앞서 공부한 프로세스 스케줄링에서 "스레드"에 대해 더 자세히 정리하고 이해해보자.
🧐 스레드드 왜 생겼는가?
스레드는 경량화한 프로세스라고 이해 했는데, 어째서 경량화한 프로세스가 필요했을까?
같은 작업을 동시에 할 수 있도록 같은 프로세스를 두개 만들어서 작업하는 것을 멀티 프로세스라 한다.
이 때, 각각의 프로세스들은 독립된 메모리 공간을 차지하기에 서로간의 정보 공유가 불가하다.
이는 컨텍스트 스위칭의 부담을 준다.
컨텍스트 스위칭(Context Switching)
현재 실행중인 프로세스A를 내리고 프로세스B를 실행한다고 하면, 문맥 교환(Context Switch)를 통해 프로세스A의 작업을 저장하고 저장된 프로세스B의 작업을 백업한다. 이 과정들을 컨테스트 스위칭이라한다.
프로그램의 실행을 위해서는 해당 프로세스의 정보가 메인 메모리에 올라와야 한다.
이때 서로의 정보를 공유하지 않는 프로세스들의 컨텍스트 스위칭에는 프로세스의 전체 데이터가 내려갔다가 올라오기를 반복하기에 공간과 시간에 부담을 준다.
그래서 생긴게 스레드다.
스레드는 멀티프로세스의 특징을 유지하면서 단점을 극복하기 위해 등장하게 되었다.
🔎 스레드의 구조
스레드가 생긴 이유를 멀티프로세스의 단점(컨텍스트 스위칭의 부담)을 극복하기 위해서라고 이해했다면, 어떻게 단점을 극복하게 되었는지 구조를 통해 이해 할 수 있다.
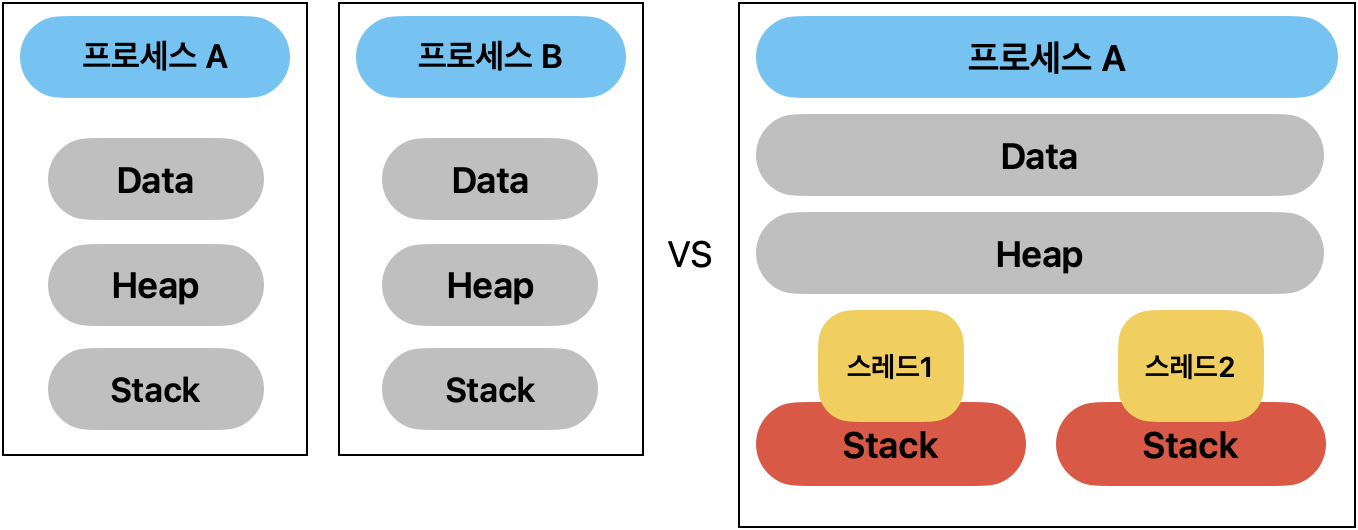
동일한 작업을 단일 스레드 두개의 프로세스가 작업하는 경우와 (단일 스레드 멀티 프로세스)
멀티 스레드 프로세스 하나가 작업하는 경우의 구조는 아래와 같다. (멀티 스레드 싱글 프로세스)
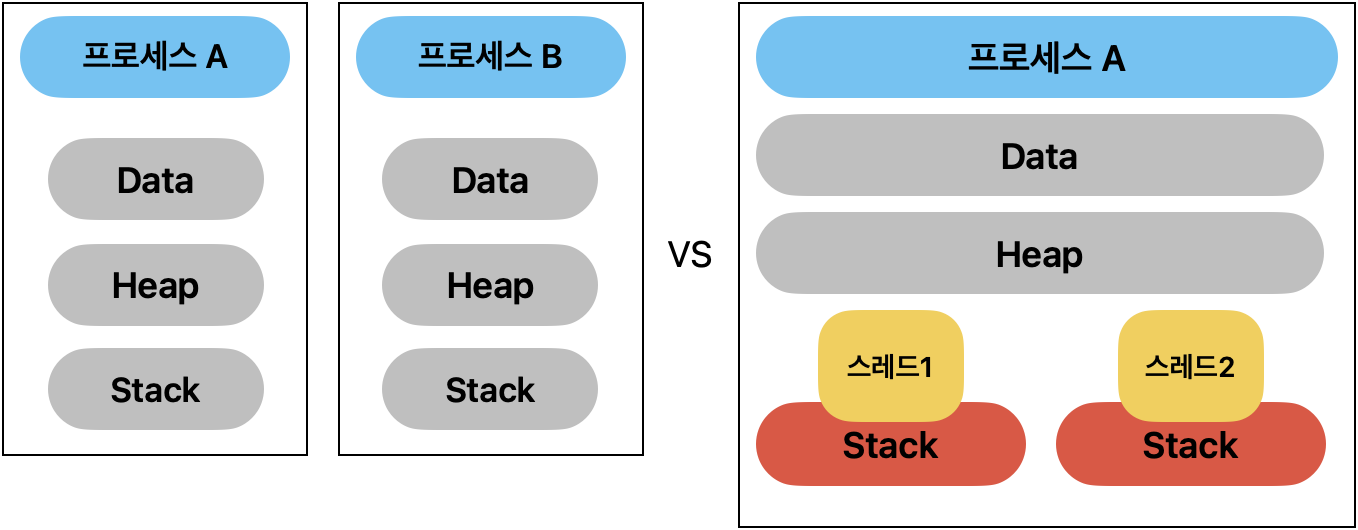
각 프로세스들은 간단하게 Data, Heap, Stat 영역을 가지고 있다.
| 영역 | 내용 |
|---|---|
| Data | 전역 변수 할당 |
| Heap | malloc, new등 동적 할당 |
| Stack | 함수의 실행에 사용 |
그럼 같은 작업을 동시에 실행함(실행흐름)을 갖는 것이 멀티 프로세스의 목적이라면
굳이 Data와 Heap가지 복사를 해서 따로 가지고 있어야한 할까?
실행흐름에 필요한 Stack만을 분리하고 Data와 Heap은 같은 메모리를 공유하여
동일 작업을 동시에 실행 할 수 있도록 해주기 위한 스레드의 구조이다.
스레드를 통해 컨텍스트 스위칭 시 Data와 Heap영역의 올리고 내림이 필요 없어졌으며,
Data와 Heap을 공유하기에 서로의 데이터를 공유, 교환도 가능하게 된다.
구조를 통해 프로세스와 스레드를 다음과 같이 정의 할 수 있다.
프로세스 : 운영체제 관점에서 별도의 실행흐름을 구성하는 단위
스레드 : 프로세스 관점에서 별도의 실행흐름을 구성하는 단위
👍 스레드의 장점
-
응답성(Responsiveness) 향상
: 다중 스레드로 구성된 프로레스 구조에서는 하나의 서버 스레드가 blocked(waiting)상태인 동안에도 동일한 프로세스 내의 다른 스레드가 실행(running)되어 빠른 처리를 할 수 있다.
(ex. 웹페이지에서 하나의 스레드는 HTML을 분석하고 다른 스레드는 웹피이지에 정보를 요청하고 또 다른 쓰레드는 다른 받은 정보를 띄운다.) -
자원공유(Resource Sharing)
: 동일한 일을 수행하는 다중 스레드가 자원을 공유하여 협력하기에 높은 처리율과 성능 향상을 얻을 수 있다. -
경제성(Economy)
: 여러 프로세스를 만드는 것보다 여러 스레드를 만드는 것이 오버헤드가 적다.
또 한, 문맥교환시의 오버헤드 또한 경제적이다. -
CPU가 여러개인 경우(Utilization of MP Architectures)
: 각각의 스레드가 각각의 CPU에서 병렬적으로 작업이 가능하다.
