활성화 함수 종류
-
tanh
-
ELU
relu에서 0 이하에서 기울기가 0이 되어서 Relu와 연결된 노드들이 모두 활성화 되지 않는 문제가 있다. 이 문제를 해결하기 위해 0 이하에서도 기울기를 주면서 동시에 음수의 값을 가지게 해서 평균이 0에 가까워지도록 (mean shift toword zero) 조정했다. 이것으로 ReLU나 Leaky Relu에 비해 학습속도와 성능이 향상된다.
batch normalization에서 힌트를 얻어온 것 같다.
-
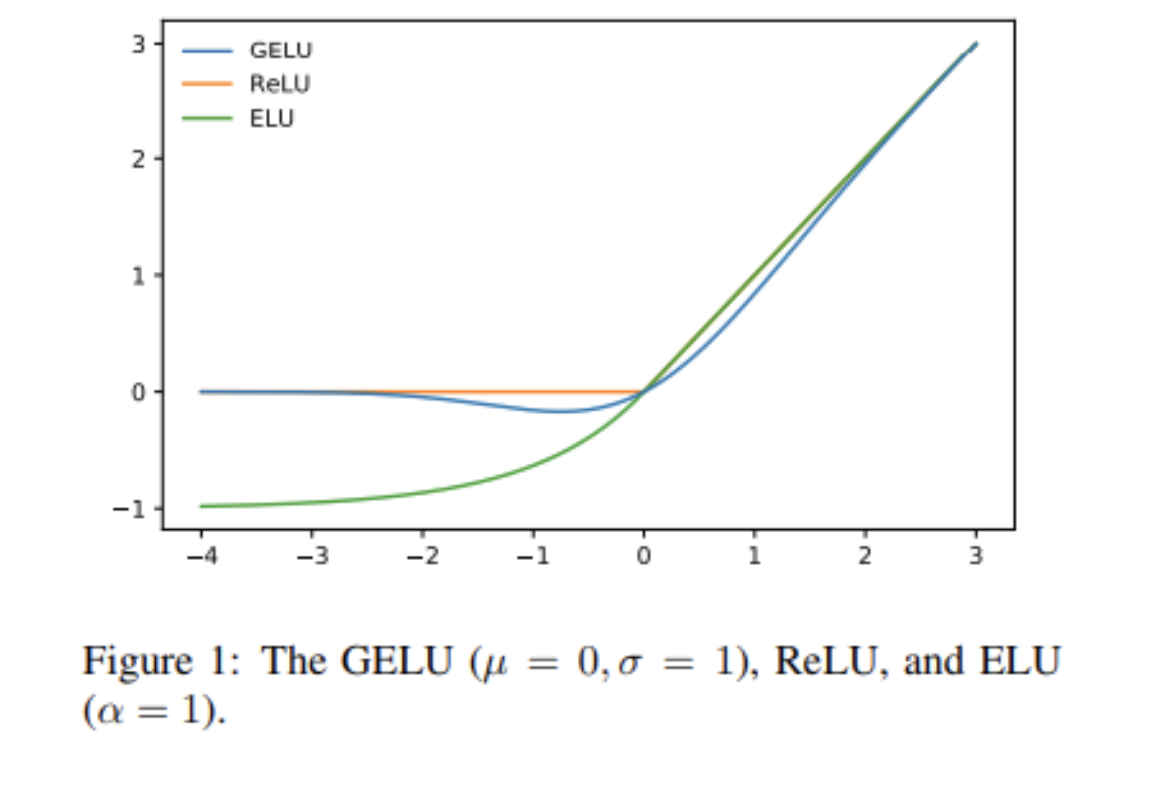
GELU
모든 점에서 미분가능, 단조증가함수가 아님.
sigmoid, tanh가 bounded (특정값으로 수렴) gradient vanishing 현상을 유발
ReLU는 입력이 음수가 되면 기울기 0이 되어 연결된 파라미터들 업데이트 안되는 문제 (Dying Relu 현상)
이를 해결하기 위해 음수에서 작은 기울기를 주는 활성화 함수들 개발됨 (Leaky ReLU)
하지만 이 함수들은 음수에 대해서 bounded되어 있지 않다. 이로 인해 음수가 계속해서 곱해질 우려가 있고 이는 활성화에 좋지 않은 영향을 끼칠 수 있다.
GELU는 이를 방지하기 위해 음수부분에 대해서 bounded되어 있는 것이 특징이다.
BERT, GPT 등의 SOTA모델에 대해서 사용됨.
-
CReLU
- 기타
Mish, Swish

지식 정리용 벨로그