개요
하나의 마이크로서비스를 하나 이상의 인스턴스에서 기동을 시켰을 때 클라이언트 요청이 여러개가 들어왔을 때 그것을 부하분산 처리하기 위해서 우리가 여러개의 인스턴스를 띄울 수 있다. (로드밸런싱) 마이크로서비스를 기동을 할 때, 우리가 서비스 port를 지정하게 되는데, 서비스 port를 0번으로 지정을 하게되면, 랜덤 port가 지정이 되서 여러개의 인스턴스를 실행한다 하더라도 충돌이 발생하지 않는다.
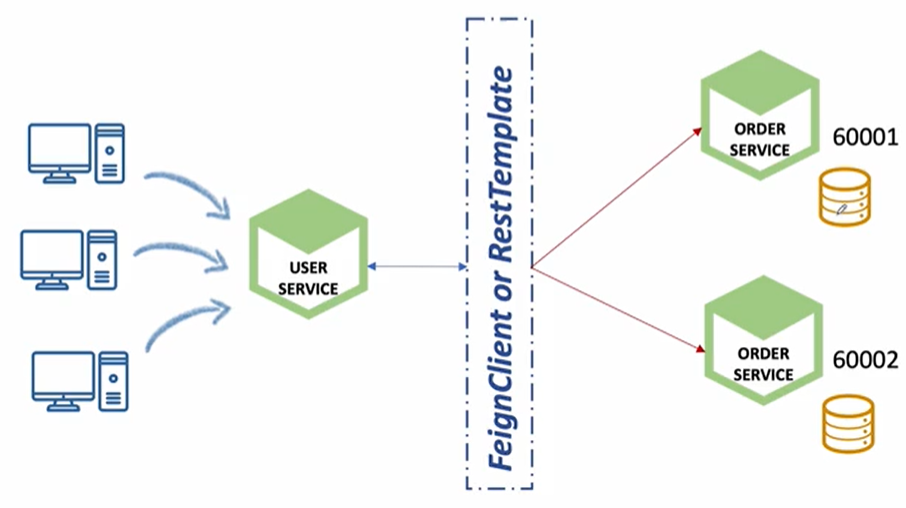
order-service 인스턴스가 기동이될 때 H2라는 내장DB가 같이 기동이 된다. 각각의 데이터베이스가 각각의 인스턴스에 사용되고 있다.
-> 하나의 주문에 대해서 나눠서 저장되어 있는 주문 데이터 값을 동기화를 어떻게 처리할 것인가?
데이터 동기화를 어떻게 할 것인가?
1.하나의 Database 사용
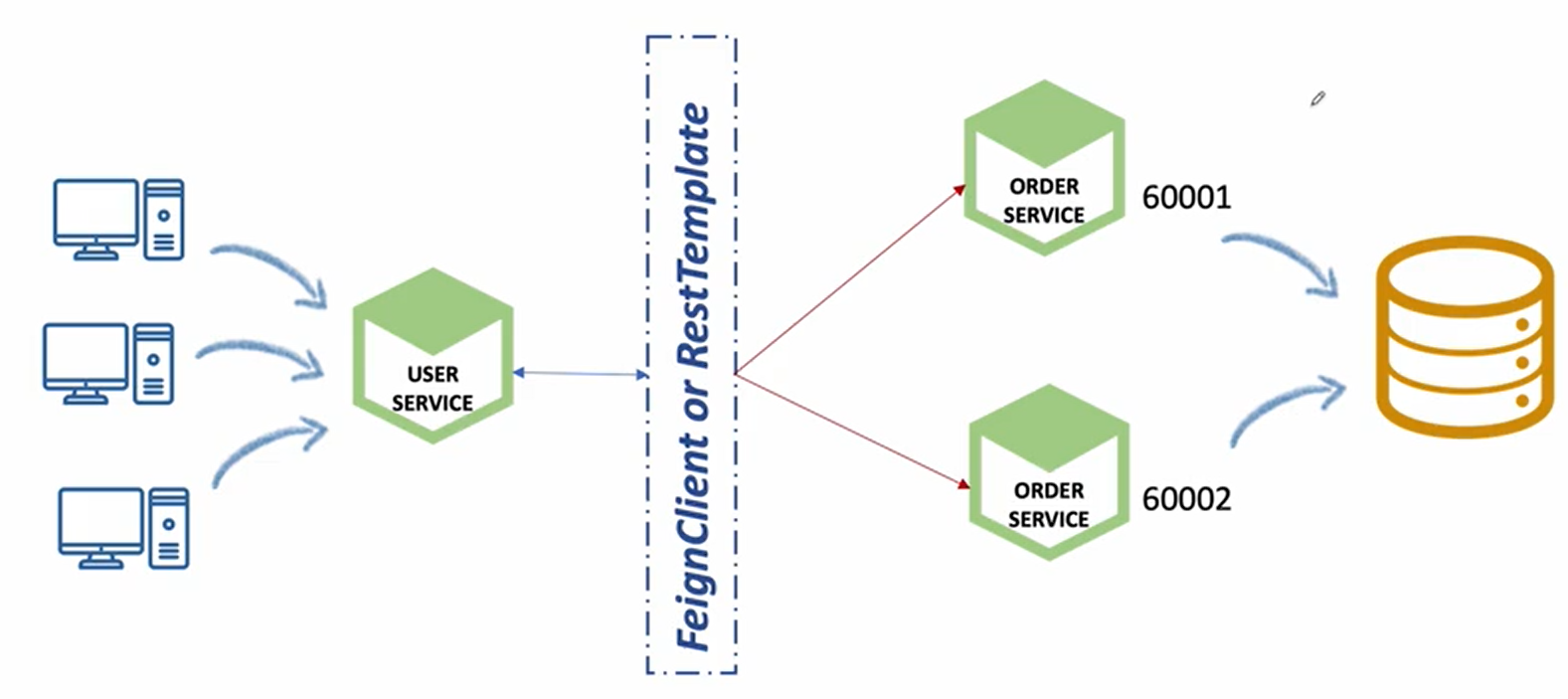
물리적으로 떨어져 있는 인스턴스를 하나의 데이터베이스에 저장하기 위해서는 트랜잭션 관리를 잘 해줘야한다.(동시성)
2. Database간의 동기화
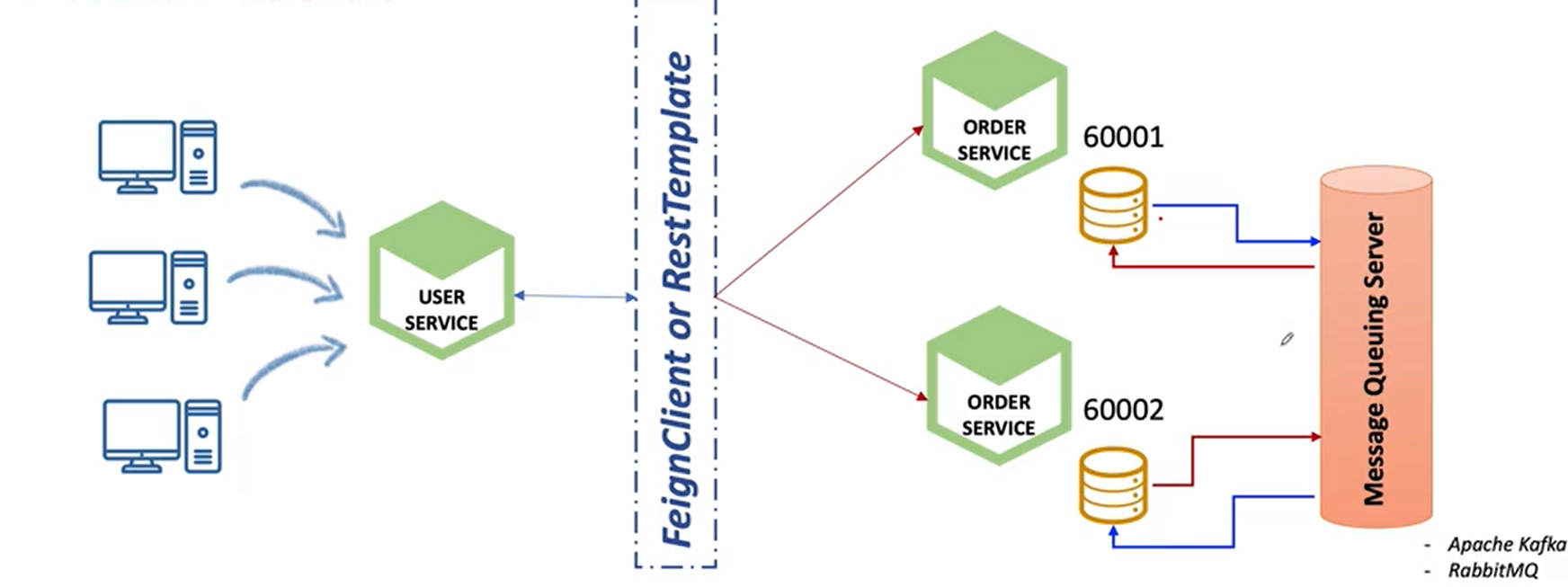
각각 1번과 2번의 데이터베이스에서 필요한 데이터 값을 하나씩 전달하는 방법이 아니라 중간에 메시지 큐잉이라는 서버를 통해서(Apache, Kafka) 한 쪽에서 발생했던 데이터를 메시지 큐잉 서버에 전달한다.
메시지 큐잉서버에 변경된 데이터가 있으면 알려달라는 구독 신청을 하면 데이터가 들어오면 해당 데이터 값을 데이터베이스에 업데이트 시켜준다.
-> 두 가지 데이터베이스에서 동기화가 가능
3. Kafka Connector + DB
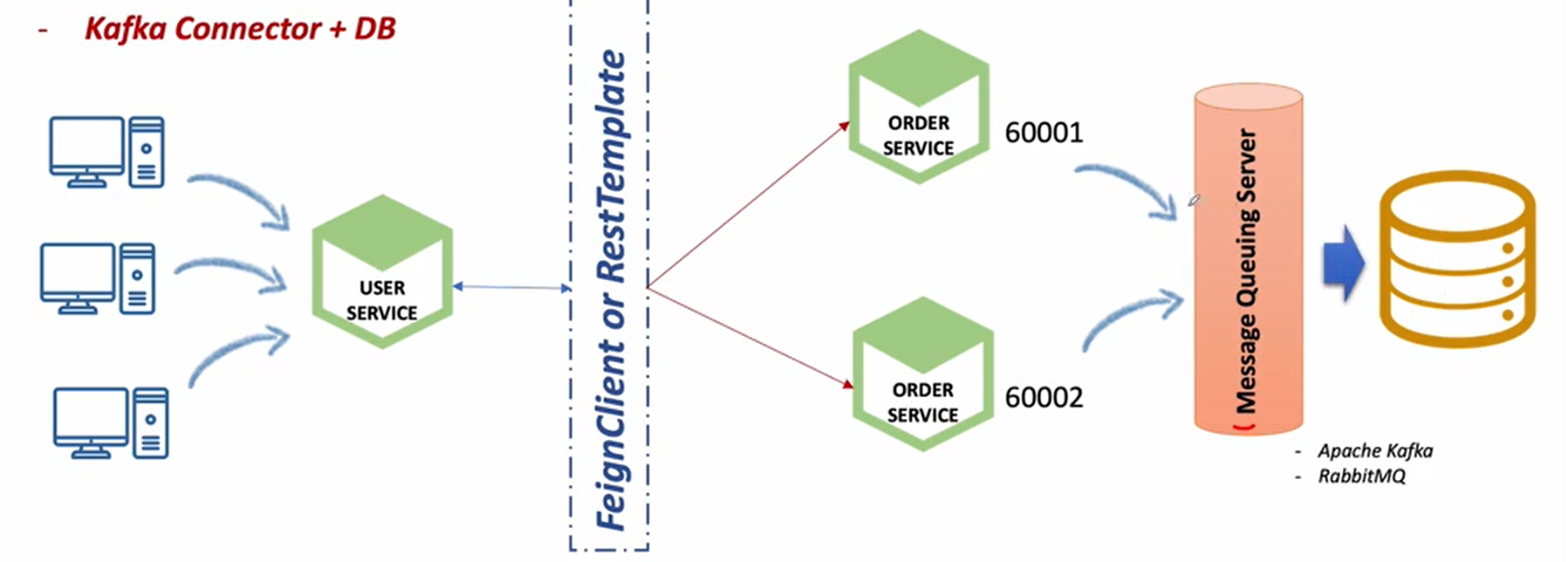
하나의 데이터베이스 사용과 데이터 베이스 동기화의 복합 예제
메시지 큐잉 서버를 사용하고 데이터베이스도 하나를 사용
첫 번째 order service 두 번째 order service에서 발생한 데이터를 메시지 큐잉 서버에 메시지를 보내게 된다. 메시지 큐잉 서버 자체는 이런 처리를 하기 위해 특화되어 있는 시스템이다보니 메시지가 전달되면 순차적으로 해석해서 이 메시지를 사용하고자 하는 곳에 사용할 수 있게끔 뿌려주는 중간 매개체(미들웨어) 역할을 한다. 아무리 많은 역할을 한다 하더라도 1초안에 수만건의 데이터를 처리할 수 있는 기술이기 때문에 동시성에 대한 문제라던가 시간적인 배분에 대한 것들은 충분히 해결할 수 있는 능력이 있다.
그리고 메시지 큐잉에 전달된 데이터를 하나의 단일 데이터베이스에 저장한다고 하면 각각의 order service가 자신이 필요한 데이터를 가져갔을때 동일한 데이터베이스를 사용하기 때문에 데이터 간에 일치하지 않는 문제는 해결할 수 있다.
데이터 동기화를 위한 Kafka 활용 1
Apache Kafka
- Apache Software Foundation의 Scalar 언어로 된 오픈 소스 "메시지 브로커" 프로젝트
- Open Source Message Broker Project
- 링크드인(Linked-in)에서 개발, 2011년 오픈 소스화
- 2014년 11월 링크드인에서 Kafka를 개발하던 엔지니어들이 Kafka 개발에 집중하기 위해 Confluent라는 회사 창립
- 실시간 데이터 피드를 관리하기 위해 통일된 높은 처리량, 낮은 지연 시간을 지닌 플랫폼 제공
- Apple, Netflix, Shopify, Yelp, Kakao, New York Times, Cisco, Ebay, Paypal, Hyperledger Fabric, Uber, Salesforce.com 등이 사용
💡 메시지 브로커?
: 특정한 리소스에서 다른쪽의 리소스(서비스, 시스템)으로 메시지를 전달할 떄 사용되는 서버
카프카 사용 전 시스템 구성
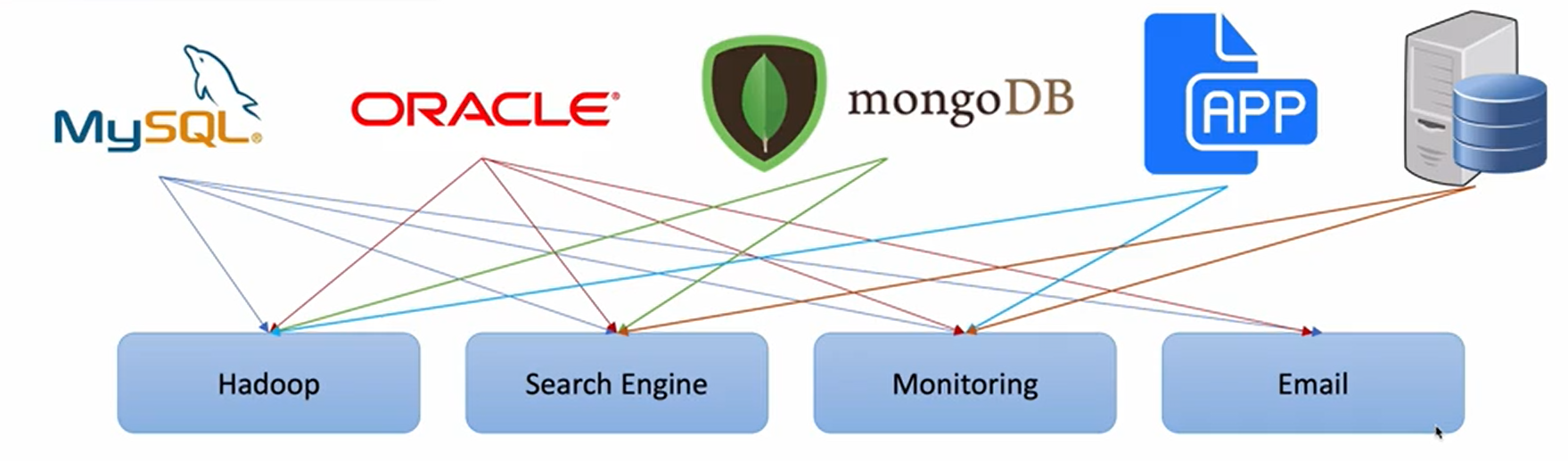
- End-to-End 연결 방식의 아키텍처
- 데이터 연동의 복잡성 증가 (HW, 운영체제, 장애 등)
- 서로 다른 데이터 Pipeline 연결 구조
- 확장이 어려운 구조
이런 문제점을 해결하기 위해서 카프카가 탄생
- 모든 시스템으로 데이터를 실시간으로 전송하여 처리할 수 있는 시스템
- 데이터가 많아지더라도 확장이 용이한 시스템
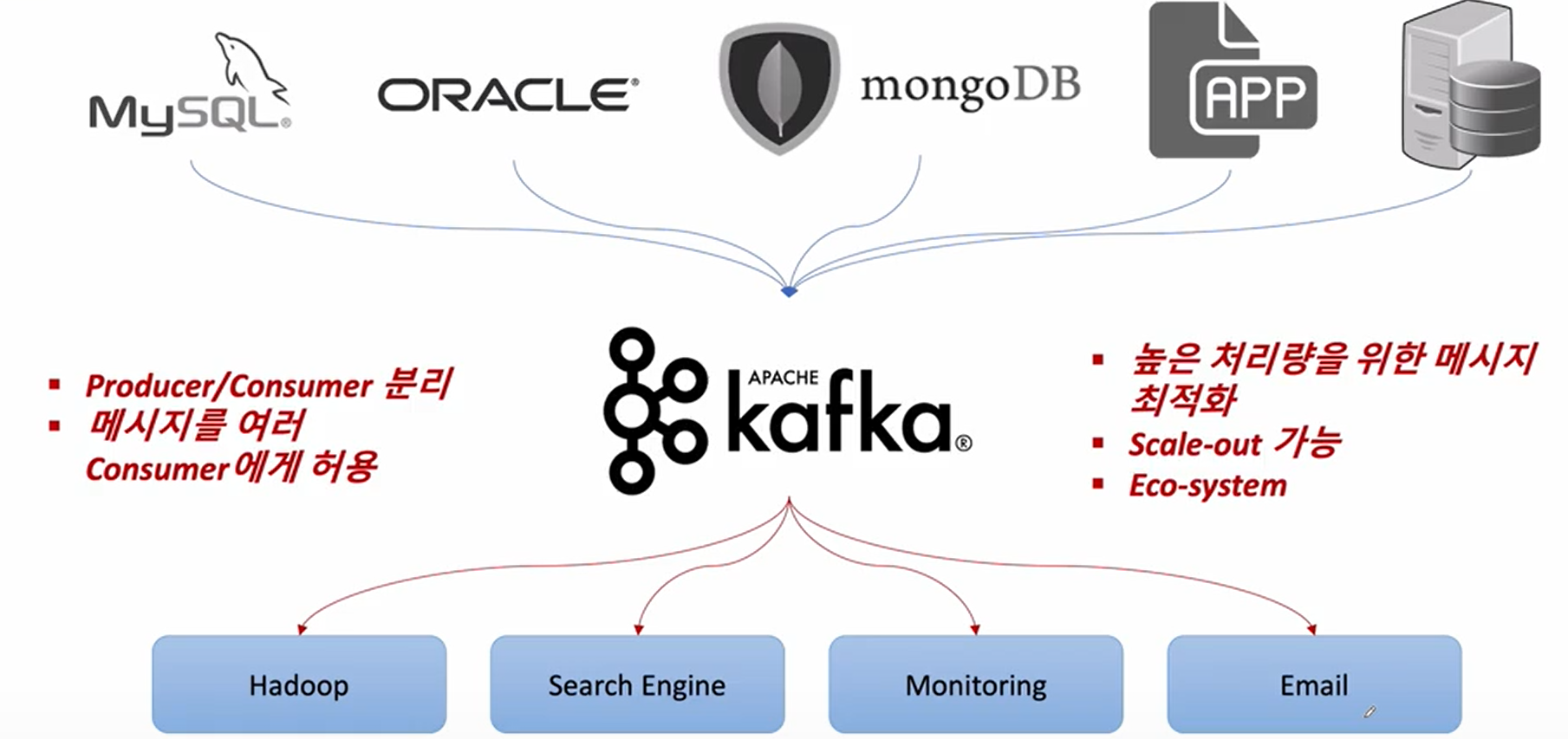
중간에 카프카라는 시스템을 도입함으로써 자신들이 보내는 데이터가 어떠한 시스템에 저장되는지 관계하지 않고 카프카 하나만 상대하면 된다. 받는 쪽도 카프카 단일 포맷으로 받을 수 있다.
-> 보내는 쪽과 받는 쪽이 누가 보냈고 누가 보냈는지 신경쓰지 않는 상태에서 메시지를 받는게 가능해짐
- 메시지를 보내는 쪽: Producer
- 메시지를 받는 쪽: Consumer
Kafka Broker
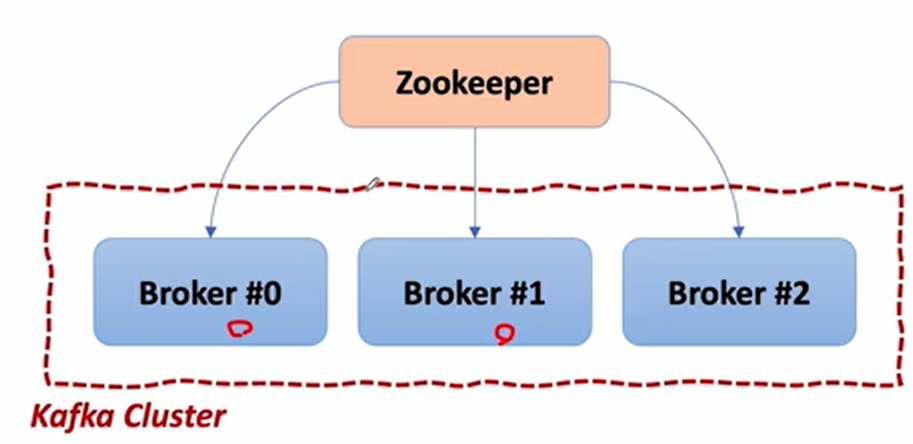
- 실행 된 Kafka 애플리케이션 서버
- 3대 이상의 Broker Cluster 구성
- Zookeeper 연동
- 역할: 메타데이터 (Broker ID, Controller ID 등) 저장
- Controller 정보 저장
- n개 Broker 중 1대는 Controller 기능 수행
- Controller 역할
- 각 Broker에게 담당 파티션 할당 수행
- Broker 정상 동작 모니터링 관리
- Controller 역할
💡 Broker는 메시지 저장 Zookeeper는 Broker 중재자라고 보면된다.
Kafka 서버 기동 - Windows
- Windows에서 Kafka 실행 명령어는 $KAFKA_HOME\bin\windows 폴더에 저장되어있다.
.\bin\windows\kafka-server-start.bat .\config\server.propertiesZookeeper 및 Kafka 서버 기동
$KAFKA_HOME/bin/zookeeper-server-start.sh $KAFKA_HOME/config/zookeeper.properties
ex) .\bin\windows\zookeeper-server-start.bat .\config\zookeeper.properties
$KAFKA_HOME/bin/kafka-server-start.sh $KAFKA_HOME/config/server.properties
ex) .\bin\windows\kafka-server-start.bat .\config\server.propertiesKafka는 Kafka 자체를 관리해줄 수 있는 코디네이터(Zookeeper)가 필요하다.
Topic 생성
$KAFKA_HOME/bin/kafka-topics.sh --create --topic quickstart-events --bootstrap-server localhost:9092 --partitions 1
ex) .\bin\windows\kafka-topics.bat --create --topic quickstart-events --bootstrap-server localhost:9092 --partitions 1Kafka는 기본적으로 메시지를 보내면 그 데이터는 topic이라는 곳에 저장이된다.
(Topic는 임의로 자유롭게 생성할 수 있다)
Topic을 생성한 다음에 Producer는 Topic에 메세지를 보내게 된다.
Topic에 관심이 있다고 등록한 Consumer가 있을 것이다.
-> 구독 서비스(Topic)에 새로운 소식이나 알람이 들어왔을 때 그걸 받겠다고 신청
-> 그러면 Topic에 전달된 내용이 있을 경우에 해당하는 Topic에 전달된 메시지를 Topic에 관심이 있다고 했던 Consumer에 일괄적으로 전달되는 방식(BroadCast)
💡 보내거나 받는 쪽은 Topic을 통해서 전달하거나 전달 받는 것
--
Topic 목록 확인
$KAFKA_HOME/bin/kafka-topics.sh --bootstrap-server localhost:9092 --list
ex) .\bin\windows\kafka-topics.bat --bootstrap-server localhost:9092 --listTopic 정보 확인 (좀 더 상세)
$KAFKA_HOME/bin/kafka-topics.sh --describe --topic quickstart-events --bootstrap-server localhost:9092Kafka Producer/Consumer 테스트
메시지 생산 (Producer)
$KAFKA_HOME\bin\windows\kafka-console-producer.bat --broker-list localhost:9092 --topic quickstart-events
ex) .\bin\windows\kafka-console-producer.bat --broker-list localhost:9092 --topic quickstart-events메시지 소비 (Consumer)
$KAFKA_HOME\bin\kafka-console-consumer.bat --bootstrap-server localhost:9092 --topic quickstart-events --from-beginning
ex) .\bin\windows\kafka-console-consumer.bat --bootstrap-server localhost:9092 --topic quickstart-events --from-beginning- --from-beginning: 모든 메시지를 처음부터 얻어오기 위함
Kafka Connect
- Kafka Connect를 통해 Data를 Import/Export 가능
- 코드 없이 Configuration으로 데이터를 이동
- Standalone mode, Distribution mode 지원
- RESTful API 통해 지원
- Stream 또는 Batch 형태로 데이터 정송 가능
- 커스텀 Connector를 통한 다양한 Plugin 제공(File, S3, Hive, Mysql, etc ...)

- 데이터를 가져오는 쪽: Kafka Connect Source
- 데이터를 보내는 쪽: Kafka Connect Sink
특정한 Resource에서 데이터를 가지고 와서 Kafka Cluster에 저장을 한다.
-> 그때 관여 하는 것이 Connect Source
이 Source에는 기존에 있었던 Database 라던가 File 등이 가능 할 것이고 반대로 Kafka Connect에 저장되어 있었던 데이터 값을 Kafka Connect Sink라는 것을 통해 다른쪽으로 Export 할 수 있다.
MariaDB 연동
MariaDB 설치 - Windows
Dependency 추가
implementation group: 'org.mariadb.jdbc', name: 'mariadb-java-client'MariaDB h2-console 접속
테이블 생성
create table users(
id int auto_increment primary key,
user_id varchar(20),
pwd varchar(20),
name varchar(20),
created_at datetime default NOW()
);
create table orders (
id int auto_increment primary key,
product_id varchar(20) not null,
qty int default 0,
unit_price int default 0,
total_price int default 0,
user_id varchar(50) not null,
order_id varchar(50) not null,
created_at datetime default NOW()
);Kafka Connect 사용하기
Kafka Connect 설치, JDBC Connector 설정
생략
Kafka Connect 실행
.\bin\windows\connect-distributed.bat .\etc\kafka\connect-distributed.propertiesconnect 실행 시
- connect-configs
- connect-offsets
- connect-status
와 같은 topic들이 추가가 된다.
Kafka Source Connect 추가 (MariaDB)
echo '
{
"name" : "my-source-connect",
"config" : {
"connector.class" : "io.confluent.connect.jdbc.JdbcSourceConnector",
"connection.url":"jdbc:mariadb://localhost:3307/mydb",
"connection.user":"root",
"connection.password":"password",
"mode": "incrementing",
"incrementing.column.name" : "id",
"table.whitelist":"users1",
"topic.prefix" : "my_topic_",
"tasks.max" : "1"
}
}
' | curl -X POST -d @- http://localhost:8083/connectors --header "content-Type:application/json"- Kafka Connect 목록 확인
curl http://localhost:8083/connectors | jq- Kafka Connect 확인
curl http://localhost:8083/connectors/my-source-connect/status | jqKafka Sink Connect 추가 (MariaDB)
echo '
{
"name":"my-sink-connect",
"config":{
# 어떤 connector를 쓸것인가
"connector.class":"io.confluent.connect.jdbc.JdbcSinkConnector",
"connection.url":"jdbc:mariadb://localhost:3307/mydb",
"connection.user":"root",
"connection.password":"password",
"auto.create":"true",
"auto.evolve":"true",
"delete.enabled":"false",
"tasks.max":"1",
"topics":"my_topic_users1"
}
}
'| curl -X POST -d @- http://localhost:8083/connectors --header "content-Type:application/json"Topic에 Source Connect에서 데이터를 전달하게 되면 Topic에 데이터가 쌓임
Sink Connect가 하는 일은 Topic에 전달된 데이터를 가져와서 사용하는 곳이다.
- auto.create: sink connect를 생성함과 동시에 topic의 이름과 같은 테이블을 생성한다.
Kafka Producer를 이용해서 Kafka Topic에 데이터 직접 전송
- Kafka-console-producer에서 데이터 전송 -> Topic에 추가 -> MariaDB에 추가
.\bin\windows\kafka-console-producer.bat --broker-list localhost:9092 --topic my_topic_users
{"schema":{"type":"struct","fields":
[{"type":"int32","optional":false,"field":"id"},
{"type":"string","optional":true,"field":"user_id"},
{"type":"string","optional":true,"field":"pwd"},
{"type":"string","optional":true,"field":"name"},
{"type":"int64","optional":true,"name":"org.apache.kafka.connect.data.Timestamp","version":1,"field":"created_at"}],"optional":false,"name":"users1"},"payload":{"id":7,"user_id":"user4","pwd":"user4444","name":"User4 name","created_at":1680643371000}}데이터 동기화 Orders -> Catalogs
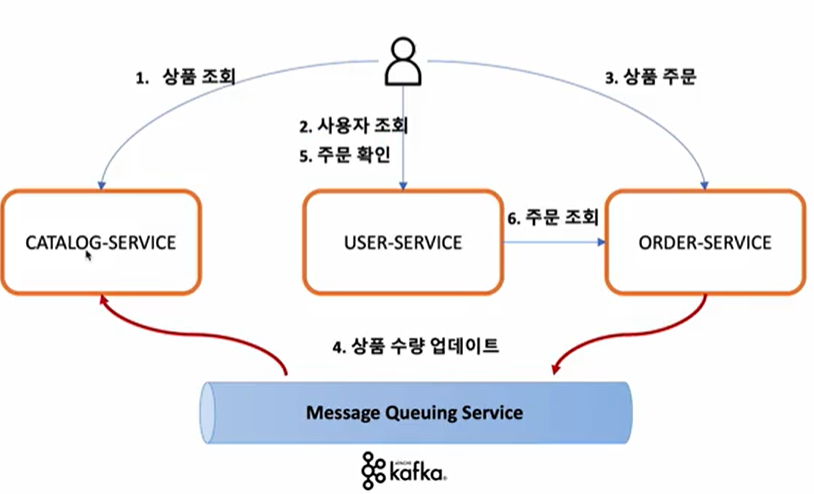
- Order Service에 요청 된 주문의 수량 정보를 Catalogs Service에 반영
- Orders Service에서 Kafka Topic으로 메시지 전송 -> Producer
- Catalogs Service에서 Kafka Topic에 전송 된 메시지 취득 -> Consumer
Dependency 추가
implementation 'org.springframework.kafka:spring-kafka:2.9.1'Catalogs Service 수정
KafkaConsumerConfig.java
/*
Catalogs Service에서 Kafka Topic에 전송 된 메시지 취득 -> Consumer
*/
// KafkaListener 빈을 생성하기 위한 기능을 활성화
@EnableKafka
@Configuration
public class KafkaConsumerConfig {
// Kafka Consumer를 생성하기 위한 팩토리 메서드
// Topic에 접속하기 위한 정보가 들어 있음
@Bean
public ConsumerFactory<String, String> consumerFactory() {
Map<String, Object> properties = new HashMap<>();
// 사용하고자 하는 Kafka 서버의 주소
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "127.0.0.1:9092");
/*
데이터를 지정을 해줄 때 Topic에 저장되는 값 자체가 어떠한 형태로 되어있는가를 지정할 수 있다.
JSON 형식의 포맷이기 때문에 Key 값과 Value가 한 세트가되서 저장이 된다.
Key, Value 한 세트가 저장되어 있을 때, 그 값을 가져와서
역으로 해석을해서 사용을 해야한다. -> DESERIALIZER 타입 지정
데이터를 하나 만들어서 다른쪽으로 전달하는 용도로써 압축하는 과정을 SERIALIZER라고 가정하면
다시 원래의 형태로 풀어서 쓰기 위한 과정을 DESERIALIZER라고 보면 된다.
*/
// Consumer가 속한 Consumer Group 설정
properties.put(ConsumerConfig.GROUP_ID_CONFIG, "127.0.0.1:9092");
// Consumer가 읽어들이는 데이터의 key와 value의 직렬화 방법을 지정
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
return new DefaultKafkaConsumerFactory<>(properties);
}
// Kafka Listener(Topic에 변경사항이 있는지 Listening)를 생성하기 위한 팩토리 메서드 정의
// 만약 Topic에 변경사항이 생기면 해당하는 값을 바로 캐치
@Bean
public ConcurrentKafkaListenerContainerFactory<String, String> kafkaListenerContainerFactory() {
ConcurrentKafkaListenerContainerFactory<String, String> kafkaListenerContainerFactory
= new ConcurrentKafkaListenerContainerFactory<>();
kafkaListenerContainerFactory.setConsumerFactory(consumerFactory());
return kafkaListenerContainerFactory;
}
}KafkaConsumer.java
// Topic에 변경되어진 값을 가져와서 실제 데이터베이스에 반영해주는 작업을 해주는 Consumer 역할
@Service
@Slf4j
public class KafkaConsumer {
CatalogRepository repository;
@Autowired
public KafkaConsumer(CatalogRepository repository) {
this.repository = repository;
}
// 'example-catalog-topic' 토픽에서 메시지를 수신하는 메서드
@KafkaListener(topics = "example-catalog-topic")
public void updateQty(String kafkaMessage) {
log.info("Kafka Message: ->" + kafkaMessage);
Map<Object, Object> map = new HashMap<>();
/*
ObjectMapper를 사용하여 kafkaMessage에서 데이터를 추출
메시지 데이터는 JSON 형식으로 되어 있으며 이를 Map 객체로 변환한다.
*/
ObjectMapper mapper = new ObjectMapper();
try {
map = mapper.readValue(kafkaMessage, new TypeReference<Map<Object, Object>>() {});
} catch (JsonProcessingException ex) {
ex.printStackTrace();
}
/*
변환된 Map 객체에서 productId값을 추출하여 CatalogEntity 객체를 조회한다.
조회된 CatalogEntity 객체의 stock 값을 업데이트하여 repository.save를 호출하여 데이터를 저장한다.
*/
CatalogEntity entity = repository.findByProductId((String) map.get("productId"));
if (entity != null) {
entity.setStock(entity.getStock() - (Integer)map.get("qty"));
repository.save(entity);
}
}
}Orders Service 수정
KafkaProducerConfig.java
/*
Order Service에서 Kafka Topic으로 메시지 전송 -> Producer
*/
@EnableKafka
@Configuration
public class KafkaProducerConfig {
// Kafka Producer를 생성하기 위한 설정 정보를 포함하는 팩토리 클래스
@Bean
public ProducerFactory<String, String> producerFactory() {
Map<String, Object> properties = new HashMap<>();
// 사용하고자하는 Kafka서버의 주소
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "127.0.0.1:9092");
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
return new DefaultKafkaProducerFactory<>(properties);
}
// Kafka Producer를 템플릿으로 사용하여 Kafka 메시지를 보내는 데 사용
@Bean
public KafkaTemplate<String, String> kafkaTemplate() {
return new KafkaTemplate<>(producerFactory());
}
}KafkaProducer.java
// Kafka Template을 사용하여 메시지를 Kafka에 보내는 역할
@Service
@Slf4j
public class KafkaProducer {
private KafkaTemplate<String, String> kafkaTemplate;
@Autowired
public KafkaProducer(KafkaTemplate<String, String> kafkaTemplate) {
this.kafkaTemplate = kafkaTemplate;
}
// OrderDto객체를 JSON 문자열로 변환하고 KafkaTemplate의 send를 호출하여
// Kafka에 메시지를 보냄
public OrderDto send(String topic, OrderDto orderDto) {
ObjectMapper mapper = new ObjectMapper();
String jsonInString = "";
try {
// 주문을 json으로 보내기 위한 작업
jsonInString = mapper.writeValueAsString(orderDto);
} catch (JsonProcessingException ex) {
ex.printStackTrace();
}
// topic: topic의 이름
// jsonInString: 보내고자하는 json 값
kafkaTemplate.send(topic, jsonInString);
log.info("Kafka Producer sent data from the Order microservice: " + orderDto);
return orderDto;
}
}OrderController.java
@PostMapping("/{userId}/orders")
public ResponseEntity<ResponseOrder> createOrder(@PathVariable("userId") String userId, @RequestBody RequestOrder orderDetails) {
ModelMapper mapper = new ModelMapper();
mapper.getConfiguration().setMatchingStrategy(MatchingStrategies.STRICT);
OrderDto orderDto = mapper.map(orderDetails, OrderDto.class);
orderDto.setUserId(userId);
/* jpa */
OrderDto createdOrder = orderService.createOrder(orderDto);
ResponseOrder responseOrder = mapper.map(createdOrder, ResponseOrder.class);
/* send this order to the kafka */
kafkaProducer.send("example-catalog-topic", orderDto);
orderProducer.send("orders", orderDto);
ResponseOrder responseOrder = mapper.map(orderDto, ResponseOrder.class);
return ResponseEntity.status(HttpStatus.CREATED).body(responseOrder);
}Multi Order Microservice 사용에 대한 데이터 동기화 문제
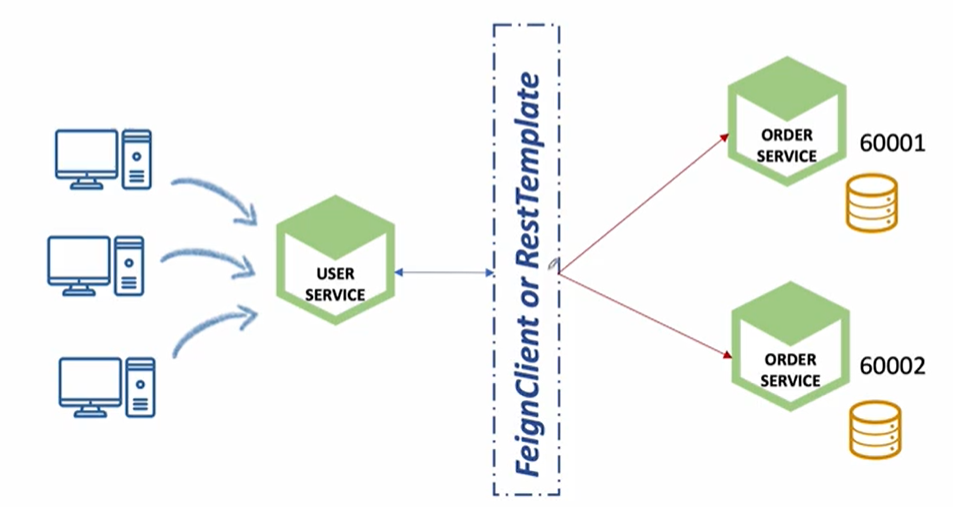
-
Order Service 2개 기동
- Users의 요청 분산 처리
- Orders 데이터도 분산 저장 -> 동기화 문제
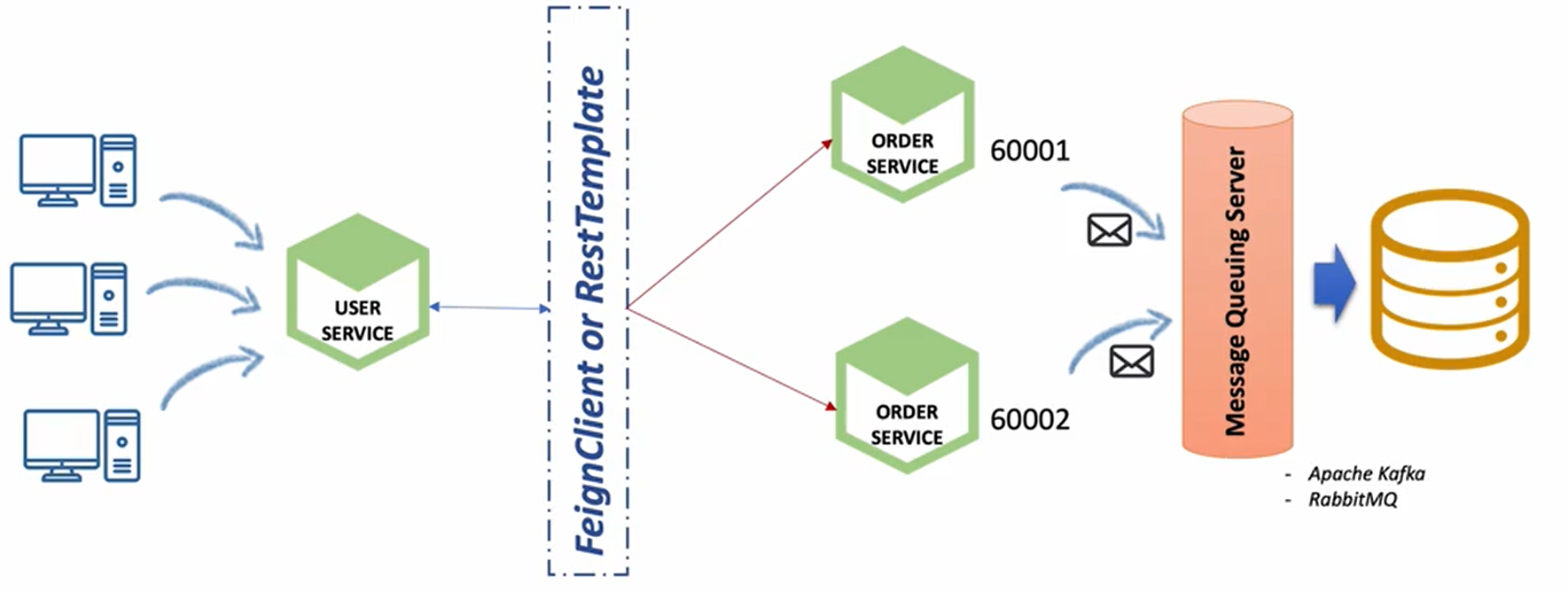
- Order Service에 요청 된 주문 정보를 DB가 아니라 Kafka Topic으로 전송
- Kafka Topic에 설정 된 Kafka Sink Connect를 사용해 단일 DB에 저장 -> 데이터 동기화
💡 Message Queuing Server는 들어왔던 정보를 순차적으로 가지고 있다가 그 데이터 값을 데이터베이스에 업데이트 시켜주는 역할
Multiple Order Service 데이터 동기화
Order Service Controller 수정
@PostMapping("/{userId}/orders")
public ResponseEntity<ResponseOrder> createOrder(@PathVariable("userId") String userId, @RequestBody RequestOrder orderDetails) {
ModelMapper mapper = new ModelMapper();
mapper.getConfiguration().setMatchingStrategy(MatchingStrategies.STRICT);
OrderDto orderDto = mapper.map(orderDetails, OrderDto.class);
orderDto.setUserId(userId);
/* jpa */
// OrderDto createdOrder = orderService.createOrder(orderDto);
// ResponseOrder responseOrder = mapper.map(createdOrder, ResponseOrder.class);
/* kafka */
orderDto.setOrderId(UUID.randomUUID().toString());
orderDto.setTotalPrice(orderDetails.getQty() * orderDetails.getUnitPrice());
/* send this order to the kafka */
kafkaProducer.send("example-catalog-topic", orderDto);
orderProducer.send("orders", orderDto);
ResponseOrder responseOrder = mapper.map(orderDto, ResponseOrder.class);
return ResponseEntity.status(HttpStatus.CREATED).body(responseOrder);
}: 기존에는 DB에 바로 저장을 했다면 Kafka를 통해 DB를 저장하는 것으로 변경
Order Service의 Producer에서 발생하기 위한 메세지 등록
우리가 가지고 있었던 주문 정보를 어떻게 Topic에 보낼 것인가?
Topic에 쌓였던 메시지들은 Sink Connector에 의해 불려지고 Sink Connector가 Topic에 있었던 메시지 내용들을 열어본 다음에 어떻게 저장되어 있는지 파악하고 해당하는 JDBC Connector에 그 값을 저장한다. 허나 정해져있는 데이터 포맷으로 저장하지 않으면 데이터베이스로 저장이 되지 않을 것이다.
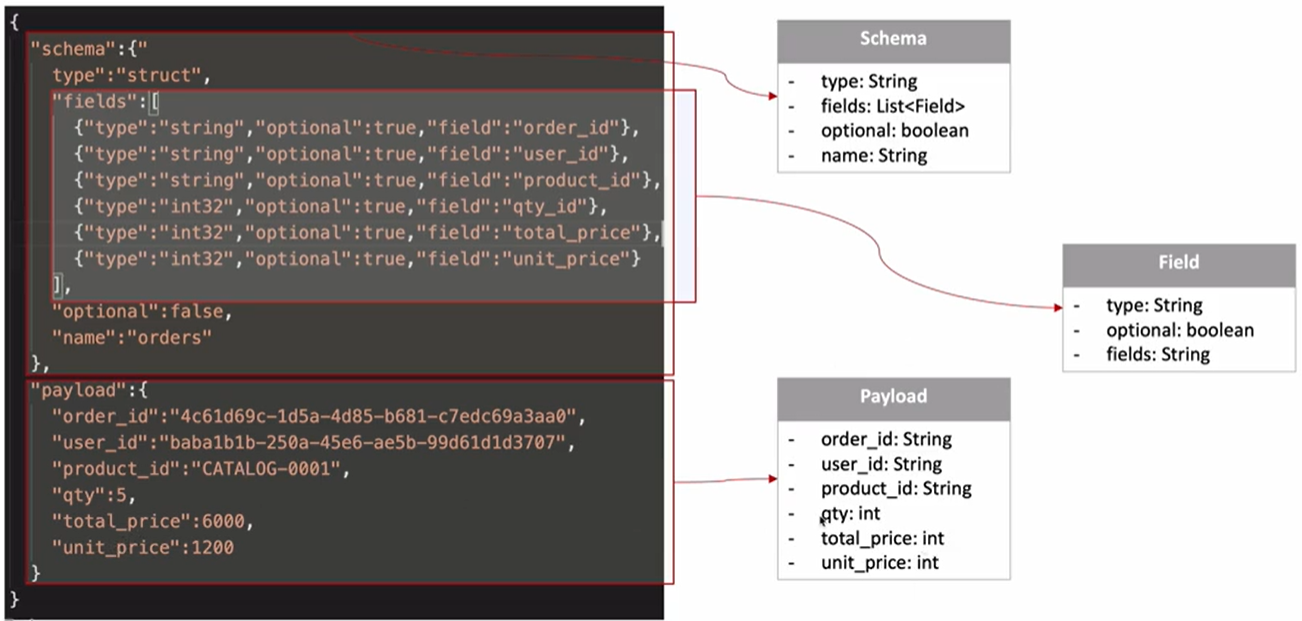
- schema: 테이블 구조
- payload: 실제로 저장되고자하는 주문 정보
Order Service의 Producer에서 발생하기 위한 메시지 등록
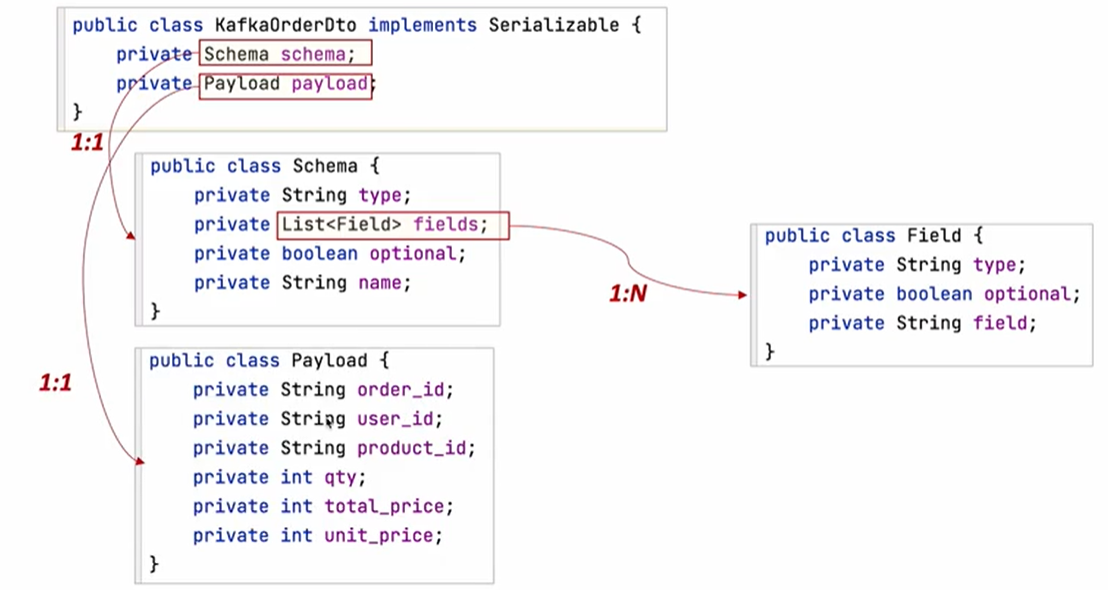
Order Service의 OrderProducer 생성
// Kafka Producer
// Kafka Template을 사용하여 메시지를 Kafka에 보내는 역할
@Service
@Slf4j
public class OrderProducer {
// Kafka에서 제공하는 메시지 전송을 쉽게 해주는 템플릿
// 첫 번째 제네릭 타입: Key의 타입
// 두 번째 제네릭 타입: Value의 타입
private KafkaTemplate<String, String> kafkaTemplate;
// Kafka의 Schema에 들어갈 필드를 정의
List<Field> fields = Arrays.asList(new Field("stirng", true, "order_id"),
new Field("string", true, "user_id"),
new Field("string", true, "product_id"),
new Field("int32", true, "qty"),
new Field("int32", true, "unit_price"),
new Field("int32", true, "total_price"));
// Kafka 메시지에서 사용될 스키마를 정의
Schema schema = Schema.builder()
.type("struct")
.fields(fields)
.optional(false)
.name("orders")
.build();
@Autowired
public OrderProducer(KafkaTemplate<String, String> kafkaTemplate) {
this.kafkaTemplate = kafkaTemplate;
}
// Kafka에 메세지를 전송하는 메소드
// 전송할 Topic과 OrderDto 객체를 인자로 받아 KafkaOrderDto 객체를 생성
// 이후 KafkaTemplate의 send() 메소드를 사용하여 메시지를 전송
public KafkaOrderDto send(String topic, OrderDto orderDto) {
Payload payload = Payload.builder()
.order_id(orderDto.getOrderId())
.user_id(orderDto.getUserId())
.product_id(orderDto.getProductId())
.qty(orderDto.getQty())
.unit_price(orderDto.getUnitPrice())
.total_price(orderDto.getTotalPrice())
.build();
KafkaOrderDto kafkaOrderDto = new KafkaOrderDto(schema, payload);
// ObjectMapper 객체를 사용하여 KafkaOrderDto 객체를 JSON 문자열로 변환
ObjectMapper mapper = new ObjectMapper();
String jsonInString = "";
try {
jsonInString = mapper.writeValueAsString(kafkaOrderDto);
} catch (JsonProcessingException ex) {
ex.printStackTrace();
}
kafkaTemplate.send(topic, jsonInString);
log.info("Order Producer sent data from the Order microservice: " + kafkaOrderDto);
return kafkaOrderDto;
}
}Order Service를 위한 Kafka Sink Connector 추가
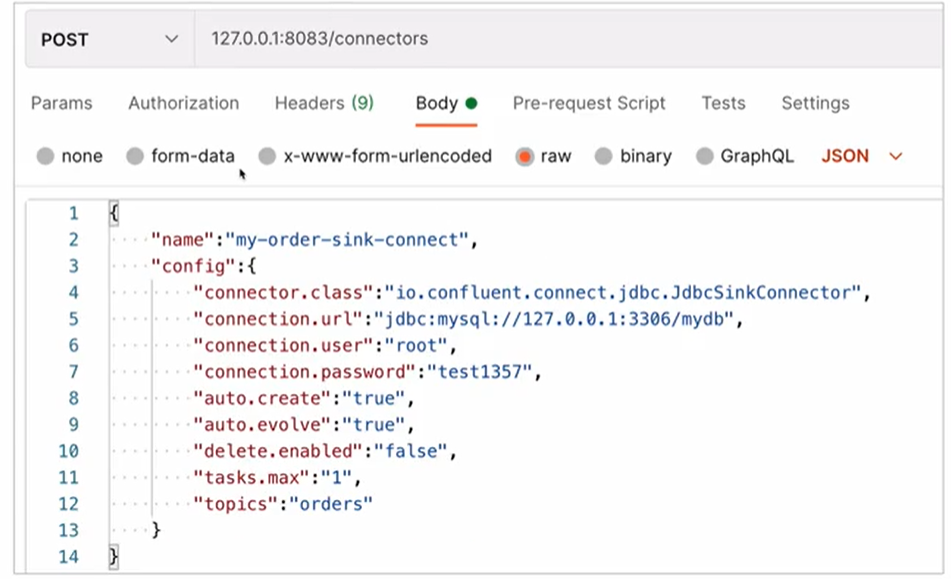
Topic에 데이터가 저장된 다음에 할 작업은 해당하는 데이터 값을 MariaDB에 업데이트 시켜주는 과정이 필요하다. 즉 Topic에 있던 데이터의 감지 내용을 가지고 가서 데이터베이스에 업데이트 시켜주는 작업을 Kafka Connector에서 Kafka Sink Connector가 작업을 한다.
