이 글은 코드프레소 Java 웹 개발 체험단 활동 중 처음 시작하는 SQL 프로그래밍 강좌를 기반으로 작성하였습니다.

코드프레소 URL: https://www.codepresso.kr/
강의 목차
먼저 강의 목차는 아래 그림과 같이 구성되어 있습니다.
MySQL소개
데이터베이스 소개
데이터는 다양한 방법으로 관리가 가능하다(파일, 엑셀 등). 데이터란 여러 사람이 공유하여 사용할 목적으로, 통합하여 관리되는 데이터 집합이다. 자료 항목의 중복을 없애고 자료를 구조화하여 저장함으로써 자료검색과 갱신의 효율을 높일 수 있다.
단순 파일로 데이터를 관리하는 것이 서류더미 라면 데이터베이스는 잘 정리 된 캐비닛이라 볼 수 있다.
DBMS(Database Management System)
데이터베이스를 관리하기 위한 프로그램으로, 관계형 데이터베이스로(RDBMS)
MySQL, Oracle, PostgreSQL, SQL Server, DB2, SQLite, 티베로 등이 있다.
SQL(Structured Query Language) 소개
SQL이란 데이터베이스에 데이터를 요청하는 언어로 인간과 데이터베이스간의 언어를 뜻한다.
ex) SELECT * FROM customer WHERE age >= 20 AND city='seoul' AND gender='female'
SQL은 문법이 단순하여 배우기 쉽고 ANSI, ISO 표준이다. 각 DBMS마다 자기만의 방언을 가지지만 핵심 문법은 유사하다.
MySQL소개
MySQL이란 오픈 소스 RDBMS고 가장 많이 사용되는 DBMS 중 하나이다. 페이스북 초기 서비스를 MySQL로 구축했다.
SQL 명령어를 이용한 데이터 정의
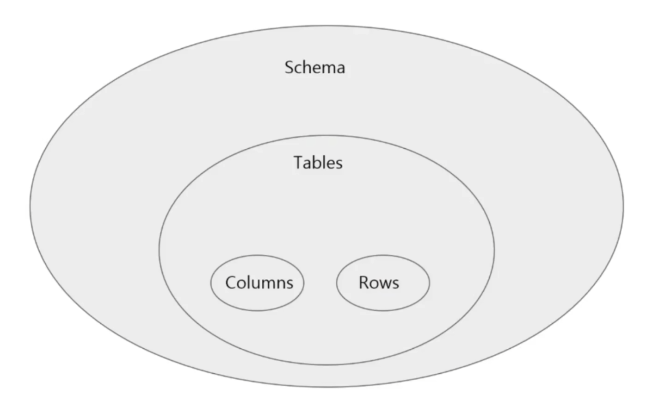
데이터베이스의 구성요소
- Schema - application 마다 1개
- Table - 각 application의 세부 기능 마다 정의
- Column - 각 기능에 필요한 요소들
- Row - 데이터 1건 (Record)
MySQL의 데이터 타입
- 데이터 타입 - 컬럼에 어떠한 형태의 자료를 저장할지를 미리 결정한 것
- 숫자(Numeric) - 정수형, 실수형
- 문자(Character) - 고정 문자형, 변동 문자형
- 날짜/시간(Date/Time) - 날짜형, 시간형, 날짜시간형
데이터베이스 Schema 생성
테이블 생성 전 Scema 생성이 선행 되어야 함
데이터베이스 Table 생성

옵션
- PK: 테이블당 1개만 존재 가능, Unique한 값(Not Null 필수)
- NN: Not Null, 데이터가 반드시 저장되어야 함
- UQ: Unique한 값(Null 가능)
- UN: Unsigned
- AI: Auto Increment
- Default: 디폴트 값
INSERT 명령어를 이용한 데이터 추가

SQL 명령어를 이용한 데이터의 조회
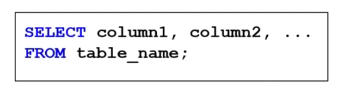
SELECT 명령어를 이용한 데이터의 조회
WHERE절을 이용한 데이터 필터링

비교 연산자를 이용한 데이터 필터링
- 같음: =
- 같지 않음: <>
- 큼: >
- 작음: <
- 크거나 같음: >=
- 작거나 같음: <=
AND, OR 연산자를 이용한 데이터 필터링
- 하나 이상의 조건들을 결합 하여 필터링 가능
- AND 연산자 - 주어진 모든 조건을 모두 만족 시키는 데이터만 조회
- OR 연산가 - 주어진 조건 중 하나 이상 만족 시키는 데이터 조회
SQL명령어를 이용한 데이터의 조회 2
ORDER BY 명령어를 이용한 데이터의 정렬
데이터는 특정 컬럼을 기준으로 내림차순 또는 오름차순으로 정렬이 가능하다. 이때 ORDER BY 명령어를 사용하는대 1개 이상의 정렬 조건을 조합 가능하다.
ASC(오름 차순), DESC(내림 차순)을 명시할 수 있으며 오름 차순이 Default값이다.

LIMIT, OFFSET 명령어를 이용한 조회 데이터의 제한
Top N 데이터 조회 - LIMIT, OFFSET
LIMIT는 조회 된 결과 값의 개수를 제한 하는데 사용, OFFSET은 LIMIT와 함께 사용되며 페이지 처리를 하는데 사용한다. LIMIT는 주로 ORDER BY 절과 같이 사용되며, 정렬 후 상위 N개의 결과만을 확인할 수 있다.

IN 연산자를 이용한 데이터 필터링

BETWEEN 연산자를 이용한 데이터의 필터링

LIKE 연산자를 이용한 데이터의 필터링
LIKE 연산자는 문자열 안에서 특정 패턴을 검색하기 위해 사용한다. 연산자가 문자열이 완전히 일치하는 조건인 반면, LIKE연산자는 문자열이 부분적으로 일치하는 조건
DISTINCT 명령어를 이용한 중복 데이터 제거
DISTINCT문은 특정 컬럼의 unique한 값 들을 조회한다. 엑셀의 중복 값 제거 기능 실행 후 결과와 동일하다 다수의 컬럼을 명시할 수 있지만 자주 사용되지는 않는다.
누락(Null Value) 데이터의 처리
Null Value란 아무것도 값이 없는 상태를 의미한다. IS NULL, IS NOT NULL 연산자로 null인 또는 null이 아닌 데이터만 조회가 가능하다.

AS 명령어를 이용한 데이터의 별칭
AS란 Alias(별칭)을 의미한다. 컬럼 또는 테이블에 별칭을 부여하여 조회가 가능하며 컬럼 명을 이해하기 쉽게 만들기 위해서 사용한다. 테이블 명을 짧게 만들기 위해서 사용한다.
SQL 명령어를 이용한 데이터의 변경
UPDATE 명령어를 이용한 데이터 수정
기존의 데이터를 수정할 때 사용되며 WHERE 절에 명시한 조건에 해당하는 데이터를 변경한다. (명시하지 않으면 모든 ROW의 값이 변경 될 수 있다)

DELETE 명령어를 이용한 데이터 삭제
기존 데이터를 삭제할 수 있다. WHERE절에 명시한 조건에 해당하는 데이터를 삭제한다.(명시하지 않으면 해당 테이블의 모든 데이터가 삭제될 수 있다) 또한 지워진 데이터는 복구가 어렵다.

SQL 명령어를 이용한 데이터의 집계
COUNT 함수를 이용한 데이터 개수 집계
조회 된 데이터의 개수를 계산하는 함수이다. WHERE 절을 통해 필터링 된 데이터의 개수를 계산 가능하다. Null Value는 카운트 되지 않는다.

SUM 함수를 이용한 데이터의 합 집계
조회 된 데이터의 합을 계산하는 함수로 WHERE 절을 통해 필터링 된 데이터의 합을 계산 가능하다. *를 사용할 수 없고 특정 컬럼 명을 명시해야한다.

MIN, MAX 함수를 이용한 최대값, 최소값 집계
MIN은 조회된 데이터에서 특정 컬럼의 최소 값을 계산하는 함수이다.
MAX는 조회된 데이터에서 특정 컬럼의 최대 값을 계산하는 함수이다.
WHERE 절을 통해 필터링 된 데이터의 최대값 최소값을 계산 가능하다.

AVG함수를 이용한 평균값 집계
조회된 데이터에서 특정 컬럼의 평균 값을 구하는 함수이다.
WHERE 절을 통해 필터링 된 데이터에서 특정 컬럼의 평균값을 계산 가능하다.

VARIANCE, STDDEV 함수를 이용한 분산, 표준편차 집계
- VARIANCE: 조회된 데이터에서 특정 컬럼의 분산 계산
- STDDEV: 조회된 데이터에서 특정 컬럼의 표준편차 계산
분산과 표준편차는 데이터들이 평균에서 벗어나 있는 정도를 측정하는 지표이다.

GROUP BY 명령어를 이용한 그룹별 데이터 집계
특정 컬럼들을 기준으로 데이터를 그룹 지어 분석할 수 있다. (한 개 이상의 컬럼으로 그룹화 가능)
GROUP BY는 집계함수들과 함께 자주 사용한다.
HAVING 명령어를 이용한 집계 데이터 필터링
HAVING 명령어는 그룹화 한 결과를 필터링 해준다. 그룹화 전 필터링은 WHERE, 그룹화 후 필터링은 HAVING이다.

SQL 명령어를 이용한 데이터의 결합
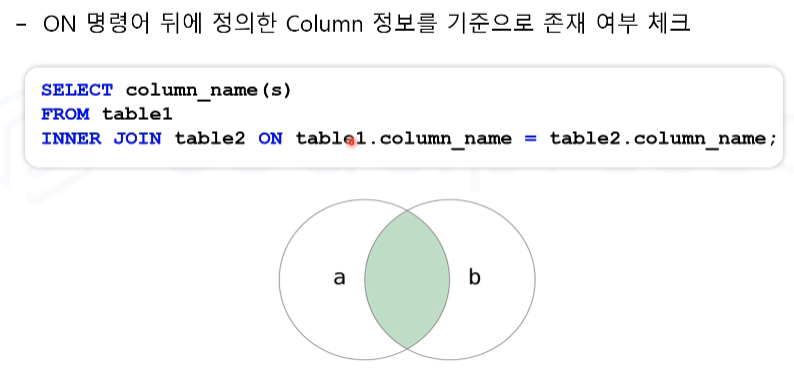
INNER JOIN 명령어를 이용한 데이터의 Column 결합

SQL JOIN의 종류에는
- INNER JOIN
- LEFT (OUTER) JOIN
- RIGHT (OUTER) JOIN
- FULL OUTER JOIN
- CROSS JOIN
- SELF JOIN
그 중 INNER JOIN 명령어는 두 개의 테이블에 모두 존재하는 데이터만 결합하여 조회한다.
OUTER JOIN 명령어를 이용한 데이터의 Column 결합
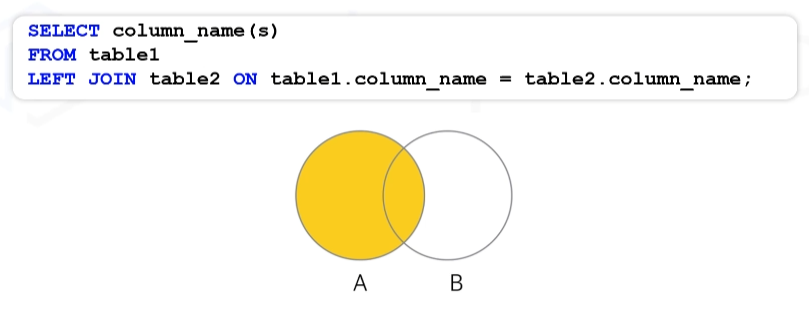
LEFT JOIN
-> 왼쪽에 위치한 테이블을 기준으로 오른쪽의 테이블의 데이터를 붙인다.
- 왼쪽 테이블의 데이터는 모두 조회 됨
- 왼쪽 테이블에는 있지만 오른쪽 테이블에 없는 데이터는 Null
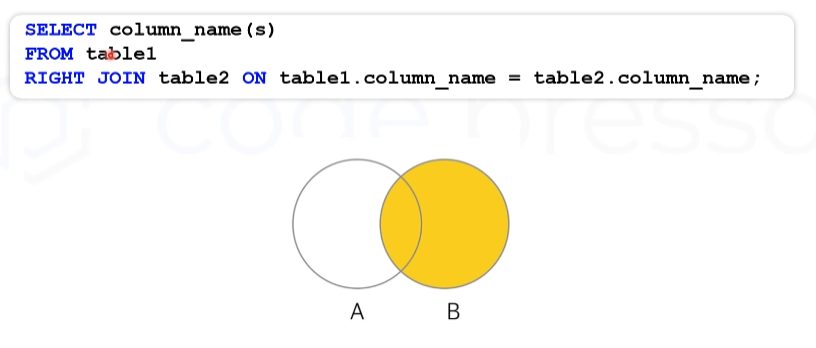
RIGHT JOIN
-> LEFT JOIN과 동일하고 기준이 되는 테이블의 방향만 반대이다.