여러가지 자료구조

iterable, sequence
- iterable
- 멤버를 차례로 하나씩 반환할 수 있는 객체
- iterator를 반환하는 빌트인 함수 iter()를 위한 매직 메소드인iter()를 구현하고 있는 객체
- list, str, tuple, dict
- sequence
- 정수 index를 통해 각 멤버에 접근할 수 있는 iterable 객체
- dict type은 key index를 통해 각 멤버에 접근하므로 sequence가 아니다.
iterable 객체의 내장함수
sorted()
map()
- 객체의 모든 요소에 일괄적으로 넘겨준 함수를 적용
- map 객체를 리턴하기에 보통 결과를 list()로 다시 형변환 해줘야 한다.
- map(func, iterable)
def func_mul(x):
return x * 2
result1 = list(map(func_mul, [5, 4, 3, 2, 1]))
print(f"map(일반함수, 리스트) : {result1}")
result2 = list(map(lambda x: x * 2, [5, 4, 3, 2, 1]))
print(f"map(람다함수, 리스트) : {result2}")
l = [[1, 1], [2, 2], [0, 3]]
result3 = list(map(lambda x: [x[0], x[1]-1] if x[1]-1 > 0 else None, l))
filter()
- map과 비슷하지만 조건에 맞는 element만 반환
- 함수의 리턴값이 bool type이어야 한다. True인 element만 리턴
target = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
result = filter(lambda x : x%2==0, target)
print(list(result))
L = [0, 23, 234, 89, None, 0, 35, 9]
L = filter(None, L)
[23, 234, 89, 35, 9]
# None값만 제거
L = [x for x in L if x is not None]
L = filter(lambda v: v is not None, L)
[0, 23, 234, 89, 0, 35, 9]
- 각 element 연산 후 특정 조건 element 제거
l = [[1, 1], [2, 2], [0, 3]]
list(filter(None, map(lambda x: [x[0], x[1]-1] if x[1]-1 > 0 else None, l)))
set
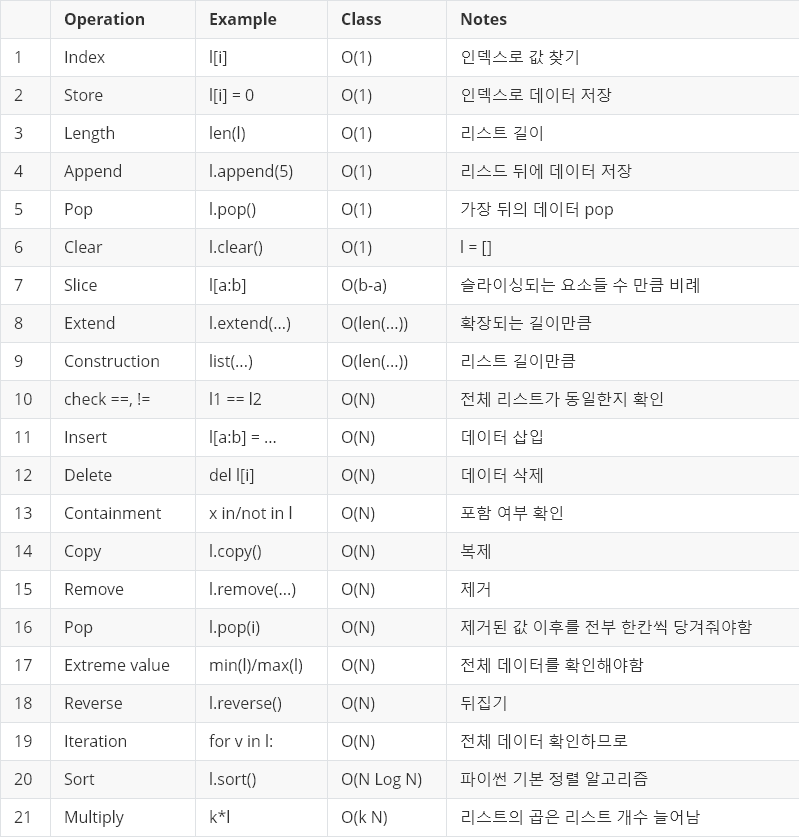
- set을 활용하면 list 보다 시간복잡도를 줄일 수 있는 경우들이 있다.
- list 시간복잡도
- set 시간복잡도
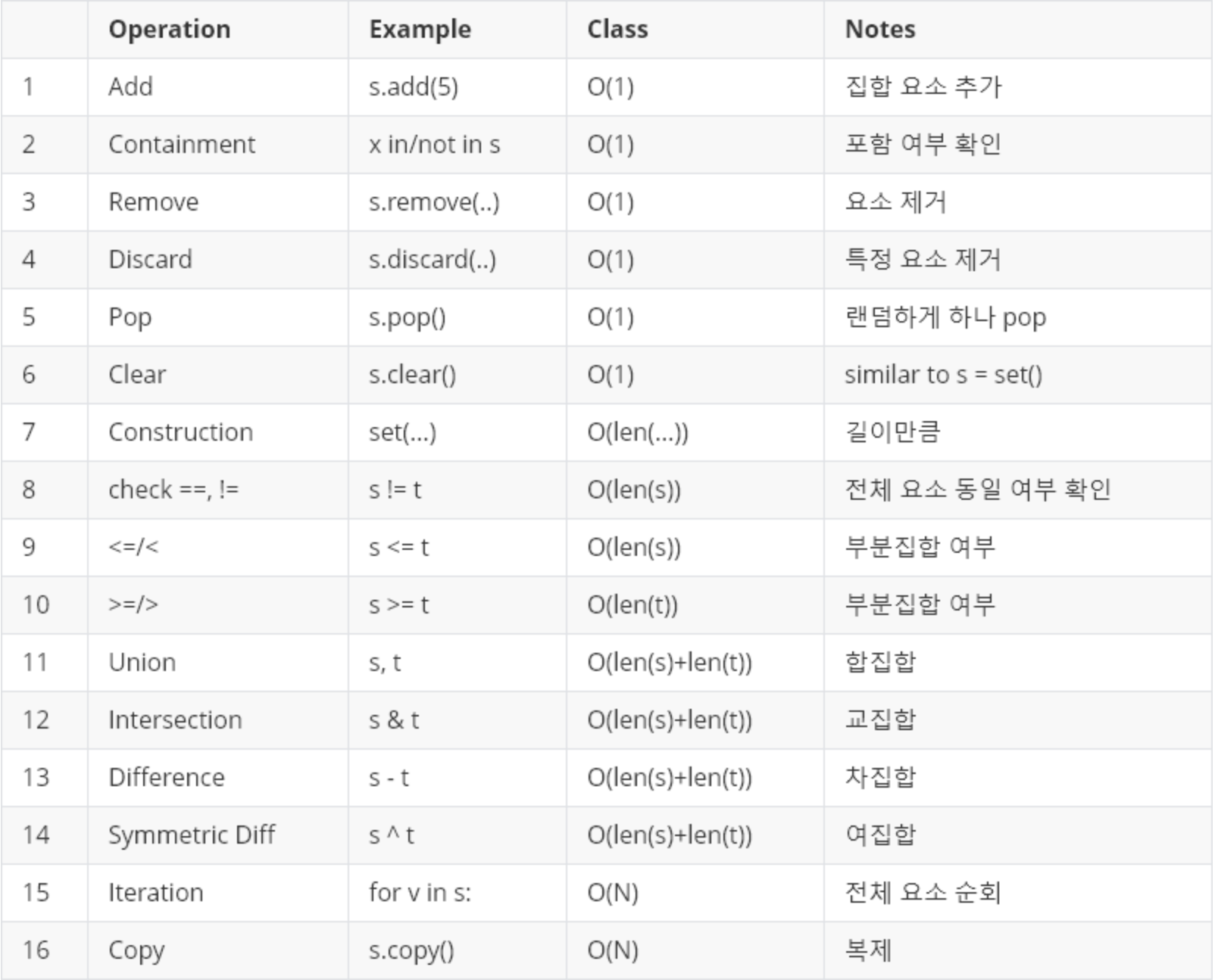 : set
: set
- 선언
s1 = set()
s2 = set([1,2,3])
s3 = {1, 2, 3}
원소 추가, 삭제
s1.add(10)
- set.remove(x)
- O(1)
- 특정 element 삭제
- 없는 element 삭제 시 error 발생
s1 = set([1, 2, 3])
s1.remove(2)
s1
- set.discard(x)
- 없는 element 삭제해도 error 발생 안 함
포함관계
- in
- O(1)
- element가 set에 들어있는지 확인
s1 = set()
s2 = set([1,2,3])
s3 = {1, 2, 3}
if 2 in s2:
print("yes")
if 5 not in s2:
print("yes")
- set1이 set2의 부분집합인지 확인
(자기 자신도 부분집합임)
set1 = {1, 3}
set2 = {1, 2, 3, 4}
print(set1 <= set2)
print(set1.issubset(set2))
dict
기본 함수
d = {}
d = {"a": 1, "b": 2}
d = dict(a=1, b=2)
d = dict([("a", 1), ("b", 2)])
d["c"] = 3
d["a"] = 10
d.update({"d": 4, "e": 5})
d["a"]
d.get("a")
d.get("x", 0)
d.pop("a")
d.pop("x", None)
d.popitem()
del d["b"]
d.clear()
for k in d: ...
for k, v in d.items(): ...
for k in d.keys(): ...
for v in d.values(): ...
dict 정렬 - sorted()
- 단순히 sorted() 함수에 dict 객체를 넣으면 key 값들로 구성된 정렬된 list가 리턴된다.
dict1 = {'c':1, 'b':5, 'a':2}
sorted(dict1)
- 모든 정렬은 dict.items()를 통해 진행한다.
: (key, value)의 tuple pair로 구성된 list (dict_items객체) 리턴
items = sorted(d.items())
items = sorted(d.items(), key=lambda x: x[1])
top3 = sorted(d.items(), key=lambda x: x[1], reverse=True)[:3]
d_sorted = dict(sorted(d.items(), key=lambda x: x[1]))
- sorted() 함수에 파라미터 안 주고 dict_items객체 단순히 넣으면
: key를 기준으로 오름차순 정렬한 list리턴
sorted(dict1.items())
- sorted(dict, key= , reverse= ) 이용
: 기본적으로 이 방법 활용하자!
sorted(dict1.items(), key = lambda item: item[0], reverse = True)
sorted(dict1.items(), key = lambda item: item[1])
sorted(dict1.items(), key = lambda item: item[1], reverse = True)
defaultdict, Counter
from collections import defaultdict, Counter
dd = defaultdict(list)
dd["a"].append(1)
cnt = Counter(["a","b","a","c","b","a"])
cnt["a"]
cnt.most_common(2)
referenced
