
현재 저희 인프라는 다음과 같이 세 가지 역할로 EC2 인스턴스를 분리하여 구성되어 있습니다.
- EC2 #1: Spring 애플리케이션, HAProxy, Nginx Proxy Manager(NPM)
- EC2 #2: MySQL, Redis (DB 서버)
- EC2 #3: Prometheus, Grafana (모니터링 서버)
이러한 환경에서 JMeter를 통해 부하 테스트를 진행하던 중, HTTP 503 오류가 간헐적으로 발생하는 현상이 포착되었습니다. 이에 대한 원인 분석과 해결 과정을 공유드립니다.
1. 증상 및 초기 추정
JMeter에서 스레드 수 4개로 테스트를 진행할 때, 일부 요청이 503 오류로 응답되었습니다.
처음에는 서버의 Connection Pool 부족 문제를 의심했습니다. 저희 Spring 애플리케이션은 CPU 코어 수 2개 기준으로 max pool size를 5로 설정하고 있었고, JMeter의 스레드 수는 4였습니다. 이에 따라 max pool size 초과 상황은 아니라고 판단했습니다.
2. 에러 로그 확인
Spring 애플리케이션 로그를 확인하던 중 다음과 같은 에러 메시지가 출력되었습니다:

이 에러는 ServletOutputStream이 클라이언트와의 연결이 끊긴 상태에서 flush를 시도하며 발생한 것으로, HAProxy 측에서 해당 요청을 강제로 종료했음을 시사합니다.
3. HAProxy 헬스체크 문제 확인
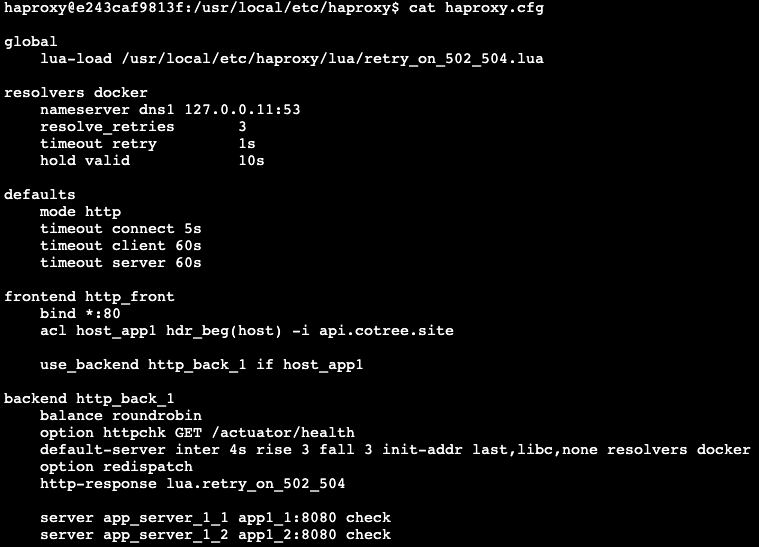
HAProxy 로그를 통해 해당 요청이 들어올 당시 백엔드 서버가 Down 상태로 간주되었음을 확인할 수 있었습니다. 이후 원인을 파악하는 과정에서 HAProxy가 사용 중인 /actuator/health 엔드포인트가 문제의 원인임을 알게 되었습니다.

Spring Boot Actuator의 /actuator/health는 단순히 서버의 상태만을 체크하는 것이 아니라 다음과 같은 외부 의존성도 함께 포함하여 체크합니다.
- 메일 서버 (SMTP)
- Redis
- MySQL 등
이 중 메일 서버의 응답 지연으로 인해 헬스체크 응답이 늦어지고, HAProxy가 해당 서버를 비정상으로 판단해 트래픽 라우팅을 중단하는 현상이 발생했습니다.
4. 해결 방안
① 전용 헬스체크 엔드포인트 추가
외부 의존성의 영향을 받지 않고 Spring 애플리케이션 자체의 상태만 확인할 수 있는 헬스체크 엔드포인트 /health 를 추가하였습니다.
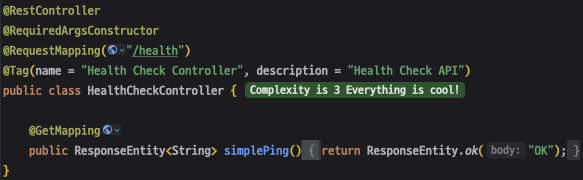
이처럼 단순히 "OK" 문자열만을 반환하는 lightweight한 health check 엔드포인트를 제공함으로써, 외부 시스템의 영향을 받지 않도록 했습니다.
② HAProxy 설정 변경
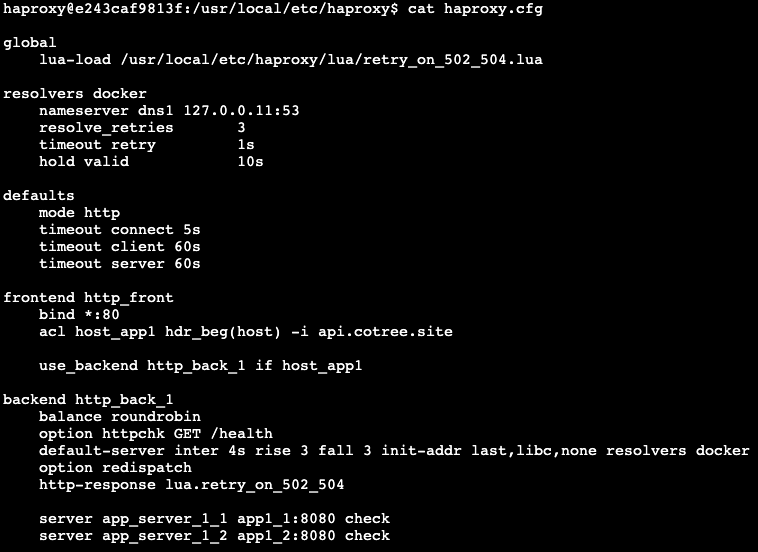
HAProxy 설정 파일에서 기존 /actuator/health 경로를 /health으로 변경하여, 외부 요소에 의한 false negative 상황을 방지했습니다.
- 변경 전 설정:
- 변경 후 설정:
5. 결론
Spring Boot Actuator의 /actuator/health는 매우 유용한 기능이지만, 외부 시스템에 대한 의존성이 많은 경우 운영 환경에서 예기치 못한 이슈를 유발할 수 있습니다.
따라서, HAProxy와 같은 로드 밸런서에서 사용하는 헬스체크 경로는 외부 리소스에 영향을 받지 않는 전용 엔드포인트로 분리하여 구성하는 것이 바람직합니다.
이번 경험을 통해, 시스템 구성 요소 간 상호작용을 명확히 이해하고, 장애 발생 시 빠르게 원인을 추적할 수 있는 구조를 갖추는 것이 얼마나 중요한지를 다시금 실감할 수 있었습니다.
