Intro
컴퓨터 언어는 0과 1로 이루어진 2진법 수만 취급한다.
이는 사람들이 이해하기 어렵기에 프로그래밍 언어가 진화하였고,
그렇게 만들어진 고수준의 언어들이 C, C++, JAVA와 같이 발전 하였다.
하지만 프로그래밍 언어가 고수준으로 발전하더라고 컴퓨터는 계속해서 0과 1의 언어를 원한다.
그렇기에 사람의 언어와 컴퓨터 언어를 서로 이해하게 해주는 일종의 파파고 번역기들이
(어셈블러, 컴파일러, 프리프로세서, 인터프리터 등) 등장하게 되었다.
그 중 고수준의 언어 번역기가 바로 컴파일러다.
컴파일러를 바로 이해하기에는 나는 아직 너무 🐣 이기에.
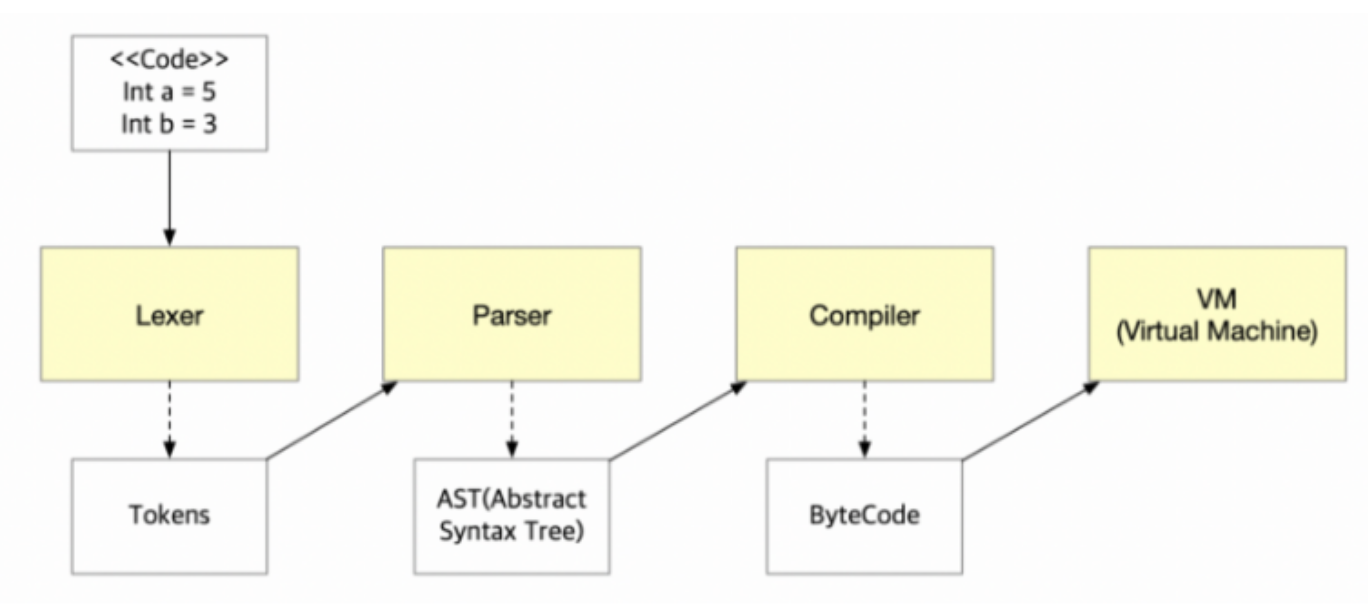
컴파일러 이론 중 문자열 분석 (tokenizer, lexer, parser)의 역할을 알고
간단하게 만들어보면서 이해해보려고 한다.
✍️ 학습으로 구현하고자 하는 내용
- 코드를 의미있는 조각으로 나누는 토크나이징/렉싱
- 코드를 트리구조로 나타내는 AST로 만드는 파싱
🌱 학습 키워드
XML
Extensible Markup Language(XML)
공유 가능한 방식으로 데이터를 정의하고 저장하여 컴퓨터 시스템 간의 정보 교환을 지원한다.
규칙을 사용하여 데이터를 효율적으로 정확하게 읽을 수 있으므로 모든 네트워크에서 데이터를 XML 파일로 손쉽게 전송할 수 있다.
태그 등을 이용하여 데이터의 구조를 기술하는 마크업 언어다.
가장 대표적인 마크업 언어로 HTML이 있다.
well-formed
XML의 기본 문법을 만족하는 수준으로 되어있는 문서.
모든 구문을 허용하기 때문에 XML처럼 보이기는 하지만 실제로 데이터 교환수단으로 바로 쓰기는 어렵다.
유효(Valid) XML문서
XML 문서의 형식을 만족하도록 작성된 XML 문서.
Ajax
Ajax(Asynchronous JavaScript and XML)란 자바스크립트를 사용하여
① 브라우저가 ② 서버에게 비동기 방식으로 데이터를 요청하고,
서버가 응답한 데이터를 수신하여 웹페이지를 동적으로 갱신하는 프로그래밍 방식 을 말한다.
JSON
JSON은 JavaScript Object Notation의 약자다.
JSON은 클라이언트와 서버 간의 HTTP 통신을 위한 텍스트 데이터 포맷이다.
서버에서 클라이언트로 데이터를 보낼 때 사용하는 양식으로 클라이언트가 사용하는 언어에 관계 없이 통일된 데이터를 주고 받을 수 있다.
자바스크립트에 종속되지 않는 언어 독립형 데이터 포맷으로, 대부분의 프로그래밍 언어에서 사용할 수 있다.
JSON의 프로토타입 메서드
-
JSON.stringify()
JSON.stringify 메서드는 ① 객체를 ② JSON 포맷의 문자열로 변환한다.
클라이언트가 서버로 객체를 전송하려면 객체를 문자열화해야 하는데 이를 직렬화(serializing)라 한다. -
JSON.parse()
JSON.parse 메서드는 ① JSON 포맷의 문자열을 ② 객체로 변환한다.
서버로부터 클라이언트에게 전송된 JSON 데이터는 문자열이다.
이 문자열을 객체로 사용하려면 JSON 포맷의 문자열을 객체화해야 하는데 이를 역직렬화(deserializing)라 한다.
토큰
문법적 의미를 갖는 코드의 최소 단위
정규표현식
정규 언어를 수학적으로 기술하는 방식
문자열에서 특정 문자 조합을 찾기 위한 패턴
Stack
스텍은 제한적으로 접근할 수 있는 나열 구조다.
스텍은 선형구조다. (Last In First Out : LIFO)
DOM
DOM은 HTML 문서의 계층적 주고와 정보를 표현하며 이를 제어할 수 있는 API, 즉 프로퍼티와 메서드를 제공하는 트리 자료구조다.
- HTML 문서는 HTML 요소들의 집합으로 이루어지며 HTML 요소는 중첩 관계를 갖는다
- 이떄 HTML 요소 간에는 중첩 관계에 의해 부자(부모자식)관계가 형성된다
- 이러한 HTML 요소 간의 부자 관계를 반영하여 모든 노드들을 트리 자료구조로 구성한다.
- 이 노드들로 구성된 트리 자료구조를 DOM이라 부른다.
직렬화
자바스크립트 엔진은 위에서부터 아래로 차례대로 (직렬적으로) 코드를 실행한다.
Tokenizer
주어진 문장을 토큰 이라 불리는 단위로 나누는 과정.
토큰의 단위는 상황에 따라 다르며 기본적으로 단어, 문자, 서브워드 등 세가지 방법이 존재한다.
-
단어 단위 토큰화
단어(공백) 단위로 토큰화 -
문자 단위 토큰화
문자 단위로 토큰화 (Apple -> A,p,p,l,e) -
서브워드 단위 토큰화
단어와 문자 단위 토큰화의 중간 형태
Parser
문장을 그것을 이루고 있는 구성 성분으로 분해하고 그들 사이의 위계 관계를 분적하여 문장의 구조를 결정하는 것을 말한다.
CS에서는 일련의 문자열을 의미있는 토큰으로 분해하고 이들로 이루어진 "파스 트리"를 만드는 과정을 말한다.
정형화 데이터
데이터는 형태에 따라 정형 데이터, 반정형 데이터, 비정형 데이터가 있다.
이를 구분하는 기준으로 스키마 형태의 유무, 즉 형태가 있느냐 없느냐가 분류기준이다.
여기서 형태가 있고 연산가능하면 정형 데이터라 한다.
HTML5
최신 웹 표준 버전
웹 표준이란 웹 상에서 표준적으로 사용되는 기술을 말한다.
표준은 W3C(World Wide Web Consortium)기구 표준을 말한다.
XML Parser
XML 문저의 평문 데이터를 읽어 그것을 XML DOM 객체로 변환하는것을 말한다.
DOM Parser
Document Object Model(문서 객체 모델)의 약자로 HTML과 XML문서를 위한 API로서
문서의 물리적 구조와 문서가 접근되고 다루어지는 방법을 정의한다.
DOM은 XML문서를 하나의 Tree구조로 본다. 이에 Element의 위치에 따라 상/하위 개념 및 형제 개념을 가지고 있다.
즉, DOM parser를 사용하여 XML 문서에 있는 것을 객체화 시켜 JavaScript에서 사용할 수 있는 등 문서의 내용을 동적으로 조회, 갱신, 생성 및 삭제 할 수 있게 해준다.
lexer(렉서)
Lexer는 lexical analysis(어휘 분석)을 뜻한다.
텍스트를 받아서 한 글자 한 글자 읽어나가다가 의미를 가진 단어를 만나면 Lexer에서는 그 단어를 전체 텍스트로부터 잘라서 Token이란 것으로 만든다.
HTML 파싱
바이트 > 문자 > 토큰 > 노드 > DOM
- 서버에 존재하던 HTML 파일이 브라우저의 요청에 의해 응답된다
- 이때 서버는 브라우저가 요청한 HTML 파일을 읽어 들여 메모리에 저장한 다음 메모리에 저장된 바이트(2진수)를 인터넷을 경유하여 응답한다
- 브라우저는 서버가 응답한 HTML 문서를 바이트(2진수) 형태로 응답받는다
- 따라서 응답된 바이트 형태의 HTML 문서를 meta 태그의 charset 어트리뷰트에 의해 지정된 인코딩 방식을 기준으로 문자열로 변환한다
- 문자열로 변환된 HTML 문서를 읽어 들여 문법적 의미를 갖는 코드의 최소 단위인 토큰(token)들로 분해한다.
- 각 토큰들을 객체로 변환하여 노드들을 생성한다 토큰의 내용에 따라 ⑴ 문서 노드 ⑵ 요소 노드 ⑶ 어트리뷰트 노드 ⑷ 텍스트 노드가 생성된다.
소스코드 컴파일러 방법?
프로퍼티 리스트
프로퍼티 리스트(property list)는 OS X, iOS, NeXTSTEP, GNUstep 프로그래밍 소프트웨어 프레임워크 등에 이용되는 객체 직렬화를 위한 파일이다.
또한 .plist라는 확장자를 가지므로, 보통 plist 파일이라고 하는 경우가 많다.
AST
추상적 구문 트리
프로그래밍 언어로 쓰여진 소스코드의 abstract syntactic 구조를 표현하기 위해서 사용된다.
쉽게 말하자면 특정 프로그래밍 언어로 작성된 프로그램 소스 코드를 각각 의미별로 분리하여 컴퓨터가 이해할 수 있는 구조로 변경시킨 트리를 의미한다.
오토마타
오토마타 이론(Automata theory)은 현재 Computing에 있어서 Algorithms들에 대한 이론적인 부분이라고 알려져 있다.
사실 오토마타는 컴퓨터가 발전하고 나온 컴퓨터 알고리즘 이론이라기보다는 기존부터 있던 알고리즘 이론이다.
알고리즘이라는 것 자체가 기원전 2500년때 부터 이미 사용되어오고 있다는 점에서 오토마타 이론은 오래전부터 있었지만 컴퓨팅 알고리즘에 활용되고 발전해왔다고 볼 수 있다.
오토마타 이론이 컴퓨팅 알고리즘에 활용되는 큰 이유 중 하나는 추상적인 요소를 계산적인 요소로 바꿔서 이해하고 계산하기 위해서는 알고리즘이 필요하다.
오토마타 이론은 이러한 추상적인 문제를 계산할 수 있는 상태로 만들어 알고리즘화를 할 수 있다는 점에서 컴퓨팅 과정에서 적용하여 사용하게 되었다.
📑 참고자료
정규표현식 개념 + 메서드
tokenizer, laxer, parser 예시
lexer 예시
정규식 예시
정규식 예시
대표적인 정규식
📝 구현하기
Tokenizer 구현
- 문제를 간소화하여 예제
<html<span>codesquad</span></html>를 기준으로 구현한다. - 빌트인으로 토큰화 시키는 기준을 정한다.
- 정규식으로 기준에 해당하는 토큰을 추출하여 배열에 추가한다.
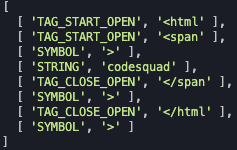
doTokenizer(xml) {
let string = xml;
const tokenArray = [];
const builtIn = [
["TAG_START_OPEN", "^<[a-zA-Z0-9]+"],
["TAG_CLOSE_OPEN", "^</[a-zA-Z0-9]+"],
["STRING", "^[a-zA-Z0-9]+"],
["SPACE", "^\\s+"],
["SYMBOL", "^\\S"],
];
while (string) {
for (let i = 0; i < builtIn.length; i++) {
let token = string.match(new RegExp(`${builtIn[i][1]}`, "g"));
if (token) {
tokenArray.push([builtIn[i][0], token[0]]);
string = string.substring(token[0].length);
break;
}
}
}
return tokenArray;
}Tokenizer 출력
Lexer 구현하기
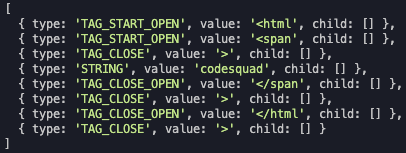
- Tokenizer에서 토큰화된 토큰들에 의미를 부여한다.
- "<"로 시작되면 테그의 시작 타입과 테그 이름 벨류를 가진다.
- ">"는 테그 닫음 타입을 가진다.
- "</"로 시작되면 테그의 종료 타입과 해당 테그 벨류를 가진다.
- 단순 문자열은 SRTING 타입을 가지며 문자열 벨류를 가진다.
- 모든 토큰에게 자식[]을 부여한다.
doLexer(tokens) {
const tokenArray = tokens;
const lexerArray = [];
for (let i = 0; i < tokenArray.length; i++) {
const lexerObject = {};
if (tokenArray[i][1] === ">") {
tokenArray[i][0] = "TAG_CLOSE";
}
lexerObject.type = tokenArray[i][0];
lexerObject.value = tokenArray[i][1];
lexerObject.child = new Array();
lexerArray.push(lexerObject);
}
return lexerArray;
}Lexer 출력
Parser 구현하기
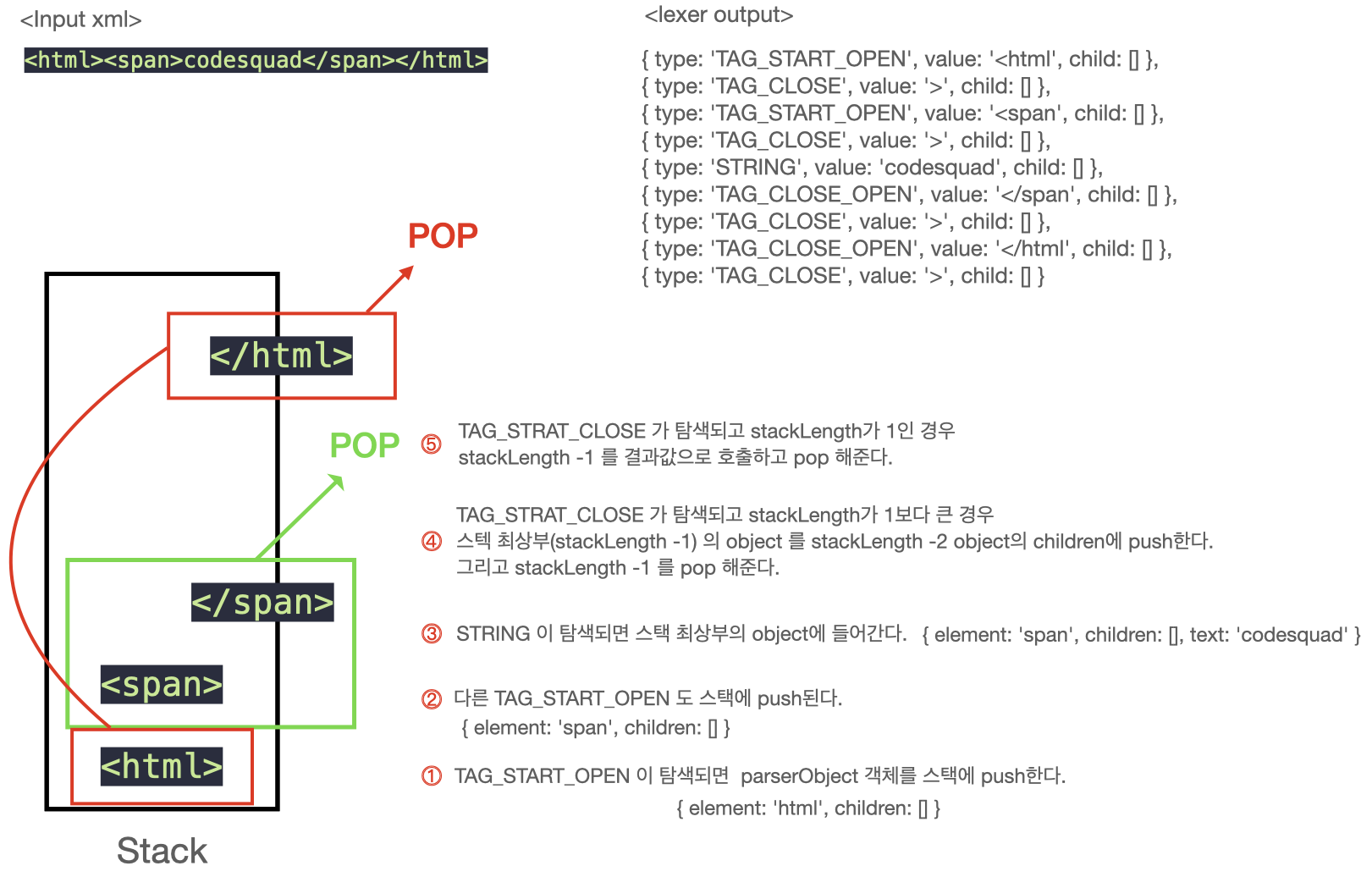
- lexer에서 분석된 토큰들을 탐색한다.
- lexer에서 받은 의미부여 토큰들을 탐색하여 TAG_START_OPEN이 있으면 stack에 푸쉬한다.
- 다음 탐색에서 tag close(>)가 없다면 오류를 호출한다.
- 스택에 있는 테그의 TAG_CLOSE_OPEN가 탐색 되기 전의 TAG_START_OPEN 토큰은 계속해서 스택에 푸쉬한다.
- STRING가 탐색되면 가장 위 stack의 객체에 부여한다.
- TAG_CLOSE_OPEN이 탐색되면 stack.length와 스택 최상위 객체의 value값이 일치하는지 확인한다.
- 일치한다면 stack 최상위(stackLength - 1) 객체를 stackLength -2 객체의 children에 push한다.
- (stackLength -1) 을 pop한다.
- 반복하며 TAG_CLOSE_OPEN가 stact[0]과 일치하면 stack[0] 객체를 결과 값으로 호출하고 pop해준다.
- 최종적으로 stack에 남은 객체가 있다면 오류를 호출한다.
doParser(lexeredTokens) {
const parserArray = [];
const stack = [];
let checkTagOk = 0; // Parser 이후 닫히지 않은 테그가 있으면 (0이 아니면) 오류
let stackPointer = -1; // Parser 이후 stack이 남아있다면 (-1이 아니면) 오류
// 렉서에서 의미를 부여받은 토큰들을 탐색한다.
for (let i = 0; i < lexeredTokens.length; i++) {
const type = lexeredTokens[i].type;
const value = lexeredTokens[i].value;
const child = lexeredTokens[i].child;
const stackLength = stack.length;
// 토큰 탐색으로 만들어지는 객체(스텍에 추가)
function makeParserObject() {
const parserObject = {};
const getElement = value.match(new RegExp(/[^<][a-zA-Z0-9]*/), "g");
parserObject.element = getElement[0];
parserObject.children = child;
return parserObject;
}
// "TAG_START_OPEN"의 경우
if (type === "TAG_START_OPEN") {
if (stackLength === 0) {
stack.push(makeParserObject());
checkTagOk++;
stackPointer++;
} else if (stackLength >= 1) {
stack.push(makeParserObject());
checkTagOk++;
stackPointer++;
}
}
// "TAG_CLOSE_OPEN"의 경우 && 마지막 테그가 아닌 경우
if (type === "TAG_CLOSE_OPEN" && stackLength > 1) {
checkTagOk++;
if (
stack[stackLength - 1].element ===
value.match(new RegExp(/[a-zA-Z0-9]+/))[0]
) {
stack[stackLength - 2].children.push(stack[stackLength - 1]);
stack.pop();
stackPointer--;
} else {
console.log("올바른 형식이 아닙니다.");
return;
}
}
// "TAG_CLOSE_OPEN"의 경우 && 마지막 테그인 경우
if (type === "TAG_CLOSE_OPEN" && stackLength === 1) {
checkTagOk++;
if (
stack[stackLength - 1].element ===
value.match(new RegExp(/[a-zA-Z0-9]+/))[0]
) {
parserArray.push(stack[0]);
stack.pop();
stackPointer--;
} else {
console.log("올바른 형식이 아닙니다.");
return;
}
}
// "TAG_CLOSE"의 경우
if (type === "TAG_CLOSE") {
checkTagOk--;
}
// "STRING"의 경우
if (type === "STRING") {
const getText = value;
stack[stackLength - 1].text = getText;
}
}
// 모든 테그가 잘 닫혔는지 && close 테그가 존재하는지 검증
if (checkTagOk !== 0 || stackPointer !== -1) {
console.log("올바른 형식이 아닙니다.");
return;
}
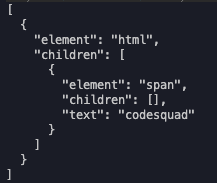
return parserArray;
}Parse 출력
Outro
간단한 예제로 문제를 푸는데도 조건들이 까다롭게 느껴졌고 Parser의 중첩에서 많이 어려웠다.
쉬운 이론으로 생각했던 stack의 파워풀(?)함에도 놀라게 되었다.
JS에서 Html의 tag들에 접근하는 원리에 대해서도 조금은 이해 할 수 있었다.
const divTag = document.querySelector("div");
🛠️ 보완점
- 속성, 닫힘 없는 테그 등 더욱 다양한 예제에서 구동이 가능하도록 해보자.
- elementByAttribute 기능을 구현해보자.
- elementByTag 기능을 구현해보자.
