1. 논리 데이터 저장소 확인
🔷 데이터 모델 ( Data Model )
현실 세계의 정보를 인간과 컴퓨터가 이해할 수 있도록 추상화하여 표현한 모델
◼ 데이터 모델 절차 ⭐ 🔔
❐ 개념적 데이터 모델
- 현실 세계에 대한 인식을 추상적, 개념적으로 표현
- 개체관계 다이어그램, ERD
❐ 논리적 데이터 모델
- 업무 모습을 모델링 표기법으로 형상화하여, 사람이 이해하기 쉽게 표현
- 정규화
❐ 물리적 데이터 모델
- 논리 데이터 모델을 DBMS의 특성 및 성능을 고려해 물리적 스키마를 만듦
- 반 정규화
◼ 개체-관계 ( E-R ) 모델 ( 개념적 데이터 모델 )
현실 세계에 존재하는 데이터와 그들 간의 관계를 사람이 이해할 수 있는 형태로 명확하게 표현
| 구성 | 기호 |
|---|---|
| 개체 | □ ( 사각형 ) |
| 관계 | ◇ ( 마름모 ) |
| 속성 | ○ ( 타원 ) |
| 다중 값 속성 | ◎ ( 이중 타원 ) |
| 관계-속성 연결 | ㅡ ( 선 ) |
🔷 논리 데이터 모델
개념 모델로부터 업무 영역의 업무 데이터 및 규칙을 구체적으로 표현
개체 ( Entity ) , 속성 ( Attribute ) , 관계 ( Relationship ) 으로 구성
◼ 종류
❐ 관계 데이터 모델
- 2차원 테이블 형태
- 기본키 ( PK ) , 외래키 ( FK )
- 1:1 , 1:N , N:M 관계
❐ 계층 데이터 모델
- 트리 형태
- 상하관계 존재 ( 부모 개체 - 자식 개체 )
- 1:N 관계만 허용
❐ 네트워크 데이터 모델
- 그래프 형태
- CODASYL DBTG 모델
- 상위와 하위 레코드 사이에 다대다( N:M ) 관계 만족
🔷 관계 데이터 모델 ( Relation Data Model )
데이터를 행과 열로 구성된 2차원 테이블 형태로 구성한 모델
수학자 E.F.Codd 박사 제안
◼ 구성
| 구성요소 | 설명 |
|---|---|
| 릴레이션 | 행( Row )과 열( Column )으로 구성된 테이블 |
| 튜플 ( Tuple ) | 행 ( Row ) |
| 속성 ( Attribute ) | 열 ( Column ) |
| 카디널리티 ( Cardinality ) | 튜플 ( Row )의 개수 |
| 차수 ( Degree ) | 속성 ( Column )의 개수 |
| 스키마 ( Schema ) | 데이터베이스의 구조, 제약조건 등의 정보를 담고 있는 기본적인 구조 |
| 인스턴스 ( Instance ) | 정의된 스키마에 따라 테이블에 실제 저장된 데이터의 집합 |
◼ 관계 대수
관계형 데이터베이스에서 원하는 정보와 그 정보를 어떻게 유도하는가를 기술하는 절차적 정형 언어
- 일반 집합 연산자
- 순수 관계 연산자
❐ 일반 집합 연산자 🔔
일반 집합 연산자는 수학의 집합 개념을 릴레이션에 적용한 연산자
| 연산자 | 기호 | 표현 |
|---|---|---|
| 합집합 ( Union ) | ∪ | R ∪ S |
| 교집합 ( Intersection ) | ∩ | R ∩ S |
| 차집합 ( Difference ) | - | R - S |
| 카티션 프로덕트 ( CARTESIAN Product ) | × | R × S |
❐ 순수 관계 연산자 🔔
순수 관계 연산자는 관계 데이터베이스에 적용할 수 있도록 특별히 개발한 관계 연산자이다.
| 연산자 | 기호 | 표현 | 설명 |
|---|---|---|---|
| 셀렉트 ( Select ) | σ | σ 조건 ( R ) | 릴레이션 R에서 조건을 만족하는 튜플( 행, Row ) 반환 |
| 프로젝트 ( Project ) | π | π 속성 리스트 ( R ) | 릴레이션 R에서 속성 리스트의 값으로만 구성된 튜플( 행, Row ) 반환 |
| 조인 ( Join ) | ⋈ | R ⋈ S | 공통 속성을 이용해 R과 S의 튜플들을 연결하여 만들어진 튜플 반환 |
| 디비전 ( Division ) | ÷ | R ÷ S | 릴레이션 S의 모든 튜플과 관련있는 R의 튜플 반환 |
◼ 관계 해석
튜플 관계 해석과 도메인 관계 해석을 하는 비절차적 언어
프레티킷 해석 ( Predicate Calculus )에 기반한 언어
📝 비절차적 언어 : 원하는 정보가 무엇이라는 것만 선언
🔷 논리 데이터 모델링 속성
논리 데이터 모델링의 속성은 개체 , 속성 , 관계로 구성된다.
| 구조 | 설명 |
|---|---|
| 개체 ( Entity ) | 관리한 대상이 되는 실체 |
| 속성 ( Attribute ) | 관리할 정보의 구체적 항목 |
| 관계 ( Relationship ) | 개체 간의 대응 관계 |
◼ 개체 ( Entity )
- 사물 쪼는 사건으로 정의
- "개체"라고도 부름
- 피터 챈 모델 ( Peter Chen Model ) : 사각형 ( □ )
- 까마귀발 모델 ( Crow's Foot Model ) : 표 형식
◼ 속성 ( Attribute )
- 개체가 가지고 있는 요소 또는 성질
- 피터 챈 모델 ( Peter Chen Model ) : 타원형 ( ○ )
- 까마귀발 모델 ( Crow's Foot Model ) : 표 내부에 표시
◼ 관계 ( Relationship )
- 두 개체간의 관계를 정의
- 피터 챈 모델 ( Peter Chen Model ) : 마름모 ( ◇ )
- 까마귀발 모델 ( Crow's Foot Model ) :
| 기호 | 의미 |
|---|---|
 | 1 : 1 관계 |
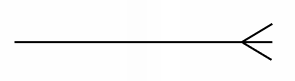 | 1 : N 관계 |
| N : M 관계 |
🔷 개체-관계 ( E-R ) 모델
현실 세계에 존재하는 데이터와 그들 간의 관계를 사람이 이해할 수 있는 형태로 명확하게 표현하기 위해 사용되는 모델
| 구성 | 기호 |
|---|---|
| 개체 | □ ( 사각형 ) |
| 관계 | ◇ ( 마름모 ) |
| 속성 | ○ ( 타원 ) |
| 다중 값 속성 | ◎ ( 이중 타원 ) |
| 관계-속성 연결 | ㅡ ( 선 ) |
🔷 정규화 ( Normalization ) 🔔
관계형 데이터 모델에서 데이터의 중복성을 제거하여 이상현상을 방지하고, 일관성과 정확성을 유지하기 위해 무손실 분해하는 과정
◼ 이상 현상( Anomaly ) ⭐ #삽살개 🔔
정규화를 하지 않았을 경우에 대한 문제점으로, 데이터 중복성으로 인해 릴레이션을 조작할 때 발생하는 현상
-
삽입 이상 : 정보 저장 시 해당 정보의 불필요한 세부정보를 입력해야 하는 경우
-
삭제 이상 : 정보 삭제 시 원치 않는 다른 정보가 같이 삭제 되는 경우
-
갱신 이상 : 중복 데이터 중 특정 부분만 수정되어 중복된 값이 모순을 일으키는 경우
◼ 정규화 단계 ⭐ #원부이결다조 🔔
-
1 정규형 ( 1NF ) : 원자값으로 구성
-
2정규형 ( 2NF ) : 부분 함수 종속 제거
-
3정규형 ( 3NF ) : 이행 함수 종속 제거
-
보이스-코드 정규형 ( BCNF ) : 결정자 후보키가 아닌 함수 종속 제거
-
4정규형 ( 4NF ) : 다치 종속 제거
-
5정규형 ( 5NF ) : 조인 종속 제거
🔷 반 정규화 ( De-Normalization , 비정규화 , 역정규화 ) 🔔
정규화된 엔티티, 속성, 관계에 대해 성능 향상과 개발 운영의 단순화를 위해 중복, 통합, 분리 등을 수행
◼ 특징
- 장점
- 성능 향상
- 관리의 효율성 증가 - 단점
- 데이터의 일관성 및 정합성 저하
- 유지비용 별도 발생 → 성능에 악영향 미칠 가능성 있음
◼ 반 정규화 기법
- 테이블
- 테이블 병합
- 테이블 분할
- 중복 테이블 추가 - 컬럼
- 컬럼 중복화 - 관계
- 중복 관계 추가
2. 물리 데이터 저장소 설계
🔷 물리 데이터 모델링
논리모델을 적용하고자 하는 기술에 맞도록 상세화 해가는 과정
◼ 물리 데이터 모델링 변환 절차
- 개체를 테이블로 변환
- 속성을 컬럼으로 변환
- UID를 기본키로 변환
- 관계를 외래키로 변환
- 컬럼 유형과 길이의 정의
- 반 정규화 수행
🔷 물리 데이터 저장소 구성
◼ 테이블 제약조건 ( Constraint ) 설계
❐ 참조무결성 제약조건 ⭐
- 제한 ( Restricted ) : 참조 무결성을 위배하는 연산 거절
- 연쇄 ( Cascade ) : 참조되는 릴레이션에서 튜플 삭제 후, 이 튜플을 참조하는 다른 릴레이션의 튜플도 삭제
- 널 값 ( Nullify ) : 참조되는 릴레이션에서 튜플 삭제 후, 이 튜플을 참조하는 다른 릴레이션의 튜플을 NULL
❐ 참조무결성 제약조건 SQL 문법
ALTER TABLE 테이블 ADD
FOREIGN KEY ( 외래키 )
REFERENCES 참조테이블( 기본키 )
ON DELETE [ RESTRICT | CASCADE | SET NULL ] ;◼ 뷰 ( View ) 설계
❐ 뷰 속성
- REPLACE : 뷰가 이미 존재하는 경우 재생성
- FORCE : 본 테이블의 조냊 여부에 관계없이 뷰 생성
- NOFORCE : 기본 테이블이 존재할 때 뷰 생성
- WITH CHECK OPTION : 서브 쿼리 내의 조건을 만족하는 행만 변경
- WITH READ ONLY : 데이터 조작어 작업 불가
◼ 파티션 ( Partition ) 설계
❐ 파티션 종류 ⭐
- 레인지 파티셔닝 ( Range Partitioning ) : 연속적인 숫자나 날짜 기준
- 해시 파티셔닝 ( Hash Partitioning ) : 파티션 키의 해시 함수 값 기준
- 리스트 파티셔닝 ( List Partitioning ) : 특정 파티션에 저장 될 데이터에 대한 명시적 제어가 가능
- 컴포지트 파티셔닝 ( Composite Partitioning ) : 레인지 파티셔닝, 해시 파티셔닝, 리스트 파티셔닝 중 2개 이상의 파티션을 결합
3. 데이터베이스 기초 활용하기
🔷 데이터베이스 ( Database )
◼ 정의 ⭐ 🔔
- 통합된 데이터 ( Integrated ) : 중복을 배제한 데이터의 모임
- 저장된 데이터 ( Stored ) : 저장 매체에 저장된 데이터의 모임
- 운영 데이터 ( Operational ) : 조직의 업무를 수행하는데 필요
- 공용 데이터 ( Shared ) : 여러 애플리케이션, 시스템들이 공동으로 사용
◼ 특성 ⭐ 🔔
- 실시간 접근성 : 쿼리에 대해 실시간 응답 가능
- 계속적인 변화 : 새로운 데이터의 삽입, 삭제, 갱신으로 항상 최신 데이터 유지
- 동시 공용 : 다수의 사용자가 동시에 같은 데이터 이용 가능
- 내용 참조 : 데이터 참조 시 레코드의 주소나 위치가 아닌, 사용자가 요구하는 데이터 내용으로 찾기
◼ 종류
❐ 파일 시스템 (File System )
- 파일에 이름을 부여하고 어디에 위치시킬지 정의한 뒤 관리하는 데이터베이스 이전 단계의 데이터 관리 방식
- ISAM
- VSAM
❐ 관계형 데이터베이스 관리시스템 ( RDBMS ; Relational Database Management System )
- 관계형 모델을 기반으로 하는 가장 보편화된 데이터베이스
- 데이터를 저장하는 테이블의 일부를 다른 테이블과 상하관계로 표시하며 상관관계 정리
- 변화하는 업무나 데이터 구조에 대한 유연성이 좋아 유지 관리가 용이
- Oralce
- SQL Server
- MySQL
- Maria DB
❐ 계층형 데이터베이스 관리시스템 ( HDBMS ; Hierarchical Database Management System )
- 데이터를 상하 종속적인 관계로 계층화하여 관리하는 데이터베이스
- 데이터 접근 속도 빠름
- 종속적 구조로 인해 변화하는 데이터 구조에 유연한 대응이 어려움
- IMS ( Information Management System )
- System2000
❐ 네트워크 데이터베이스 관리시스템 ( NDBMS ; Network Database Management System )
- 데이터의 구조를 네트워크상의 망상 형태로 표현한 데이터 모델
- 트리 구조나 계층형 데이터베이스보다 유연 but 설계가 복잡
- IDS ( Integrated Data Store )
- IDMS ( Integrated Database Management System )
🔷 DBMS ( Database Management System )
데이터 관리의 복잡성을 해결하는 동시에 데이터 추가, 변경, 검색, 삭제, 백업, 복구 등의 기능을 지원하는 SW
◼ 유형
- 키-값 ( Key-Value ) DBMS
- 컬럼 기반 데이터 저장 ( Column Family Data Store ) DBMS
- 문서 저장 ( Document Store ) DBMS
- 그래프 ( Graph ) DBMS
◼ 특징
- 데이터 무결성
- 데이터 일관성
- 데이터 회복성
- 데이터 보안성
- 데이터 효율성
🔷 빅데이터 ( Big Data )
주어진 비용, 시간 내에 처리 가능한 데이터 범위를 넘어서는 수십 페타바이트(PB) 크기의 비정형 데이터
◼ 특성 ( 3V ) ⭐
- 데이터의 양 ( Volume )
- 데이터의 다양성 ( Variety )
- 데이터의 속도 ( Velocity )
◼ 빅데이터 수집, 저장, 처리 기술
- 비정형 / 반정형 데이터 수집 : 정제되지 않은 데이터
- 장향 데이터 수집 : 정제된 데이터
- 분산데이터 저장 / 처리 : 대용량 파일의 효과적인 분산 저장 및 분산 처리 기술
- 분산데이터 베이스 : HDFS의 컬럼 기반 데이터베이스로 실시간 랜던 조회 및 업데이트가 가능한 기술
◼ 빅데이터 분석, 실시간 처리 및 시각화 기술
❐ 빅데이터 분석
- 데이터 가공 : 피그 ( Pig ) , 하이브 ( Hive )
- 데이터 마이닝 : 머하웃 ( Mahout )
❐ 빅데이터 실시간 처리
- 실시간 SQL 질의 : 임팔라 ( Impala )
- 워크플로우 관리 : 우지 ( Oozie )
❐ 분산 코디네이션
- 주키퍼 ( ZooKeeper )
❐ 분석 및 시각화
- 알 ( R )
🔷 NoSQL ( Not Only SQL ) 🔔
전통적인 RDBMS와 다른 DBMS를 지칭하기 위한 용어로, 최근 빅데이터 활성화와 함께 부각
- 데이터 저장에 고정된 테이블 스키마가 필요하지 않다.
- 조인(Join) 연산을 사용할 수 없다.
- 수평적으로 확장이 가능하다.
◼ 특성 #BASE
- Basically Available : 언제든지 데이터는 접근 가능
- Soft-State : 노드의 상태는 외부에서 전송된 정보를 통해 결정
- Eventually Consistency : 일정 시간이 지나면 데이터의 일관성 유지
◼ 유형
- Key-Value Store : Unique한 Key에 하나의 Value를 가진 형태
- Column Family Data Store : Key 안에 ( Column, Value ) 조합으로 된 여러 개의 필드를 갖는 DB
- Document Store : Value의 데이터 타입이 Document라는 타입을 사용하는 DB
- Graph Store : 시맨틱 웹 & 온톨로지 분야에서 활용되는 그래프로 데이터를 표현하는 DB
🔷 데이터마이닝 ( Data Mining ) 🔔
대규모로 저장된 데이터 안에서 체계적이고 자동적으로 통계적 규칙이나 패턴을 찾아내는 기술
대규모 데이터에서 의미있는 패턴을 찾아내거나 예측하여 의사결정에 활용하는 기법
◼ 절차
- 목적 설정
- 데이터 준비
- 가공
- 마이닝 기법 적용
- 정보 검증
◼ 주요 기법
- 분류 ( Classification ) : 과거 데이터로부터 특성을 찾아내어 분류모형을 만들어 결과 예측
- 연관 ( Association ) : 데이터 안에 존재하는 항목들 간의 종속관계를 찾아내는 기법
- 연속 ( Sequence ) : 연관 규칙에 시간 정보가 포함된 형태의 기법
- 데이터 군집화 ( Clustering ) : 유사한 특성을 지닌 몇 개의 소그룹으로 분할
