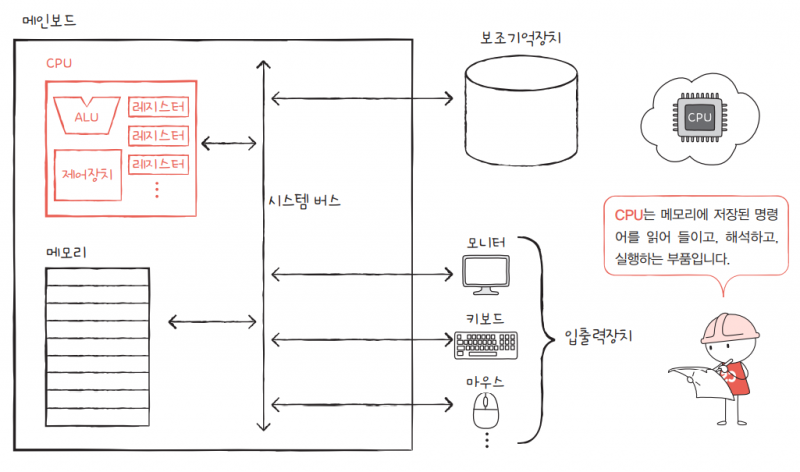
🚩 CPU
기억 장치에 저장되어 있는 프로그램 코드인 명령어들을 실행함으로써 프로그램 수행이라는 컴퓨터의 기본적인 기능을 수행
✔️ CPU가 수행해야 하는 세부적인 동작들
1. 명령어 인출 (Instruction Fetch)
- 기억장치로부터 명령어를 읽어오기
2. 명령어 해독 (Instruction Decode)
- 수행해야 할 동작을 결정하기 위하여 명령어를 해독
3. 데이터 인출 (Date Fetch)
- 명령어 실행을 위하여 데이터가 필요한 경우에는 기억장치 혹은 I/O장치로부터 그 데이터를 읽어오기
4. 데이터 처리 (Data Process)
- 데이터에 대한 산술적 혹은 논리적 연산을 수행
5. 데이터 저장 (Data Store)
- 처리된 결과를 기억 장치나 레지스터에 저장
✔️ CPU의 기본 구조
산술논리연산장치(Arithmetic and Logical Unit ; ALU) + 레지스터 세트(Register Set) + 제어 유니트(Control Unit)
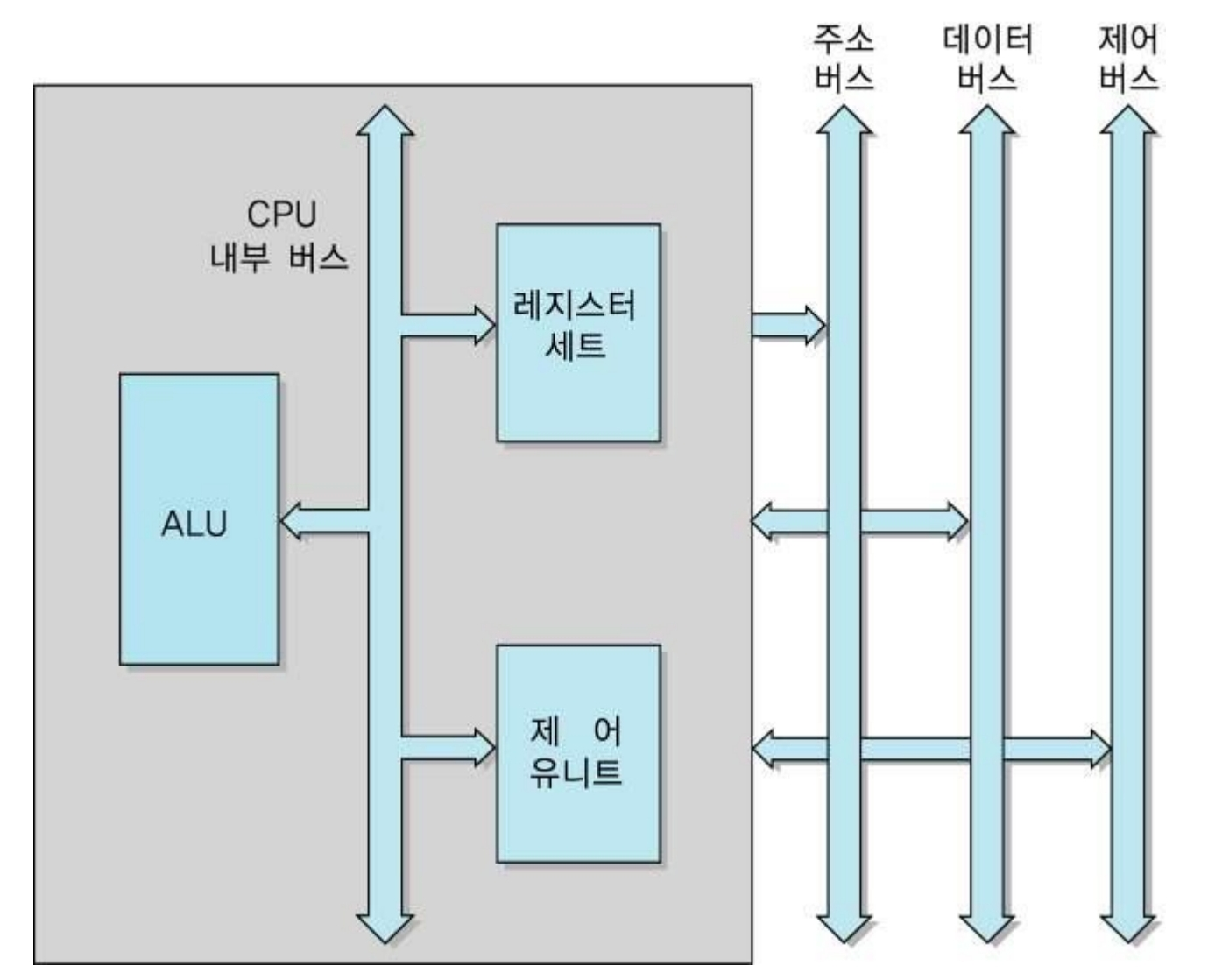
- 산술논리연산장치(Arithmetic and Logical Unit ; ALU)
- 각종 산술 연산들과 논리 연산들을 수행하는 회로들로 이루어진 하드웨어 모듈
(산술 연산 : 덧셈, 뺄셈, 곳셈, 나눗셈)
(논리 연산 : AND, OR, NOT)
- 각종 산술 연산들과 논리 연산들을 수행하는 회로들로 이루어진 하드웨어 모듈
- 레지스터 (Register)
- CPU 내부에서 고속으로 데이터를 저장하고 접근
- 액세스 속도가 컴퓨터의 기억 장치들 중 가장 빠름
✅ 그럼 레지스터를 많이 두면, CPU가 빨라지지 않나?
👉🏻 레지스터는 내부 회로가 복잡하여 비교적 큰 공간을 차지하므로 많은 수의 레지스터들을 CPU 내부에 포함시키기는 어려움
➡️ 지정된 용도로만 사용되는 특수 목적용 레지스터들과 적은 수의 일반 목적용 레지스터들만이 포함 - CPU 내부 레지스터
👉🏻 프로그램 카운터 (Program Counter ; PC)
- 다음에 인출될 명령어의 주소를 가지고 있는 레지스터
👉🏻 누산기 (Accumulator ; AC)
- 데이터를 일시적으로 저장하는 레지스터 = 이 레지스터의 비트 수는 CPU가 한 번에 연산 처리할 수 있는 데이터 비트의 수
👉🏻 명령어 레지스터 (Instruction Register ; IR)
- 가장 최근에 인출된 명령어가 저장되어 있는 레지스터
👉🏻 기억장치 주소 레지스터 (Memory Address Register ; MAR)
- 프로그램 카운터에 저장된 명령어 주소가 시스템 주소 버스로 출력되기 전에 일시적으로 저장되는 주소 레지스터
👉🏻 기억장치 버퍼 레지스터 (Memory Buffer Register ; MBR)
- 기억장치에 저장될 데이터 혹은 기억장치로부터 읽혀진 데이터가 일시적으로 저장되는 버퍼 레지스터
- 제어 유니트(Control Unit)
- 프로그램 코드(=명령어)를 해석하고, 그것을 실행하기 위한 제어 신호들(Control Signals)을 순차적으로 발생하는 하드웨어 모듈
- 명령어 실행에 필요한 각종 정보들의 전송 통로와 방향을 지정
- CPU 내부 요소 들과 시스템 구성 요소들의 동작시간도 결정
- CPU 내부버스
- PU 내부의 구성 요소들(레지스터, ALU, 제어 유니트 등) 간 데이터를 주고받는 전송 통로
✅ CPU는 기억장치에 저장되어 있는 명령어들을 인출하여 실행함으로써, 실제적인 작업을 수행
CPU가 한 개의 명령어를 실행하는 데 필요한 전체 과정 🟰 명령어 사이클(Instruction Cycle)
🔍 CPU 명령어 실행 과정
1️⃣. Memory Address Register는 Program Counter에서 수행할 명령어의 메모리 주소를 넘겨 받음
2️⃣. Memory Address Register가 넘겨받은 메모리 주소로 데이터를 인출 (이때 Progrom Counter 다음 명령어 주소로 증가)
3️⃣. Memory Buffer Register가 Memory Address Register가 인출해온 데이터를 일시적 저장
4️⃣. Memory Buffer Register에 저장된 데이터 중 명령어는 Instruction Register로 저장
연산에 사용될 데이터는 Accumulator에 저장
✅ Instruction Register에는 명령어
✅ Accumulator에는 연산의 결과 값이나 중간 값을 일시적으로 저장
✅ 최종 결과는 Memory Buffer Register를 통해 메모리 전송
5️⃣. Control Unit가 Instruction Register에 있는 명령어를 받아 해석하고, 해석된 명령을 실행할 시스템에 Control Signal을 보냄
6️⃣. ALU는 산술 논리 연산 실행
7️⃣. 연산의 결과 값은 Memory Buffer Register에 저장
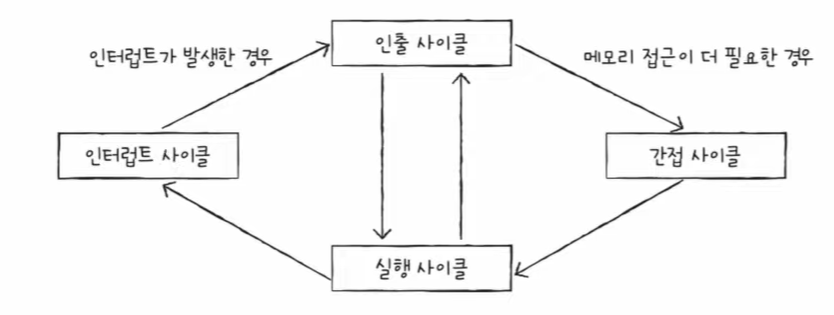
❓ 인출 사이클
- 기억장치에 지정된 위치로부터 명령어를 CPU로 읽어오는 과정
👉🏻 프로그램 카운터(PC) 안에 있는 명령어의 주소를 MAR로 전달 :MAR <- PC
👉🏻PC <- PC+1
👉🏻 제어 유니트의 '메모리 읽기' 제어 신호와 MAR는 전달받은 명령어 주소값이 제어버스와 주소버스를 통해 전달되어 메모리를 읽고 데이터베어스를 톨해서 MBR로 전달 :MBR <- M[MAR]
👉🏻 MBR에 저장된 값은 IR로 이동 :IR <- MBR
❓ 실행 사이클
- CPU가 인출된 명령어 코드를 해독하고, 그 결과에 따라 필요한 연산을 수행
(수행 연산 : 데이터 이동 / 데이터 처리 / 데이터 저장 / 프로그램 제어)
❓ 인터럽트 사이클
➡️ 인터럽트 : 대부분의 컴퓨터들은 프로그램 처리 중에 CPU로 하여금 순차적인 명령어 실행을 중단하고 다른 프로그램을 처리하도록 요구할 수 있는 메커니즘을 제공 = 단순히 정상적인 프로그램 처리의 흐름을 방해하는 동작
- 동기 인터럽트(Synchronous Interrupts ; Exception)
- CPU에 의해 발생하는 인터럽트
- 프로그래밍 상의 오류와 같이 CPU가 내부에서 명령어들을 수행하다가 예외 상황이 발생했을 때 발생하는 인터럽트
- 비동기 인터럽트 (Asynchronous Interrupts ; Interrupt)
- 입출력과 같은 CPU 외부에서 처리할 예외 상황이 발생할 때 발생하는 인터럽트
❓ 간접 사이클
- 명령어 실행을 위해 데이터의 실제 주소를 기억장치로부터 읽어오는 과정
👉🏻 명령어 레지스터인 IR에 있는 명령어의 오퍼랜드(addr)값을 MAR로 전달 :MAR <- IR(addr)
👉🏻 명령어 유효주소의 주소를 통해서 메모리를 읽고 데이터 버스를 통해서 MBR에 전달 :MBR <- M[MAR]
👉🏻 MBR의 데이터는 명령어의 유효주소 데이터 ➡️ IR의 오퍼랜드에 저장 :IR(addr) <- MBR
🔍 기억장치로부터 인출된 명령어는 MBR을 경유하여 IR에 저장되며, 실행 사이클에서 제어 유니트로 보내져 해독
🔍 기억장치로부터 인출된 데이터는 MBR을 경유하여 AC로 적재되며, 만약 명령어가 그 데이터에 대해 연산을 수행하는 것이라면 ALU로 보내져 연산을 실행하고, 결과는 AC에 다시 저장
📌 CPU 성능 향상 전략
✔️ 클럭
- 컴퓨터에서 특정한 간격으로 반복되는 신호를 의미
👉🏻 클럭 신호 : 제어 장치가 타이밍을 맞추고 다른 컴퓨터 부품들과 동기화를 유지하는 데 필수적인 역할
👉🏻 클럭 신호 = 타이밍 신호 ➡️ 컴퓨터의 각 부품이 동기화되어 동작하도록 만드는 역할을 함
✅ 컴퓨터 여러 부품들은 클럭 신호에 의존하여 동작 ➡️ 그럼 클럭의 속도가 높으면 CPU 명령어 사이클을 더 빠르게 수행하게 되니까, CPU가 빨라지나?- "부분적으로 빨라짐"
- 클럭 속도를 강제로 증가 = 오버클럭킹 (OverClocking)
🔊 일정 수준의 성능 향상, but 발열 문제나 과부화와 같은 위험성을 야기
👉🏻 CPU 아키텍처, 메모리 속도, 버스 속도 등 다른 여러 요소가 CPU의 성능에 크게 영향을 미치기 때문에, 클럭 속도를 무조건적으로 높이는 것만으로 CPU 성능 향상에 한계
✔️ RISC와 CISC
❓️ RISC (Reduced Instruction Set Computer) 방식
- CPU 명령어의 개수를 줄이고, 단순한 명령어 집합을 사용하는 방식 ➡️ 단순 명령어를 활용한 빠른 연산
- 고정 길이 명령어를 사용해 빠르게 해석 가능하며, 파이프라이닝에 유리함
- 복잡한 연산도 적은 수의 명령어를 조합하여 수행 가능
- 많은 레지스터와 캐시를 사용해 메모리 접근 횟수를 줄이고 성능을 향상
- 대부분의 명령어가 하나의 클럭 사이클에서 실행됨
- 대표적으로 ARM
❓️ CISC (Complex Instruction Set Computer) 아키텍처
- 복잡하고 다양한 명령어 집합을 사용하는 방식 ➡️ 복잡한 명령어 집합을 사용해 메모리 효율 증가
- 마이크로코드를 활용해 복잡한 명령어를 실행 가능하며, 메모리 효율성이 높음
- 명령어가 복잡하여 디코딩 속도는 낮고, 설계가 복잡
- 가변 길이 명령어를 사용하며, 파이프라이닝 효율이 낮음
- 명령어 실행 시간이 명령어마다 다름
- 대표적으로 x86
👉🏻 RISC는 "요리 과정을 세부적으로 분리하여 제공" ➡️ 단순한 명령어로 빠르게 연산 가능
👉🏻 CISC는 "완성된 요리 레시피 제공" ➡️ 명령어 집합으로 메모리 효율 증가
✔️ 코어와 멀티 코어
- 코어(CORE)
- CPU의 작업 처리 단위 = 프로세서
- 각 코어는 독립적으로 명령어를 실행 가능 ➡️ 이런 코어가 여러 개 모인 것을 멀티 코어 CPU OR 멀티코어 프로세서
✅ 코어도 늘리면 처리 속도도 그만큼 빨라지나?
👉 CPU의 연산 속도가 코어 수에 비례하여 증가하지 않음
👉 CPU 연산 속도는 코어마다 적절히 분배된 작업량에 따라 달라짐 ➡️ 이는 코어가 많아도 작업량이 늘어나지 않음
🔊 처리해야하는 작업의 규모보다 코어 수가 지나치게 많다면, 그 코어들이 활용되지 않아 성능 향상에 도움 ❌
👉🏻 각 코어에 얼마나 효율적으로 명령어들을 분배하느냐 ➡️ 작업의 병렬 처리 가능성과 프로그램츼 최적화 수준, 운영체제의 스케줄링 등에 의해 결정
✔️ 스레드와 멀티 스레드
- 스레드 (Thread)
- 프로그램에서 실행 흐름의 최소 단위
- SW 스레드 : 하나의 프로그램에서 독립적으로 실행되는 단위
- HW 스레드 : 하나의 코어가 동시에 처리하는 명령어 단위
👉🏻 하나의 코어로 여러 명령어를 동시에 처리하는 CPU를 멀티 스레드 프로세서 or 멀티스레드 CPU
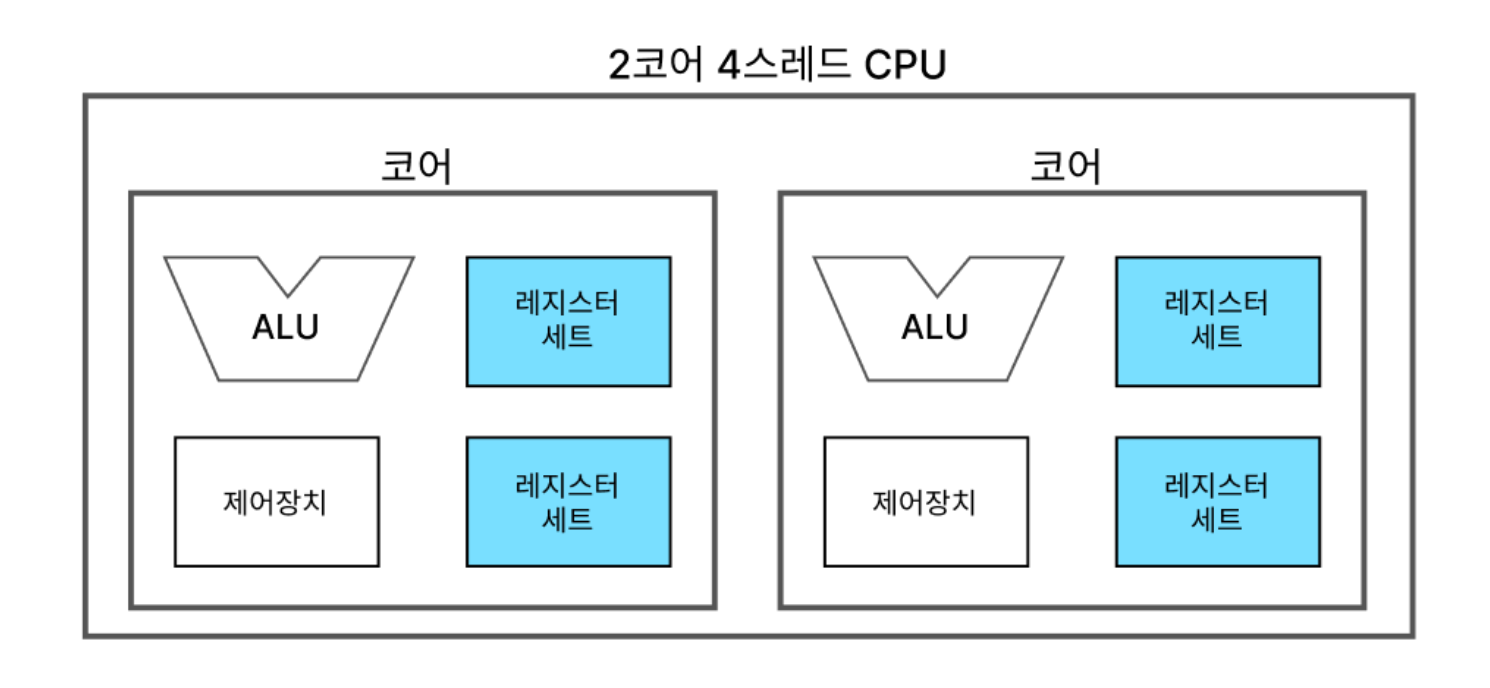 🔍 2개의 코어 = 독립적으로 작동 = 동시에 두 개의 명령어를 병렬 처리 가능
🔍 2개의 코어 = 독립적으로 작동 = 동시에 두 개의 명령어를 병렬 처리 가능
🔍 4 스레드 = 하나의 코어가 두 개의 스레드를 처리하기 위해 각각의 스레드에 독립적인 레지스터 세트 제공 = 하나의 코어에 두 개의 레지스터 세트
👉🏻 병렬 처리로 인해 효율성 증가 / CPU 리소스 활용 극대화
✔️ 명령어 파이프라이닝
- 명령어를 실행하는데 사용되는 하드웨어를 여러 개의 독립적인 단계들로 분할하고, 그들로 하여금 동시에 서로 다른 명령어들을 처리하도록 함으로써 CPU 성능을 높여주는 기술
👉🏻 분할되는 단계의 수가 많아질수록, 처리 속도가 높아짐 - 예를 들면, 명령어를 실행하는 하드웨어를
명령어 인출,명령어 해독,오퍼랜드 인출,실행네 단계로 아래 사진처럼 분할
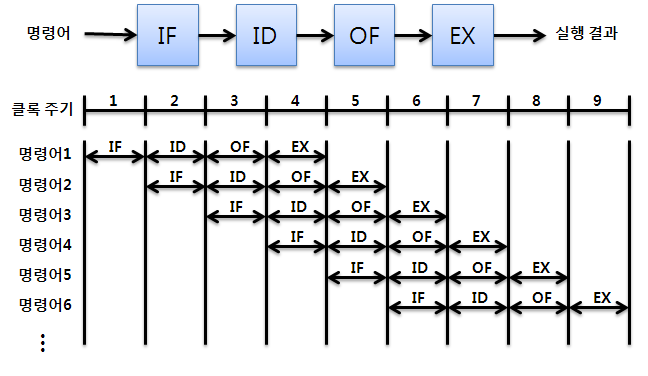 👉🏻각 단계는 명령어 실행의 일부를 담당하며, 다음 명령어가 이전 명령어의 완료를 기다리지 않고 연속적으로 처리해 CPU 처리 효율을 크게 향상
👉🏻각 단계는 명령어 실행의 일부를 담당하며, 다음 명령어가 이전 명령어의 완료를 기다리지 않고 연속적으로 처리해 CPU 처리 효율을 크게 향상

궀뜨