Recap: language models (LMs)
language model (LM)
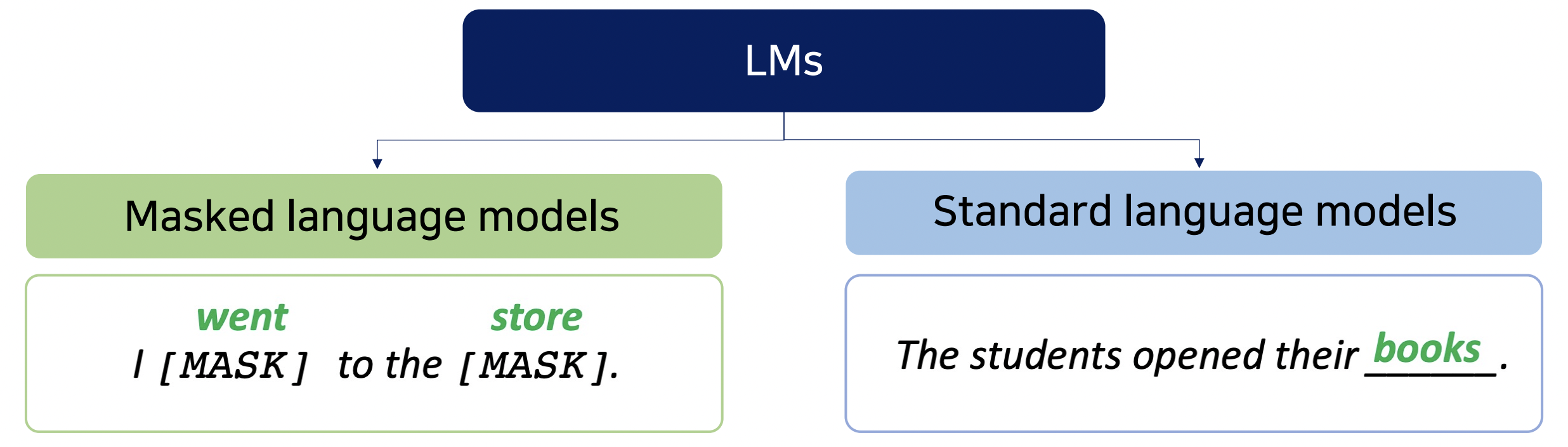
- language model은 pre-training을 통해 언어 구조를 이해하고 이를 활용해 NLP task를 수행한다.
- pre-training의 objective
- Masked LM
- Auto Encoding
- Input Sequence의 일부 mask 토큰에 대해 대체된 단어 예측
- BERT류 Encoding
- Standard LM
- Auto Regressive
- Sequence 다음에 올 단어를 예측
- Masked LM
What does a language model know?
- LM Prediction은 말이 되거나, (문법적)형태적으로 문제없는 답을 일반적으로 잘 도출한다.
- 하지만 그 답이 모두 factually correct 한 것은 아니다.
- 즉, knowledge에 기반하지 못 하는 경우 존재.
- 원인
- Unseen facts: 학습한 말뭉치에 해당 fact 정보가 없었기 때문에.
- Rare facts: 해당 정보가 존재했지만, 학습이 제대로 될 만큼 양이 충분하지 않았다.
- Model sensitivity: input sequence에 대한 model의 sensitivity가 너무 높다.
- ex Correctly answers “x was made in y” templates but not “x was created in y”
: 같은 표현이지만 모델이 다르게 인식한다.
- LM Prediction에 knowledge를 반영하도록 개선하는 방법론은?
- 궁극적으로 LM이 traditional knowledge bases을 대체할 수 있을까?
기존 방법론
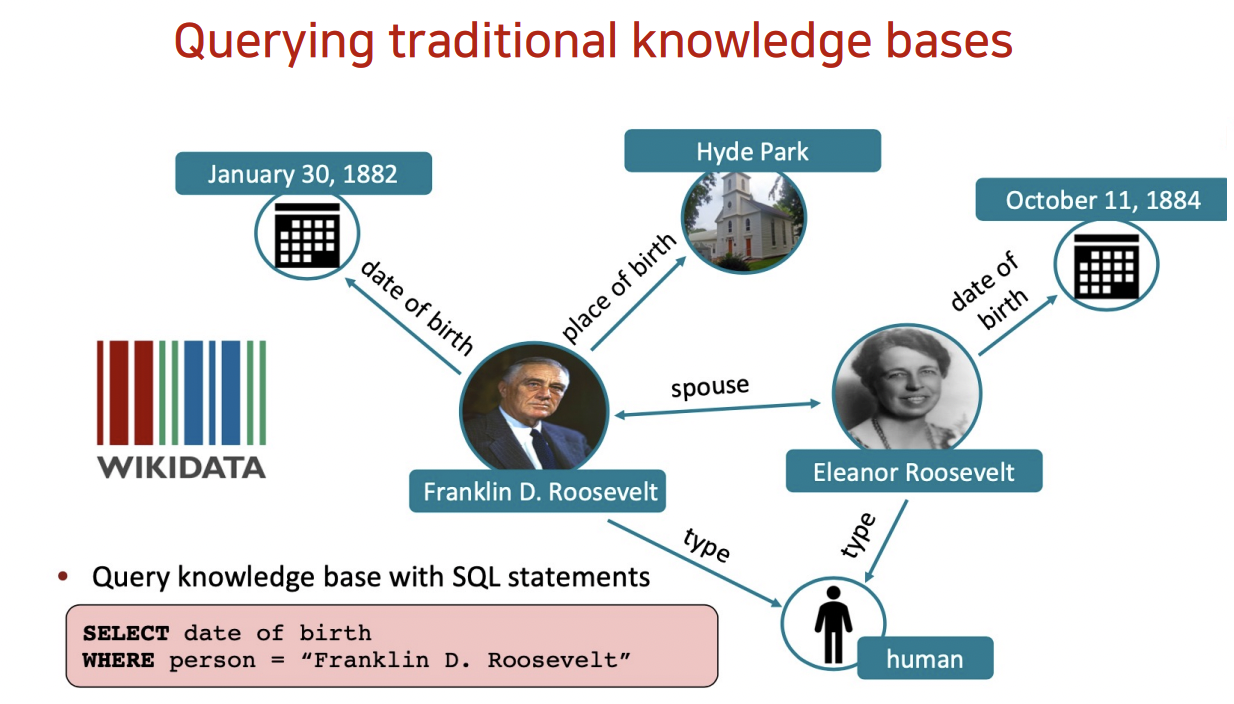
- Querying traditional knowledge bases
- 이미 갖춰진 지식 정보를 기반으로 학습시키자
- Manual Annotation이 필요
- structured data를 LM에 반영하기 위한 pipeline 필요
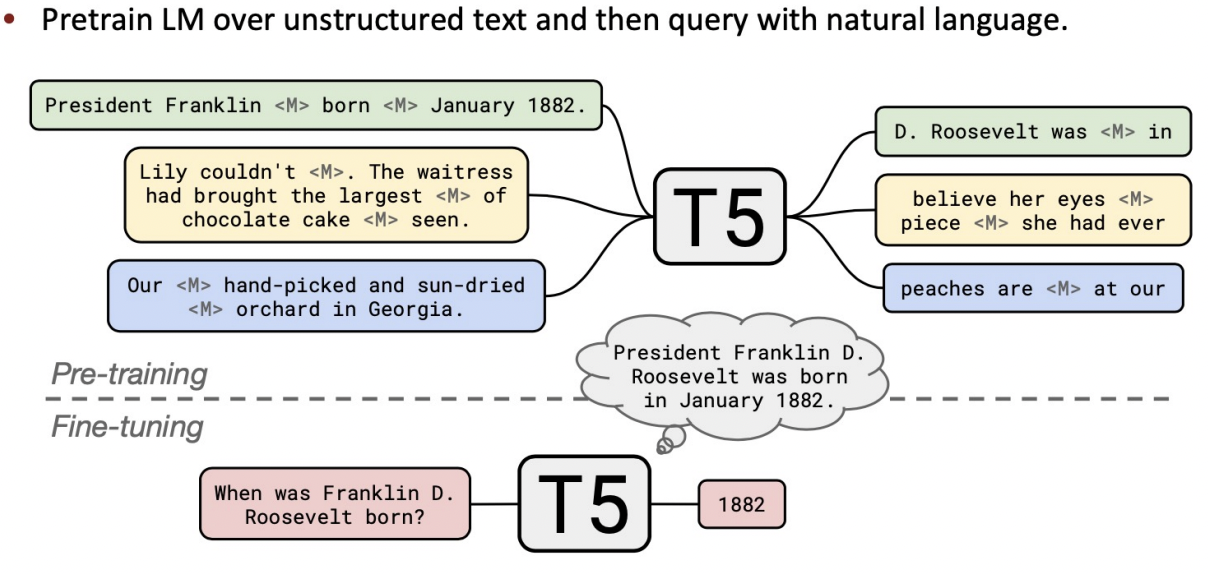
- Querying language models as knowledge bases
- 방대한 양은 data로 학습된 LM자체를 knowledge bases로 사용
- 위의 방법론에 비해 flexible
- 내장된 정보를 interpret, trust, modify하기 어렵다.
: 갖고 있는 정보에 대한 관리 어려움
Techniques to add knowledge to LMs
: knowledge를 LM에 주입시키기 위한 방법
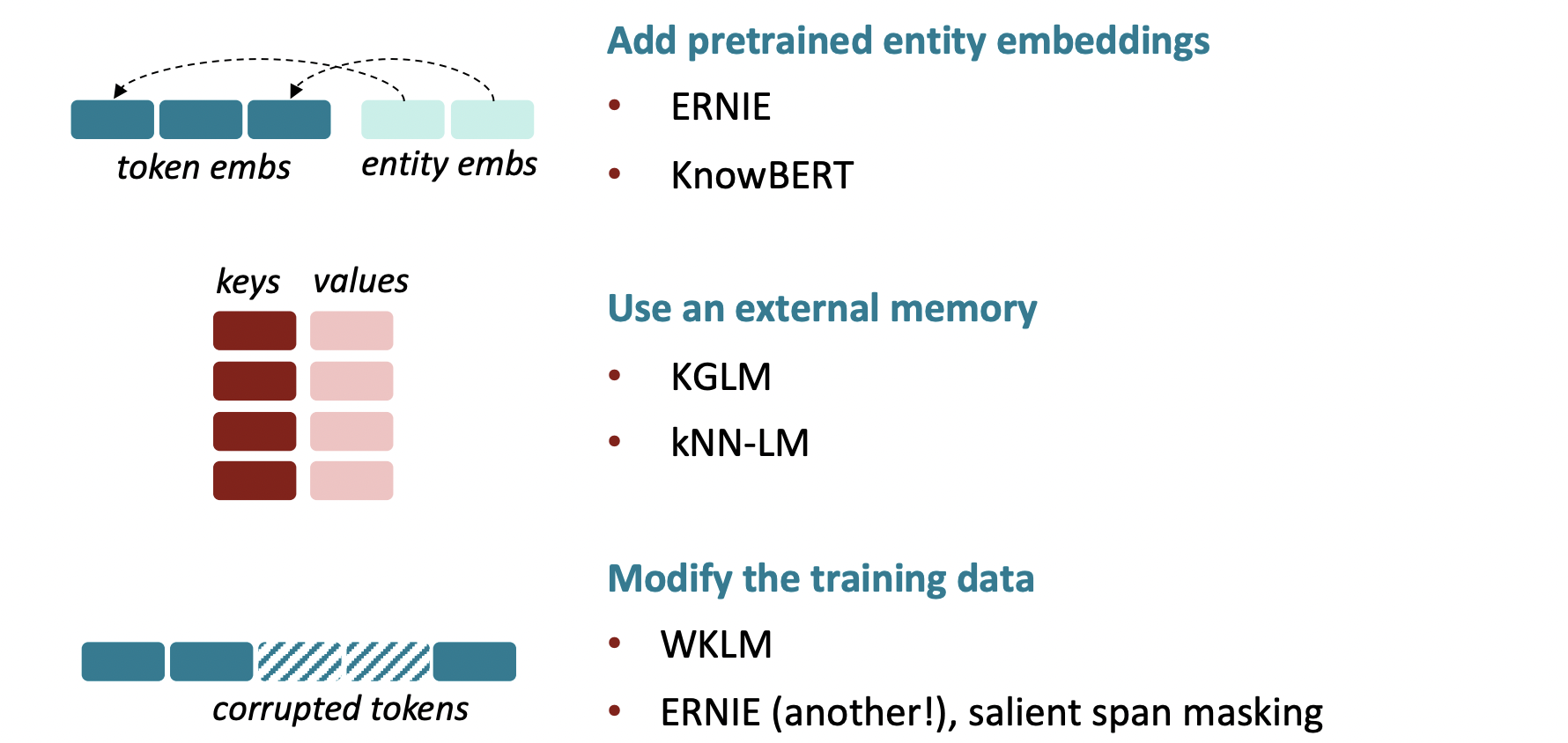
Add pretrained entity embeddings

ERNIE
- ERNIE: Enhanced Language Representation with Informative Entities, Zhang, et al., 2019. (Accepted by ACL 2019) - 칭화대
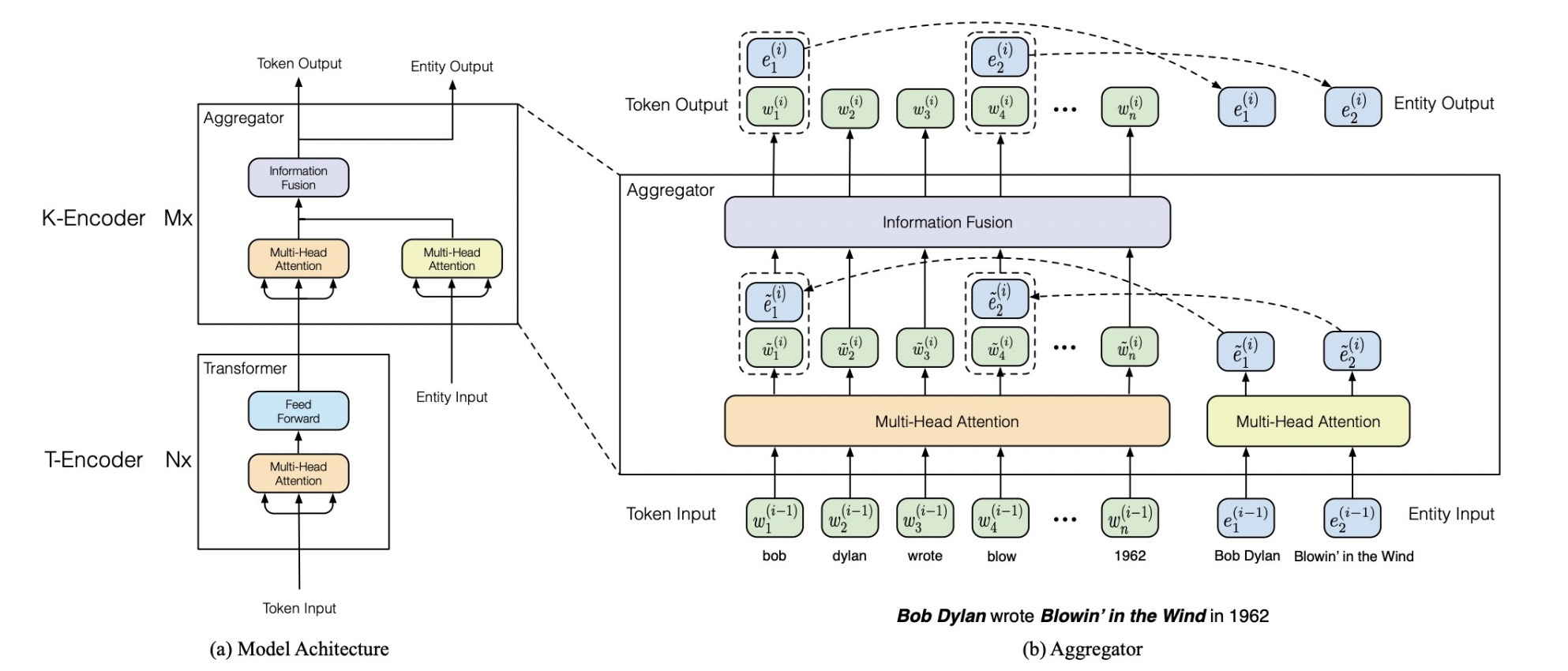
- Input Sequence에 대한 word embeddings에 Knowledge에 대한 Entity embeddings 정보를 반영하여, 기존 MLM과 다르게 context와 더불어 knowledge fact를 aggregate 할 수 있다.
- Textual Encoder (T-Encoder)
- multi-layer bidirectional encoder (BERT)
- sequence 자체에 대한 정보 추출
- word Embedding 생성
- Entity input
- by. TransE
: 사전학습된 Entity(knowledge graph의 node)의 vector embedding - Entity embedding
- by. TransE
- Knowledgeable Encoder (K-Encoder)
- 입력받은 두 vector, language represent와 knowledge represent를 (각각 multi-head attention 통과 후) 결합하는(fusion) 작업 수행
- Heterogeneous Information Fusion
: 별개의 vector space위에 학습되어 표현된 두 정보를 fusion
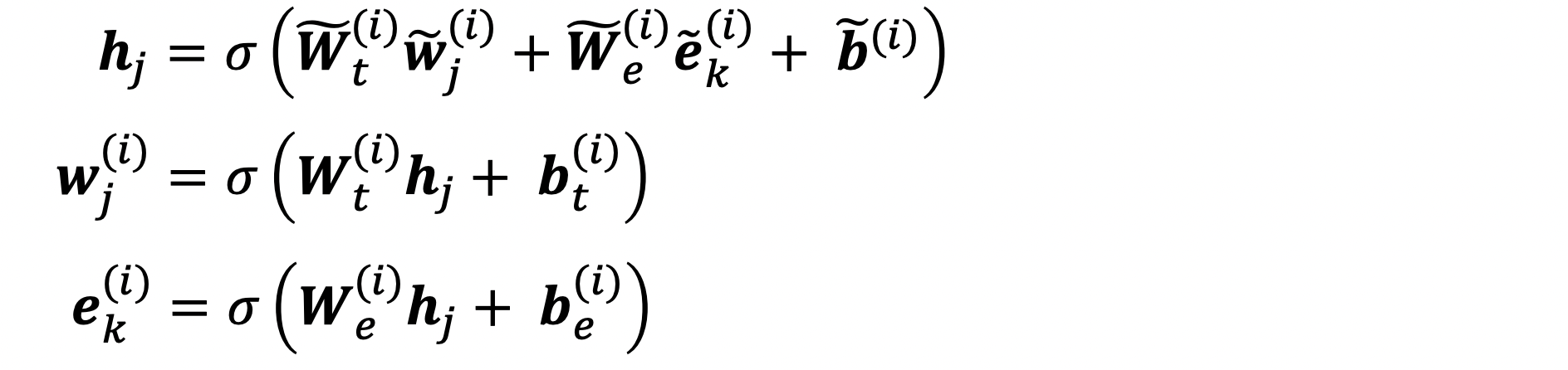
- 별개의 다른 embedding space로부터 나온 Embedding들의 결합
: 하나의 linear layer(= fusion layer) 추가해서 수행
KnowBERT
- downstream task에서 entity를 예측하는 entity linker(EL)을 BERT에 추가해서 사전학습 시키는 방식. EL을 학습시켜 예측에 이용하기에 entity annotation필요 없다.
Use an external memory

KGLM
- Barack's Wife Hillary: Using Knowledge-Graphs for Fact-Aware
Language Modeling (KGLM)
https://aclanthology.org/P19-1598/
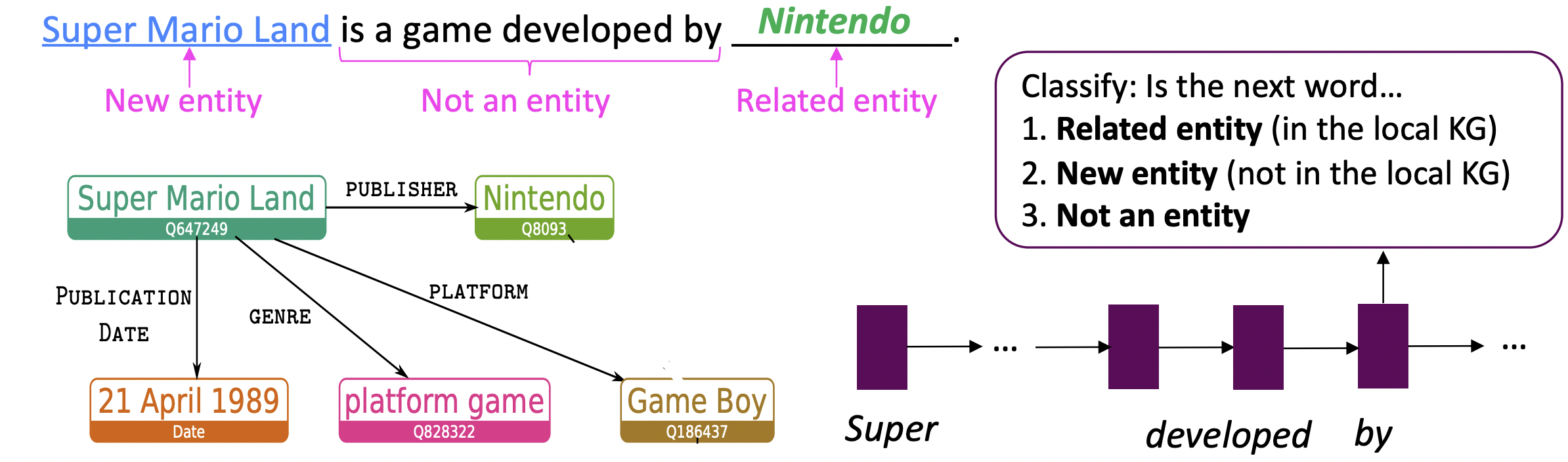
- 전체 KG의 Sequence에 관련있는 entity만으로 구성된 부분집합인, “local” knowledge graph을 구축하여 다음 단어 예측에 활용.
- 다음 단어의 type을 LSTM을 이용해 예측
- 다음 단어 예측에 standard vocabulary와 더불어 top-scoring entity 에 대한 entity aliases(를 지칭할 수 있는 표현)를 포함시켜 예측을 수행한다.
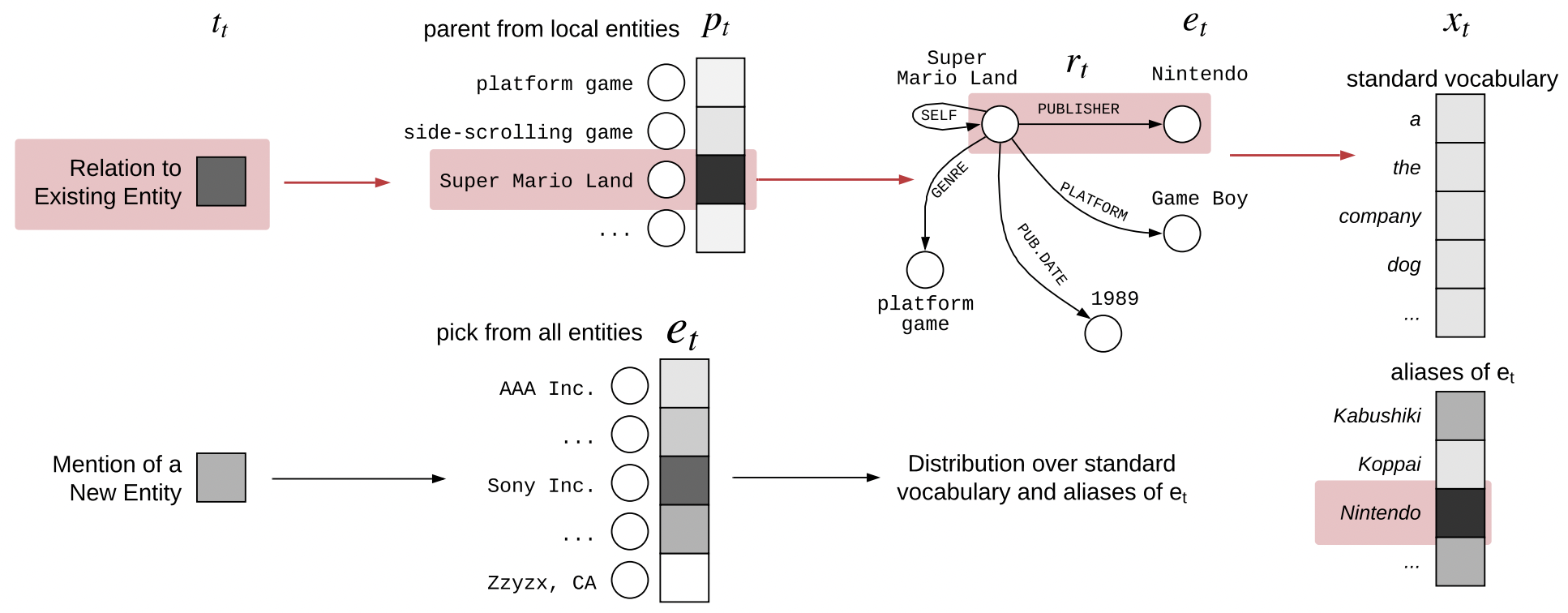
- 사용한 KG에 따라 모델의 성능 변화가 크기에 KG에 의존적이다.
kNN-LM
- Nearest Neighbor Language Models _ https://arxiv.org/abs/1911.00172
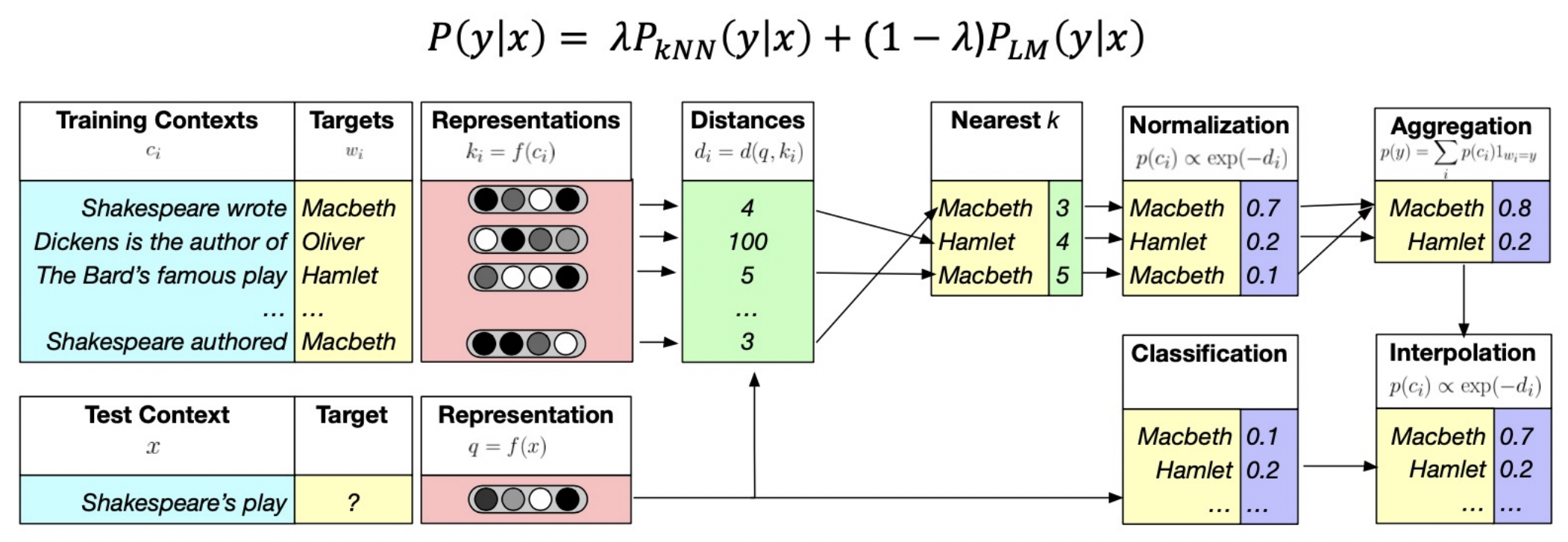
- KNN, 거리에 기반하여 유사한 단어들을 탐색 후, 단어 예측에 해당 정보를 추가적으로 사용하는 방법
- LM prob.와 kNN prob.을 결합해 최종 예측 prob.로 사용한다.
Modify the training data

WKLM
- Pretrained Encyclopedia: Weakly Supervised KnowledgePretrained Language Model (WKLM) _ https://arxiv.org/pdf/1912.09637.pdf
- pretraining 과정에서 자연스럽게 knowledge 주입. 더 자연스러운 예측 가능
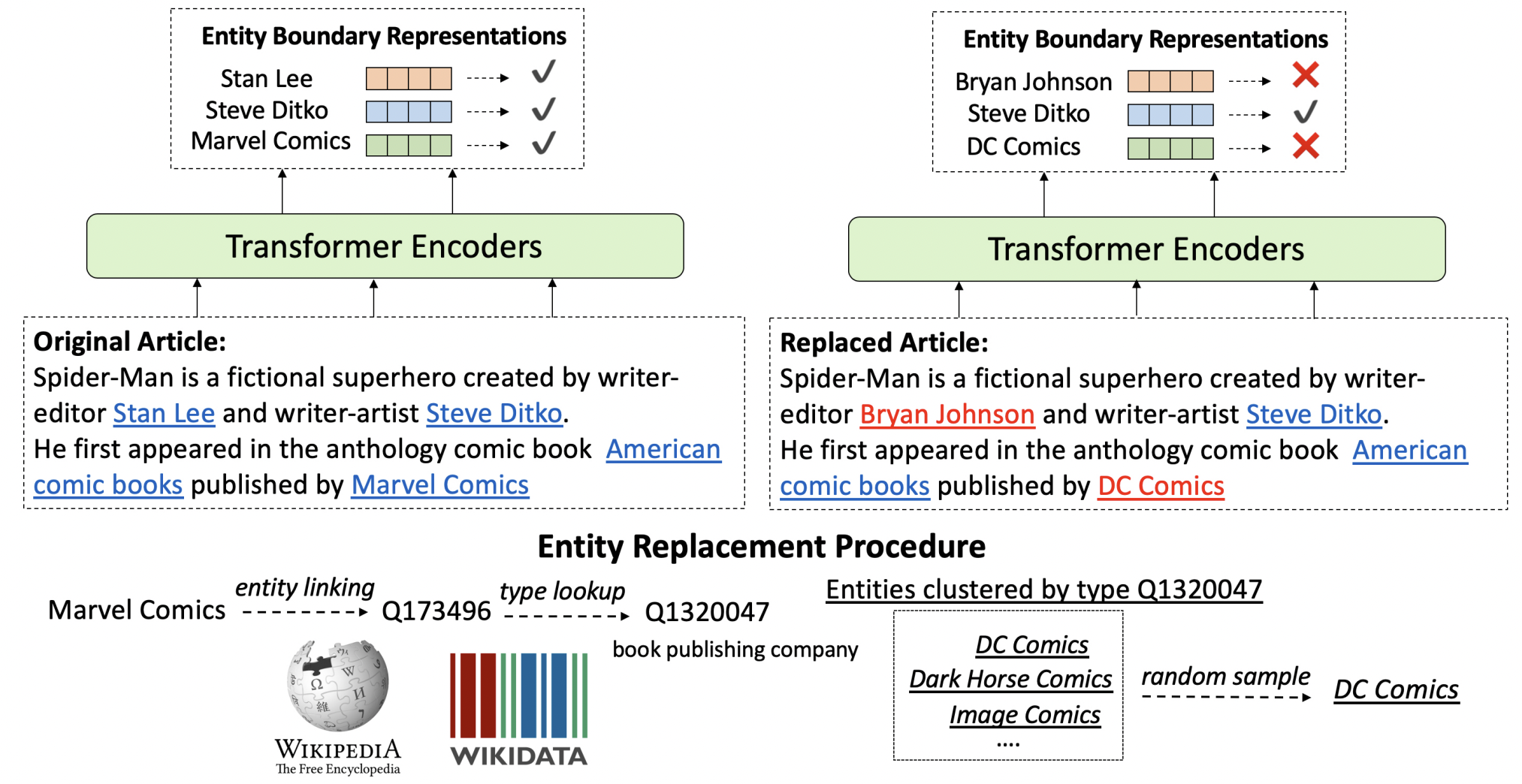

- 모델이 true knowledge와 false knowledge를 구분할 수 있도록 학습
- false knowledge 생성
- true knowledge인 기존 데이터의 일부분을 같은 type의 다른 entity로 변경해서 생성.
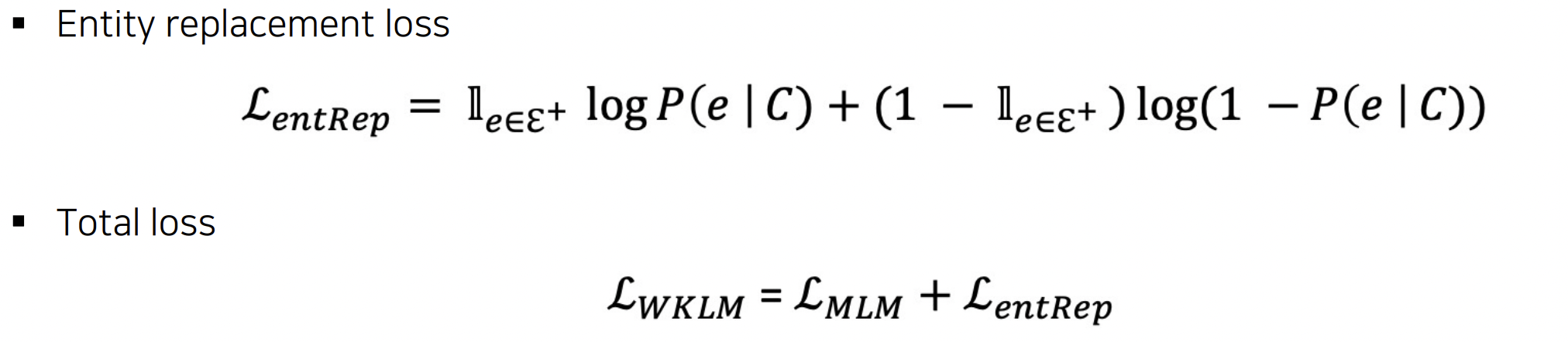
- entity replacement loss : True/False knowledge 판별 위한 별도의 loss
- 최종 loss : MLM loss와 entRep loss - summation
ERNIE
- ERNIE1: Enhanced Representation through Knowledge Integration
_ https://arxiv.org/abs/1904.09223 - 바이두
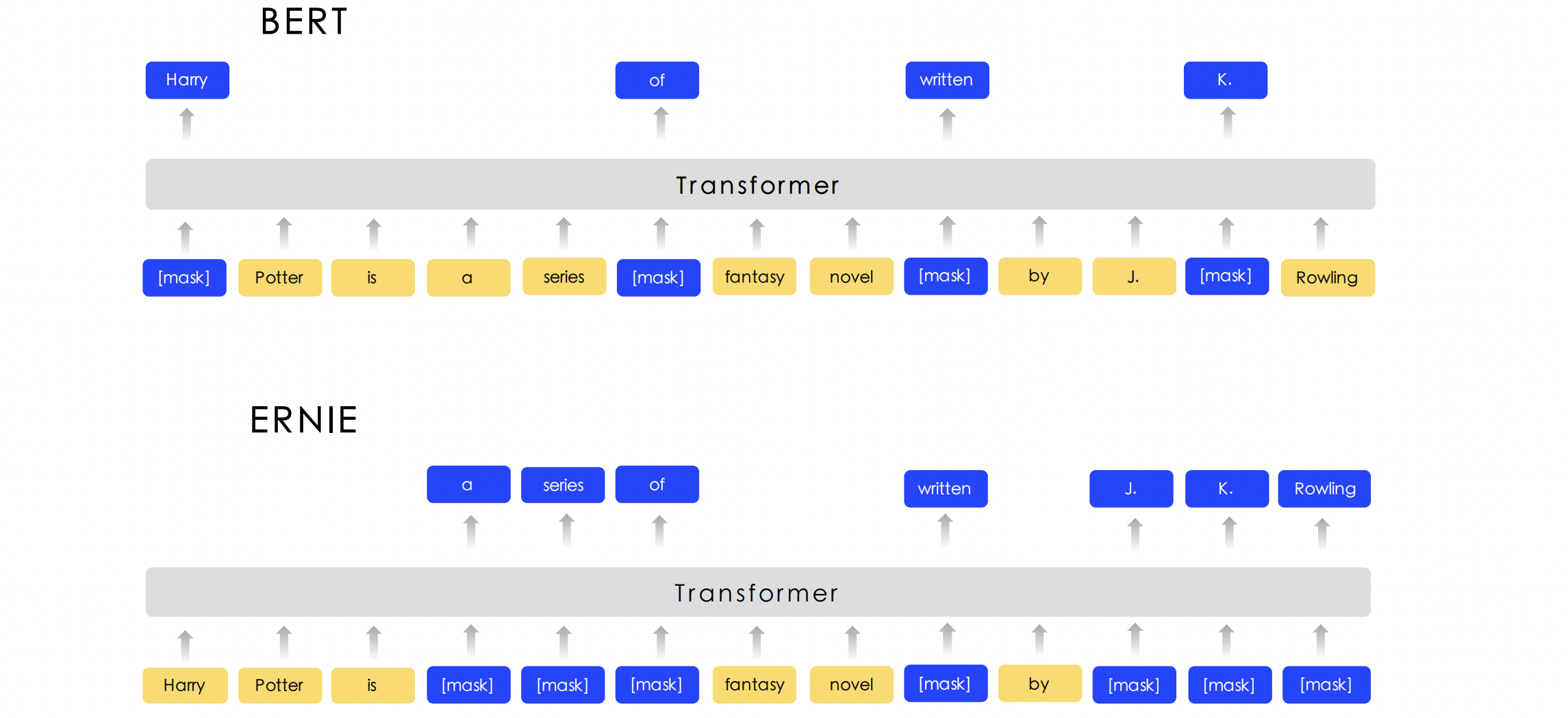
- 별도의 Entity Embedding 사용하지 않고, masking기법을 통해 knowledge 정보 주입.
- salient span masking
Evaluating knowledge in LMs
LAMA
- 기성 LM이 얼마나 relational knowledge를 반영하고 있는지 probe하는 하나의 benchmark
- KG triples와 question-answer pair에서 cloze statements를 생성
- LM을 supervised relation extraction(knowledge triple 추출)과 QA systems을 비교하여 평가 수행
- 한계
- 설명성 부족
- sensitive to the phrasing
LAMA-UHN
- relational knowledge(entity)가 있어야 답변 가능한 data만 남긴다.
- score 변화를 관찰.
- BERT는 겉보기(sequence의 표면적 형태)에 의존하는 경향 발견.
Developing better prompts to query knowledge in LMs
- query(prompt) 형식에 따라 성능 차이가 크게 나타난다.
- LM은 query에 매우 sensitive하다.
