[Tech Blog 번역] Uber의 Domain-Oriented 마이크로서비스 아키텍쳐 소개
개요
최근에 서비스 기반의 아키텍쳐와 특히 마이크로서비스 아키텍쳐의 단점에 대해서 꽤나 많은 논의가 있었다. 몇년 전 만 해도 많은 사람들이 수많은 이점들 때문에 손쉽게 마이크로서비스 아키텍쳐를 채택했다. 예를 들어, 독립적인 배포와 명확한 ownership, 시스템 안정성의 개선, 더 나아진 문제의 분산등은 유연성을 가져다 주었다. 하지만 최근에 사람들은 마이크로서비스가 너무 복잡도가 증가해 사소한 기능조차 빌드하기 어려운 형태로 되버린 경향에 대해서 비판하기 시작했다.
우버는 약 2200개의 주요한 마이크로서비스를 가지게 되었고, 우리는 가장 먼저 이런 트레이드 오프(Trade-off)를 경험하게 되었다. 지난 2년 동안 우버는 마이크로서비스의 복잡도를 줄이면서 그 이점을 가져가기 위한 시도를 해왔다. 이 블로그 포스트를 통해서 DOMA (Domain-Oriented Microservice Architecture, 이하 DOMA) 라고 불리는 우리의 마이크로 서비스 구조를 소개하려고 한다.
최근 몇 년간 위와 같은 단점으로 인해 마이크로서비스 구조를 비판하는 목소리가 컸던 반면에 정말 소수의 사람들만이 마이크로서비스 구조를 완강히 거부했다. 운영에 있어서의 이점은 너무 중요했고, 이것을 대체할만한 것들이 딱히 보이지 않았다. DOMA의 목표는 조직에서 마이크로 서비스를 사용하면서 유연성을 충분히 유지한 채 전체적인 시스템의 복잡도를 감소시키는 방법을 제공하는 것이다.
이 글은 DOMA를 설명하고 Uber가 이 아키텍쳐를 채택하게 된 이유, 또한 플랫폼과 프로덕트 팀, 그리고 이 아키텍쳐를 채택하고자 하는 팀들을 위해 이점들을 설명한다.
마이크로서비스란 무엇인가?
마이크로서비스는 service-oriented 아키텍쳐의 연장선이라고 할 수 있다. 2000년대의 꽤나 큰 '서비스'들에 반해 마이크로서비스는 정말 잘게 쪼개진 기능들의 세트라고 설명할 수 있다. 이러한 어플리케이션들은 모든 네트워크 상에서 사용될 수 있도록 호스팅되었고 잘 정의된 인터페이스로 많이 알려졌다. 다른 어플리케이션에서는 이러한 인터페이스를 'RFC (Remote procedure call)'을 만든다고 한다.
마이크로서비스 아키텍쳐의 핵심 특징은 코드들이 호스팅되고, 호출되고 배포되는지에 대한 방법이다. 조금 크고, monolithic한 (한 덩어리의) 어플리케이션을 생각해봤을 때, 그런 어플리케이션들은 일반적으로 잘 정의된 인터페이스와 함께 캡슐화된 컴포넌트들로 쪼개진다. 그리고 이러한 인터페이스들은 네트워크에 걸쳐 호출되는 것이 아니라, 프로세스 내에서 직접 호출된다. 우리는 마이크로서비스를 기능을 호출하기 위한 성능 (Netowrk I/O와 serialization / deserialization)저하 라이브러리 로 생각할 수 있다.
우리가 이러한 방식으로 마이크로서비스를 생각할 때, 우리는 이렇게 질문할 수 있다. "왜 우리가 마이크로 서비스 아키텍쳐를 채택해야 하는가?". 답은 잦은 독립적인 배포와 스케일링이다. 큰 한덩어리의 어플리케이션에서는 조직전체가 그들의 코드의 배포와 릴리즈를 한번에 하게끔 강요받는다. 각 새로운 버전의 어플리케이션은 이러한 수많은 변화를 포함한다. 배포자체가 risky하고 시간낭비인 것이다. 누구든지 시스템 다운을 불러올 수 있다.
다르게 말하면 각 조직에서는 마이크로서비스를 성능을 조금 희생시키면서 운영적인 이점을 가져가기 위해 채택할 수 있다. 또한 조직에서는 마이크로서비스를 지원하기 위한 인프라 유지 비용도 지출해야 한다. 수많은 상황에서 이러한 트레이드 오프는 이해가 되지만, 가끔은 이러한 마이크로서비스의 성급한 채택이 강한 논쟁을 불러일으키기도 한다.
마이크로서비스를 사용한 동기
우버에서는, 2012-2013년 경에 두개의 큰 모놀리틱 서비스를 가지고 있었고 마이크로서비스가 해결할 수 있는 수많은 운영적인 이슈들을 맞이하게 되어, 마이크로서비스 아키텍쳐를 채택했다.
-
Availability Risk : 모놀리틱 기반에서의 단 한번의 regression이 모든 시스템의 다운을 불러 일으킬 수 있다.
-
Risky, expensive deployments: 잦은 롤백은 시간낭비와 고통의 연속이었다.
-
Poor seperation of concerns: 거대한 코드 베이스에서는 우려점들의 분산이 어려웠다. 매우 빠르게 성장하는 환경에서는 편의성이 결국 로직과 컴포넌트 사이의 허술한 경계를 초래했다.
-
Ineffcient execution: 이러한 이슈들은 팀들이 독립적으로 일하기가 어렵게 만들었다.
다르게 말하면, 우버는 10명에서 100명의 엔지니어로 각 팀에서 각자의 Tech stack들을 가지고 성장했고, 모놀리틱한 아키텍쳐는 결국 그들은 함께 일하는 운명으로 만들었고 독립적으로 운영되기 어려운 형태로 만들었다.
결과적으로 우리는 마이크로서비스 아키텍쳐를 채택하기로 했다. 궁극적으로 우리의 시스템이 지향하는 것은 각 팀들이 좀더 독립적으로 일할 수 있도록 유연해지는 것이었다.
-
System reliability: 마이크로서비스 아키텍쳐가 되면서 전체적인 시스템 안정성이 증가했다. 하나의 서비스가 다운되거나 롤백이 되어도 전체적인 시스템이 다운되는 경우는 없었다.
-
Seperation of concerns: 구조적으로, 마이크로서비스 아키텍쳐는 이러한 질문을 하게 만들었다. "왜 이 서비스가 존재하는가?". 그리고 각각 다른 컴포넌트들의 역할을 좀 더 명확하게 만들었다.
-
Clear Ownership: 누가 코드를 소유했는지 좀 더 명확해졌다. 서비스는 전형적으로 개인, 팀 또는 조직 레벨에 속했고 좀 더 빠른 성장이 가능했다.
-
Autonomous execution: 독립적인 배포와 명확한 ownership은 각각 다른 프러덕트와 플랫폼 팀들이 독립적으로 실행될 수 있게 만들었다.
-
Developer Velocity: 팀들이 각각 독립적으로 그들의 코드를 배포할 수 있게 되었고, 그들 각각의 페이스에 맞게 실행할 수 있게 되었다.
우버는 마이크로서비스 아키텍쳐 없이는 이제까지 이러한 퀄리티와 스케일을 달성할 수 없었을 것이다.
하지만, 엔지니어의 숫자가 100명에서 1000명으로, 회사가 훨씬 커지면서 어마어마하게 복잡해진 시스템 복잡성에 대해서 이슈가 생겨나기 시작했다. 마이크로서비스 아키텍쳐에서는 언제든 변경이 되는 기능을 가지고 있는 블랙박스를 위한 하나의 모놀리틱 코드는 예상치 못한 반응을 불러일으 킬 수 있다.
예를 들어, 엔지니어들이 어떤 문제의 원인을 검사하기 위해 12팀으로 나누어 50여개의 서비스를 뒤져봤어야 했다.
서비스들간의 디펜던시를 이해하는 것은 꽤 어려울 수 있다. N번째 dependency에서의 latency spike는 이슈 업스트림의 cascade를 야기할 수 있다. 실제로 무엇이 일어나는지에 대한 시각화는 올바른 툴 없이 불가능하다.
단순한 기능을 만들기 위해서 한명의 엔지니어가 종종 여러 종류의 서비스들에서 일하는 경우가 있다. 이 때 각각의 서비스들은 다른 개인들과 팀에서 운영되고 있다. 이러한 경우에 코드 리뷰, 디자인, 미팅과 같은 과한 협업에 시간이 많이 소모된다. 이전의 서비스 ownership에 대한 명확한 약속들은 팀들이 각각의 코드를 빌드하면서, 각각의 데이터 모델을 변경하면서, 심지어 서비스 owner를 대신해서 배포하는 등의 형태를 통해 없어졌다. 네트워크로 연결된 모놀리스가 형성될 수 있으며, 여기서 독립적인 것처럼 보이는 서비스는 모두 함께 배포되어 안전하게 변경을 수행해야만 한다.
이러한 결과로, 개발자에게는 느리고, 서비스 owner에게는 안정적이지 않으며 더욱더 고통스러운 마이그레이션이 될 수 있다. 또한 이미 일찍이 마이크로서비스 아키텍쳐를 채택한 조직에게는 다시 돌아갈 수 있는 길이 주어지지 않는다. 마치 "함께 살 수도 없고, 그것들 없이 살 수도 없는 형태"와 같다.
Domain-Oriented 마이크로서비스 아키텍쳐
만약 우리가 마이크로서비스를 I/O bound 라이브러리로, 그리고 마이크로서비스 아키텍쳐를 어떤 큰 분산된 어플리케이션으로 생각한다면 우리는 코드를 잘 관리하기 위해 잘 알려져있는 아키텍쳐를 사용할 수 있다.
"Domain-Oriented 마이크로서비스 아키텍쳐"는 Domain-Driven Design, Clean Architecture, Service-Oriented Architecture, interface-oriented design patterns 과 같은 이미 있는 방법에서 유래했다. 우리는 DOMA가 대규모 조직의 대규모 분산 시스템에서 확립된 설계 원칙을 활용하는 비교적 새로운 방법인 경우에만 혁신적이라고 생각한다.
핵심 원리와 DOMA에 관련된 용어들은 다음과 같다:
-
단일 마이크로 서비스를 지향하는 대신, 우리는 마이크로서비스 관련 컬렉션을 지향한다. 우리는 이것을 도메인(Domain) 이라고 정의한다.
-
우리는 더 나아가 도메인들의 콜렉션들을 생성하고 이것을 레이어라고 부른다. 도메인이 속한 레이어는 해당 도메인에 속한 마이크로서비스가 어떤 dependencies 들을 가질 수 있는지 기준을 가진다. 이것을 레이어 디자인(Layer design) 이라고 한다.
-
콜렉션으로 진입하는 한 점을 게이트웨이(Gateway) 라고 부르고, 도메인들을 위한 명확한 인터페이스들을 제공한다.
-
마지막으로 '각 도메인은 다른 도메인이 알 수 없다'고 정의한다. 이 뜻은 한 도메인이 다른 도메인과 연관된 논리 혹은 코드나 데이터 모델이 없어야 한다는 뜻이다. 꽤나 한 팀이 다른 팀의 도메인 로직을 포함해야 하는 경우가 잦으므로 (예를 들어, 사용자 임의의 검증 로직 또는 데이터 모델에서의 meta context 등), 우리는 도메인 내에 잘 정의된 확장점을 지원하는 확장 아키텍쳐(Extension Architecture) 를 제공한다.
다시 말하면, 시스템적인 아키텍쳐와, 도메인 게이트웨이 그리고 미리 정의되 확장 포인트들을 제공함으로써 DOMA는 마이크로 서비스를 뭔가 복잡한 것에서 이해 가능한 무언가로 변형시키고자 한다: 유연하고, 재사용가능한 구조 세트와 계층적 컴포넌트.
Uber에서의 적용
Domains
우버의 도메인은 기능의 논리적인 그룹으로 엮인 한 개, 혹은 여러개의 마이크로 서비스의 콜렉션을 의미한다. 도메인을 디자인 할 때 나오는 질문중 하나는, "얼마나 도메인이 커야 할까요?" 인데, 여기에 대한 가이던스는 따로 없다. 어떤 도메인들은 몇 십개의 서비스들을 포함하고 있고, 어떤 도메인은 단 한개의 서비스만을 가지고 있을 수도 있다. 중요한 것은 각 콜렉션의 '논리적'인 역할이다. 예를 들어, 지도 검색 서비스는 하나의 도메인을 형성하고, 요금 서비스도 한 도메인을 형성하며, 매칭 플랫폼 (탑승자와 운전자를 매칭해주는)도 하나의 도메인을 형성한다. 이러한 것들은 항상 회사 조직의 구조를 따르지는 않는다. Uber Map 조직은 세 개의 도메인으로 나누어지며 약 80개의 마이크로서비스를 가지고 있으며 그 뒤에는 3개의 다른 게이트웨이들이 존재한다.
Layer Design
레이어 디자인은 Uber의 마이크로서비스 아키텍쳐에서 "그렇다면 한 서비스가 어떤 서비스를 호출할 수 있나요?"에 대한 답변을 해줄 수 있다. 결과적으로, 우리는 레이어 디자인을 "규모 면에서의 세분화" 라고 생각할 수 있다. 또 다르게는, 레이어 디자인을 "규모 면에서의 dependency 관리"라고 생각할 수도 있다.
레이어 디자인은 우버에서의 서비스 dependency 전반에 걸쳐 실패 여파 반경과 제품 특이성을 생각하는 메커니즘으로 설명된다. 도메인이 하단 레이어에서 상단 레이어로 움직이면 그 도메인들은 예외상황이 발생한 경우에 다른 서비스에 미치는 영향이 적으며 좀 더 특정한 서비스의 use case를 의미한다. 반대로 말하면 하단 레이어에서의 기능은 더욱 종속적이며 더 큰 실패 여파 반경을 불러일으킬 수 있고, 이 경우에는 비즈니스 로직상 일반적인 기능이기도 하다. 아래의 그림은 이러한 컨셉을 설명한다.
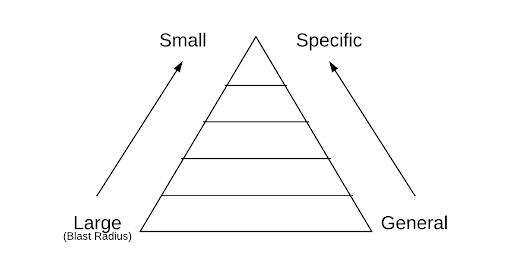
어떤 사람은 가장 상위의 레이어가 한 사용자의 경험 (예를 들면 모바일에서의 한 기능)정도로 생각할 수 있으며 가장 하위의 레이어를 일반화된 비즈니스상의 특징 정도 (예를 들면 회계 관리 혹은 시장 조사)로 생각할 수 있다. 모든 레이어들은 바로 아래에 있는 레이어들만 의존하며 '실패 여파의 반경' 혹은 '도메인 통합' 등과 관련된 질문들에 대해 생각해 볼 수 있는 유용한 직관을 제공한다.
기능들이 종종 이 차트의 구체적인것에서 점점 일반적으로 움직여 '내려가'는 것은 주목할만한 가치가 있다. 어떤 단순한 기능이 점차 플랫폼처럼 진화하는 것을 상상해 볼 수 있다. 실제로 이 아래방향의 통합은 예측가능하며 많은 우버의 주요한 비즈니스 플랫폼이 탑승자와 운전자의 어떤 구체적인 기능으로부터 시작해 점차 발전해 더 많은 사업라인들이 생겨났다. (우버 이츠 혹은 우버 freight 등).
우버에서는 아래 5개의 레이어들을 정의했다.
-
Infrastructure layer : 어느 엔지니어링 조직에서도 사용할 수 있는 기능을 제공한다. 이 레이어는 저장소(storage) 혹은 네트워킹과 같은 거대한 엔지니어링의 질문에 대한 대답이 된다.
-
Business layer: 우버에서 한 조직이 사용할 수 있는 기능들을 제공한다. 하지만 우버 라이드, 이츠 혹은 freight와 같은 LOB(Lines of Business)나 특정한 제품 카테고리에 국한되지는 않는다.
-
Product layer: 특정한 제품 카테고리나 LOB에 관련된 기능들을 제공한다. 하지만 모바일에서는 알 수 없다. 예를 들어 'Ride를 요청'과 같은 로직은 여러 ride 어플리케이션에 의해 레버리지 될 수 있다.
-
Presentation Layer: 사용자가 직접 마주하는 어플리케이션에 관련된 기능들에 직접적으로 관련있는 기능들을 제공한다. (Mobile/ Web)
-
Edge layer: 우버 서비스에서 바깥 세상으로 안전하게 노출되어있는 부분으로 모바일 어플리케이션 등이다.
Gateways
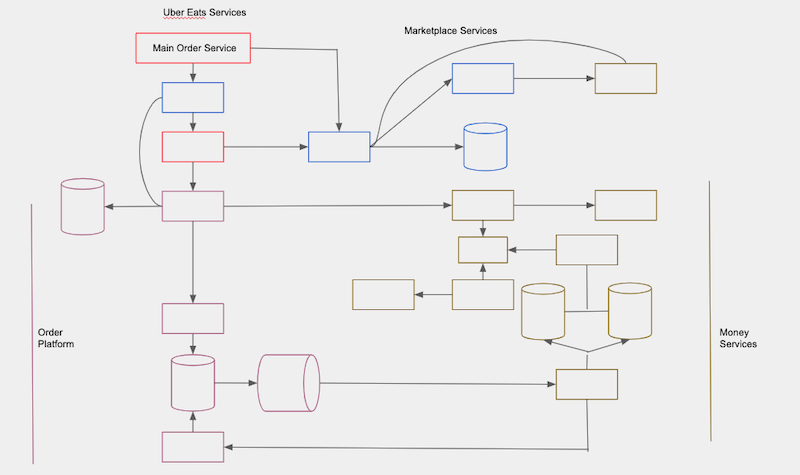
"Gateway API"라는 용어는 이미 마이크로서비스 아키텍쳐에서 넓게 정의되어 있다. 우리의 정의는 기존의 정의에서 크게 다르지는 않다. 다른 부분은 우리가 Gateway를 '도메인'이라고 부르는 어떤 핵심적인 서비스의 콜렉션에 진입하는 '하나의 entry-point'로만 여기려고 한다는 점이다. Gateway 의 성공은 API Design의 성공에 의존하고 있다.
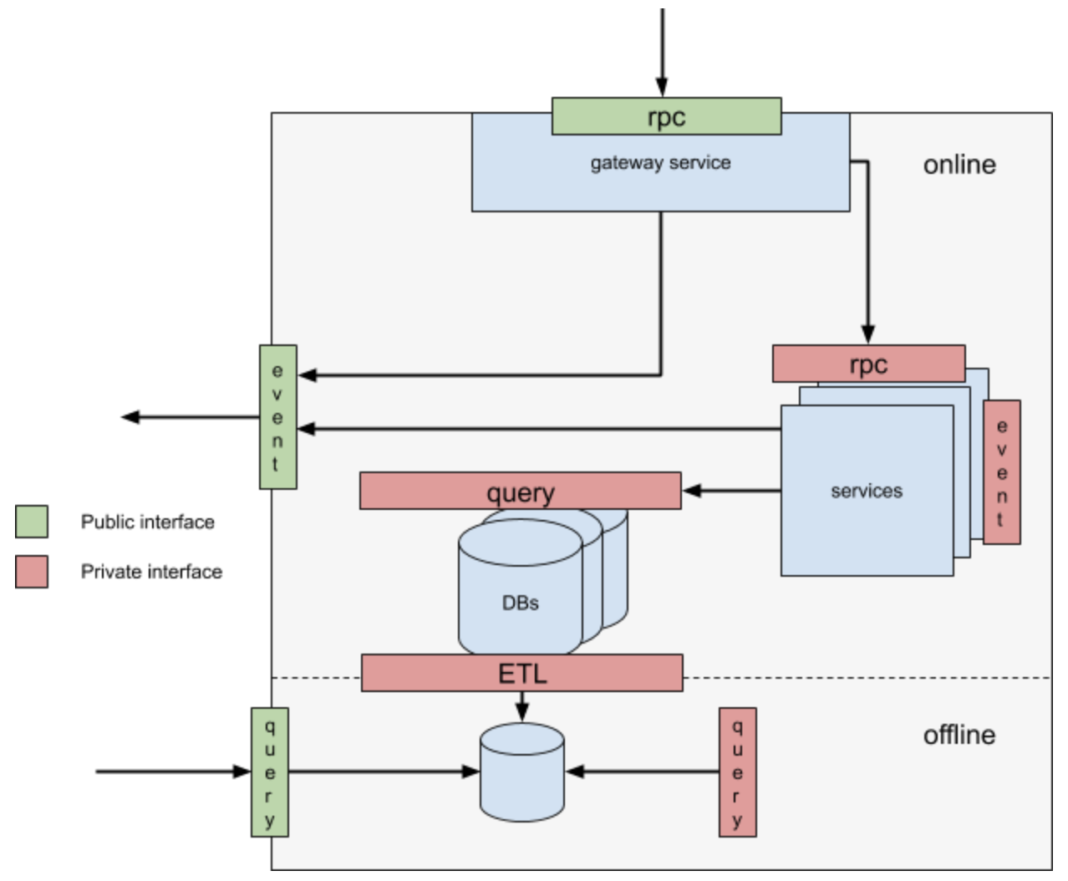
Upstream (로컬에서 서버로) consumer들은 하나의 서비스에서만 구동하고, gateway는 몇몇 다운스트림 서비스에 대한 의존성과 반대로 업스트림 서비스만으로 미래에 있을 migration이나 Discoverability(발견되는정도) 그리고 전체적인 시스템 복잡도의 감소의 관점에서 여러가지 이점을 가져다 준다. 만약 우리가 OO (Object-Oriented) 디자인의 관점에서만 생각해 본다면, 그것들은 핵심 "implementation"의 관점에서 우리가 원하는 것 어떤것이든 할 수 있게 해주는 인터페이스 정의와도 같다. (여기서는 핵심 마이크로서비스의 콜렉션과 같다.)
Extensions
Extension은 도메인을 확장하기 위한 메커니즘을 의미한다. Extension의 기본 개념은 전체적인 안정성에 영향을 미치지 않으면서 실제 서비스 implementation 을 바꿀 필요 없이 기저 서비스의 기능을 확장할 수 있는 메커니즘을 제공하는 것을 의미한다. 우버에서는 두개의 extension model을 제공한다: logic extension과 data extension이다. Extension의 개념은 서로 독립적으로 작동하면서 여러 팀에서 아키텍쳐를 확장할 수 있도록 만들어주었다.
Logic Extensions
Login Extension은 서비스의 주요 로직을 확장하는 메커니즘을 제공한다. logic extension을 위해 우리는 provider 혹은 plugin 패턴을 service-by-service 기반에 정의된 인터페이스와 함께 사용한다. 이것은 기반 플랫폼에서 주요 코드의 변경 없이 interface-driven 방법으로 extension 로직을 적용할 수 있도록 한다.
예를 들어, 운전자들은 온라인에서 서비스를 이용한다. 일반적으로, 우리는 한 명의 운전자가 온라인으로 가는 것을 허용하기 위해 여러가지를 체크한다. (안전 체크, 법규 준수 등). 이때 각각의 사람들은 어떤 독립적인 팀에 의해 소유된다. 각 팀이 같은 endpoint로 logic을 써서 보냄으로써 가능할 수 있지만 이것은 꽤나 복잡할 수 있다. 각 체크는 사용자마다 너무 다르고, 아예 연관이 없을 수도 있다.
logic extension 케이스의 경우, 'go online'의 엔드포인트는 미리 정의된 request type과 response와 함께 각각의 extension을 기대할 수 있는 인터페이스를 정의할 것이다. 각 팀들은 이 로직의 실행될 수 있는 extension을 등록할 것이다. 이러한 경우에 그들은 driver에 대한 context를 가져와 bool 값을 return 하고 드라이버가 go online 할 수 있는지의 여부를 말해준다. 'go online'의 endpoint는 이러한 response를 단순히 순회하고 그것들중에 false가 있는지를 결정할 것이다.
이것은 각 extension으로부터 주요한 코드를 분리시켜주며 extension 간에 독립성을 제공한다 (다른 로직이 실행되고 있는 지 모르도록). 이 주변에 새로운 기능들을 추가하는 것이 훨씬 쉬워지는 것이다.
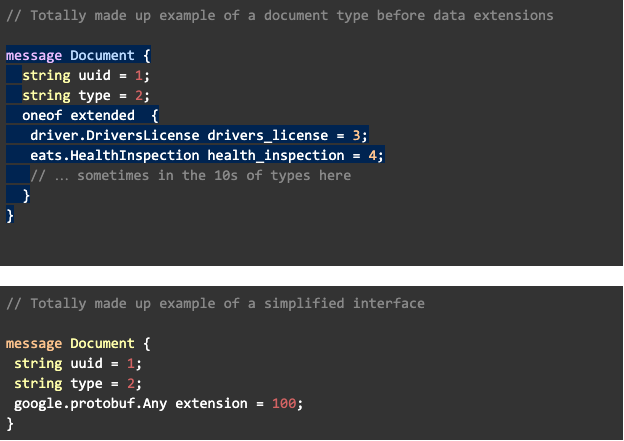
Data Extensions
Data Extension은 핵심 플랫폼 데이터 모델 안에서 인터페이스에 임의의 데이터를 붙일 때 bloat을 피하기 위한 메커니즘을 제공한다. Data extension을 위해서 우리는 Protobuf의 'Any' 기능을 레버리지해서 팀들이 request에 임의의 데이터를 붙일 수 있도록 한다. 서비스들은 주로 이 데이터를 저장하거나 logic extension쪽으로 넘겨서 핵심 플랫폼이 이 임의의 컨텍스트에 대해서 절대 deserializing에 책임을 지지 않도록 한다. Protobuf의 Any 구현에는 보다 강력한 타이핑을 제공하는 대신 인프라 오버헤드가 수반된다. 간단한 구현을 위해서, 임의의 데이터를 나타내는 JSON string 으로 쉽게 설명할 수 있다.
Custom
logic 과 data extension 외에도, Uber 에서의 많은 팀들이 그들의 도메인에 적절한 자신들만의 extension들을 가지고 있다. 예를 들어, 상당수의 integration들이 presentation architecture에 DAG based task 실행 로직을 사용하면서 통합되어 있다.
Benefits
Uber에서의 거의 모든 주요 도메인들이 DOMA에 의해 영향을 받았다. 몇 년동안 우리는 우리의 다양한 비즈니스 라인에 대한 일반화된 로직을 제공하는 Uber의 비즈니스 레이어에 초점을 맞추어왔다.
DOMA는 Uber에서 아직 성숙하지 못하다. 우리는 향후에 우리의 아키텍쳐의 더 심층적인 예시와 많은 데이터들을 공유하길 원한다. 하지만, 초기에 보여지는 신호는 매우 긍정적이다. 간단해진 개발 경험과 전체적인 시스템 복잡도가 감소하고 있다.
Product & Platforms
DOMA는 우버에서 프러덕트와 플랫폼 팀들간의 동의가 만들어낸 결과다. 플랫폼 지원 비용이 종종 크게 감소했고, 프러덕트 팀은 가드레일로부터 많은 수혜를 입었고 개발을 더욱 가속화할 수 있었다.
예를 들어, 우리의 extension architecture에서의 초기 플랫폼 소비자들은 새로운 기능에 대한 우선순위를 정하는 것과 통합하는 시간을 extension architecture을 채택함으로써 코드 리뷰, 기획, 스터디 하는 시간을 포함해 3일에서 3시간정도로 줄일 수 있었다.
Reduced Complexity
이전에는 product team이 도메인의 이점을 취하기 위해 수많은 downstream service를 호출해야 했다; 지금은 단 한번만 호출하면 된다. 새로운 기능을 정착시키기 위해 접촉해야 하는 횟수를 줄임으로써, 플랫폼은 약 25-50%의 시간은 단축시킬 수 있었다. 게다가, 2200개의 마이크로서비스를 70개의 도메인으로 분류할 수 있었다. 대략 50% 정도는 이미 구현이 되었고 대부분은 또 향후에 채택될 예정이다.
Future Migrations
우버에서, 우리는 마이크로서비스의 절반 생명주기가 약 1.5년으로 계산을 했다. 이 뜻은 마이크로서비스의 약 50%가 대부분 생을 마감한다는 뜻이다. Gateway없이 마이크로서비스 구조가 'migration hell'에 빠지기 쉽다. 끊임없이 변화하는 마이크로서비스는 끊임없는 upstream migration이 필요하다. Gateway는 주요한 도메인 서비스에서 dependencies들을 피하게 해주고 이 뜻은 이러한 서비스들이 upstream migration을 강제하지 않고도 변화를 꾀할 수 있다는 뜻이다.
두 우버의 가장 큰 플랫폼은 작년에 게이트웨이 뒷편에서 다시 구성되었다. 이러한 플랫폼에는 기존 소비자를 마이그레이션해야 하는 수백 개의 서비스가 있다. 이러한 경우에 마이그레이션 비용은 엄청나게 높고 완전한 플랫폼을 다시 구성하는 것은 거의 불가능에 가깝다.
새로운 비즈니스 라인 & 제품
DOMA 를 사용해 설계된 플랫폼은 유지하기가 좀 더 쉽고 확장가능하다는 것이 증명되었다. Uber에서 DOMA를 채택했던 대부분의 팀들은 더욱 그러했는데 새로운 비즈니스 라인을 지원하는 것이 너무 비용이 컸기 때문이다.
실용적인 조언
이 섹션에서는 DOMA를 채택하고자 하는 회사들에게 좀더 실용적인 조언을 주려고 한다. 여기서의 가이딩 원리는 적재적소에 nudge로부터 성숙하고 사려깊은 마이크로서비스 구조 경험에서 비롯된것이다. 현실적으로 어떤 한 큰 마이크로서비스 아키텍쳐에서 "재구성"하는 것은 가능하지는 않다는 것이다.
결과적으로, 우리는 마이크로서비스 아키텍쳐를 진화시켜나가는 것은 좀 더 가지치기를 하는 것과 비슷하다. 가지를 침으로써 그것이 top-down 이나 한번 사용되는 아키텍쳐보다 결과적으로 올바르게 성장하게끔 하는 것이다. 이것은 동적이고 진보적인 절차다.
Startups
아마 떠오르는 질문들은 "언제 이 마이크로서비스 아키텍쳐를 적용해야 할까요?", 그리고 "이게 지금 우리 조직에 맞는 걸까요?" 등일 것이다. 위에서 보았듯이 마이크로서비스가 많은 수의 엔지니어가 있는 조직에서 운영적인 이점을 가져다 주긴 하지만 이것이 결국 어떤 기능들을 빌드하기 어렵게 복잡도를 증가한다는 트레이드-오프가 있다.
조그만 조직에서는, 운영적인 이점이 결코 구조적인 복잡도를 증가시키지 않는다. 게다가 마이크로서비스 아키텍쳐는 종종 우선순위 관점에서 차선책 혹은 초기 단계의 기업이 예산이 바닥난 경우에 좀 더 헌신된 엔지니어링 리소스를 필요로 하기도 한다.
이러한 기조에서, 마이크로서비스들을 동시에 함께 들고있는 것은 결코 합리적이지 않다. 만약 조직에서 마이크로서비스를 채택하기로 했다면, "거대한 분산 어플리케이션으로써의 마이크로서비스"라고 생각해야하고 마이크로서비스 사이에서의 걱정 분산에 대해서 생각해야 한다. 또한, 첫번째 마이크로서비스가 비즈니스의 핵심을 제일 잘 알고 있고 처음이 가장 중요하고 장기적으로 지속될 가능성이 높다는 것을 인지해야 한다.
Midsize
한번 기업이 여러팀들로 된 중간 사이즈로 되면, 여러 다른 기능과 플랫폼들간의 명확한 세분화가 불분명해지고, 마이크로서비스 구조는 확실히 유용하게 된다.
어떤 한 사람이 마이크로 서비스간의 계층구조에 대해서 생각해보는 단계가 된다. Dependency 관리는 저욱더 중요해지고, 몇몇 서비스들은 비즈니스 운영에 훨씬 중요해지기 시작한다. 또한 계속 팀들이 그것들을 점점 의지하게 된다.
플랫폼화의 초기 투자는 추후에 큰 금전적인 이점을 불러일으킬 수 있다. 만약 어떤 사람이 핵심 플랫폼 서비스에서 임의의 product logic을 피하고 product agnostic한 비즈니스 플랫폼을 완전히 만들 수 있다면, 기술 부채를 피할 수 있는 가능성이 있다. 여기서는 목표치를 달성하기 위해 extension들을 사용하는 것도 용인될 수 있다.
마이크로서비스의 수가 여전히 훨씬 적어도, 그들이 함께 엮이는 것은 용인되지 않을 수 있다. 하지만 Uber의 DOMA 구현이 딱 한개의 서비스만으로도 가능하다는 사실은 주목할만하다. 그래서 "domain-oriented" 방법으로 생각하는 것은 여전히 유용하다.
Large
더 큰 엔지니어링 조직에서는 아마 꽤나 많은 디펜던시들과 수백명의 엔지니어들, 그리고 마이크로서비스들을 가지고 있을 것이다. 여기서, DOMA는 최대의 효용성을 가진다. 명확하게 마이크로서비스의 클러스터들이 게이트웨이와 함께 도메인으로 쉽게 묶일수도 있다. 레거시 서비스들은 종종 리팩토링 되거나 다시 구성되서 병합이 되는데, 이 뜻은 게이트웨이들이 설치되어있는 경우 마이그레이션의 관점에서 가치를 제공하기 시작할 것이라는 뜻이다.
명확한 계층구조는 특정한 기능들을 위해 "product"서비스들로 운영되고 있는 서비스들과 "플랫폼"이라고 불리우는 여러개의 프로덕트를 점차 지원하는 서비스들에 있어서 점점 더 중요할 것이다. 플랫폼과 구별되어, 임의의 제품 로직을 유지하는 것은 이 단계에서 매우 중요하다. 그렇게 함으로써 시스템 전반적인 비안정성과 플랫폼에서의 과중한 운영적인 수고들을 피할 수 있다.
최종 정리
우리는 여전히 우버의 더 많은 팀들이 적극적으로 DOMA를 발전시켜나가고 있다. DOMA의 주요 인사이트는 하나의 마이크로서비스 구조가 오직 하나의 큰 분산된 프로그램이라는 것이고 이것을 어떤 종류의 소프트웨어에서든지 같은 원리로 적용할 수 있다는 것이다. DOMA는 이러한 원리를 연습하는데 있어서 하나의 접근방법이다. 우리는 이것이 다른 사람들이 유용하다는 것을 알길 원하고, 피드백을 기대한다.
