<프로그램과 프로세스>
프로세스(process)란?
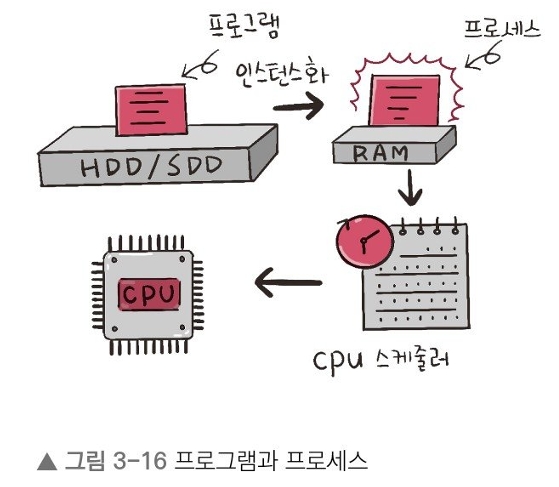
컴퓨터에서 실행되고 있는 프로그램이며, CPU 스케줄링의 대상이 되는 작업이라는 의미로 쓰인다.
사진처럼 프로그램이 메모리에 올라가면 프로세스가 되는 인스턴스화가 일어나고, 이후 운영체제의 CPU 스케줄러에 따라 CPU가 프로세스를 실행한다.
3.3.1 프로세스와 컴파일 과정
프로세스는 프로그램이 메모리에 올라가 인스턴스화된 것을 말한다.
예를 들어서 프로그램은 구글 크롬 프로그램(chrome.exe)과 같은 실행 파일이고, 이를 두 번 클릭하면 구글 크롬 프로세스로 변환되는 것이다.
프로그램을 만드는 과정은 만드는 언어마다 다를 수 있고, 컴파일 언어인 C언어 기반의 프로그램을 기준으로는 컴파일러가 컴파일 과정을 통해 컴퓨터가 이해할 수 있는 기계어로 번역하여 실행할 수 있는 파일을 만들게 된다.
아래는 컴파일 과정을 나타낸 사진이다.
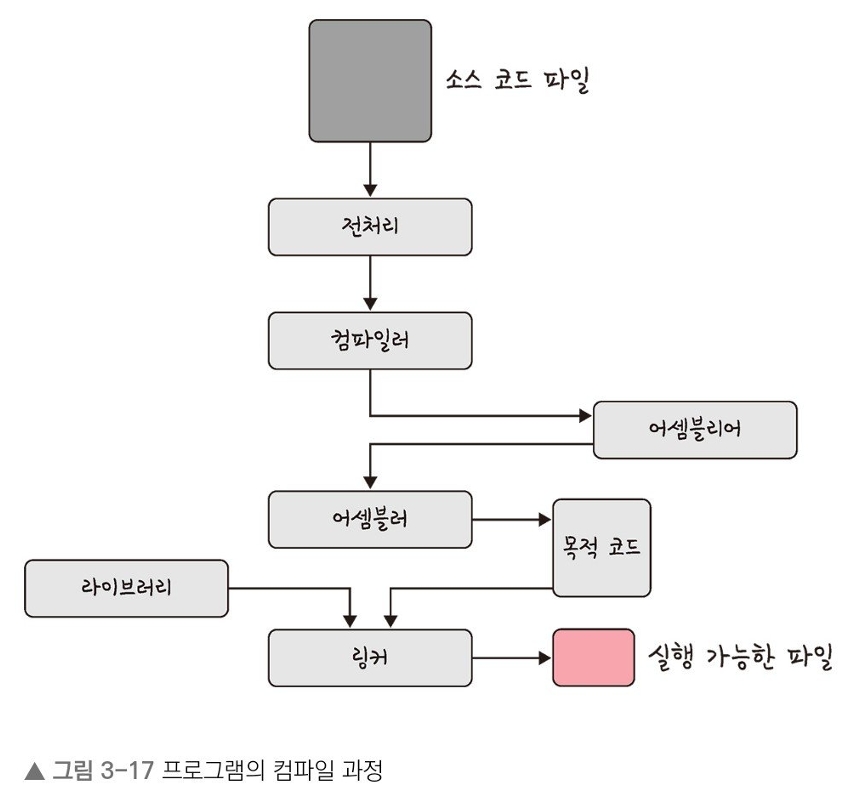
<프로그램의 컴파일 과정>
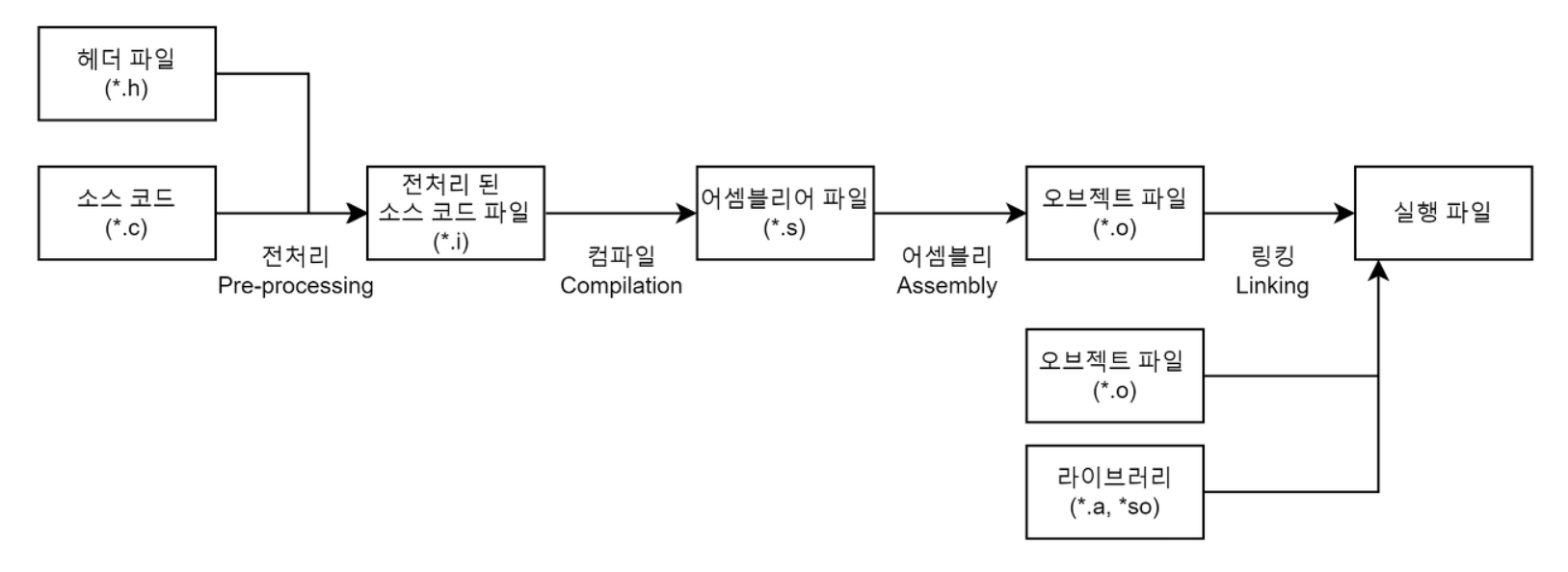
컴파일 과정은 4가지 단계(전처리 과정 - 컴파일 과정 - 어셈블리 과정 - 링킹 과정)로 나눠진다.
1. 전처리(Pre-processing) 과정
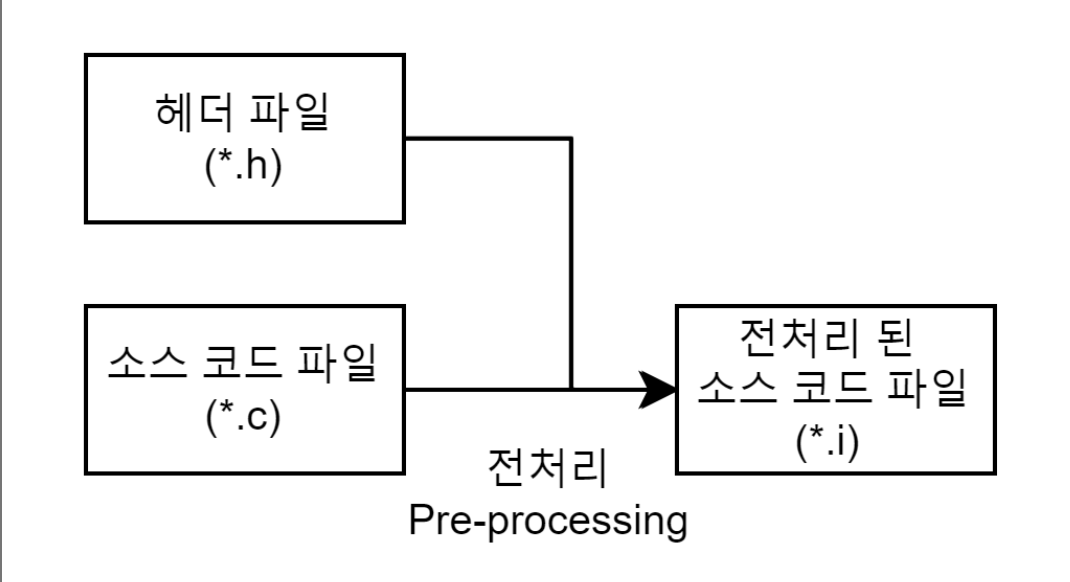
전처리기(Preprocessor)를 통해 소스 코드 파일(*.c)을 전처리된 소스 코드 파일(*.i)로 변환하는 과정이다.이 과정에서 대표적으로 세 가지 작업을 수행한다.
주석 제거 : 소스 코드에서 주석을 전부 제거한다. 주석은 사람들이 알아볼 수 있게 남긴 내용이지 컴퓨터가 알 필요는 없기 때문이다.
헤더 파일 삽입 : #include 지시문을 만나면 해당하는 헤더 파일을 찾아 헤더 파일에 있는 모든 내용을 복사해서 소스 코드에 삽입한다. 즉, 헤더 파일은 컴파일에 사용되지 않고 소스 코드 파일 내에 전부 복사된다. 헤더 파일에 선언된 함수 원형은 후에 링킹 과정을 통해 실제로 함수가 정의되어 있는 오브젝트 파일(컴파일된 소스 코드 파일)과 결합한다.
매크로 치환 및 적용 : #define 지시문에 정의된 매크로를 저장하고 같은 문자열을 만나면 #define 된 내용으로 치환한다. 간단하게 말해 매크로 이름을 찾아서 정의한 값으로 전부 바꿔준다.
+) 매크로는 특정한 문자열을 미리 정의한 값으로 치환하는 기능을 한다.
아래는 매크로 치환 및 적용에 대한 예시이다.
예를 들어, 아래와 같은 코드가 있다고 해보면
#include <stdio.h>
#define PI 3.14159
#define SQUARE(x) ((x) * (x))
int main() {
double radius = 2.0;
double area = PI * SQUARE(radius);
printf("원의 넓이: %f\n", area);
return 0;
}위 코드를 컴파일할 때 전처리기가 동작하여 #define으로 정의된 내용을 치환한다.
즉, 코드가 컴파일되기 전에 다음과 같이 변환한다.
#include <stdio.h>
int main() {
double radius = 2.0;
double area = 3.14159 * ((radius) * (radius));
printf("원의 넓이: %f\n", area);
return 0;
}2. 컴파일(Compilation) 과정
컴파일러(Compiler)를 통해 전처리된 소스 코드 파일(*.i)을 어셈블리어 파일(*.s)로 변환하는 과정이다.이 과정에서 우리가 일반적으로 컴파일하면 생각하는 언어의 문법 검사가 이루어진다. 또한 Static한 영역(Data, BSS 영역)들의 메모리 할당을 수행한다.

+) 1) 문법 검사가 컴파일 과정에서 이루어지는 이유
문법 오류를 검출해야 오류가 있는 코드가 기계어로 변환되지 않도록 막을 수 있다.
ex1) int 1abc = 5; -> 변수명이 숫자로 시작하면 안 됨
ex2) int x = "hello" -> 문자열을 정수 변수에 할당할 수 없음2) 정적(Static) 메모리 할당이 수행되는 이유
프로그램이 실행되기 전에 필요한 메모리 크기를 결정해야 하기 때문이다.
컴파일러는 전역 변수, 정적 변수 등이 차지할 메모리 크기를 미리 계산하여 실행 파일의 데이터 영역에 저장할 정보를 결정한다.
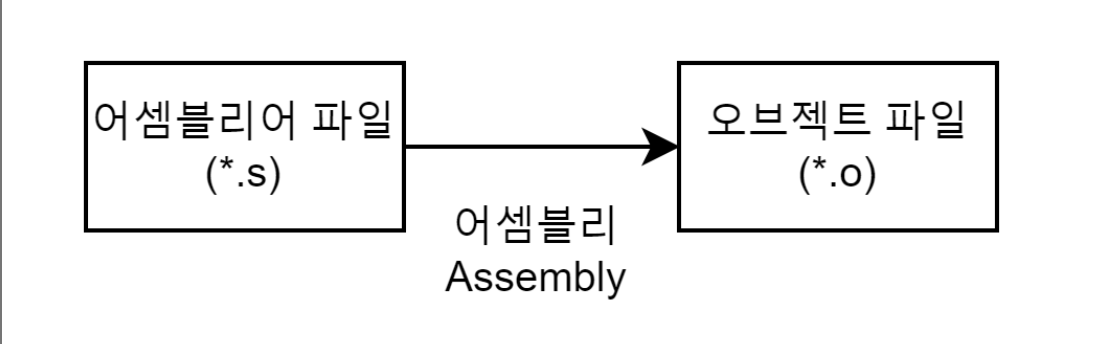
3. 어셈블리(Assembly) 과정
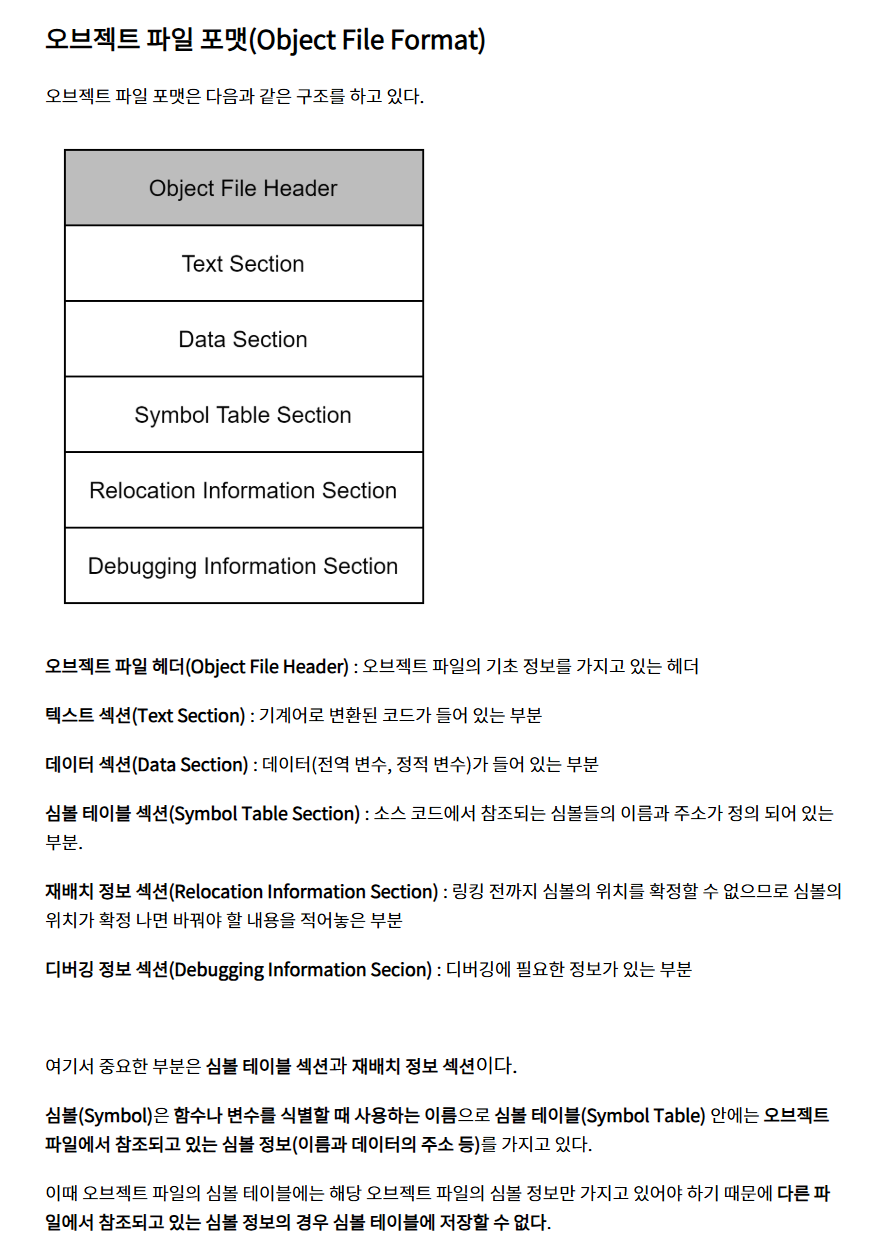
어셈블러(Assembler)를 통해 어셈블리어 파일(*.s)을 오브젝트 파일(*.o)로 변환하는 과정이다.+) 오브젝트 파일이란?
어셈블리 코드는 이제 더 이상 사람이 알아볼 수 없는 기계어로 변환되는데 이를 오브젝트 코드라 부른다.
오브젝트 코드로 구성된 파일을 오브젝트 파일(Object File)이라 부르며 이 오브젝트 파일은 특정한 파일 포맷을 가진다.
여기에서 오브젝트 파일 포맷의 종류는 Windows의 경우 PE(Portable Executable), Linux의 경우 ELF(Executable and Linking Format)로 나눠진다.
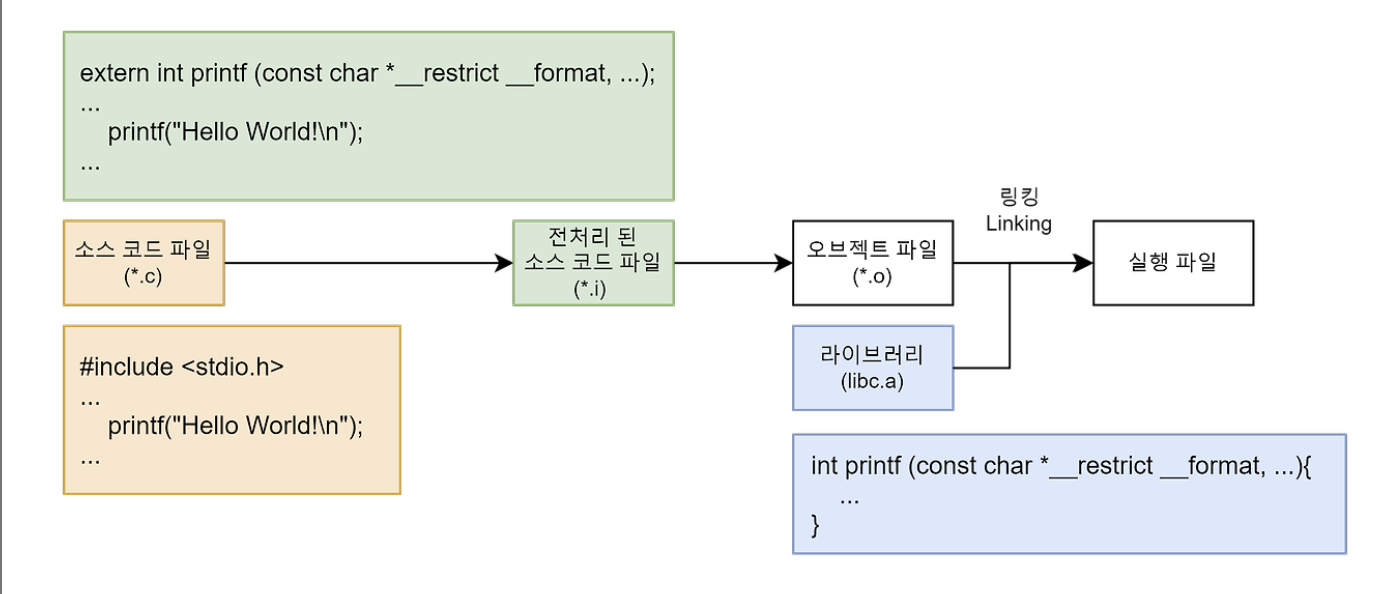
#include<stdio.h> 라이브러리를 이용해서 printf 함수를 사용하는 소스 코드 파일이 있다고 가정해보자.
우린 이 소스 코드 파일을 컴파일하여 오브젝트 파일을 생성할 수 있다.
하지만 이 오브젝트 파일은 독립적으로 실행할 수 없다. 이 파일 안에는 printf 함수를 구현한 내용이 없기 때문이다.
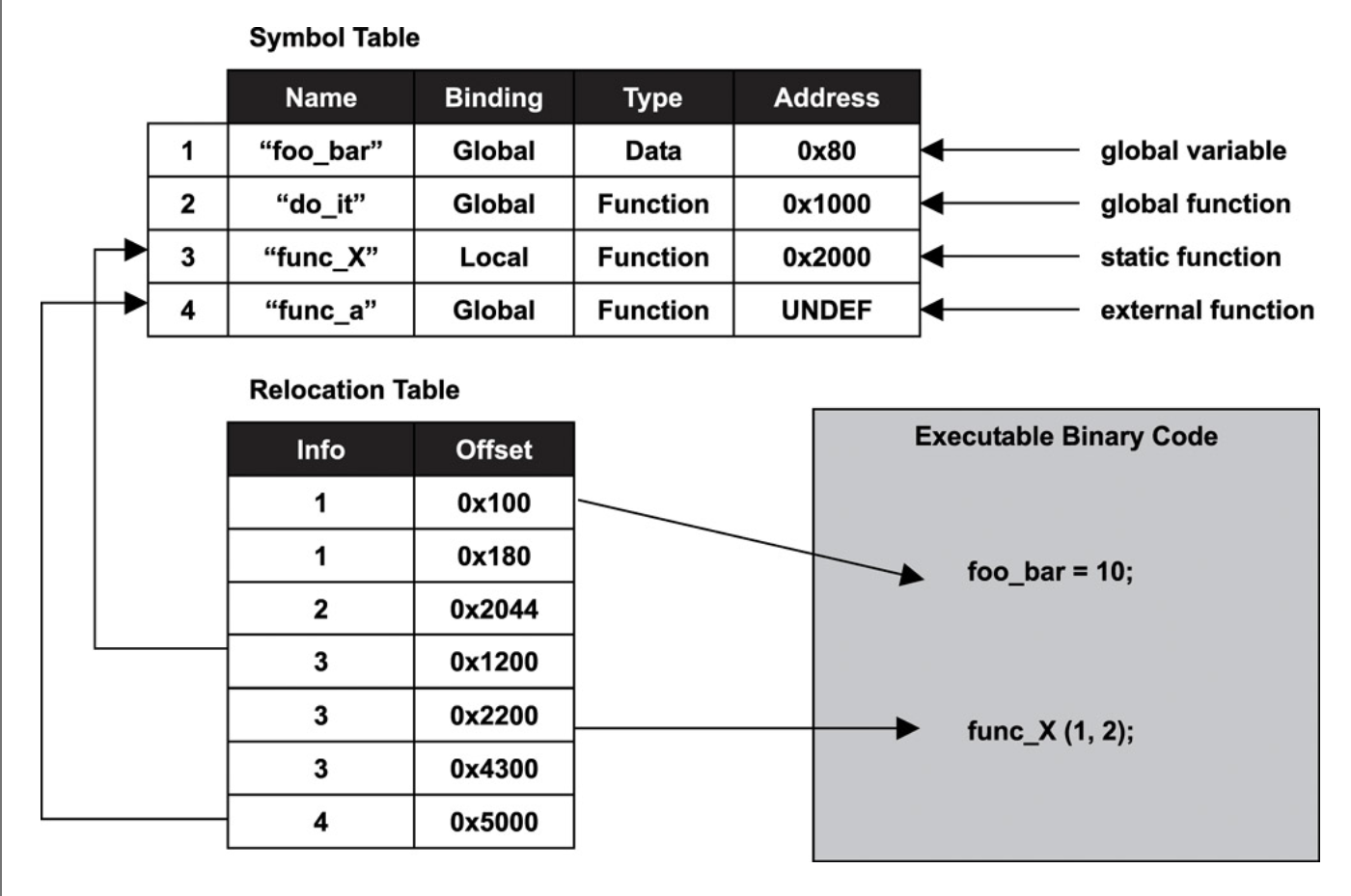
전처리 과정을 통해 #include<stdio.h>로부터 printf 함수의 원형은 복사했지만 printf를 구현한 내용은 포함되어 있지 않다. 오브젝트 파일 구조에서 말한 것처럼 심볼 테이블에는 해당 오브젝트 파일의 심볼 정보만 가지고 있지 외부에서 참조하는 printf 함수에 대한 심볼 정보는 가지고 있지 않다.
즉, 이 오브젝트 파일을 실행하기 위해서는 printf 함수를 사용하는 오브젝트 파일과 printf 함수를 구현한 오브젝트 파일(libc.a 라이브러리)을 연결시키는 작업이 필요하다.
이러한 연결 과정을 링킹(Linking)이라 부른다.
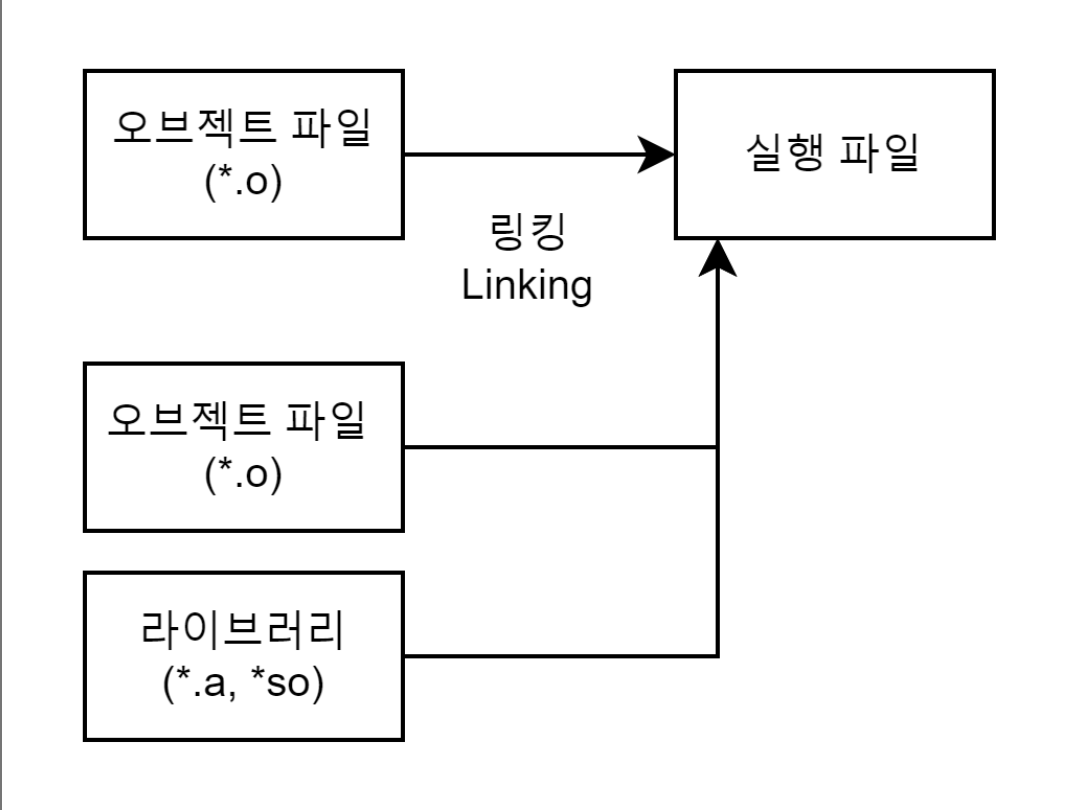
4. 링킹(Linking) 과정
링킹(Linking) 과정은 링커(Linker)를 통해 오브젝트 파일(*.o)들을 묶어 실행 파일로 만드는 과정이다.이 과정에서 오브젝트 파일들과 프로그램에서 사용하는 라이브러리 파일들을 링크하여 하나의 실행 파일을 만든다.
이때 라이브러리를 링크하는 방법에 따라 정적 링킹(Static Linking)과 동적 링킹(Dynamic Linking)으로 나눌 수 있다.
1) 정적 라이브러리(Static Link Library) 정의
정적 라이브러리는 정적 링킹(Static Linking) 과정에서 링커가 프로그램에 필요로 하는 부분을 라이브러리에서 찾아 실행 파일에 복사하는 방식의 라이브러리를 의미한다.정적 라이브러리 확장자는 윈도우 환경에서는 .lib, 리눅스 환경에서는 .a 이다.
2) 동적 라이브러리(DLL, Dynamic Link Library, Shared Library)
동적 라이브러리는 동적 링킹(Dynamic Linking) 과정에서 링커가 라이브러리 내용을 복사하지 않고 해당 내용의 주소만 가지고 있다가 런타임에 실행 파일과 라이브러리가 메모리에 위치할 때 해당 주소로 가서 필요한 내용을 가져오는 방식의 라이브러리를 의미한다.동적 라이브러리 확장자는 윈도우 환경에서는 *.dll, 리눅스 환경에서는 *.so 이다.
<링커의 역할>
링커의 역할은 크게 심볼 해석과 재배치로 나눌 수 있다.
1) 심볼 해석(Symbol Resolution)
심볼 해석은 각 오브젝트 파일에 있는 심볼 참조를 어떤 심볼 정의에 연관시킬지 결정하는 과정이다.
여러 개의 오브젝트 파일에 같은 이름의 함수 또는 변수가 정의되어 있을 때 어떤 파일의 어떤 함수를 사용할지 결정한다.2) 재배치(Relocation)
재배치는 오브젝트 파일에 있는 데이터의 주소나 코드의 메모리 참조 주소를 알맞게 배치하는 과정이다.링커가 컴파일러가 생성한 오브젝트 파일을 모아서 하나의 실행 파일을 만들 때, 각 오브젝트 파일에 있는 데이터의 주소나 코드의 메모리 참조 주소가 링커에 의해 합쳐진 실행 파일에서의 주소와 다르게 때문에 그것을 알맞게 수정해줘야 한다.
이를 위해 오브젝트 파일 안에 재배치 정보 섹션(Relocation Information Section)이 존재한다.
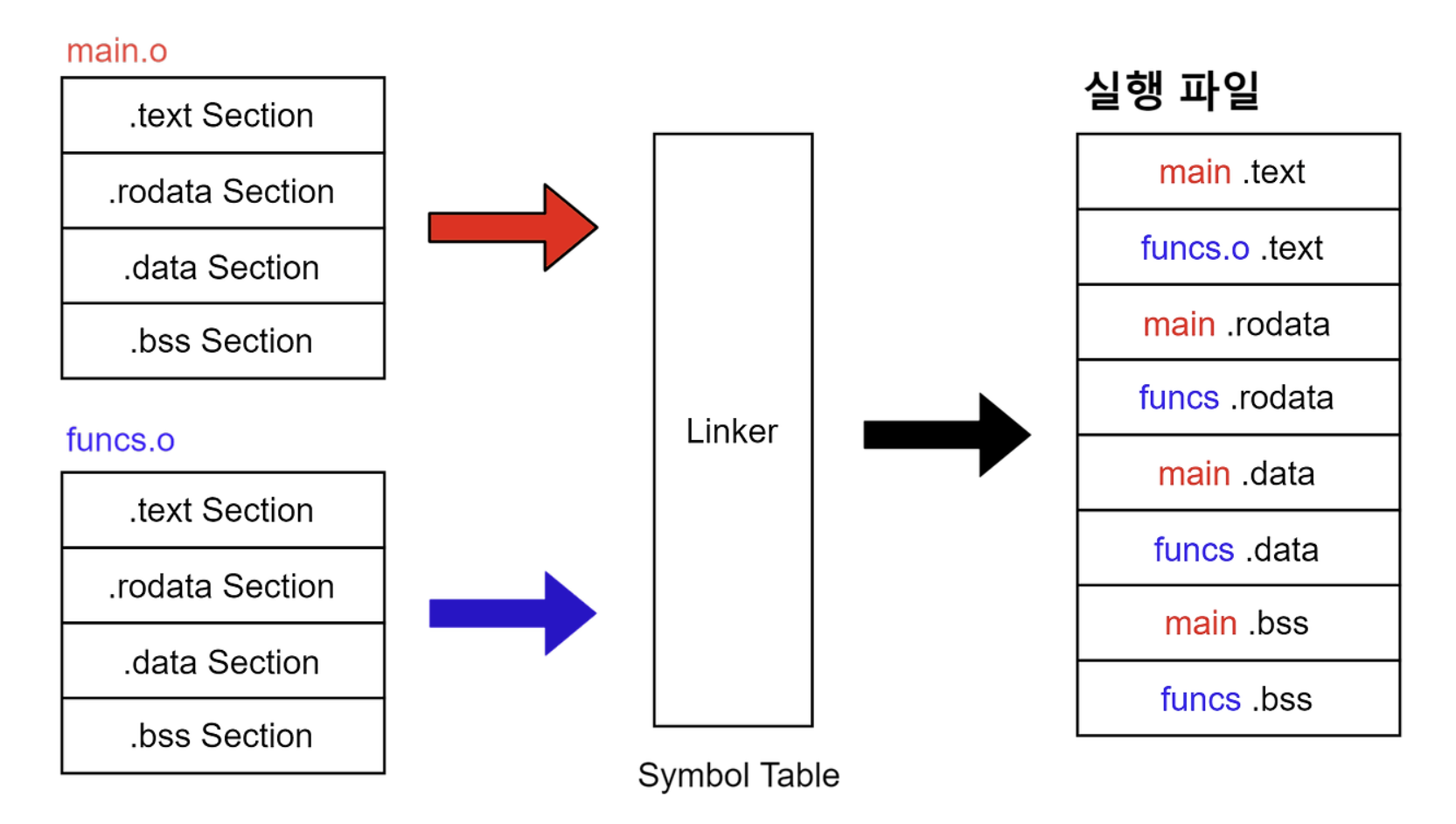
링킹 과정에서 같은 세션끼리 합쳐진 후 재배치가 일어난다.
위 그림을 통해 알 수 있듯이 오브젝트 파일 형식은 링킹 과정에서 링커가 여러 개의 오브젝트 파일들을 하나의 실행 파일로 묶을 때 필요한 정보를 효율적으로 파악할 수 있는 구조이다.링킹을 하기 전 오브젝트 파일을 재배치 가능한 오브젝트 파일(Relocatable Object File)이라 부르고 링킹을 통해 만들어지는 오브젝트 파일을 실행 가능한 오브젝트 파일(Executable Object File)이라 부른다.
3.3.2 프로세스의 상태
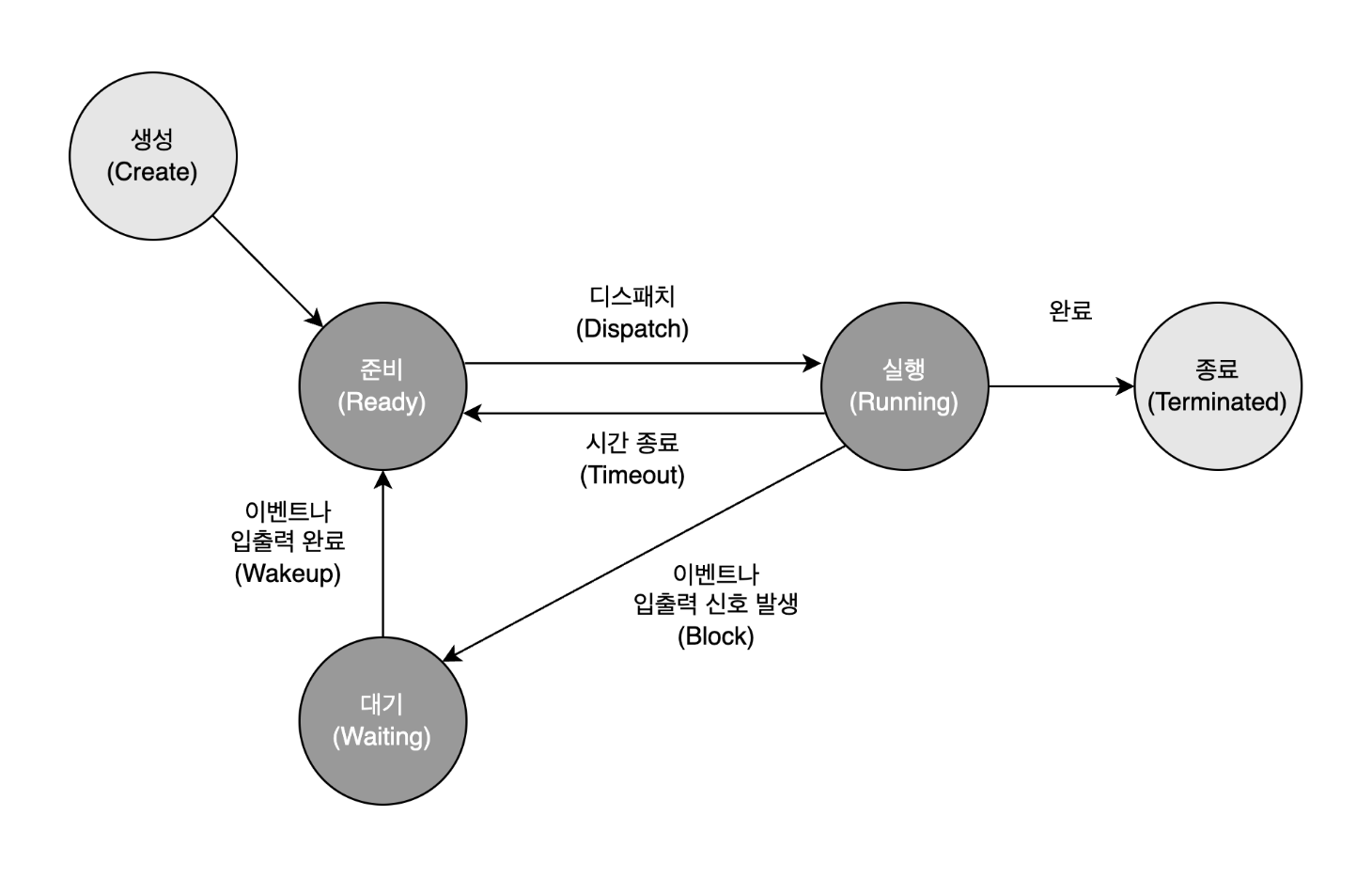
생성 상태(create)는 프로세스가 생성된 상태를 의미하며 fork() 또는 exec() 함수를 통해 생성하는데 이때 PCB가 할당된다.
fork()는 부모 프로세스의 주소 공간을 그대로 복사하며, 새로운 자식 프로세스를 생성하는 함수이다.
주소 공간만 복사할 뿐이지 부모 프로세스의 비동기 작업 등을 상속하지는 않는다.
exec()는 새롭게 프로세스를 생성하는 함수이다.
| 상태 | 설명 |
|---|---|
| 생성(create) | 프로세스의 생성 |
| 실행(running) | 프로세스가 CPU를 차지하여 명령어들 실행 |
| 준비(ready) | 프로세스가 CPU를 사용하고 있지는 않지만 언제든지 사용할 수 있는 상태 우선순위가 높은 프로세스 순으로 CPU 할당 |
| 대기(waiting) | 보류(block)라고도 부름. 입출력 완료, 시그널 수신 등 어떤 사건을 기다리고 있는 상태. |
| 종료(terminated) | 프로세스의 실행 종료 |
아래는 각각의 상세한 상태별 변화이다.
① 준비 -> 실행(Dispatch)
준비 큐 맨 앞에 있는 프로세스가 프로세서를 점유하는 것을 디스패치라고 한다.다중 프로그래밍 운영체제는 실행 상태인 프로세스가 할당된 시간만큼만 프로세서를 사용하여 특정 프로세스의 독점을 방지한다.
② 실행 -> 준비(Timeout)
운영체제는 프로세스의 독점을 방지하기 위해 인터럽트 클록(interrupt clock)을 두어 일정 시간만 점유하도록 제한한다.이 시간이 지나도 프로세서를 반환하지 않으면 클록이 인터럽트를 발생시켜 운영체제에 프로세서 제어권을 부여한다.
③ 실행 -> 대기(Block)
할당된 시간 이전에 실행 상태의 프로세스에 입출력 연산 또는 자원 요청 등의 문제로 프로세서를 스스로 넘기는 경우이다.④ 대기 -> 준비(Wakeup)
입출력 작업이 끝나거나 문제가 해결된다면 대기 상태에서 준비 상태가 된다.
3.3.3 프로세스의 메모리 구조
위에서부터 스택, 힙, 데이터 영역, 코드 영역으로 나눠진다.
스택은 위 주소부터 할당되고 힙은 아래 주소부터 할당된다.
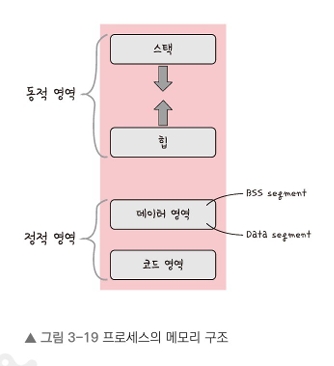
스택과 힙은 동적 할당이 되며, 동적 할당은 런타임 단계에서 메모리를 할당받는 것이다.
스택은 지역 변수, 매개변수, 실행되는 함수에 의해 늘어나거나 줄어드는 메모리 영역이다.
힙은 동적으로 할당되는 변수들을 담는데, malloc(), free() 함수를 통해 관리할 수 있으며 동적으로 관리되는 자료 구조의 경우 힙 영역을 사용한다.
데이터 영역과 코드 영역은 정적 할당되는 영역으로, 정적 할당은 컴파일 단계에서 메모리를 할당하는 것을 말한다.
데이터 영역은 아래와 같이 나뉘어서 저장된다.
BSS segment와 Data segment는 전역 변수 또는 static, const로 선언되어 있다.
BSS segment는 0으로 초기화 또는 어떠한 값으로도 되어 있지 않은 변수들이 이 메모리 영역에 할당되고, Data segment는 0이 아닌 값으로 초기화된 변수가 이 메모리 영역에 할당된다.
code segment는 프로그램의 코드가 들어간다.
3.3.4 PCB
PCB(Process Control Block)은 운영체제에서 프로세스에 대한 메타데이터를 저장한 '데이터'를 말한다.
프로세스 제어 블록이라고도 한다.
프로세스가 생성되면 운영체제는 해당 PCB를 생성한다.+) 메타데이터란?
데이터에 관한 구조화된 데이터이자 데이터를 설명하는 작은 데이터, 대량의 정보 가운데에서 찾고 있는 정보를 효율적으로 찾아내서 이용하기 위해 일정한 규칙에 따라 콘텐츠에 대해 부여되는 데이터이다.
<PCB의 구조>
아래 사진은 PCB의 구조이다.


<컨텍스트 스위칭>
컨텍스트 스위칭은 PCB를 기반으로 프로세스의 상태를 저장하고 로드시키는 과정을 말한다.
위와 같이 컨텍스트 스위칭이 일어날 때 유휴 시간(idle time)이 발생하는 것을 볼 수 있다.
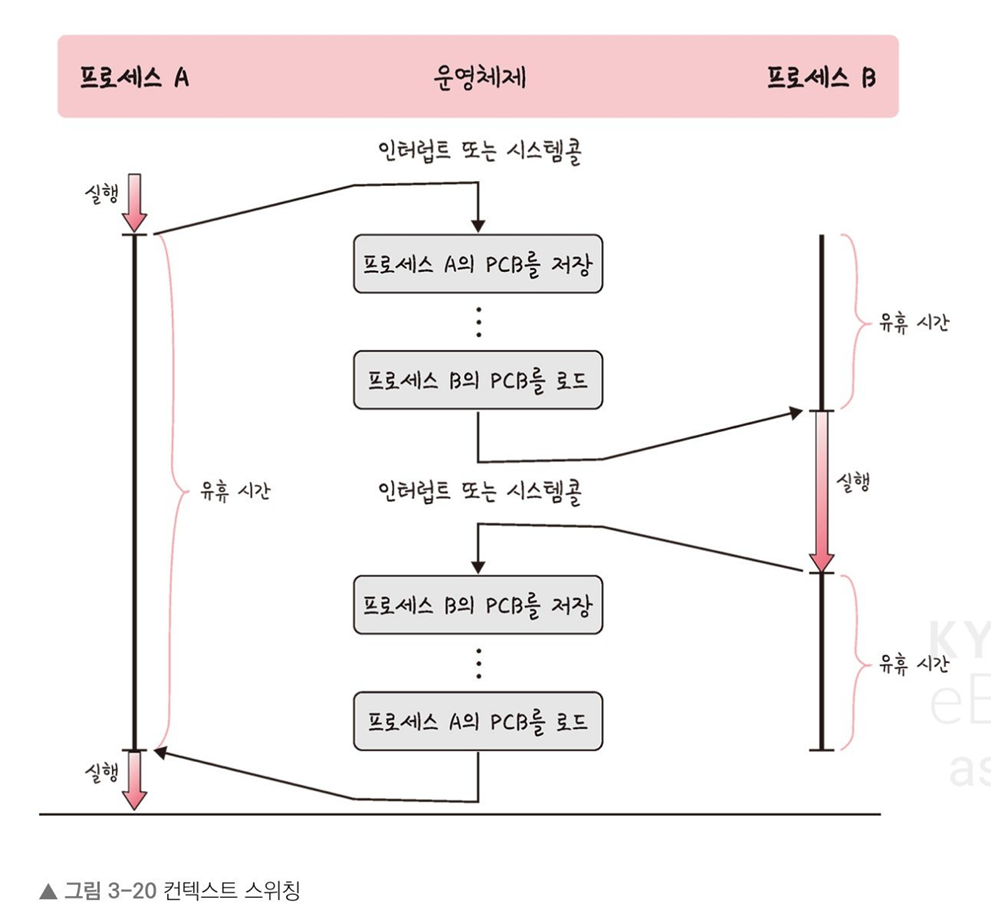
이뿐만 아니라 컨텍스트 스위칭에 드는 비용이 더 있는데 이를 캐시미스라고 한다.
<비용: 캐시미스>
컨텍스트 스위칭이 일어날 때 프로세스가 가지고 있는 메모리 주소가 그대로 있으면 잘못된 주소 변환이 생기므로 캐시 클리어 과정을 겪게 되고 이 때문에 캐시미스가 발생한다.
<스레드에서의 컨텍스트 스위칭>
컨텍스트 스위칭은 스레드에서도 일어나는데 스레드는 스택 영역을 제외한 모든 메모리를 공유하기 때문에(각 스레드가 별도의 메모리 공간을 할당받는 대신, 공통의 데이터와 자원을 사용할 수 있게 하여 메모리 사용을 최적화함) 스레드 컨텍스트 스위칭의 경우 비용이 더 적고 시간도 더 적게 걸린다.
3.3.5 멀티프로세싱
멀티프로세싱이란?
여러 개의 '프로세스', 즉 멀티프로세스를 통해 동시에 두 가지 이상의 일을 수행할 수 있는 것을 말한다.
웹 브라우저는 멀티프로세스 구조를 가지고 있으며 다음과 같다.
1. 브라우저 프로세스: 주소 표시줄, 북마크 막대, 뒤로 가기 버튼, 앞으로 가기 버튼 등을 담당하며 네트워크 요청이나 파일 접근 같은 권한을 담당한다.
2. 렌더러 프로세스: 웹 사이트가 '보이는' 부분의 모든 것을 제어한다.
3. 플러그인 프로세스: 웹 사이트에서 사용하는 플러그인을 제어한다.
4. GPU 프로세스: GPU를 이용해서 화면을 그리는 부분을 제어한다.
IPC
멀티 프로세스는 IPC(Inter Process Communication)가 가능하며 IPC는 프로세스끼리 데이터를 주소받고 공유 데이터를 관리하는 메커니즘이다.
IPC의 종류로는 공유 메모리, 파일, 소켓, 익명 파이프, 명명 파이프, 메시지 큐가 있다.
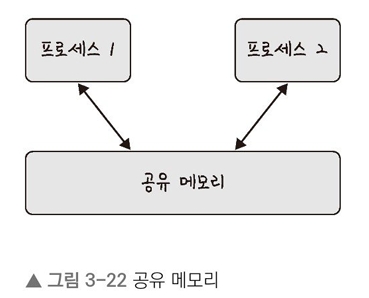
1. 공유 메모리: 여러 프로세스에 동일한 메모리 블록에 대한 접근 권한이 부여되어 프로세스가 서로 통신할 수 있도록 공유 메모리를 생성해서 통신하는 것이다.
2. 파일: 디스크에 저장된 데이터 또는 파일 서버에서 제공한 데이터를 말하는데 이를 기반으로 프로세스 간 통신을 한다.
3. 소켓: 동일한 컴퓨터의 다른 프로세스나 네트워크의 다른 컴퓨터로 네트워크 인터페이스를 통해 전송하는 데이터를 의미하며 TCP와 UDP가 있다.
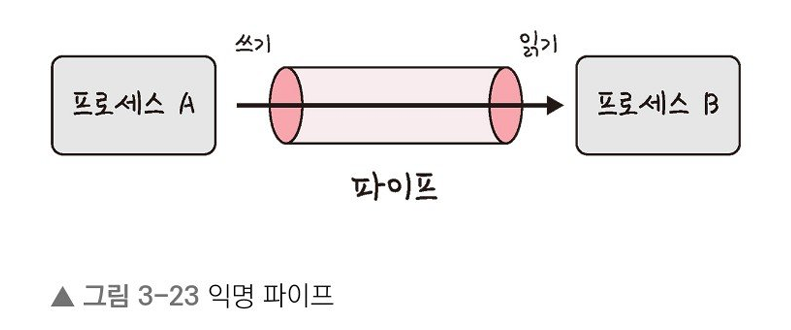
4. 익명 파이프: 프로세스 간에 FIFO 방식으로 읽히는 임시 공간인 파이프를 기반으로 데이터를 주고 받으며, 단방향 방식의 읽기 전용, 쓰기 전용 파이프를 만들어서 작동하는 방식을 말한다. 이는 부모, 자식 프로세스 간에만 사용할 수 있으며 다른 네트워크 상에서는 사용이 불가능하다.
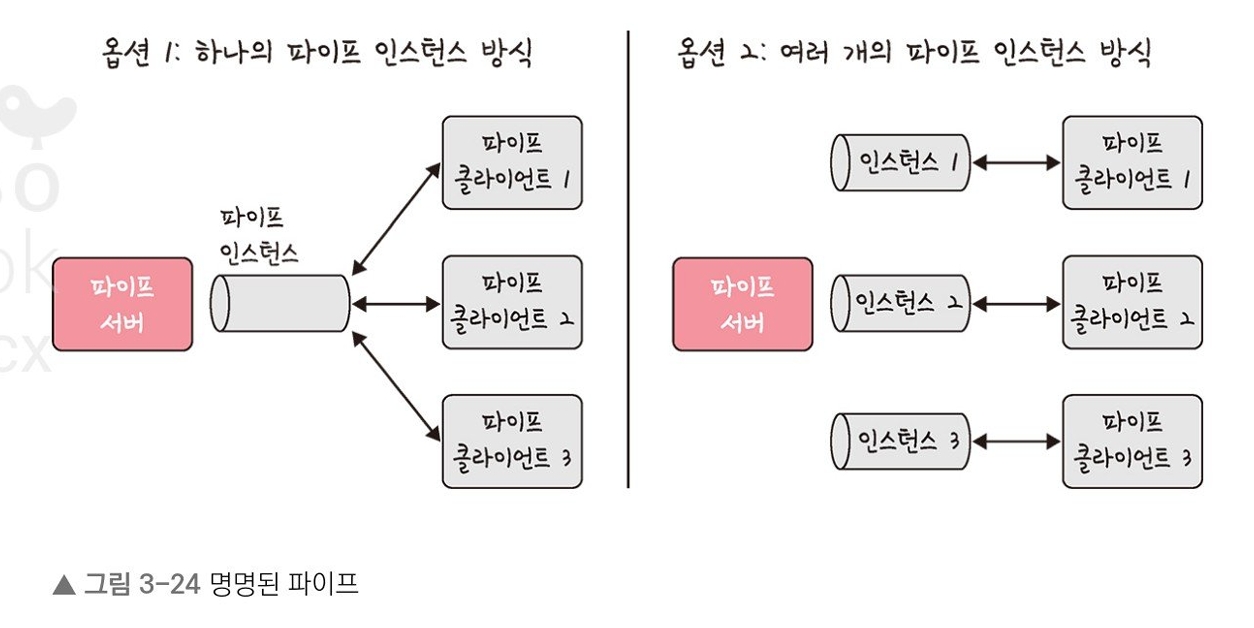
5. 명명 파이프: 파이프 서버와 하나 이상의 파이프 클라이언트 간의 통신을 위한 명명된 단방향 또는 양방향 파이프를 말한다. 클라이언트/서버 통신을 위한 별도의 파이프를 제공하며, 여러 파이프를 동시에 사용할 수 있다. 컴퓨터의 프로세스끼리 또는 다른 네트워크 상의 컴퓨터와도 통신을 할 수 있다.
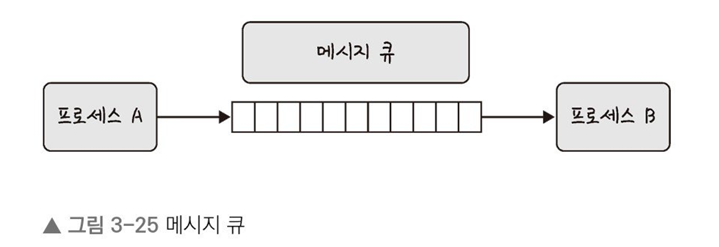
6. 메시지 큐: 메시지를 큐(queue) 데이터 구조 형태로 관리하는 것을 의미한다.
이는 커널의 전역변수 형태 등 커널에서 전역적으로 관리되며 다른 IPC 방식에 비해서 사용 방법이 매우 직관적이고 간단하며 다른 코드의 수정 없이 몇 줄의 코드만 추가시켜 간단하게 메시지 큐에 접근할 수 있다.
3.3.6 스레드와 멀티스레딩
스레드란?
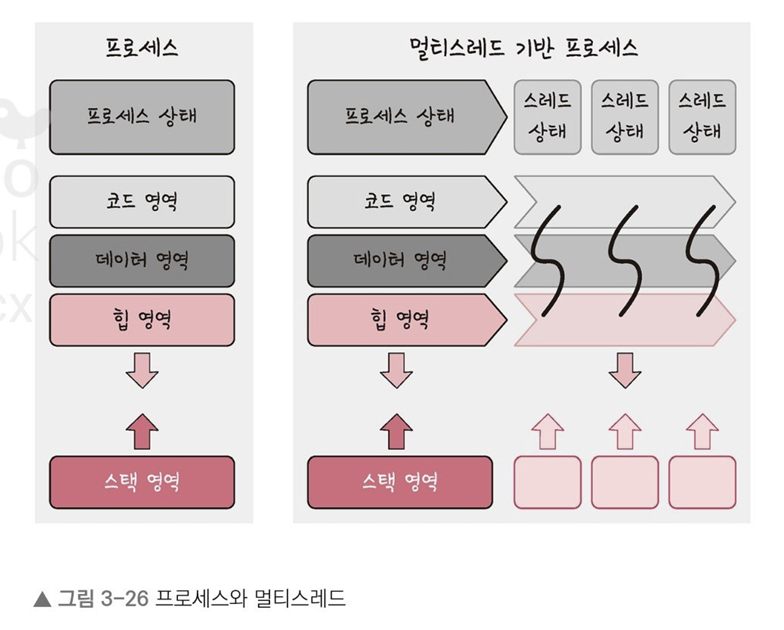
프로세스의 실행 가능한 가장 작은 단위이다.
프로세스는 여러 스레드를 가질 수 있다.
코드, 데이터, 스택, 힙을 각각 생성하는 프로세스와는 달리 스레드는 코드, 데이터, 힙은 스레드끼지 서로 공유한다.
멀티스레딩
멀티스레딩은 프로세스 내 작업을 여러 개의 스레드, 멀티스레드로 처리하는 기법이며 스레드끼리 서로 자원을 공유하기 때문에 효율성이 높다.
또한, 동시성에도 큰 장점이 있다. 하지만 한 스레드에 문제가 생기면 다른 스레드에도 영향을 끼쳐 스레드로 이루어져 있는 프로세스에 영향을 줄 수 있는 단점이 있다.
+) 동시성이란?
서로 독립적인 작업들을 작은 단위로 나누고 동시에 실행되는 것처럼 보여주는 것이다.
3.3.7 공유 자원과 임계 영역
<공유 자원과 경쟁 상태>
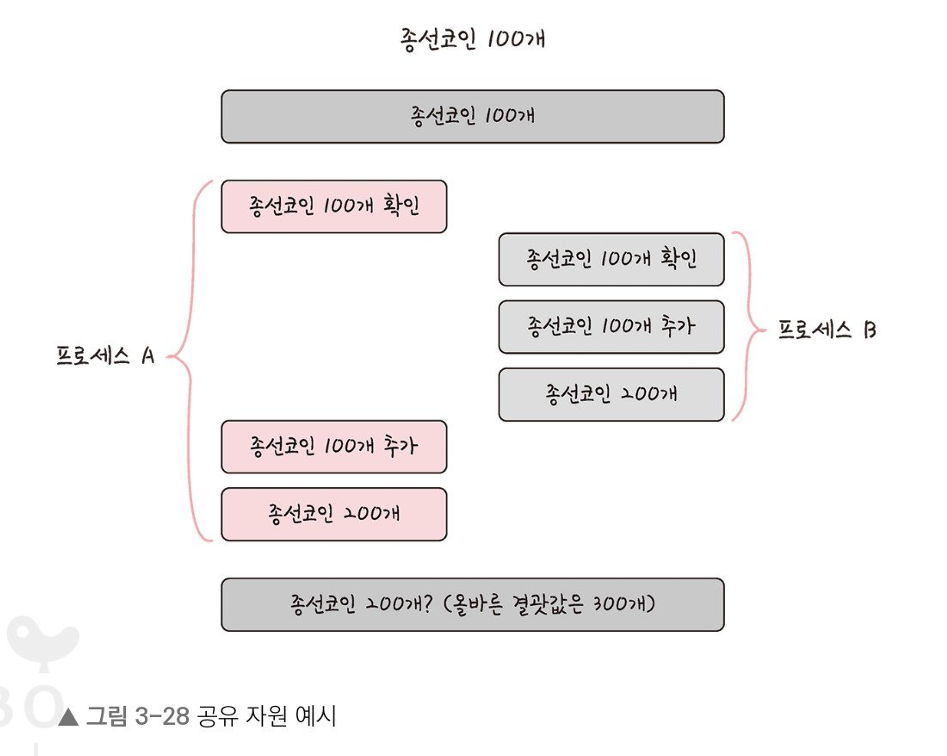
공유 자원(shared resource)은 시스템 안에서 각 프로세스, 스레드가 함께 접근할 수 있는 모니터, 프린터, 메모리, 파일, 데이터 등의 자원이나 변수 등을 의미한다.
이 공유 자원을 두 개 이상의 프로세스가 동시에 읽거나 쓰는 상황을 경쟁 상태(race condition)라고 한다.
프로세스 A와 프로세스 B가 동시에 접근하여 타이밍이 서로 꼬여 정상 결괏값은 300인데 200이 출력된다.
<임계 영역>
임계 영역(critical section)은 둘 이상의 프로세스, 스레드가 공유 자원에 접근할 때 순서 등의 이유로 결과가 달라지는 코드 영역을 말한다.* 임계 영역을 해결하는 방법: 뮤텍스, 세마포어, 모니터
위 방법 모두 상호 배제, 한정 대기, 융통성이란 조건을 만족해야 한다.1) 상호 배제(mutual exclusion): 한 프로세스가 임계 영역에 들어갔을 때 다른 프로세스는 들어갈 수 없다.
2) 한정 대기(bounded waiting): 특정 프로세스가 영원히 임계 영역에 들어가지 못하면 안 된다.
3) 융통성(progress): 만약 어떠한 프로세스도 임계 영역을 사용하지 않는다면 임계 영역 외부의 어떠한 프로세스도 들어갈 수 있으며 이 때 프로세스끼리 서로 방해하지 않는다.이 방법에 토대가 되는 메커니즘: 잠금(lock)
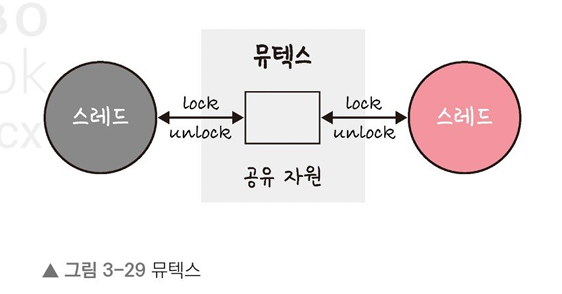
<뮤텍스>
뮤텍스(mutex)는 프로세스나 스레드가 공유 자원을 lock()을 통해 잠금 설정하고 사용한 후에는 unlock()을 통해 잠금 해제하는 객체이다.
<세마포어>
세마포어(semaphore)는 일반화된 뮤텍스이다.
간단한 정수 값과 두 가지 함수 wait(P 함수라고도 함) 및 signal(V 함수라고도 함)로 공유 자원에 대한 접근을 처리한다.
wait()는 자신의 차례가 올 때까지 기다리는 함수이며, signal()은 다음 프로세스로 순서를 넘겨주는 함수이다.
바이너리 세마포어와 카운팅 세마포어가 있다.
<뮤텍스와 세마포어의 차이점>
| 비교 항목 | 뮤텍스 (Mutex) | 세마포어 (Semaphore) |
|---|---|---|
| 동기화 대상 | 하나의 공유 자원 | 여러 개의 공유 자원 |
| 소유권 | 있음 (잠근 스레드만 해제 가능) | 없음 (임의의 스레드가 해제 가능) |
| 값의 범위 | 0 또는 1 (이진) | 0 이상 (N개까지 설정 가능) |
| 한 번에 접근 가능한 스레드 수 | 1개 | N개 (설정 값에 따라 다름) |
<모니터>
모니터는 둘 이상의 스레드나 프로세스가 공유 자원에 안전하게 접근할 수 있도록 공유 자원을 숨기고 해당 접근에 대해 인터페이스만 제공한다.
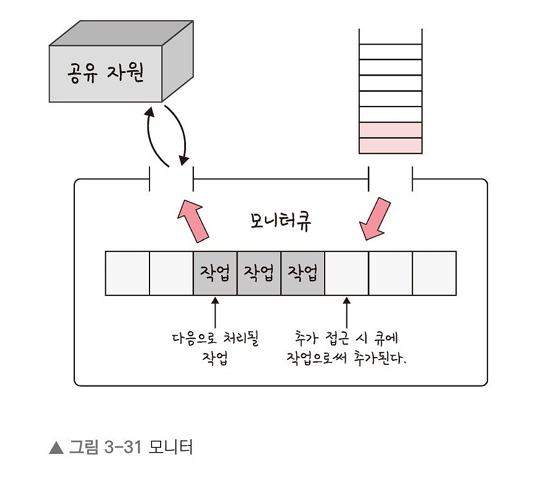
3.3.8 교착 상태
교착상태란?
두 개 이상의 프로세스들이 서로가 가진 자원을 기다리며 중단된 상태를 말한다.
<교착 상태의 원인>
1) 상호 배제: 한 프로세스가 자원을 독점하고 있으며 다른 프로세스들은 접근이 불가능하다.
2) 점유 대기: 특정 프로세스가 점유한 자원을 다른 프로세스가 요청하는 상태이다.
3) 비선점: 다른 프로세스의 자원을 강제적으로 가져올 수 없다.
4) 환형 대기: 프로세스 A는 프로세스 B의 자원을 요구하고, 프로세스 B는 프로세스 A의 자원을 요구하는 등 서로가 서로의 자원을 요구하는 상황을 말한다.
<교착상태 해결방법>
크게 3가지의 해결법이 존재한다.
데드락이 발생하지 않도록 예방(prevention) 하기
데드락 발생 가능성을 인정하면서도 적절하게 회피(avoidance) 하기
데드락 발생을 허용하지만 데드락을 탐지(detection)하여, 데드락에서 회복(Recovery)하기
1) 예방 (Prevention)
교착상태가 발생할 수 있는 요구조건을 만족시키지 않게 함으로써 교착상태를 방지한다.
위에 있는 교착상태 발생의 네가지 조건 중에서 어느 하나를 제거함으로써 수행된다.
자원 낭비가 가장 심한 기법이다.2) 회피 (Avoidance)
교착상태가 발생할 가능성을 배제하지 않고 교착상태가 발생하면 적절히 피해나가는 방법이다.
리소스 할당의 측면에서, 교착상태가 발생할 가능성이 있는 자원 할당(unsafe allocation)을 하지 않는다.
주로 은행원 알고리즘(Banker's Algorithm)이 사용된다.+)은행원 알고리즘
은행원 알고리즘은 다익스트라가 제안한 기법으로, 은행에서 모든 고객의 요구가 충족되도록 현금을 할당하는데서 유래한 기법
각 프로세스에게 자원을 할당하여 교착상태가 발생하지 않으며 모든 프로세스가 완료될 수 있는 상태는 안전상태, 교착상태가 발생할 수 있는 상태는 불안전 상태 라고 한다.
은행원 알고리즘을 적용하기 위해서는 자원의 양과 사용자(프로세스) 수가 일정해야 한다.
은행원 알고리즘은 프로세스의 모든 요구를 유한한 시간안에 할당하는 것을 보장한다.3) 탐지 및 회복 (Detection and Recovery)
교착상태가 발생 할 수 있도록 놔 두고 교착상태가 발생 할 경우 찾아내어 고친다.
3-1) 탐지
시스템에 교착상태가 발생했는지 점검하여 교착상태에 있는 프로세스와 자원을 발견한다.
교착상태 발견 알고리즘과 자원 할당 그래프 등을 사용한다.
자원 할당 그래프의 단점 : 자원을 요청할 때마다 탐지 알고리즘을 실행하면, 오버헤드가 발생한다.3-2) 회복
교착상태를 발견했다면 회복기법을 진행한다.
교착상태를 일으킨 프로세스를 종료하거나 교착상태의 프로세스에 할당된 자원을 선점하여 프로세스나 자원을 회복한다.
