Algorithm&자료구조
1.Big-O 표기법

서로 다른 알고리즘의 효율을 측정, 비교하기 위한 방법수행되는 연산(산술, 비교 대입) 의 개수를 '대략적으로' 판단영향력이 가장 큰 대표 항목만 남기고 삭제상수는 무시한다.(2N -> N)Big-O를 통해 입력 N의 크기에 따라 성능이 영향을 받는 정도를 나타낼 수
2.미로 - 오른손 법칙
.gif)
미로를 통과하기 위한 길찾기 알고리즘 중 가장 간단한 알고리즘.오른손으로 벽을 짚으며 미로를 빠져나가는 알고리즘이다.오른쪽에 갈 수 있는 길이 있으면 오른쪽 길로 가고 오른쪽 길이 막혀있으면 앞으로 전진, 앞으로 가는길 또한 막혀있다면, 왼쪽 방향으로 몸을 회전하여 길
3.선형 자료구조 개요
선형 구조란 자료를 순차적으로 나열한 상태를 의미한다.배열연결 리스트스택 / 큐반대로 비선형 구조는 하나의 자료 뒤에 다수의 자료가 올 수 있는 형태를 의미한다.트리그래프원소들이 메모리에 연속되어 배정된다.고정된 메모리를 사용한다.메모리 공간을 추가하거나 축소할 수 없
4.동적 배열
동적 배열은 원소가 추가됨에 따라 capacity를 적절하게 늘려주어 메모리 공간을 예약하는 방법을 사용한다.일반 배열이 메모리를 축소, 추가하지 못하는 점을 개선하기 위함.현재 vector의 size와 capacity를 비교하여 둘이 같다면 vector가 꽉 차있다고
5.연결리스트
리스트에는 원소를 갖는 노드들이 속해져 있고, 서로 앞, 뒤로 있는 노드 끼리 연결되어져 있는 형태의 자료구조.중간에 원소를 삽입/삭제하는 경우 삽입/삭제할 공간의 앞, 뒤 노드만 연결 상태를 변경해주면 되기 때문에 효율적이다.단 임의 접근은 비효율적이기 때문에 사용하
6.Stack
후입선출의 특징을 갖는 자료구조ctrl + z 등의 되돌리기를 구현할 때 사용된다.cpp의 std 자료구조들은 인테페이스가 대부분 통일된 형태로 구현되어 있다.따라서 Stack의 원소를 저장하는 자료구조가 List든 vector든 같은 명령어로 호출이 가능하다.실제 s
7.Queue
FIFO (First In First Out 선입선출)List로 구현한 QueueList를 활용하여 Queue를 구현하면 Vector와는 달리 중간 삽입/삭제가 효율적이기 때문에 이점이 있다. (List Queue)Vector를 활용하여 Queue를 구현할 경우 순환
8.미로 - 오른손법칙 개선
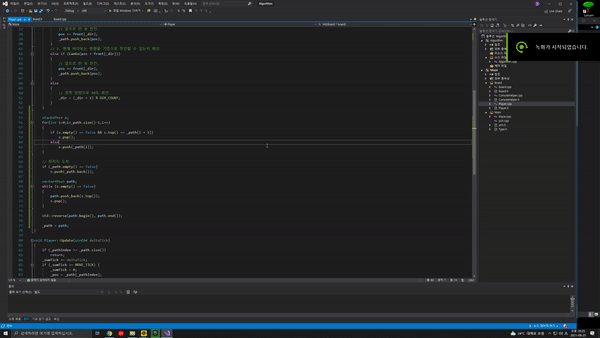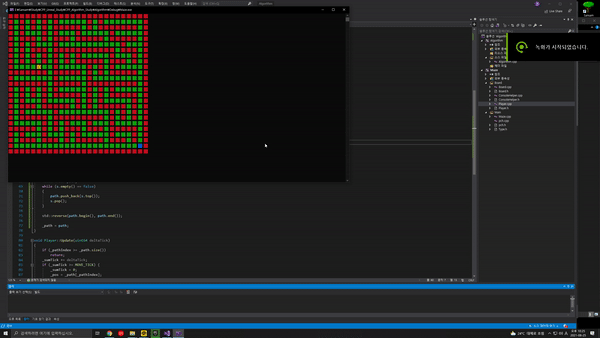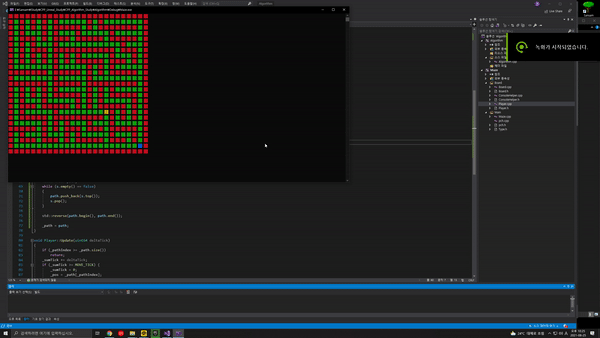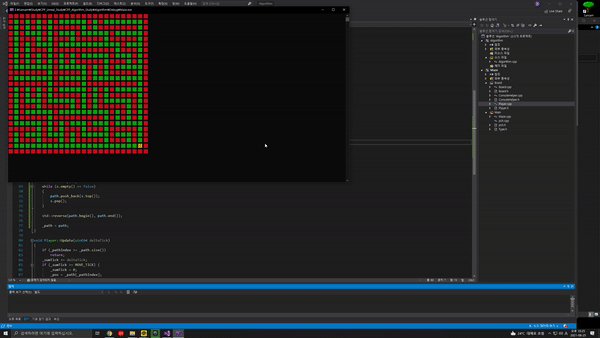
앞서 만들어본 오른손법칙을 통한 미로 길찾기는 불필요한 길을 지나는 것이 불가피한 알고리즘이였다.stack을 이용하면 최단루트를 구할 순 없지만 막다른 길에서 되돌아 오는 것을 방지하는 길을 알아낼 수 있다.현재 위치를 i라고 할 때 스택에 저장되어 있는 (i - 1)
9.DFS (Depth First Search) 깊이 우선 탐색
그래프 탐색법 중 하나인 DFS는 다음 분기로 넘어가기 전에 해당 분기를 끝마치는 탐색법이다.경로 탐색 시 이어지는 길이 있으면 끝까지 간다.그래프 탐색은 모든 정점을 방문하는 것을 목표로 하므로 방문 여부를 확인하는 bool변수를 생성해 방문 시 체크해준다.재귀를 사
10.BFS (Breadth First Search) 너비 우선 탐색
루트 노드나 임의의 노드에서 시작하여 인접한 노드를 먼저 탐색하는 그래프 탐색 방법.시작 정점으로부터 가까운 정점을 먼저 탐색하는 방법이다.따라서 깊게보단 넓게 탐색하기 때문에 너비 우선 탐색이라고 불린다.최단 경로 혹은 임의의 경로를 찾고자 할 때 이 방법을 사용한다
11.미로 - BFS
.gif)
우리는 오른손 법칙을 개선하여 막다른 길에서 되돌아가는 루트를 줄여 조금 더 짧은 길찾기 루트를 알아낼 수 있었다.하지만 오른손 법칙 개선은 "되돌아가는" 루트만 제거했다뿐이지 최단루트를 보장하는 알고리즘은 아니다.최단루트를 알아내는 알고리즘은 대표적으로 BFS를 사용
12.Graph
노드와 그 노드를 연결하는 간선을 하나로 모아놓은 자료구조를 의미한다.즉, 연결되어 있는 객체 간의 관계를 표현하는 자료구조이다.ex) 지도, 지하철 노선도, 전기 회로의 소자 등등그래프는 인접리스트, 인접 행렬로 구현하는 방식이 있다.인접리스트인접리스트 방식은 정점들
13.Dijkstra
하나의 정점에서 다른 모든 정점까지의 최단 경로를 구하는 알고리즘이다.양의 가중치를 갖는 간선을 사용하는 그래프에서 사용된다.각 정점들은 시작정점에서 부터의 거리를 갖는 distance를 가지게 된다.distance는 탐색도중 시작정점으로부터 해당 정점까지의 거리 중
14.Tree
계층적 구조를 갖는 데이터를 표현하기 위한 자료구조노드: 데이터를 표현간선: 노드의 계층 구조를표현하기 위해 사용트리의 특성상 재귀 알고리즘과 잘 어울린다.노드들은 데이터와 자식을 가지고 자식 또한 데이터와 자식을 가진 계층구조로 이루어져 있다.트리 밑에 트리가 있는
15.힙 트리
최대 2개의 자식을 갖는 이진트리중 하나이다.부모노드가 가진 값은 항상 자식노드가 가진 값보다 크다. ( 최대 힙, 최소 힙은 반대로 부모노드가 자식 노드보다 작다.)노드 개수를 알면, 트리 구조는 무조건 확정할 수 있다. 배열을 이용해서 힙 구조를 바로 표현할 수 있
16.이진 탐색 트리
이진 탐색 트리 이진 탐색 정렬되어 있는 배열에 한해서 특정한 값을 찾아내는 알고리즘이다. 정렬되어 있는 배열의 중간 지점의 값(mid)과 찾고있는 값(key)을 비교하여 mid > key 일 경우 key가 배열에 존재한다는 가정 하에 key는 mid의 좌측 배열
17.레드 블랙 트리
레드 블랙 트리 각각의 노드가 레드나 블랙인 생상 속성을 가지고 있는 이진 탐색 트리이다. 일반적인 이진 탐색 트리가 가지고 있는 조건에 추가적인 조건을 만족해야 유효한 레드 블랙 트리가 된다. 노드는 레드 혹은 블랙 중의 하나이다. 루트 노드는 블랙이다.
18.정렬
정렬 1) 버블 정렬 2) 선택 정렬 3) 삽입 정렬 4) 힙 정렬 5) 병합 정렬 6) 퀵 정렬
19.Hash Table
해시 테이블은 (Key, Value)로 데이터를 저장하는 자료구조중 하나로 빠르게 데이터를 검색할 수 있는 자료구조 이다.Map과 비슷하지만 Map은 레드 블랙트리로 이루어져 있는 반면 HashMap은 배열과 비슷한 버킷으로 이루어져 있다.메모리를 내주고 속도를 취하는
20.최소 신장 트리
신장 트리란 그래프에서 모든 정점을 포함하고 정점 간 서로 연결이 되며 싸이클이 존재하지 않는 그래프를 의미한다.최소 신장 트리란 그래프의 신장 트리들 중 간선의 가중치의 합이 최소가 되는 신장 트리를 최소 신장 트리라고 한다.ex) 도시를 모두 연결하는 루트를 구성하