1. DBMS
데이터베이스(Database)
- 데이터:
관찰 결과로 나타난 정량적 혹은 정성적인 실제 값
- 정보:
데이터를 기반으로 의미를 부여한 것
- 데이터베이스:
한 조직에 필요한 정보를 여러 응용 시스템에서 공용할 수 있도록
논리적으로 연관된 데이터를 모으고 중복되는 데이터를 최소화하여
구조적으로 통합, 저장해놓은 것
- 데이터베이스의 특징
1) 실시간 접근성(real time accessibility):
사용자가 데이터 요청 시 실시간으로 결과 서비스
2) 계속적인 변화(continuos change):
데이터 값은 시간에 따라 항상 바뀜
3) 동시 공유(concurrent sharing):
서로 다른 업무 또는 여러 사용자에게 동시 공유됨
4) 내용에 따른 참조(reference by content):
데이터의 물리적 위치가 아닌 데이터 값에 따라 참조
DBMS
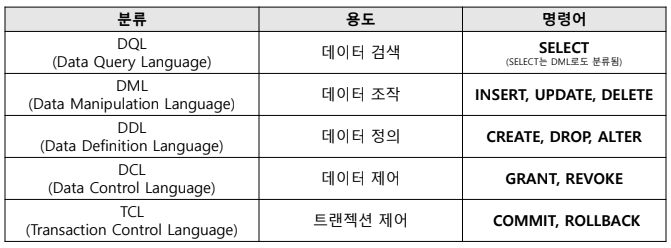
- 데이터베이스에서 데이터 추출, 조작, 정의, 제어 등을 할 수 있게 해주는 데이터베이스 전용 관리 프로그램
- 데이터베이스의 기능
1) 데이터 추출
2) 데이터 조작
3) 데이터 정의
4) 데이터 제어
- 데이터베이스의 장점
1) 데이터 독립화
2) 데이터 중복 최소화, 데이터 무결성 보장:
중복되는 데이터를 최소화 시키면 데이터 무결성이 손상될 가능성이 줄어든다.
중복되는 데이터를 최소화 시키면 필요한 저장공간의 낭비를 줄일 수 있다.
3) 데이터 보안 향상
4) 관리 편의성 향상
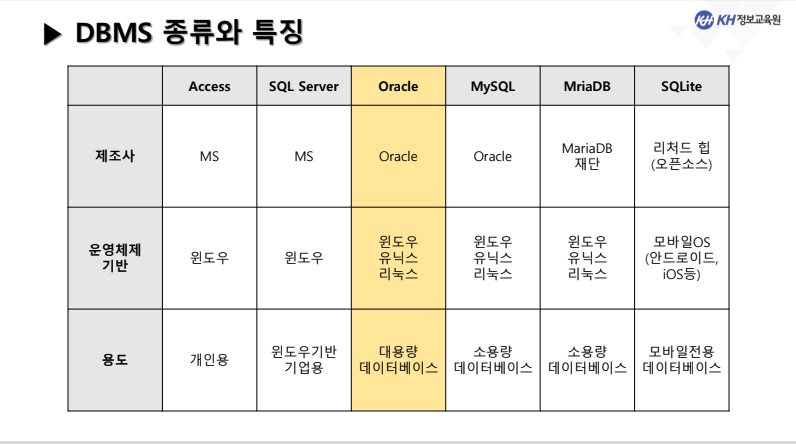
- DBMS의 종류
1) 계층형 데이터베이스:
트리 형태의 계층적 구조를 가진 데이터베이스로 최상위 계층의 데이터부터 검색하는 구조
2) 네트워크형 데이터베이스:
하위 데이터들끼리의 관계까지 정의할 수 있는 구조로 설계 및 구현이 복잡하고 어려움
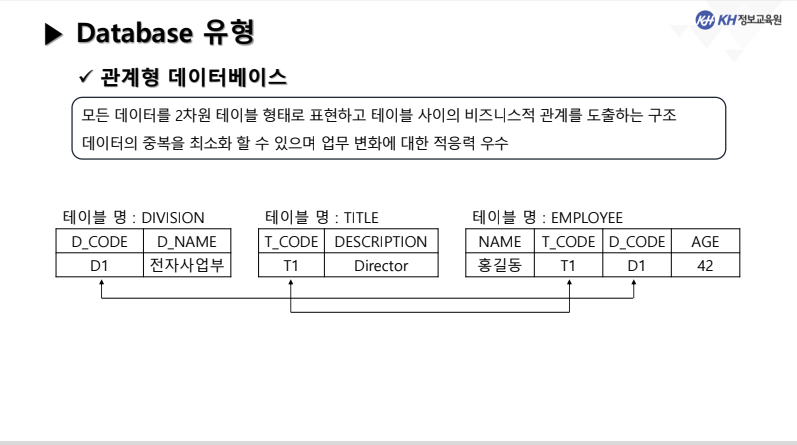
3) 관계형 데이터베이스:
모든 데이터를 2차원 테이블 형태로 표현하고 테이블 사이의 비즈니스적 관계를 도출하는 구조
데이터의 중복을 최소화할 수 있으면 업무 변화에 대한 적응력 우수
2. SELECT
SQL(Structured Query Language)
- 관계형 데이터베이스에서 데이터를 조회하거나 조작하기 위해 사용하는 표준 검색 언어
원하는 데이터를 찾는 방법이나 절차를 기술하는 것이 아닌 조건을 기술하여 작성
- 주요 데이터 타입
- NUMBER:
숫자
- CHAR:
고정길이 문자
- VARCHAR2:
가변길이 문자
- DATE:
날짜

SELECT문
- 데이터를 조회한 결과를 Result Set이라고 하는데
SELECT구문에 의해 조회된 행들의 집합을 의미
- Result Set은 0개 이상의 행이 포함될 수 있고
Result Set은 특정한 기준에 의해 정렬 가능
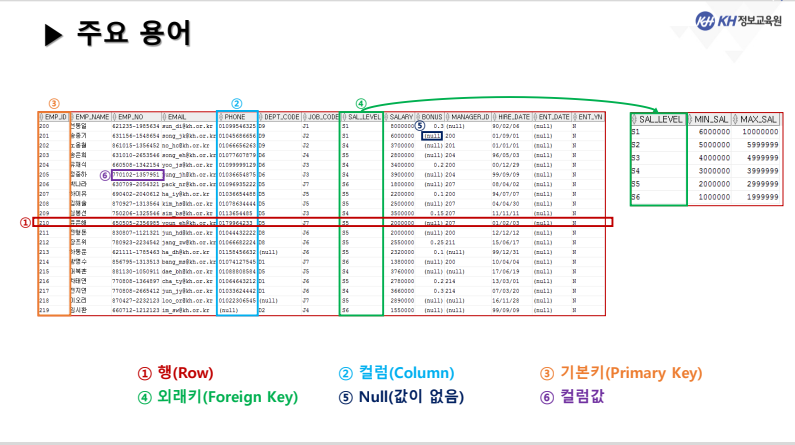
- 한 테이블의 특정 컬럼, 특정 행, 특정 행/컬럼 또는
여러 테이블의 특정 행/컬럼 조회 가능
SELECT 컬럼명
FROM 테이블명
WHERE 조건식;
SELECT *
FROM EMPLOYEE
WHERE SALARY >= 3000000;
- 주석은 --와 /* */를 사용한다.
- 컬럼 값 산술 연산이 가능하다.
- 해석 순서는 FROM절, WHERE절, SELECT절 순서임에 유의
각종 SELECT 구문
- 별칭
1) 컬럼명 AS 별칭:
문자 O, 띄어쓰기 X, 특수문자 X
2) 컬럼명 AS "별칭":
문자 O, 띄어쓰기 O, 특수문자 O
3) 컬럼명 별칭:
문자 O, 띄어쓰기 X, 특수문자 X
4) 컬럼명 "별칭":
문자 O, 띄어쓰기 O, 특수문자 O
SELECT EMP_NAME, SALARY * 12 AS 연봉
FROM EMPLOYEE;
- 리터럴:
임의로 지정한 문자열을 SELECT절에 사용하면 테이블에 존재하는 데이터처럼 활용 가능

- DISTINCT:
컬럼에 포함된 데이터 중 중복 값을 제외하고 한번씩만 표시하고자 할 때 사용
SELECT DISTINCT JOB_CODE
FROM EMPLOYEE;
WHERE절
SELECT EMP_NAME, DEPT_CODE
FROM EMPLOYEE
WHERE DEPT_CODE = 'D9';
- 오라클 DB는 작성된 값이 다른 형식의 데이터 타입이라도
표기법이 다른 데이터 타입과 일치한다면 자동으로 데이터 타입 변경
SELECT EMP_NO, EMP_NAME, HIRE_DATE
FROM EMPLOYEE
WHERE HIRE_DATE >= '1990/01/01'
AND HIRE_DATE <= '2000/12/31';
SELECT EMP_NAME, SALARY
FROM EMPLOYEE
WHERE SALARY >= '3000000';
연결 연산자와 논리 연산자

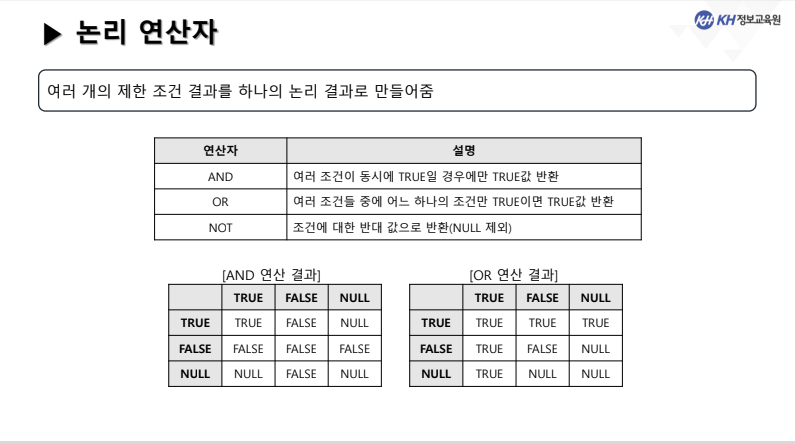
비교 연산자
- 대소 비교:
<, <=, >, >=
- 동등 비교(같다): =
- 동등 부정(같지 않다):
<>, !=, ^=

LIKE 연산자 등
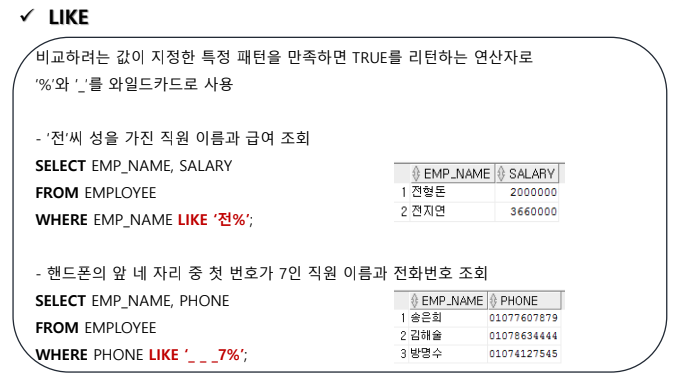
- 검색 대상과 와일드카드가 겹치는 경우 ESCAPE문을 사용해 탈출시킨다.
SELECT EMP_ID, EMP_NAME, EMAIL
FROM EMPLOYEE
WHERE EMAIL LIKE '___$_%' ESCAPE '$';


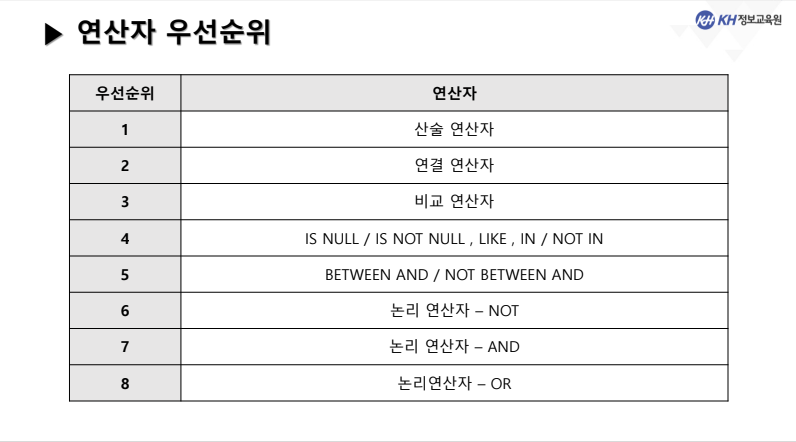
- ORDER BY절:
SELECT문의 조회 결과를 정렬할 때 사용하는 구문
SELECT문의 제일 마지막에 해석
문자열, 날짜, 숫자 모두 정렬 가능
SELECT 컬럼명 AS 별칭
FROM 테이블명
WHERE 조건식
ORDER BY 컬럼명 | 별칭 | 컬럼 순서(오름차순 ASC/내림차순 DESC)
[NULLS FIRST | LAST]
- ORDER BY 정렬 중첩:
큰 분류를 먼저 정렬하고 내부 분류를 다음에 정렬하는 방식
SELECT EMP_NAME, DEPT_CODE, SALARY
FROM EMPLOYEE
ORDER BY DEPT_CODE DESC, SALARY DESC;
