
🎯 학습목표
git을 무작정 사용하지말고 내부구조와 동작원리를 이해하고 사용하도록 해보자.
🧐 생활코딩 지옥에서 온 Git 강의 내용을 학습을 위해 정리하고 실습한 내용입니다.
🗂️ 버전관리란?
사무일을 생각해보자. 엑셀로 자료를 정리했을때, xls_rev0, rev1....final...final2 처럼 저장한 경험이 있을거다.
내가 자료를 만든 시점와 내용을 구분해서 저장하기 위해 우리는 버전관리를 경험해왔고 사용해왔다.
만약 앞서 파일의 버전을 관리해왔을때, rev0, rev2와 같이 이름을 바꿀 필요가 없다면?
이름은 동일한데 내가 원하는 시점의 내용을 관리가 가능하다면??
거기에 파일을 백업하고 복원마저 가능하다면???
버전 관리에 굉장한 도움을 줄것이다.
이것을 가능하게 해주는 프로그램을 VCS(Version Control Ststem)라 하며,
이중 가장 많이 사용되고 있는 것이 GIT 이다.
⚙️ git의 원리
첫번째 알고가기 ⭐️ (핵심)
파일의 이름은 index에 있고
파일의 내용은 object에 존재한다.
git은 파일을 저장할때 이름이 달라도 내용이 같다면 같은 객체(log ID)를 가르킨다.
누가 저장을 하건 어떤 이름으로 저장을 하건 내용이 같아면 같은 객체(log ID)를 가르킨다.

내용이 같다면 어떻게 동일한 객체를 가르킬까?
Git은 파일의 내용을 sha-1 이라는 hash를 이용해서 id값을 얻어낸다.
내용을 기반으로 객체(id)값을 얻어내기에 내용이 같다면 같은 id값을 가지게 되는 원리다.
commit도 객체의 내용으로 들어간다.
우리가 commit을 하면 commit 객체가 저장되며 commit 객체는 tree라는 객체를 가지게 된다.
이 tree에는 커밋 시점의 파일들의 객체(id)들이 들어가 있다.
새로운 commit을 하게 된다면 새로운 commit 객체가 만들어지고
새로운 commit객체에는 새로운 commit시점의 파일들의 객체(id)들이 들어가있다.
그리고 새로운 commit에는 부모 commit객체 id정보가 들어가 있는데,
부모 commit객체의 id를 확인하면 이전에 commit한 객체로 들어가진다. (이전 시점의 파일들의 객체를 볼 수 있다.)
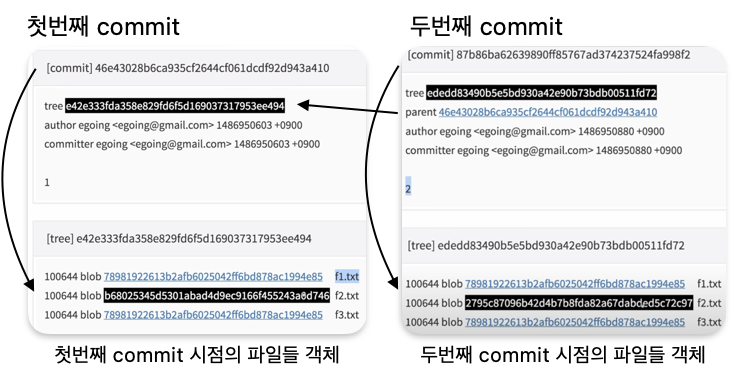
commit객체에 포함된 중요 정보
- 이전 부모가 누구인가
- commit 시점의 파일들이 담긴 tree (스냅샷)
git에 존재하는 객체는 아래 3가지 중 하나가 된다.
(git의 객체는 아래 3가지 중 하나의 형태로 존재한다.)
- blob : 특정 파일 객체를 가진다.
- tree : 커밋객체에 들어가는 객체로 커밋 순간의 파일들의 객체들을 가진다.
- commit : 커밋 메시지, tree, 부모 커밋 참조를 가진다.
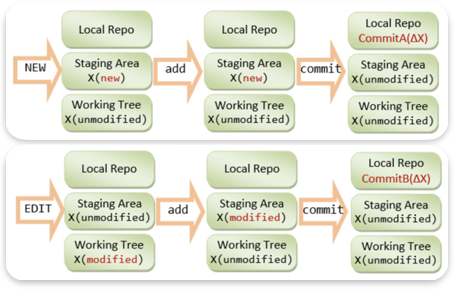
git status (git은 커밋해야하는 파일이 있는지 어떻게 알까?)
관리하고 싶은 파일들은 add 명령어로 스테이지에 올려진다.
스테이지에 올라가면 해당 파일의 object(blob)가 생성되고 스테이지에 올라간 파일들을
commit을 하면 commit 순간을 스냅샷한 객체가 만들어 지고 파일들은 tree로서 존재한다.
(스테이지에 있는 blob들이 커밋 순간의 tree가 된다.)
작업 중인 파일을 work space
스테이지에 올라간 장소를 index
commit된것을 repository 라고 부르는데
워크스페이스에서 파일을 수정하면 수정전에 인덱스에 저장된 내용(이전 tree)와 달라진다.
내용을 id로 가지는 깃 객체는 내용이 변경됨을 알 수 있게 된다. (내용이 바뀌면 id가 일치하지 않는다.)
변경된 내용을 add 후의 인덱스(tree)는 워크스페이스와는 동일해지지만,
add 전의 tree 객체(id)를 가지고 있는 repository는 tree와 다름을 감지한다.
변경된 내용의 파일을 add하고 commit까지 하면 해당 내용(id)는 모두 같아진다.
이처럼 git은 파일의 내용을 id값으로 가지는 객체를 생성함으로써
각 단계에서 내용의 변경을 감지하고 add가 필요한 파일, commit이 필요한 파일을 사용자에게 알려준다.
🔥 git 따라하기 (add~commit)
현재 디렉토리에 내가 새로운 작업을 하겠다는 것을 git에게 알려준다.
(이 프로젝트 버전관리를 시작할게)
git init
.git 이라는 디렉토리가 생긴다.
이 디렉토리는 버전 관리를 하게 되면 여러가지 정보들이 생성되는데 이 정보들이 .git에 저장된다. (버전 정보들)
특정 파일을 git에게 관리해달라고 요청한다.
관리하고자 하는 파일을 명확 하게 관리하기 위해 만들어진 기능이다.
(관리가 필요한 파일만 정리할수 있으니깐.)
git add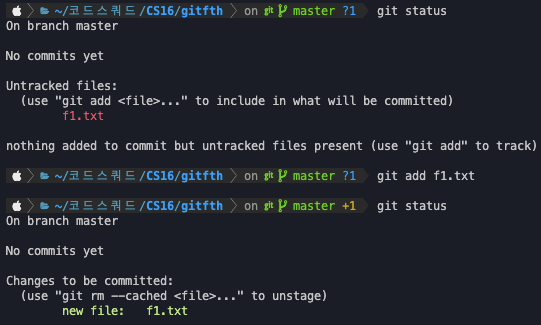
지금 만드는 버전이 누가 만들었는지 알려주기 위해 사용자를 등록한다.
(최초 한번만 작성하면 된다.)
git config --global user.name sarang_daddy
git config --global user.email sarang_daddy@naver.com관리하고자 하는 버전의 내용을 기재하고 커밋한다.
관리(기록)하고자 하는 파일의 내용을 관리 시스템에 기록한다고 이해하자.
git commit
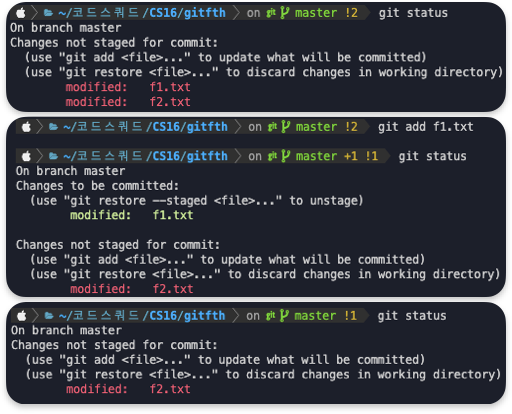
관리하는 파일 (f1.txt)가 수정되어 버전을 업데이트 한다면 add를 다시 하고 commit한다.
왜 커밋 전에 add라는 기능이 있을까? 커밋은 하나의 파일(하나의 내용)만을 포함하는게 가장 이상적이다.
하지만 프로그래밍을 하다보면 여러 작업을 진행 후에 커밋하는 경우가 발생하는데,
add는 커밋 전에 내가 커밋하고자 하는 파일만을 선택 할 수 있게 해준다.
add는 stage area에 보내는 기능이다.
f1.txt
f2.txt
수정된 두 파일 중 f1.txt 만 add하고 커밋하면 f1.txt는 버전관리에 등록되고
f2.txt는 "changes not staged for commit" 상태 그대로 유지된다.
즉, 스테이지에 추가된 수정된 파일들만이 (add를 한 파일) 커밋된다.
- add된 파일은 stage로 보내진다.
- commit된 파일은 tree가 되어 repository로 보내진다.
버전관리된 파일들 살펴보기
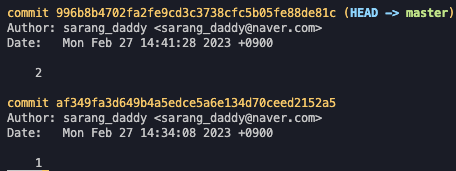
git log // 커밋된 내용들을 확인한다.
git log -p // 전체 버전들의 차이점을 확인한다. (변경 내용, 추가 파일 등)
git log diff <id>..<id> // 비교하고자 하는 log ID 두개의 차이점을 확인한다.
git diff // 현재 add 되지 않은 파일의 수정내용을 확인한다.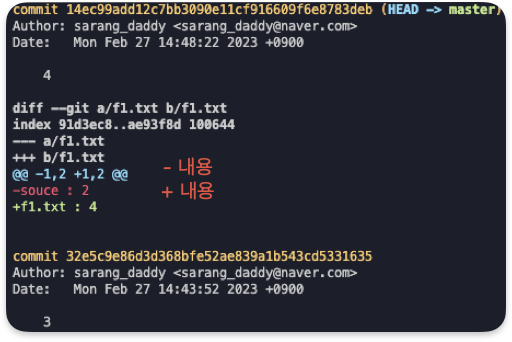
과거로 돌아가기 (커밋취소)
reset VS revert
1. reset
git reset <돌아가고 싶은 log ID>
git 32e5c9e86d3d368bfe52ae839a1b543cd5331635 --hard
* <돌아가고 싶은 log ID> 당시의 파일 상태로 돌아온다.
* <돌아가고 싶은 log ID> 위의 버전들은 git log에서 더이상 확인이 안된다.
* 다만, 실제로 삭제된 것은 아니다.
* 로컬 상태에서만 사용해야한다. (공유 후에는 절대 사용을 금한다.)
2. revert
git revert <취소하고 싶은 log ID>
* reset과의 다른점은 revert시 <취소하고 싶은 log ID>를 취소하고 새로운 버전을 생성한다.편의 기능들
git commit --help를 통해 다양한 기능을 확인 할 수 있다.
매번 add 후 커밋을 하는 작업이 번거로울 수 있다.
git commit -a // add를 생략하고 커밋 작업까지 완료
add를 생략하고 메시지 에디터도 생략하고 싶다.
git commit -am "commit 메세지"commit 메시지 수정하기 (⭐️ 원격 저장소로 push 후에는 사용하면 안된다)
git commit --amend🎬 git - branch 란?
다시 사무일을 생각해보자
엑셀로 보고서를 작성하여 제출해야되는데 A담당자의 내용과 B담당자의 내용이 함께 작성이 되어야 한다.
xls.rev0 이라는 보고서에 xls.A.rev0 , xls.B.rev0 라는 동일 파일을 2개로 만들고
각 담당자가 내용을 채운 xls.A.rev3, xls.B.rev2을 합쳐 xls.final로 최종 제출 된다.
프로그래밍 과정에서 위와 같은 과정은 반드시 존재하고 담당자는 몇명의 수준이 아닐 것이다.
다양한 기능들이 수시로 추가되고 수정되는 협업 과정에서 위와 같은 방식으로의 버전 관리는 굉장히 어렵다.
Git에서는 branch라는 기능으로 위와 같은 과정을 간편하고 유용하게 할 수 있게 해준다.
git - branch 만들기
연습을 위해 기존 내용은 지우고 새로운 gitfth폴더를 만들고
f1.txt를 생성하고 한번 수정을 거쳐 commit한 상태에서 시작하자.
여기서 새로운 기능을 개발해야 한다.
기존의 파일을 더럽히지 않고 기존의 파일 위에 새로운 기능을 추가해야하는 경우 branch를 사용한다.
현재 사용중인 branch 확인
git branch새로운 브렌치 생성
git branch "브랜치 이름"새로운 브렌치 사용
git checkout "브렌치 이름"
git switch "브렌치 이름" (checkout은 여러 기능을 하기에 switch를 사용하자)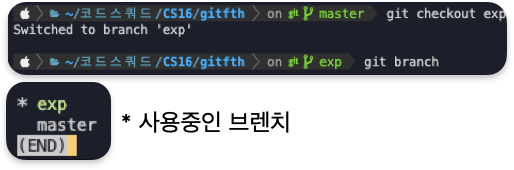
새로운 브렌치에서 파일 수정 및 add, commit을 한다면
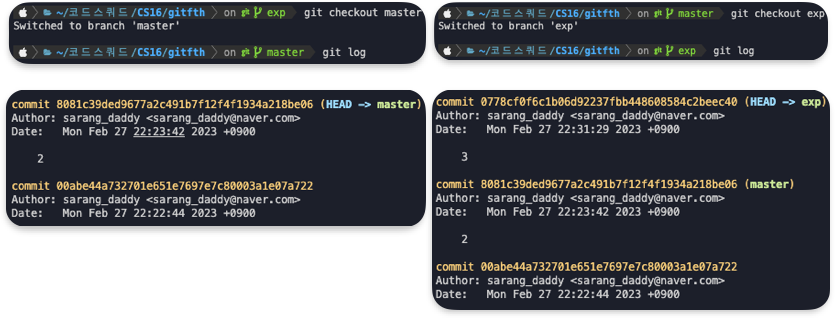
마스터 브렌치에서는 변동내용의 확인이 안되고 새로운 브렌치에서만 변경내용이 확인됨을 알 수 있다.
새로운 브렌치는 원본 위에서 새로운 작업이 시작되며 원본은 더럽히지 않고 새로운 작업을 적용 할 수 있다.
전체 브렌치 상황 확인하기
git log --branches --decorate --graph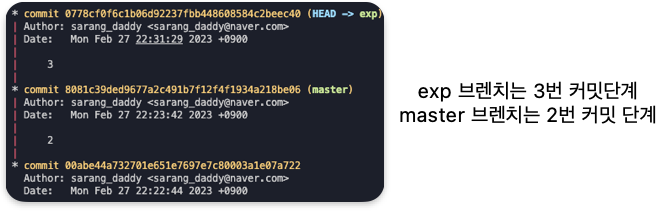
master 브렌치에서 파일 수정이 커밋 된다면
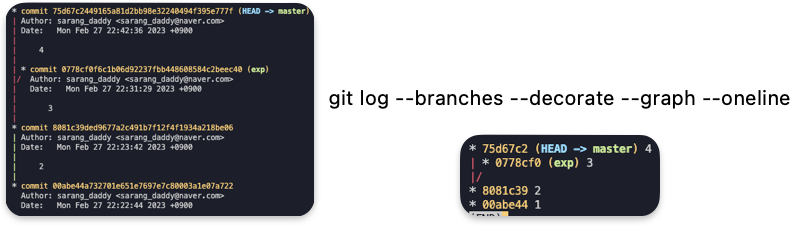
master와 새로운 브렌치를 직관적으로 확인하고 싶다면
git log master.."새로운 브렌치" // 마스터에는 있고 새로운 브렌치에는 없는거
git log "새로운 브렌치"..master // 새로운 브렌치에는 있는데 마스터에는 없는거
git log -p master.."새로운 브렌치" // 차이점과 내용까지 확인
git diff master.."새로운 브렌치" // 각각의 브렌치의 현재 상태 비교git - branch 병합
- "새로운 브렌치"를 master로 병합하기
- master 로 체크아웃 해야한다.
- git merge "새로운 브렌치" 명령어 입력

- master를 "새로운 브렌치"로 가져오기
- exp로 체크아웃 한다.
- git merge master
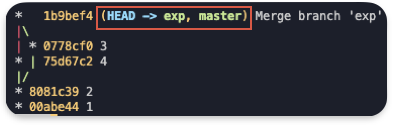
필요없는 "새로운 브렌치" 지우기
- master 로 체크아웃 해야한다.
- git branch -d "새로운 브렌치"
참고자료
지옥에서 온 Git
지옥에서 온 Git 신버전
얄코 git 강의
Github로 따라하는 버전관리
git 실습프로그램
