오늘은 게임 프로젝트 발표하는 날이다.
또한 평가일이라 수업 내용이 많지는 않을 것 같다.
1. 서브쿼리(Subquery)
서브쿼리
- 나의 SQL문 안에 포함된 또 다른 SQL문
- 메인 쿼리가 실행되기 전 한 번만 실행됨
- 비교 연산자의 오른쪽에 기술해야 하며 반드시 괄호로 묶어야 함
- 서브쿼리와 비교할 항목은 반드시 서브쿼리의 SELECT한 항목의 개수와 자료형을 일치시켜야 함
SELECT EMP_ID, EMP_NAME, JOB_CODE, SALARY FROM EMPLOYEE WHERE SALARY >= (SELECT AVG(SALARY) FROM EMPLOYEE);

2. 서브쿼리의 종류
단일행 서브쿼리
- 행 1개, 열 1개
- 서브쿼리의 조회 결과 값의 개수가 1개인 서브쿼리
- 단일행 서브쿼리 앞에는 비교 연산자 사용
다중행 서브쿼리
- 행 n개, 열 1개
- 서브쿼리의 조회 결과 값의 행이 여러 개인 서브쿼리
- 다중행 서브쿼리 앞에는 일반 비교 연산자 사용 불가
- IN / NOT IN:
여러 개의 결과값 중에서 한개라도 일치하는 값이 있다면 혹은 없다면- > ANY, < ANY:
여러개의 결과값 중에서 한개라도 큰 / 작은 경우
가장 작은 값보다 큰가? / 가장 큰 값보다 작은가?- > ALL, < ALL:
여러개의 결과값의 모든 값보다 큰 / 작은 경우
가장 큰 값보다 큰가? / 가장 작은 값보다 작은가?- EXISTS / NOT EXISTS:
값이 존재하는가? / 존재하지 않는가?
서브쿼리 조회 결과가 1행 이상이면 메인 쿼리 행을 결과에 포함SELECT EMP_ID, EMP_NAME, DEPT_TITLE, JOB_NAME, '사수' AS 구분 FROM EMPLOYEE LEFT JOIN DEPARTMENT ON (DEPT_ID = DEPT_CODE) JOIN JOB USING (JOB_CODE) WHERE EMP_ID IN (SELECT DISTINCT MANAGER_ID FROM EMPLOYEE WHERE MANAGER_ID IS NOT NULL);SELECT EMP_ID, EMP_NAME, JOB_NAME, SALARY FROM EMPLOYEE JOIN JOB USING (JOB_CODE) WHERE JOB_NAME = '대리' AND SALARY > ANY (SELECT SALARY FROM EMPLOYEE JOIN JOB USING (JOB_CODE) WHERE JOB_NAME = '과장');
다중열 서브쿼리
- 행 1개, 열 n개
- 서브쿼리의 조회 결과 컬럼의 개수가 여러 개인 서브쿼리
SELECT EMP_NAME, JOB_NAME, DEPT_TITLE, HIRE_DATE FROM EMPLOYEE NATURAL JOIN JOB JOIN DEPARTMENT ON (DEPT_CODE = DEPT_ID) WHERE (DEPT_TITLE, JOB_NAME) = (SELECT DEPT_TITLE, JOB_NAME FROM EMPLOYEE NATURAL JOIN JOB JOIN DEPARTMENT ON (DEPT_CODE = DEPT_ID) WHERE ENT_YN = 'Y' AND SUBSTR(EMP_NO, 8, 1) = '2');
다중행 다중열 서브쿼리
- 행 n개, 열 n개
- 서브쿼리의 조회 결과 컬럼의 개수와 행의 개수가 여러 개인 서브쿼리
SELECT EMP_ID, EMP_NAME, JOB_CODE, SALARY FROM EMPLOYEE WHERE (JOB_CODE, SALARY) IN (SELECT JOB_CODE, TRUNC(AVG(SALARY), -4) FROM EMPLOYEE GROUP BY JOB_CODE);
상관 서브쿼리
- 서브쿼리가 만든 결과 값을 메인 쿼리가 비교 연산할 때
메인 쿼리 테이블의 값이 변경되면 서브쿼리의 결과 값도 바뀌는 서브쿼리- 메인 쿼리 각 행마다 메인 -> 서브 -> 메인 순서로 해석
SELECT EMP_ID, EMP_NAME, DEPT_TITLE, MANAGER_ID FROM EMPLOYEE MAIN LEFT JOIN DEPARTMENT ON (DEPT_ID = DEPT_CODE) WHERE EXISTS (SELECT EMP_ID FROM EMPLOYEE SUB WHERE SUB.EMP_ID = MAIN.MANAGER_ID);
스칼라 서브쿼리
- SELECT절에 사용되는 서브쿼리 결과로 1행만 반환
- 상관쿼리와 같이 사용하는 경우가 많음
SELECT EMP_NAME, JOB_CODE, SALARY, (SELECT FLOOR(AVG(SALARY)) FROM EMPLOYEE SUB WHERE SUB.JOB_CODE = MAIN.JOB_CODE) 평균 FROM EMPLOYEE MAIN;SELECT EMP_ID, EMP_NAME, MANAGER_ID, NVL((SELECT EMP_NAME FROM EMPLOYEE SUB WHERE SUB.EMP_ID = MAIN.MANAGER_ID), '없음') 관리자명 FROM EMPLOYEE MAIN;
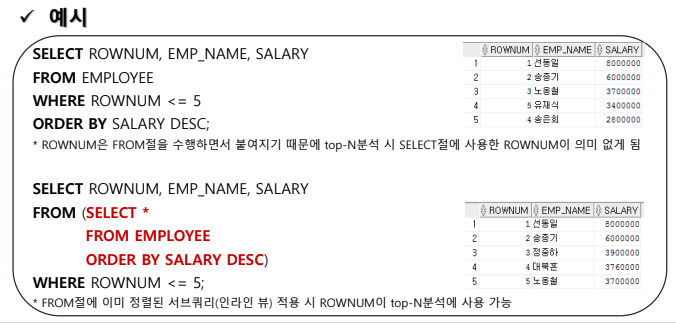
인라인 뷰
- FROM 절에서 서브쿼리를 사용하는 경우
SELECT ROWNUM, EMP_NAME, SALARY FROM (SELECT EMP_NAME, SALARY FROM EMPLOYEE ORDER BY SALARY DESC) -- 메인쿼리 안에 포함된 뷰 생성 구문(인라인 뷰) WHERE ROWNUM <= 5;
- 인라인 뷰 사용시 컬럼명에 유의해야 한다.
SELECT * FROM (SELECT DEPT_CODE, DEPT_TITLE, FLOOR(AVG(SALARY)) 평균 FROM EMPLOYEE LEFT JOIN DEPARTMENT ON (DEPT_CODE = DEPT_ID) GROUP BY DEPT_CODE, DEPT_TITLE ORDER BY 평균 DESC) WHERE 평균 = 5900000; -- 메인쿼리에서 인라인 뷰의 컬럼명을 그대로 사용
3. 서브쿼리 보조 기능
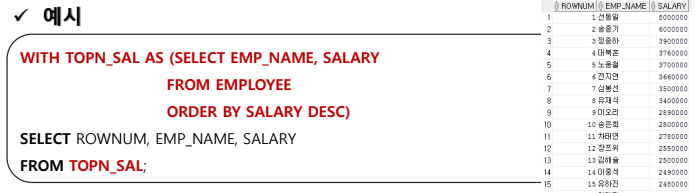
WITH
- 서브쿼리에 이름을 붙여주고 사용시 이름을 사용하게 함
- 인라인 뷰로 사용될 서브쿼리에 주로 사용됨
- 같은 서브쿼리가 여러 번 사용될 경우 중복 작성을 피할 수 있고 실행속도도 빨라진다는 장점이 있음
WITH TOP_SALARY AS (SELECT EMP_NAME, SALARY FROM EMPLOYEE ORDER BY SALARY DESC) SELECT ROWNUM, EMP_NAME, SALARY FROM TOP_SALARY;
RANK() OVER
- 순위를 만들어낼 수 있는 함수
- SELECT 절에서만 사용 가능
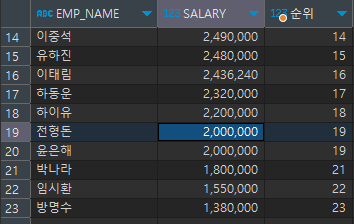
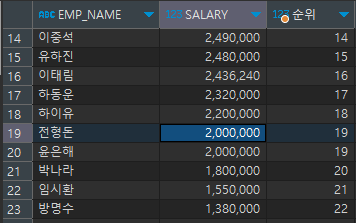
SELECT EMP_NAME, SALARY, RANK() OVER(ORDER BY SALARY DESC) 순위 FROM EMPLOYEE;
- DENSE_RANK() OVER:
동일한 순위 이후의 등수를 이후의 순위로 계산하는 함수
(공동 1위가 2명이어도 다음 순위는 2위)SELECT EMP_NAME, SALARY, DENSE_RANK() OVER(ORDER BY SALARY DESC) 순위 FROM EMPLOYEE;