
DOM에서 요소가 존재할 때까지 기다려야할 때, WebDriverWait를 사용합니다.
Expected Conditions
Selenium에서 제공하는 wait 조건 메소드를 사용할 수 있습니다.
제가 자주 사용하는 조건은 아래와 같습니다.
- presence_of_element_located >> element가 존재할 때까지 기다려야할 때
- element_to_be_clickable >> element 클릭 가능할 때까지 기다려야할 때
- frame_to_be_available_and_switch_to_it >> iframe이 존재할 때까지 기다려야할 때
그 외 사용할 수 있는 다른 조건들은 공식 문서에서 확인하실 수 있습니다.
예제
아래는 id값이 'someid'인 요소를 클릭 가능할 때까지 최대 10초 기다리는 코드입니다.
설정한 timeout 시간인 10초 내에 조건이 충족되지 않으면, TimeoutException이 발생합니다.
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
element = WebDriverWait(driver, 10).until(EC.element_to_be_clickable((By.ID, 'someid')))Custom Wait Conditions
위의 Expected Conditions에서 사용할 수 있는 조건이 아니라, 직접 조건을 만들어서 wait 해야할 경우가 있습니다.
저의 경우, 더보기 버튼을 클릭하거나 스크롤을 내렸을 시, 리스트 element 개수가 증가할 때까지 기다리는 조건이 필요해서 custom wait 조건 구현이 필요했습니다.
링크를 참고하였고, 리스트 element 개수가 증가할 때까지 기다리는 조건 코드는 아래와 같습니다.
class elements_length_changes(object):
"""An expectation for checking that an elements has changes.
locator - used to find the element
returns the WebElement once the length has changed
"""
def __init__(self, locator, length):
self.locator = locator
self.length = length
def __call__(self, driver):
elements = driver.find_elements(*self.locator)
element_cnt = len(elements)
if element_cnt > self.length:
return elements
else:
return False이 조건 클래스를 활용하여 예제로, 트위터 구글계정에서 스크롤을 내렸을 시 리스트 element 개수가 증가할 때까지 최대 10초 기다리면서 총 20개의 작성된 게시물의 순서번호와 작성시간을 출력해보겠습니다.
예제
main.py
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from selenium.webdriver.support.wait import WebDriverWait
from webdriver_manager.chrome import ChromeDriverManager
""" 위에 작성한 elements_length_changes 클래스(생략) """
if __name__ == '__main__':
driver = webdriver.Chrome(service=Service(ChromeDriverManager(log_level=0).install()))
try:
url = "https://twitter.com/google"
driver.get(url)
article_cnt = 0
index = 0
while article_cnt < 20:
locator = (By.TAG_NAME, 'article')
article_elements = driver.find_elements(*locator)
article_cnt = len(article_elements)
while index < article_cnt:
article_write_time_text = article_elements[index].find_element(By.TAG_NAME, 'time').get_attribute('innerText')
print(f'{index+1}번째 게시물({index+1}/{article_cnt}) 작성 시간 : {article_write_time_text}')
index += 1
scrolling(driver=driver)
condition = elements_length_changes(locator=locator, length=article_cnt)
WebDriverWait(driver, 10).until(condition)
finally:
driver.quit()(참고로, WebDriverWait과 관련이 없어 위의 코드 내용에 생략했지만, 스크롤하는 함수 코드는 아래와 같습니다.)
def scrolling(driver):
last_height = driver.execute_script("return document.body.scrollHeight")
while True:
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
driver.execute_script("window.scrollBy(0, -10);")
new_height = driver.execute_script("return document.body.scrollHeight")
if new_height == last_height: # 페이지 맨아래로 스크롤 완료 상태
break
last_height = new_height실행결과

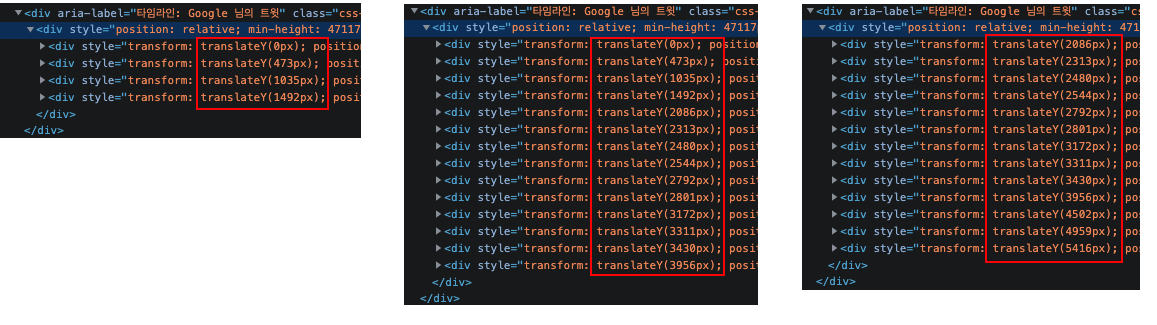
트위터 구글계정에서 초기에는 2개의 게시물이 노출되다가, 스크롤 시 5개->8개->9개로 게시물 개수가 증가되면서 게시물 작성시간이 출력됨을 확인할 수 있었습니다.
(10번째 게시물 이후에는 TimeoutException이 발생하였는데요, 추가 확인해보니 트위터에서 스크롤 시 게시물 요소가 계속 쌓이는 것이 아니라, 스크롤 위치에 따라 DOM에서 보여지는 게시물 개수가 조정되어 게시물 요소 추출한 개수가 절대 20개가 나올 수 없는 거였네요^^;)
이상, WebDriverWait은 ajax를 사용하는 웹 페이지에서 유용하게 사용할 수 있을 것 같습니다 :)
