Hyper-Parameter / Parameter
- Hyper-Parameter
: 학습을 위한 세팅 값 - 직접 설정할 수 있는 변수
: learning-rate(SGD), layer-num,drop-out-rate(NN) 등
- Parameter
: 학습을 통해 최적화, 업데이트 하는 변수
: 학습의 목적이 최적의 이 parameters를 찾는 것이다.
Loss/Cost/Objective Function
- Loss Function
: 한 데이터 포인트에 대한 오차(실체값에 대해 예측값이 벗어난 정도)
: MAE, MSE, RMSE
- Cost Function
: 전체 데이터에 대한 오차
: loss함수의 합(sigma), 적분(integral), 평균을 통해 얻는다.
- Objective Function
: cost function, MLE 등 최소화/최대화 시킴으로써 모델을 최적화(optimization)하는 함수
: 최적화는 objective function을 최소화(최대화) 하는 값으로 parameter를 업데이트 함으로써 이루어진다.
one-hot Encoding
- 각 클래스는 순서의 의미를 갖고 있지 않으므로 각 클래스 간의 오차는 균등 (유클리드 거리가 동일).
: 무작위성
- 무작위성은 때로는 단어의 유사성을 구할 수 없다는 단점으로 언급되기도 함.
logistic regression
- class가 2개인 classification분류 문제를 해결하기 위한 모델
- 가설 : H(x) = sigmoid(wX+b)
- ex) pytorch에서 logistic regression 모델 구현
model = nn.Sequential(
nn.Linear(2, 1),
nn.Sigmoid()
)
softmax regression
- Multi-class Classification를 해결하기 위한 모델
- f개의 독립변수(feature) input으로 c개의 class 중 하나를 예측할 때
: [ c x f ] 형태의 W matrix(가중치 행렬)를 필요로 합니다.
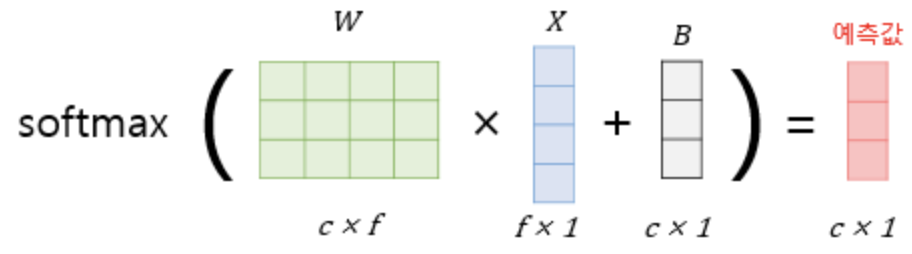
- 예측값은 합이 1인 c개의 확률값으로 도출됩니다.
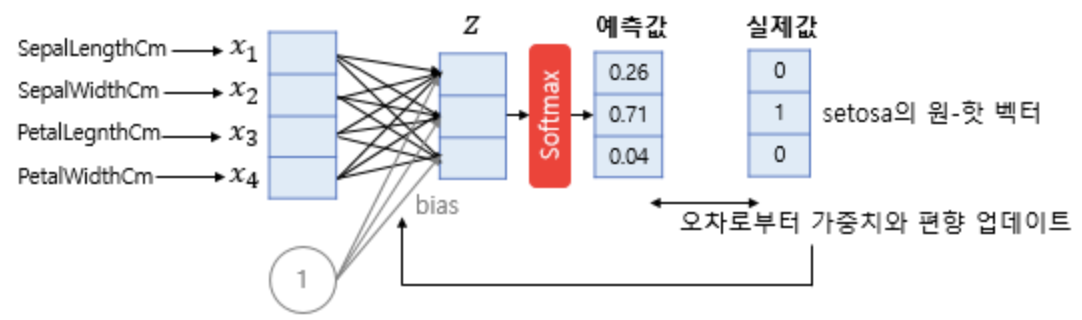
- 오차로부터 optimization을 위한 cost function은 "크로스 엔트로피 함수"를 이용합니다.
(n : 전체 데이터 개수, k : class 개수)
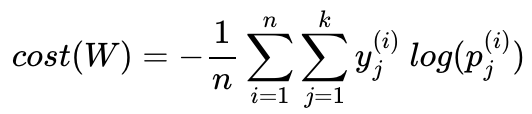
머신러닝 모델의 기본 구조
- X, y data-set 세팅
- parameter 초기값 부여(rand)
ㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡ
- hypothesis(가설->예측값) 연산식
: by. 모델 (linear regression, softmax regression 등)
- hypothesis 기반으로 cost function
: by. (MSE, cross entropy 등)
- cost function 기반으로 optimization
: by. optimizer (SGD 등)
: parameter update
: back propagation
ㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡ
3., 4., 5. 반복( x epoch )
참고
https://wikidocs.net/60572
