[Javascript] Data Structure revisited

What is data structure?
-
data structure(자료구조:collection of data values)는 데이터의 엑세스와 modification을 가능케 하는 방향으로 데이터를 organize, manage 및 store 하는 format 이다.
-
Javascript 에는 primitve(built in) 와 non-primitive(not built in, custom 으로 만들 어야 함) data structure가 존재 한다.
Basics of data structure
Array(배열)
-
가장 기본적인 primitive data structure 중의 하나이며 Array 의 각 element 들은 index 를 가지고 있다.
-
몇몇 프로그래밍 언어에서는 같은 type 의 element 들만 동일한 배열에 담을 수 있지만 javascript 에는 혼합해서 담아도 괜찮다.
-
배열안의 배열도 가능
ex)const ary = [ [1,2,3], [4,5,6], [7,8,9], ] -
Array 는 가장 많이 쓰이는 data structure 이지만 새로운 item을 배열의 시작이나 중간에 삽입 할 경우, 나머지 item 들의 index 가 변동 되므로 이에 따른 computational cost 가 발생하며 이는 배열의 약점 중의 하나이다.
-
이러한 이유로 data structure 후미에 item 을 더하거나 빼는 것에는 강점을 가지지만 data structure 의 특정 부분에 item 을 추가 하거나 제거 하는데 있어서는 다른 종류의 자료 구조가 더 효율적이다.
-
Array 를 manipulate 하는 각종 method에 관한 글 https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Array
Object(hash tables)
-
object 는 key-value 쌍의 collection 이다. 다른 언어에서는 map, dictionary 또는 hash-table 이라고 불린다.
const obj = { key1: "value1", key2: "value2"} -
하나의 오브젝트 안에 각각의 키는 unique 한 naming 을 가지고 있어야 한다.
-
오브젝트는 value 도 담을 수 있지만 함수 또한 담을 수 있다.
-
오브젝트에서의 value는 property, 함수는 method 라 칭한다.
const obj = {key1: "value1", key2: function(){console.log("I am a method!!" }} -
properties 에 엑세스 하기 위한 두가지 방법이 있는데, dot 과 bracket 이 있다.
1) object.property 2) object["property"] -
method 을 불러올 때는
obj.key2()와 같이 불러온다. -
새로운 value 를 추가 하는 방법은 다음과 같다
obj.key4 = 1112
obj["key5"] = "새로운 prop 추가"
obj.key6 = () => console.log("함수를 추가하는 법")
console.log(obj.key4) // 1112
console.log(obj["key5"]) // "새로운 prop 추가"
obj.key6() // "함수를 추가하는 법"
-
Ojbect method 에 관한 글 https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Object
-
Object 는 연관성을 가진 데이터들을 묶는데 유용하게 쓰일 수 있다. 그리고 key 들의 유니크 함 때문에 특정 조건에 의거, 데이터를 나누는 것에도 유용하다.
ex)
const obj = {
dogPeople: 20000,
catPeople: 1000,
reptilePeople: 500
}
// 각 prop 이 동물을 좋아하는 사람들 이라는 연관성을 가졌으며, 각각의 key 가 어떤 동물을 좋아하는지 유니크한 조건을 가지고 있다Stacks
-
Stack 은 list 의 형태로 item 을 저장한다. LIFO(Last In First Out, FIFO 의 반대) 의 패턴으로만 데이터 추가 및 제거가 가능하다.
-
javascript 의 call stack, undo/redo 기능 등의 LIFO 패턴이 필요한 상황에 자주 쓰인다.
-
Stack 을 implement 하는데는 다양한 방법이 있지만 가장 흔하고 간단하게 구현하는 방법에는 array 의 push 와 pop methods 을 사용 하는 것 이다. Array 의 끝에서만 추가가 되고 제거가 되므로 LIFO 패턴이 구현된다.
-
리스트로 Stack 을 만드는 방법은 이글의 출처인 https://www.freecodecamp.org/news/data-structures-in-javascript-with-examples/#:~:text=In%20JavaScript%2C%20an%20object%20is,table%20in%20other%20programming%20languages.&text=We%20use%20curly%20braces%20to,colon%2C%20and%20the%20corresponding%20value 에서 찾을 수 있다.
-
해당 리스트 Stack 의 big O 는 다음과 같다.
-> 삽입: O(1), 제거: O(1), 탐색: O(n), 접근: O(n)
QUEUES
- queue는 FIFO 패턴을 따른다. 프린터의 인쇄 큐나 영화관 입장 줄을 생각하면 된다.
- queue 의 가장 간단한 implementation 은 Array를 사용하여 삽입시 push 를 쓰고, 삭제시 shift method 을 쓰면 된다.
- big O 는 Stack 과 동일하다.
Linked Lists
-
리스트의 형태를 띄며 각 value는 node로 취급된다. 각 node는 pointer 를 통해 다음 value 와 연결 되어 있다. 마지막 노드의 경우 null 을 가리키는 pointer 를 지닌다.
-
singly linked list, doubly linked list 가 있으며 singly linked list 는 각 node가 다음의 node를 가리키는 하나의 pointer 를 가지지만 doubly linked list 는 각 노드가 두개의 pointer를 가지며 각 pointer 는 다음과 이전의 노드를 가리킨다.
-
list 의 첫번째 요소는 head 라 불리우며 마지막 요소는 tail 이 된다. 리스트의 length 는 array 와 동일하게 요소의 갯수를 가리킨다.
-
Array 와는 다르게 list 는 index 를 가지지 않는다. 각 value 는 포인터로 연결된 value 에 대한 정보만을 가진다.
-
index 가 존재 하지 않으므로 랜덤하게 value에 접근은 불가능 하다. value 에 접근 하기 위해선 list 의 시작과 끝을 모두 iterate 해야 한다.
-
index 가 존재하지 않는것의 장점은 더 효율적인 삽입과 삭제 이다. 삽입/삭제 하고싶은 노드의 이웃 Pointer 의 redirection 을 통해 가능하다. Array 는 삽입/삭제시 index 가 바뀐다.
-
삽입: O(1), 제거: O(n), 탐색: O(n), 엑세스: O(n)
Doubly linked list
-
하나의 node 가 두개의 pointer 를 가지므로 singly linked list 와 비교 했을때 더 효율적인 상황이 많지만 메모리를 더 많이 소모한다.
-
삽입: O(1), 제거: O(1), 탐색: O(n), 엑세스: O(n)
Trees
-
tree는 parent/child relationship 으로 node 들을 묶는 data structure 이다. 가장 첫번째 node 는 root node 라 불리우며 각 Tree 마다 하나의 root 만 존재한다. 이후에 오는 모든 node 들은 이 root node 의 children node가 된다. 자식이 없는 node들은 leaf nodes 라고 불린다. Tree의 height 는 parent/child connections 의 갯수에 의해 결정 된다.
-
Array 나 linked list 와 달리 Tree 는 linear 하지 않다. node 간의 Tree formation 의 중요한 필수요소는 only valid connection between nodes is from parent to child (번역의 한계..한국말로 표현할 말이 딱히 생각이 안난다). 같은 children 끼리나 child to parent 의 connection 은 불가하다. (이러한 connection 을 가진 data structure 은 graph 이다).
-
사용 예시: the DOM model, 운영체제안의 파일 폴더(폴더안의 폴더안의 폴더..)
Binary Trees
-
바이너리 트리란 각 노드가 최대 2개의 자식을 가진 트리를 말한다.
-
바이너리 트리는 탐색에 있어 매우 유용하다.
-
이런 탐색을 할때는 Binary Search Trees(BSTs) 가 쓰인다.
-
BST 에선 부모의 왼쪽으로 descend 하는 node 는 부모보다 무조건 Value 가 작아야 하며, 오른쪽으로 descend 하는 node는 그 부모보다 value 가 커야 한다.
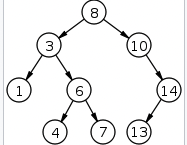
-
BST 가 searching 에 좋은 이유는 찾고자 하는 value 가 parent node 의 value 보다 큰지 작은지를 비교 함으로써 대략 반정도의 데이터를 순차적인 비교를 통해 discard 할 수 있어서 이다.
-
value 의 삽입과 삭제는 다음과 같은 알고리즘을 통해 이루어진다.
1) root node 가 존재 하는지 확인
2) 존재한다면 삽입/삭제 하려는 value 가 root node의 value 보다 큰지 작은지 확인
3) 더 작다면 좌측에 노드가 있는지 확인하고 2) operation을 반복. 존재 하지 않을시, 해당위치에 node 를 삽입/삭제.
4) 더 크다면 우측에 노드가 있는지 확인하고 2) operation을 반복. 존재 하지 않을시, 해당위치에 node 를 삽입/삭제.
-BST 의 탐색은 위의 알고리즘과 비슷한 과정을 거치는데, 다만 삽입/삭제 대신 value 가 동일한지를 비교한다.
= 이러한 operations 들은 O(log(n)) 인데, 이는 tree 가 양쪽으로 balance 된 structure을 가졌을 때만 가능하다. 한쪽에만 치중되어 있는 tree는 그 효율에서 영향을 받는다.
Heaps
-
특별한 규칙을 따르는 또다른 종류의 tree 이며 아래와 같이 크게 두가지 종류로 나뉜다.
1) MaxHeap: 부모 node 가 children 노드보다 무조건 value 가 크다.
2) MinHeap: 부모 node 가 children 노드보다 무조건 value 가 작다. -
Heap 의 siblings 들은 그들의 부모보다 크거나 작다 라는 조건 외에는 다른 커넥션을 가지고 있지 않다.
-
특히 binary heaps 는 priority queues 를 구현하는데 자주 쓰이고, Dijkstra's path-finding algorithm 에도 쓰인다.
-
priority queue 는 각 요소가 연관된 priority 를 가지고 있으며 더 높은 중요도를 가진 요소가 먼저 보여지는 data structure의 종류이다.
Graphs
-
Tree 와 다르게 root 이나 leaf node 가 없으며, head 또는 tail 도 존재하지 않는다. 그냥 node 들이 특정한 연관성을 가지고 서로 연결이 되어있다.
-
graphs 는 social networks, geolocalization, 추천 시스템 등의 구현에 유용하게 쓰일 수 있다.
Undirected and directed graphs
-
Undirected Graphs: node 의 커넥션 간에 특정한 방향이 없는 graph를 undirected graph 라 칭한다. Undirected means the connections between nodes can be used both ways.
-
Directed graph 는 undirected graph 와 반대로 노드간의 traverse 에 direction 이 존재한다. node A 에서 B 로 갈 수 있다면 B 에서 A로는 갈수 없다는 뜻.
Weighted and unweighted graphs
- 노드간의 connection 에 지정된 weight 이 있는 그래프를 weighted graph 라 칭한다. 지도에서 네비게이션 등을 위해 자주 쓰인다.
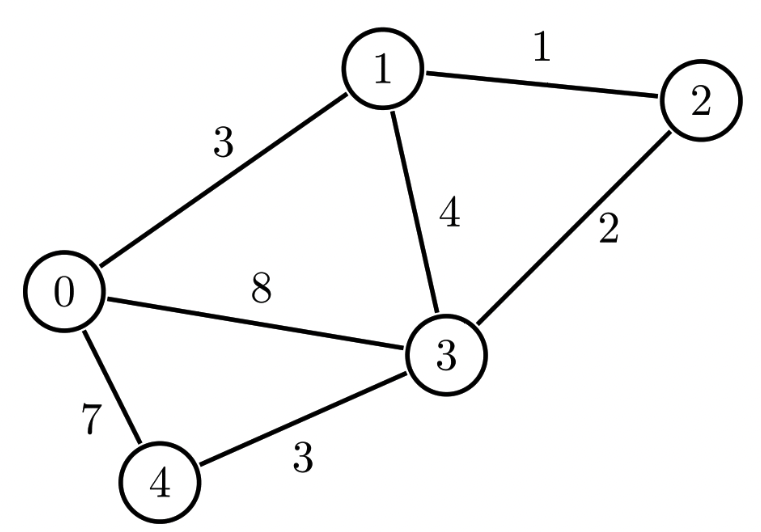
- 코드 상으로는 Adjavenvy matrix 나 Adjacency list 를 이용해 구현 할 수 있다.
