘날의 개발자들이 선호하는 애자일 접근 방식과 맞지 않습니다.
모놀리식 아키텍처의 단점에는 다음이 포함됩니다.
느린 개발 속도 – 대규모 모놀리식 애플리케이션에서는 개발이 더욱 복잡해지고 속도가 느려진다.
확장성 – 개별 컴포넌트를 확장할 수 없다.
안정성 – 모듈에 오류가 있으면 애플리케이션 전체의 가용성에 영향을 줄 수 있다.
|기술 채택의 장벽 – 프레임워크 또는 언어를 변경하면 애플리케이션 전체에 영향을 미치므로 변경 시 비용과 시간이 많이 소요되는 경우가 많다.
유연성 부족 – 모놀리스의 경우 모놀리스에서 이미 사용한 기술로 제한된다.
배포 – 모놀리식 애플리케이션을 약간만 변경하는 경우에도 전체 모놀리스를 다시 배포해야 한다.아키텍쳐 패턴 - 마이크로서비스
간단하게 마이크로서비스라고도 하는 마이크로서비스 아키텍처는 독립적으로 배포 가능한 일련의 서비스를 이용하는 아키텍처 방법이다. 이러한 서비스에는 특정한 목표를 가진 자체 비즈니스 로직 및 데이터베이스가 있다. 업데이트, 테스트, 배포 및 확장은 각 서비스 내에서 이루어진다. 마이크로서비스는 주요 비즈니스, 도메인별 문제를 별도의 독립적인 코드 베이스로 분리한다. 마이크로서비스는 복잡성을 줄여주지는 않지만, 작업이 서로 독립적으로 작동하고 전체에 기여하는 더 작은 프로세스로 분리하여 복잡성을 눈으로 볼 수 있고 관리하기 쉽도록 만든다.
마이크로서비스 채택은 팀이 사용자 요구 사항에 빠르게 적응할 수 있도록 하는 지속적 배포 관행의 기반이기 때문에 DevOps 채택과 함께 이루어지는 경우가 많다
마이크로서비스로 마이그레이션하는 Atlassian의 여정
Atlassian은 Jira와 Confluence의 성장 및 확장과 관련된 문제에 직면한 후 2018년에 마이크로서비스로 경로를 변경했다. 온프레미스에서 실행하는 단일 테넌트, 모놀리식 아키텍처는 미래의 요구 사항에 맞춰 확장할 수 없다는 것을 알게 되었다.
Atlassian은 Jira와 Confluence를 다시 설계하여 상태 저장(Stateful) 단일 테넌트 모놀리식 시스템을 Amazon Web Services(AWS)에서 호스팅하는 다중 테넌트 상태 비저장(Stateless) 클라우드 애플리케이션으로 전환하기로 결정했다. 그런 다음 시간에 걸쳐 마이크로서비스로 나눈다. “정말 마음에 드는 아이디어지만 현기증(Vertigo)이 납니다.”라는 한 선임 엔지니어의 언급에 따라서 이 프로젝트의 이름은 Vertigo가 되었다. AWS로의 전환을 완료하는 데 2년이 걸리고 서비스 중단 없이 10개월 만에 10만 명 이상의 고객을 마이그레이션한 현재까지 가장 큰 규모의 인프라 프로젝트였다. 또한 서비스를 마이크로서비스로 나누기 위해 노력했다.
마이크로서비스의 장점
마이크로서비스는 특효약은 아니지만, 성장하는 소프트웨어와 회사의 여러 문제를 해결한다. 마이크로서비스 아키텍처는 독립적으로 실행하는 유닛으로 구성되므로, 다른 서비스에 영향을 주는 일 없이 각 서비스를 개발, 업데이트, 배포 및 확장할 수 있다. 향상된 안정성, 가동 시간 및 성능으로 소프트웨어 업데이트를 더 자주 수행할 수 있다. 이전에는 업데이트를 일주일에 한 번 수행했다면 나중에는 하루에 두세 번까지 진행할 수 있게 되었다.
Atlassian이 성장함에 따라, 마이크로서비스를 통해 서비스 소유권의 라인을 따라 분할하여 팀과 지리적 위치를 더 안정적으로 확장할 수 있다. Vertigo를 시작하기 전에 Atlassian은 전 세계에서 5개의 개발 센터를 운영했다. 이러한 분산된 팀은 중앙 집중식 모놀리스에 의해 제약을 받았으며 Atlassian에서는 이들을 자율적인 방식으로 지원해야 했으며 마이크로서비스를 통해 가능했다.
Vertigo의 장점에는 배포 속도 향상, 재해 복구, 비용 절감 및 성능 개선이 포함된다. 이를 통해 목표에 더 빨리 도달하는 동시에 고객에게 더 많은 가치를 제공할 수 있다.
또한 일반적으로 마이크로서비스를 사용하면 CI/CD(지속적 통합 및 지속적 배포)를 통해 팀이 코드를 더 쉽게 업데이트하고 릴리스 주기를 가속화할 수 있다. 팀에서 코드를 실험해 보고 문제가 발생하면 롤백할 수 있다.
간단히 설명하면 마이크로서비스의 장점은 다음과 같다.
애질리티 – 배포가 잦은 소규모 팀에서 애자일 작업 방식을 유도한다.
유연한 확장 – 마이크로서비스가 부하 용량에 도달하면 해당 서비스의 새 인스턴스를 포함하는 클러스터에 신속하게 배포하여 부담을 완화할 수 있습니다. 이제 여러 인스턴스에 고객이 분산되어 있는 다중 테넌트 및 상태 비저장(stateless)이 되었으며 훨씬 더 큰 크기의 인스턴스를 지원할 수 있다.
지속적 배포 – 이제 더 자주 릴리스하고 릴리스 주기가 빨라졌습니다. 이전에는 업데이트를 일주일에 한 번 수행했다면 나중에는 하루에 두세 번 정도까지도 수행할 수 있게 되었다.
높은 유지 관리성 및 테스트 편의성 – 팀에서 새로운 기능을 실험해 보고 문제가 발생하면 롤백할 수 있습니다. 따라서 코드를 보다 쉽게 업데이트하고 새로운 기능의 시장 출시 시간을 단축할 수 있습니다. 또한 개별 서비스의 결함과 버그를 쉽게 격리하고 해결할 수 있다.
독립적 배포 가능 – 마이크로서비스는 개별적인 유닛이므로 개별 기능을 빠르고 쉽게 독립적으로 배포할 수 있다.
기술 유연성 – 마이크로서비스 아키텍처를 사용하면 팀에서 원하는 도구를 자유롭게 선택할 수 있다.
높은 안정성 – 전체 애플리케이션이 중단될 위험 없이 특정 서비스에 대한 변경 사항을 배포할 수 있다.
팀의 만족도 향상 – 마이크로서비스를 사용하는 Atlassian 팀은 더 자율적이며 풀리퀘스트가 승인될 때까지 몇 주씩 기다리지 않고도 직접 구축 및 배포할 수 있기 때문에 훨씬 더 만족도가 높다.
마이크로서비스의 단점
소수의 모놀리식 코드 베이스에서 제품을 작동하는 더 많은 분산 시스템 및 서비스로 전환했을 때 의도하지 않은 복잡성이 발생했다. 처음에는 과거와 동일한 속도와 확신을 가지고 새로운 기능을 추가하는 데 어려움을 겪었다. 마이크로서비스는 복잡성을 증가시켜 무분별한 개발 확장 또는 관리되지 않는 급속한 성장으로 이어질 수 있습니다. 서로 다른 컴포넌트가 서로 어떻게 관련되어 있는지, 특정 소프트웨어 컴포넌트를 누가 소유하고 있는지, 또는 종속 컴포넌트를 방해하지 않으려면 어떻게 할지 판단하기가 어려울 수 있다.
Atlassian은 Vertigo를 통해 기존에 가지고 있던 제품과 앞으로 인수할 제품 및 만들 제품 모두를 지원할 공통의 기능을 구축했다. 제품이 하나인 회사의 경우 마이크로서비스가 필요하지 않을 수 있다.
마이크로서비스의 단점에는 다음이 포함됩니다.
무분별한 개발 확산 – 마이크로서비스의 경우 여러 팀이 더 많은 장소에 더 많은 서비스를 만들기 때문에 모놀리스 아키텍처에 비해 더 복잡해진다. 무분별한 개발 확산이 적절하게 관리되지 않으면 개발 속도가 느려지고 운영 성능이 저하되는 결과가 나타난다.
기하급수적인 인프라 비용 – 각각의 새 마이크로서비스는 테스트 도구, 배포 플레이북, 호스팅 인프라, 모니터링 도구 등에 대한 자체적인 비용이 발생할 수 있다.
조직 오버헤드 추가 – 팀에서는 업데이트 및 인터페이스를 조정하기 위해 또 다른 커뮤니케이션과 공동 작업이 이루어져야 한다.
디버깅 문제 – 각 마이크로서비스는 자체적인 로그 집합을 가지고 있어 디버깅이 더 복잡합니다. 또한 여러 시스템에서 하나의 비즈니스 프로세스가 실행될 수 있으므로 디버깅이 더욱 복잡해진다.
표준화 부족 – 공통 플랫폼이 없어 여러 언어, 로깅 표준 및 모니터링이 사용될 수 있다.
명확한 소유권 부족 – 더 많은 서비스가 도입됨에 따라 서비스를 실행하는 팀의 수도 늘어납니다. 시간이 지나면서 팀에서 어떤 서비스를 활용할 수 있는지, 그리고 지원을 받으려면 누구에게 문의해야 하는지 파악하기가 어려워진다.
아키텍쳐 패턴 - SOA
SOA란 Service Oriented Architecture의 약자로서, 이를 해석하면 서비스 지향 아키텍쳐를 의미한다.
기존의 애플리케이션의 기능들을 비지니스적인 의미를 가지는 기능 단위로 묶어서 표준화된 호출 인터페이스를 통해 서비스로 구현하고, 이 서비스들을 기업의 업무에 따라 어플리케이션을 구성하는 소프트웨어 개발 아키텍처를 의미한다.
왜 SOA가 주목 받나요?
• 웹 서비스의 등장으로 인해 다양한 기술적 복합도를 낮출 수 있게되어, 기술적인 대안이 등장하였다.
• 점점 확장되는 독립된 업무 시스템으로 인해 통합에 대한 필요가 생겼다.
• 기업의 비지니스 속도가 빨라져서 민첩한 대응이 필요해졌다.
SOA의 기본적인 개념
서비스란?
서비스란 플랫폼에 종속되지 않는 표준 인터페이스를 통해 비지니스적인 의미를 가지는 기능들을 모아놓은 소프트웨어 컴포넌트를 의미한다.
ex. 임직원 정보 서비스, 계좌이체 서비스, 상품 주문 서비스
일반적으로 SOA에서 정의하는 서비스는 비지니스 서비스를 의미한다.
그 외의 서비스로는 Intermediary 서비스나 Process Centrix 서비스, Application 서비스, Public Enterprise 서비스 등이 있다.
SOA의 단계적 발전 구조.
SOA는 시스템의 규모와 업무적 요구 사항에 따라 3단계 순서로 발전된다.
Fundamental SOA
기존 시스템들을 서비스화하여, 각 시스템들을 통합하는 단계이다.
- 서비스화와 통합이 중점 전체를 한 시스템화한다.
- 서비스에 대한 조합은, Front End에서 담당한다.
- 비지니스 서비스와 Application서비스로만 구성된다.
Networked SOA
Fundamental SOA의 문제점
- 시스템의 크기가 증가됨에 따라 서비스와 Front-End 사이에 연결이 복잡해진다.
- 시스템의 유연성이 떨어진다.
- 관리 및 중앙 통제가 어렵습니다.
이러한 단점을 해결하기 위해 Networked SOA는 아래의 특징을 가지고 있다.
- SOA 시스템의 가운데 서비스 허브를 둬서 서비스의 중앙 통제력 및 유연성을 강화한다.
- Intermediary 서비스가 ESB(라우팅, 변환, 로깅, 서비스 통제 등)에 위치한다.
Process Oriented SOA
기존에 Networked SOA에서 발전한 단계이다.
- 비지니스 플로우(Business Flow)가 있을 경우에만 적용된다.
- 서비스의 조합을 통한 업무의 구현을 BPM을 이용한다.
- 업무 변화에 민첩하게 반응한다. (Agile 가능)
- 기술조직과 비지니스 조직간의 의사 소통이 원할하다.
다른 아키텍처와 비교
Monolithic 보다 나은점
- 출시 일정 단축 및 유연성이 향상된다.
- 신규 시장에서 레거시 인프라를 활용가능하다.
- 더 효율적인 애자일 개발 방식으로 비용을 아낄 수 있다.
- 손쉽게 유지관리한다.
- 확정성을 가지고 있다.
- 안정성이 강화된다.
- 편리한 이용이 가능하다.아키텍쳐 패턴 - 서버리스
서버리스란?
- 서버가 필요 없다는 뜻은 아니다! 클라우드상에 서버는 존재한다.
- 하지만 고객이 스스로 관리해야 하는 서버나 컨테이너가 거의 없다.
- 이벤트(트리거)에 따라 동작하는 나노 수준의 함수로 구성된다.
- 이 함수의 코드만 집중해 개발하고, 바로 배포한다.
- 프로젝트를 여러개의 함수로 쪼개, 분산된 컴퓨팅 자원에 이 함수를 등록하고, 실행 횟수에 따라 비용을 낸다
- Amazon API Gateway + AWS Lambda + AWS 기존 서비스
- AWS의 서비스 철학과 잘 맞다.
- 최소 단위의 다양한 서비스들을 자유롭게 끼워맞춰, 새로운 아키텍처를 설계, 구성하도록 하는 것이다.
- 팀 와그너 (AWSLambda 서비스 개발 총괄)의 서버리스 선언문*(Serverless Menifesto)
- 함수(Function)가 서비스의 기본 배포 및 확장 단위이다.
- 프로그래밍 모델에서 물리 서버, 가상 서버 및 콘테이너에 대한 의존성을 제거하라
- 데이터 스토리지는 어딘가 무제한으로 있다고(사용한다고) 가정하라
- 사용자가 아닌 오로지 요청(Request)에 대해서만 확장하라
- 요청이 없는데 돈을 낼 필요가 없다(가상 서버나 콘테이너도 여전히 비효율적이다).
- 함수의 실행은 어디서나 가능하므로, 장애 복원력을 가지도록 만들어라
- BYOC(Bring your own code) ?나만의 서비스를 책임지고 만들 수 있다.
- 통계 수집 및 로그 취득은 보편적인 필수 사항이다.
서버리스의 장단점
장점
- 비용 : 필요할 때만 함수를 호출하고, 그만큼만 비용이 드므로 절약된다.
- 인프라 관리 : 인프라 구성 및 보안 등 신경써야 할 것이 줄어든다.
- 확장성 : 확장을 위해 AWS Auto Scaling같은 기술도 필요 없다. 그냥 많이 쓰면 확장
단점
- 자원의 제한 : 메모리와 처리 시간에 한계가 있다.
- 로컬 데이터 사용 불가능 : 함수들은 stateless하므로 로컬 데이터를 사용할 수 없다.
- 불편함 : 디버깅이나 테스팅에 불편함이 있다.
사용 사례
- 크롤러 : 주기적으로 페이지를 긁는 일
- 파일 처리 : 업로드와 함께 화질이나 사이즈 조정 (내가 할 일!)
- 로그 분석 및 처리, 실시간 모니터링
- 자동화 작업 등등
검색 엔진 - Elasticsearch
Elastic Searh
- 고가용성의 확장 가능한 오픈소스
- 검색엔진
- 분석엔진
- (no-sql 처럼 사용 가능)
Elastic Search가 무엇이냐 하면 크게 위와같은 4가지 특징으로 들 수 있을 것 같다.
사용 용도에 따라 다르겠지만 크게는 2가지 넓게 바라보면 3가지 정도로 쓰이는 것 같다.
+ 참고로 고가용성 (HA : High Availability)이란?
" 서버, 프로그램등의 정보시스템이 상당히 오랜 기간 동안 지속적으로 정상 운영이 가능한 성질을 의미한다. "
라고 wikipedia에 나와있지만 쉽게말해서 프로그램이 정상적으로 고장안 나고 오래 운영(사용) 되는것이 고가용성이라고 이해하면 좋을 것 같다.
검색엔진으로 사용되는 Elastic Search
검색엔진으로 사용되는 ES(Elastic Search)를 알려면 먼저 Lucene(루씬)을 알아야한다.
루씬 기반으로 개발 된 서비스이기에 Lucene과 ES 각각의 큰 특징들을 알아보겠다.
Lucene (루씬)
- Java 언어로 이뤄짐
- Apache 재단 검색엔진 상위 프로젝트
- Doug Cutting (하둡 창시자)에 의해 개발
- Apache 라이센스 배포
Elastic Search (엘라스틱 서치)
- Shay Banon이 Lucene기반으로 개발
- 똑같이 Java 언어로 이뤄짐
- Apache 2.0 라이센스 의거
- HTTP Web 인터페이스 지원
- Json 형태의 도큐먼트 지원
- 준 실시간 분산형 검색엔진
분석엔진으로 사용되는 Elastic Search
분석엔진으로 사용되는 ES를 사용하려면 몇가지 솔루션 추가로 분석 엔진으로 사용이 가능하다. 이 몇가지 솔루션이 추가된 구조(스택)을 ELK라고 칭한다.
로그 분석를 위해 다음과 같은 ELK(Elastic, LogStash, Kibana) 스택이 사용된다.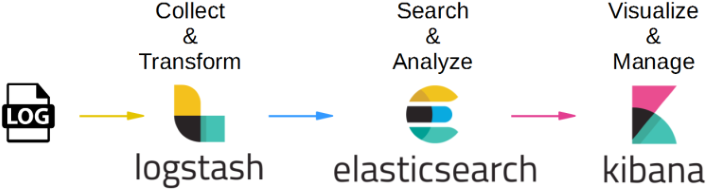
ELK stack - beats 없는 elk 그림:(
- Beats (비츠) = 로그를 Elastic나 LogStash로 전달
- 여러 (로그, 데이터)종류에 따라 각각의 Beats 존재
- 로그나 데이터 수집 용도
- Log Stash (로그 스태쉬) = 로그를 수집 파싱이나 필터링 기능 수행
- 때에 따라 데이터 수집 용도로 쓰일 수 있음
- 필터링 기능
- eg. 필터링 = 비정형화된 데이터들을 정형화 (=통일성 없는 데이터들을 통일성 있게)
- Elastic Search (엘라스틱 서치) = 검색, 분석을 할 수 있도록 Analyze를 거쳐 데이터 저장
- 정형화된 데이터 저장
- Kibana (키바나) = 저장(수집)된 ElasticSearch 데이터를 통계/집계해 시각화 제공
- 시각화 Tool
- 모니터링 가능한 대시보드 UI 제공
NO-SQL 처럼 사용가능 한 Elastic Search
다음 포스팅에 자세히 얘기할 예정인데 가볍게 말하자면 ES에는 저장되는 데이터 단위가 문서(doc)단위로 저장된다. (cf. RDB로 말하면 한 행(row))
ES를 문서를 추가(indexing)할 때 id를 자동 or 수동으로 설정할수있는데
이 때 id를 수동으로 사용자가 지정할 경우 No-SQL처럼 사용할 수 있다라는 뜻이다.
하지만 Elastic Search에서 말하는 색인(indexing) 최적화를 위해선
id를 수동(PUT)으로 인덱싱하는것 보다 자동(POST)로 생성하는것을 권고 라고 한다.
수동으로 id를 넣어 인덱싱 할 경우
해당 id의 문서가 있는지 먼저 체크를 하기에 문서가 많아지면 많아 질 수록 부하가 커진다.메시지 브로커 - RabbitMQ
RabbitMQ
"RabbitMQ는 메시지 브로커" 이다. 분산 소프트웨어 아키텍처를 만들기 위해 사용한다.
RabbitMQ 장점
1. 다양한 클라이언트 라이브러리를 제공한다.
다수의 프로그래밍 언어와 플랫폼에서 클라이언트 라이브러리가 제공된다.
서로 다른 언어와 운영체제 환경에 RabbitMQ 메시지 브로커를 이용하여 데이터를 공유할 수 있다.
2. 유연한 성능과 안정성 절충이 가능하다.
메시지 디스크 저장 설정도 할 수 있어 메시지 영속성을 보장할 수 있다.
클러스터를 설정할 때는 큐를 고가용성으로 설정하여 메시지를 여러 노드에 저장하면 일부 서버 장애로 메시지가 손실되지 않도록 처리할 수 있다.
3. 경량성
관리자 UI 플러그인과 코어 애플리케이션을 구동하는데 40MB 미만의 메모리를 사용합니다.
다만, 큐에 전송되는 메시지양이 증가하면 메모리 사용량은 증가된다.
4. 대기 시간이 긴 네트워크를 위한 플러그인
대기 시간이 짧은 네트환경에서는 기본 코어 모듈에서 제공한다
반면 인터넷과 같이 대기 시간이 긴 네트워크 간의 메시지 전달은 플러그인을 제공한다
5. 보안계층
RabbitMQ는 보안계층을 여러 단계로 제공한다
클라이언트 접속 인증은 SSL로 제한한다
가상 호스트로 사용자 접근을 관리하여 메시지와 리소스(메모리 등)를 고수준으로 격리하여 처리하고 있다.
RabbitMQ와 얼랭
RabbitMQ가 만들어진 근간에는 얼랭 이라는 언어가 있다.
RabbitMQ는 함수형 프로그래밍 언어 얼랭으로 작성되었다 .
얼랭은 99.99% 가동 시간을 요구하는 애플리케이션을 위해 설계 되었다.
얼랭은 실시간 시스템에서 경량 프로세스(Light Weight Process) 간에 메시지를 전달하고 공유하는 상태가 없도록 설계돼 있어 높은 수준의 동시성(서로 다른 작업이 같은 시간에 동시에 처리)을 제공한다.
메시지 브로커 애플리케이션
동시에 다수의 연결을 관리하고 메시지를 라우팅(최적의 경로로 데이터를 전송)하며
메시지 브로커 자신의 상태를 관리한다.
얼랭의 분산 아키텍처는 RabbitMQ의 클러스터링 메커니즘을 자연스럽게 구현할 수 있다.
RabbitMQ는 얼랭의 프로세스 간 통신(IPC) 시스템을 사용하여 클러스터링 기능을 간단하게 구현하였다.
클러스터
데이터 집단을 정의하고 집단을 대표하는 대표점을 의미한다.
IPC (Inter-process Communication)
프로세스들 사이에 데이터를 주고 받는 행위, 경로, 방법을 의미한다.
RabbitMQ 클러스터는 아래와 같다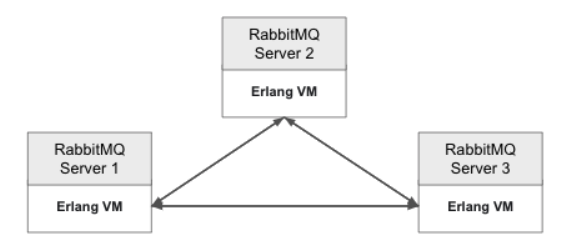
RabbitMQ 클러스터는 얼랭 VM의 네이티브 IPC 메커니즘을 사용하여 노드 간 상태 정보를 공유하며 전체 클러스터 간에 메시지를 생산하고 소비한다.
Erlang VM 간 화살표의 의미
얼랭(Erlang VM)의 IPC 시스템을 사용하여 통신한다.
얼랭 IPC 시스템를 사용하여 메시지, 상태, 설정을 공유하며 각 서버를 동기화 한다.
얼랭 IPC 시스템은 TCP/IP를 사용하여 RabbitMQ 서버 간 통신을 처리한다.
"Erlang 환경에 익숙하지 않다면 진입 장벽이 될 수 있습니다.
운영 중에 설정 파일 관리, RabbitMQ 런타임 상태 정보 수집 방법에 대해 익히는 연습을 하면 좋습니다"
Rabbitmq in depth - 30page
RabbitMQ와 AMQP
RabbitMQ 검색하다 보면 AMQP 에 대한 내용이 많이 나온다.
이번 기회에 자세히 이해할 수 있는 시간이 될 것 같다.
RabbitMQ는 개발 과정에서 상호운용성(Interoperability), 성능, 안정성을 중요한 목표로 개발되었다.
AMQP 스펙을 구현한 최초 메시지 브로커 중 하나다.
AMQP 스펙은 RabbitMQ와 통신하기 위한 프로토콜뿐 아니라 RabbitMQ 핵심 기능을 구현하기 위한 논리적인 모델의 틀도 제공하였다.
AMQP를 구현한 RabbitMQ는 메시지 라우팅, 메시지 내구성 설정, 데이터센터 간 통신 등
메시지 지향 아키텍처의 복잡한 요구사항에 중립적이며 플랫폼 독립적으로 사용이 가능하다.
RabbitMQ 활용 예시
서비스에 활용되고 있는 RabbitMQ 활용사례를 예시만 조금 다르게 하여 아래에 정리해 보았다.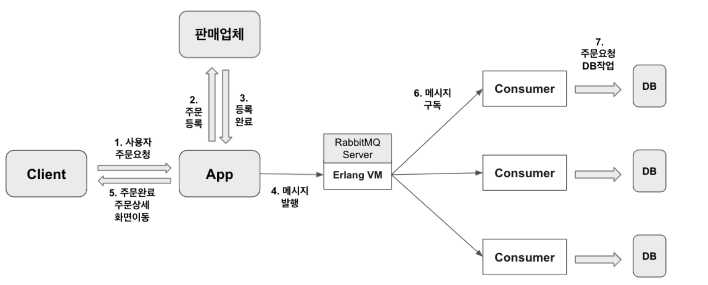
사용자가 마켓이라는 플랫폼에서 상품을 주문하는 상황이다.
사용자가 마켓에서 주문을 요청한다.
실제 판매업체에 주문등록이 완료되면 애플리케이션은 DB 작업을 기다리지 않고 사용자에게 주문이 완료되었다는 응답과 함께 주문이 완료되었다는 주문상세 화면으로 이동한다.
메시지 브로커를 활용하면 판매업체로 부터 주문등록이 완료되었다는 응답을 받은 후에 메시지만 발행해주면 주문 관련 DB 작업을 수행하는 것을 기다리지 않고 바로 사용자에게 완료되었다는 응답을 전해줄 수 있다.
여기서, 실제 DB 작업에 대해서는 발행된 메시지를 구독하고 있는 Consumer 모듈에게 전달되며 전달받은 Consumer 모듈에서 실제 주문 관련된 DB 업데이트 작업을 수행하게 되는 구조이다.
애플리케이션의 의존성 제거
방금 설명드린 사례에서 실제 DB 작업은 메인 애플리케이션과 무관하게 Consumer Application에 의해 수행되는 것을 확인하였다.
RabbitMQ를 이용하여 데이터베이스 의존성을 제거하여 느슨하게 결합된 구조가 될 수 있었다.
RabbitMQ를 활용 예시와 같은 구조의 애플리케이션은
1. 데이터베이스의 삽입, 변경 등에 대한 DB 성능에 영향을 받지 않으며
2. 애플리케이션 코드를 변경하지 않고도 데이터를 처리하는 애플리케이션을 쉽게 추가할 수 있다. (확장성)
RabbitMQ 3가지 개념
실제 코드 상에서 구현되는 개념으로 의미와 역할들이 무엇인지 정리하였다.
1. Exchange
RabbitMQ 에서 메시지를 목적지로 전달하기 위해 필요하다.
전송한 메시지를 수신하고 메시지를 보낼 위치를 결정하는 역할을 한다.
Exchange는 메시지에 적용할 라우팅 동작을 정의한다.
(메시지가 보내질 때 데이터의 속성, 메시지에 포함된 속성을 이용한다)
2. Queue
수신한 메시지들을 저장하는 역할을 하고 있다.
Queue 설정 정보에는 메시지를 메모리에만 보관할 것인지 디스크에 보관할 것인지에 대한 정보가 포함되어 있다.
수신한 메시지의 처리순서는 Queue 자료구조의 특징 선입 선출 방식으로 처리된다.
3. Binding
AMQ 모델은 바인딩을 사용해서 큐와 익스체인지 관계를 정의한다.
바인딩 키와 익스체인지는 어떤 큐에 메시지를 전달해야 하는지를 의미한다.
익스체인지에 메시지를 발행할 때 애플리케이션은 라우팅키 속성을 사용한다.
라우팅 키는 큐의 이름이거나 의미적으로 메시지를 설명하는 문자열이다.컨테이너화 대 가상화 - Docker
도커는 컨테이너 기반의 오픈소스 가상화 플랫폼이다.
다양한 프로그램, 실행환경을 컨테이너로 추상화하고 동일한 인터페이스를 제공하여 프로그램의 배포 및 관리를 단순하게 해줍니다. 백엔드 프로그램, 데이터베이스 서버, 메시지 큐등 어떤 프로그램도 컨테이너로 추상화할 수 있고 조립PC, AWS, Azure, Google cloud등 어디에서든 실행할 수 있다.
컨테이너
- 운영체계를 기반으로 만들어진 대부분의 Software는 그 실행을 위하여 OS와 Software가 사용하는 동적 Library에 대하여 의존성을 갖는다. 즉, Software의 실행을 위해선 OS와 Library를 포함, Software가 필요로 하는 파일 등으로 구성된 실행환경이 필요한데, 하나의 시스템 위에서 둘 이상의 Software를 동시에 실행하려고 한다면 문제가 발생할 수 있다. 예를 들어, Software A와 B가 동일한 Library를 사용하지만 서로 다른 버전을 필요로 하는 경우라던지 두 software의 운영 체제가 다를 경우 등 다양한 경우에서 문제가 발생할 수 있다. 이런 상황에서가장 간단한 해결책은 두 Software를 위한 시스템을 각각 준비하는 것인데, 시스템을 각각 준비할 경우 비용의 문제가 발생하게 된다(10개의 software일 경우 10개의 시스템이 필요). 이러한 문제점을 효율적으로 해결한 것이 바로 컨테이너이다. 컨테이너(Container)는 개별 Software의 실행에 필요한 실행환경을 독립적으로 운용할 수 있도록 기반환경 또는 다른 실행환경과의 간섭을 막고 실행의 독립성을 확보해주는 운영체계 수준의 격리 기술을 말한다. 컨테이너는 애플리케이션을 실제 구동 환경으로부터 추상화할 수 있는 논리 패키징 메커니즘을 제공한다.
가상 환경에 익숙하다면 컨테이너를 가상 머신(Virtual Machine)에 비교하여 생각하면 이해하기 쉽다. 호스트 운영체제에서 구동되며 그 바탕이 되는 하드웨어에 가상으로 액세스하는 Linux, Windows 등의 게스트 운영체제를 의미한다. 컨테이너는 가상 머신과 마찬가지로 애플리케이션을 관련 라이브러리 및 종속 항목과 함께 패키지로 묶어 소프트웨어 서비스 구동을 위한 격리 환경을 마련해 준다. 그러나 아래에서 살펴보듯 VM과의 유사점은 여기까지이고. 컨테이너를 사용하면 개발자와 IT 운영팀이 훨씬 작은 단위로 업무를 수행할 수 있으므로 그에 따른 이점도 훨씬 많다.
가상 머신은 하드웨어 스택을 가상화한다. 컨테이너는 이와 달리 운영체제 수준에서 가상화를 실시하여 다수의 컨테이너를 OS 커널에서 직접 구동한다. 컨테이너는 훨씬 가볍고 운영체제 커널을 공유하며, 시작이 훨씬 빠르고 운영체제 전체 부팅보다 메모리를 훨씬 적게 차지한다.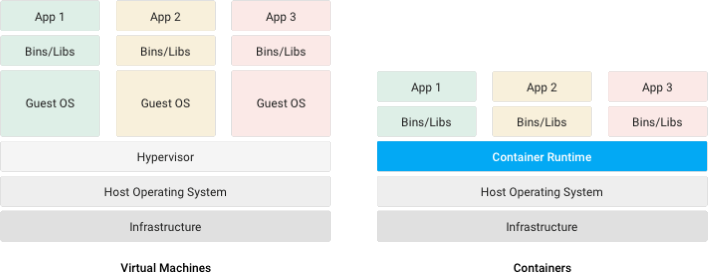
Container 기술 자체는, 격리된 실행환경을 제공하기 위한 인프라 기술이긴 하지만, Docker는 이미 그 이름에서 향기를 품고 있듯이, 그 목적부터 Software 또는 Service의 빠르고 효율적인 Shipping에 강하게 집중하고 있다. 때문에 Docker는, 근간이 되는 격리 기술을 넘어 Container와 Image, 네트워크와 서비스, 보안 등 Software의 배포와 생명 주기를 관리할 수 있는 다양한 주변 기능에 초점이 맞추어져 있다고 할 수 있다.
- 이미지
이미지는 컨테이너 실행에 필요한 파일과 설정값등을 포함하고 있는 것으로 상태값을 가지지 않고 변하지 않는다.(Immutable). 컨테이너는 이미지를 실행한 상태라고 볼 수 있고 추가되거나 변하는 값은 컨테이너에 저장된다. 같은 이미지에서 여러개의 컨테이너를 생성할 수 있고 컨테이너의 상태가 바뀌거나 컨테이너가 삭제되더라도 이미지는 변하지 않고 그대로 남아있다.
레이어 저장방식은 아래와 같다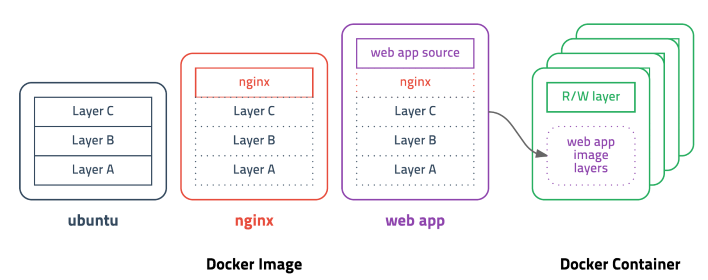
Docker Layer
도커 이미지는 컨테이너를 실행하기 위한 모든 정보를 가지고 있기 때문에 보통 용량이 수백메가MB에 이르다. 처음 이미지를 다운받을 땐 크게 부담이 안되지만 기존 이미지에 파일 하나 추가했다고 수백메가를 다시 다운받는다면 매우 비효율적일 수 밖에 없다.
도커는 이런 문제를 해결하기 위해 레이어layer라는 개념을 사용하고 유니온 파일 시스템을 이용하여 여러개의 레이어를 하나의 파일시스템으로 사용할 수 있게 해준다. 이미지는 여러개의 읽기 전용 read only 레이어로 구성되고 파일이 추가되거나 수정되면 새로운 레이어가 생성된다. ubuntu 이미지가 A + B + C의 집합이라면, ubuntu 이미지를 베이스로 만든 nginx 이미지는 A + B + C + nginx가 된다. webapp 이미지를 nginx 이미지 기반으로 만들었다면 예상대로 A + B + C + nginx + source 레이어로 구성된다. webapp 소스를 수정하면 A, B, C, nginx 레이어를 제외한 새로운 source(v2) 레이어만 다운받으면 되기 때문에 굉장히 효율적으로 이미지를 관리할 수 있다.
컨테이너를 생성할 때도 레이어 방식을 사용하는데 기존의 이미지 레이어 위에 읽기/쓰기read-write 레이어를 추가한다. 이미지 레이어를 그대로 사용하면서 컨테이너가 실행중에 생성하는 파일이나 변경된 내용은 읽기/쓰기 레이어에 저장되므로 여러개의 컨테이너를 생성해도 최소한의 용량만 사용한다.
이미지 경로는 아래와 같다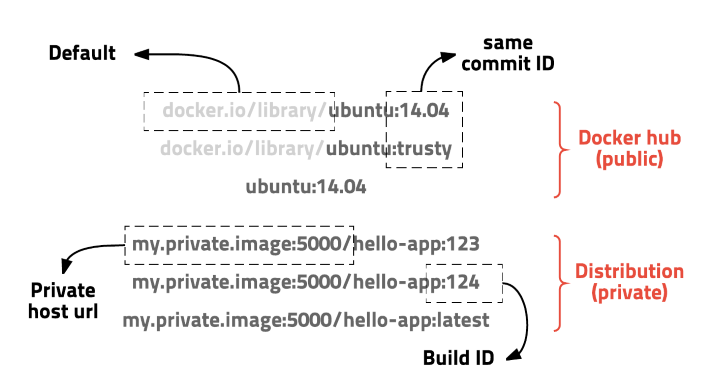
이미지는 url 방식으로 관리하며 태그를 붙일 수 있다. ubuntu 14.04 이미지는 docker.io/library/ubuntu:14.04 또는 docker.io/library/ubuntu:trusty 이고 docker.io/library는 생략가능하여 ubuntu:14.04 로 사용할 수 있다. 이러한 방식은 이해하기 쉽고 편리하게 사용할 수 있으며 태그 기능을 잘 이용하면 테스트나 롤백도 쉽게 할 수 있다.GraphQL - Apollo
- GraphQL은 애플리케이션 프로그래밍 인터페이스(API)를 위한 쿼리 언어이자 서버측 런타임으로 클라이언트에게 요청한 만큼의 데이터를 제공하는 데 우선 순위를 둡니다.
- GraphQL은 API를 더욱 빠르고 유연하며 개발자 친화적으로 만들기 위해 설계되었습니다. GraphiQL이라고 하는 통합 개발 환경(Integrated Development Environment, IDE) 내에 배포될 수도 있습니다. REST를 대체할 수 있는 GraphQL은 개발자가 단일 API 호출로 다양한 데이터 소스에서 데이터를 끌어오는 요청을 구성할 수 있도록 지원합니다.
- 또한 GraphQL은 API 유지 관리자에게 기존 쿼리에 영향을 미치지 않고 필드를 추가하거나 폐기할 수 있는 유연성을 부여합니다. 개발자는 자신이 선호하는 방식으로 API를 빌드할 수 있으며, GraphQL 사양은 이러한 API가 예측 가능한 방식으로 작동하도록 보장합니다.
GraphQL 사용 이유
1. 강력한 스키마 타입
서버에 스키마가 존재해야 클라이언트에서 해당 스키마를 사용할 수 있게 설계되어 있다. 일치하는 스키마가 없을 경우 에러가 뜨기 때문에 잘못된 스키마 정의 때문에 개발자가 고생할 필요가 없다. 또한 API 명세가 자동으로 생성되기 때문에 따로 작성할 필요가 없는 것 역시 장점이다.
2. Overfetching과 Underfetching 방지
RESTful API에서 자주 발생하는 문제를 꼽으라면 단연 Overfetching과 Underfetching이 뽑힌다. 고정된 endpoint로 요청을 보내기 때문에 정해진 데이터를 받아와야 하고 그 과정에서 문제가 발생한다. GraphQL에서는 원하는 데이터를 지정할 수 있기 때문에 위의 문제를 해결할 수 있다.
3. 생산적이다
GraphQL의 라이브러리인 Apollo에서는 chaching , realtime 또는 optimistic UI updates 를 자유롭게 활용할 수 있다. 이를 통해 다른 추가 작업 없이 보다 효율적이고 생산적으로 개발을 진행할 수 있다.
4. API 방식
GraphQL은 Schema Stitching이라는 기법을 통해 여러 API를 하나의 API로 만들 수 있다. 따라서 기존의 API가 여러 번 요청을 보내야 했던 일에 대해 하나의 요청으로 해결할 수 있게 만들어준다.
5. 넓은 생태계
많은 사람이 GraphQL을 사용, 사랑하는 만큼 충분히 넓은 개발 생태계가 있다. 즉 정보를 얻을 수 있는 방법이 많으며 좋은 라이브러리가 많이 존재한다!
Apollo GraphQL
Apollo GraphQL은 GraphQL Client 라이브러리들 중 가장 많이 사용되는 라이브러리 중 하나이다. 특히 View가 다중으로 존재하는 Android에서 GraphQL을 사용한다면 Apollo GraphQL은 필수적으로 사용된다.
Apollo GraphQL을 사용하는 대표적인 이점은 다음과 같다.
• 입력 자동 완성
• 응답을 담기 위한 클래스를 자동으로 생성(Auto Generate)
• Coroutines를 사용한 서버 요청
- 입력 자동 완성
Apollo GraphQL을 Android Studio나 Intellij에서 사용하면 자동완성이 지원된다. 기존에 GraphiQL과 같은 온라인 에디터를 써야 자동완성이 되었었는데, 이제는 안드로이드 스튜디오에서도 자동완성이 지원된다. 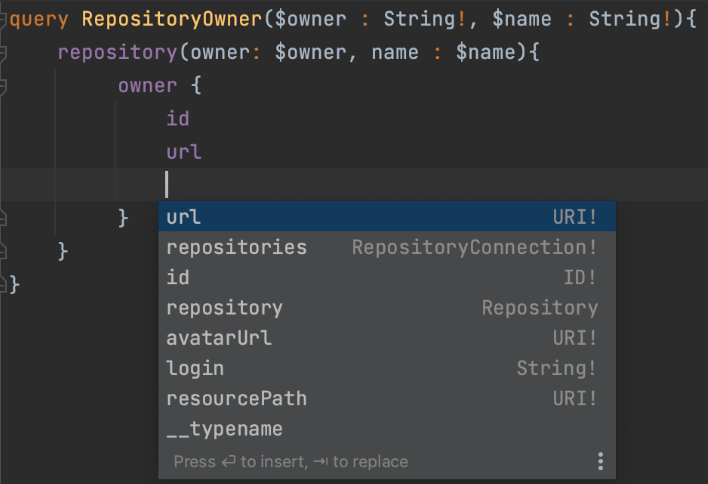
즉, QL(Query Language)용 편집기를 별도로 사용하지 않고도 IDE하나로 모든 작업을 할 수 있게 되었다. 사실상 이거 하나만으로도 Apollo GraphQL을 사용하기에 충분하다.
- 응답을 담기 위한 데이터 클래스를 자동으로 생성(Auto Generate)
Apollo GraphQL은 query나 mutation을 입력하면 해당 query나 mutation에 맞는 클래스를 Auto Generate 하며, Generate된 클래스는 우리가 쿼리를 날렸을 때 응답으로 리턴된다. 즉, query, mutation 입력 만으로 응답을 받기 위한 객체들을 모두 만들 수 있는 것이다. 기존 REST API를 사용하기 위해서는 retrofit을 사용하더라도 응답을 받기 위해 데이터 클래스를 일일히 만들어 매핑시켜줬어야 했는데 해당 부분이 모두 자동화되었다. 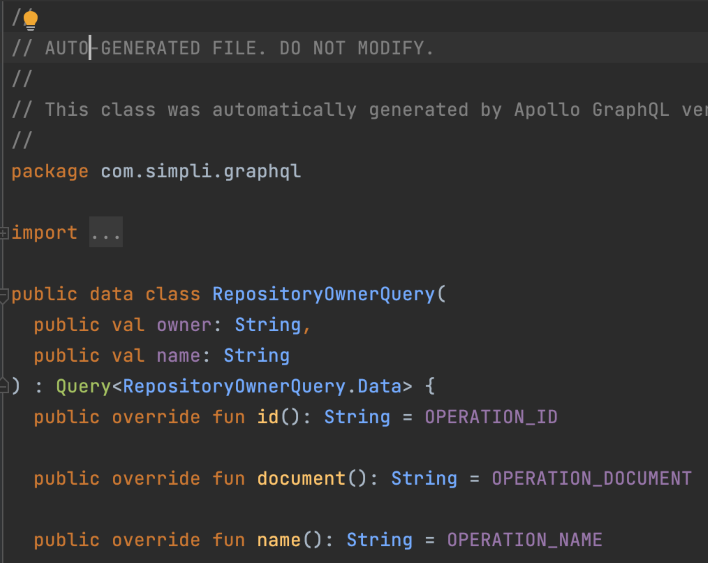
이로 인한 장점은 서버와 통신에서 문제가 생길 부분이 줄어든다는 점이며, 특히 코틀린 Class로 Auto Generate가 됨으로써 플랫폼 타입으로 인해 문제 생길 부분 또한 줄었다는 점이다.
*플랫폼 타입 : nullability를 알 수 없는 타입
- Coroutines를 사용한 서버 요청
서버로의 요청은 응답을 받기 전까지 Thread를 Blocking 시킬 수 있기 때문에 Main Thread에서 진행하면 된되고 IO Thread에서 진행되어야 한다. Apollo GraphQL은 자체 클라이언트의 요청을 위해 내부적으로 suspend fun을 사용하고 있기 때문에 경량 스레드 모델인 Coroutines를 사용하도록 강제하여 Thread를 블로킹 시키지 않도록 한다.
또한 Coroutines 를 사용해 동시성 프로그래밍을 위한 처리가 매우 간편해진다. 웹서버 - Nginx
웹 서버 (Web Server)
NginX 에 대해 알아보기 전에 웹 서버와 웹 서비스의 발전에 대해서 이해할 필요가 있었다.
초기 웹 서비스는 대부분 정보 전달이 목적인 문서 위주의 정적 페이지였다. 그렇기 때문에 HTML과 같은 마크업 언어로 작성된 문서를 서버에서 보내주기만 하면 됐다.
이후 조금 발전된 형태로 스크립트 언어를 얹은 동적 페이지가 등장하였지만, 이때까지만 하더라도 서버에서 데이터를 처리하고 클라이언트로 전송해주는데 큰 부담이 되지 않았다.
하지만 SPA(Single Page Application) 라는 개념이 등장하면서 서버가 분리될 필요성이 생겼다.
SPA는 기존의 웹 페이지와는 달리 페이지 갱신에 필요한 데이터만을 전달받아 페이지를 갱신한다. 이때 필요한 데이터는 사용자마다 달라졌고, 복잡한 연산이 필요하기도 하였다.
만약 웹 페이지에 필요한 정적 데이터와 페이지 갱신에 필요한 동적 데이터를 하나의 서버에서 처리한다면, 부하가 커지게 되고 처리가 지연됨에 따라 수행 속도가 느려질 것이다.
그래서 Web Server와 WAS(Web Application Server) 같은 개념이 생겨나게 된다.
Web Server 는 클라이언트의 요청을 처리하는 기능을 담당하고, WAS(Web Application Server) 는 DB 조회나 다양한 로직을 처리하는 기능을 담당한다.
Web Server는 클라이언트가 HTML, CSS 와 같은 정적 데이터를 요청하면 앞단에서 빠르게 제공하고, 동적 데이터가 필요하면 WAS 에 요청을 보내고, WAS 가 처리한 데이터를 클라이언트에 전달한다.
NginX 는 바로 이 Web Server 의 구축을 도와주는 소프트웨어이다.
- 엔진 엑스 (NginX)
위에서 설명한 것 처럼 Web Server 의 구축을 도와주는 소프트웨어이다. 웹 서버 소프트웨어 라고도 불린다. 이 웹 서버 소프트웨어 은 웹 어플리케이션을 안정적으로 제공할 수 있도록 도와주는 역할을 한다.
웹 서버 소프트웨어 에는 NginX 와도 많이 비교되며, 잘알려져있는 Apache 도 있다. 이 둘의 차이는 클라이언트의 요청을 처리하는 동작 방식이라고 한다.
Apache 는 스레드/프로세스 기반으로 하는 방식으로 요청을 처리하는데, 요청 하나당 스레드 하나가 처리하는 구조로 사용자가 많아지면 CPU 와 메모리 사용이 증가해서 성능이 저하될 수 있다고 한다.
NginX 는 비동기 이벤트 기반으로 하는 방식으로 처리하는데 요청이 들어오면 어떤 동작을 해야하는지만 알려주고 다음 요청을 처리하는 방식으로 진행된다고 하는데, 흐름이 끊기지 않고 응답이 빠르다고 한다.
이에 맞게 NginX 는 공식 홈페이지를 보면 가볍고 빠른 성능을 추구한다고 나와있다.
그러면 이제 NginX 가 웹 어플리케이션을 안정적으로 제공할 수 있도록 도와주는 몇가지 기능에 대해서 알아보자.
1. 리버스 프록시 (Reverse Proxy)
리버스 프록시 서버는 쉽게 설명하면 중계 기능을 하는 하는 서버이다. 클라이언트가 서버를 호출할 때 직접 서버에 접근 하는 것이 아니라 리버스 프록시 서버를 호출하게 되고, 리버스 프록시 서버가 서버에게 요청을 하고 응답을 받아 클라이언트에 전달을 한다.
클라이언트는 리버스 프록시 서버를 호출하기 때문에 실제 서버의 IP를 감출 수 있고, 이를 통해 보안을 높일 수 있다는 장점이 있다.
2. 로드밸런싱
로드밸런서는 직역하면 부하 분산으로, 서버에 가해지는 부하를 분산해주는 역할을 하는 것이다.
이용자가 많아서 발생하는 요청이 많을 때, 하나의 서버에서 이를 모두 처리하는 것이 아니라 여러대의 서버를 이용하여 요청을 처리하게 한다.
이때 서버의 로드율과 부하량 등을 고려하여 적절하게 서버들에게 분산처리 하는 것을 로드 밸런싱이라고 한다.
하나의 서버가 멈추더라도 서비스 중단 없이 다른 서버가 서비스를 계속 유지할 수 있는 무중단 배포가 가능하다는 장점이 있다.