
Life is too short, You need python.
❗️ 아주 기초적이지만 파이썬을 사용하기 위해서 꼭 알아야할 개념 및 헷갈리는 개념을 제가 보려고 정리한 내용입니다. 그래서 다소 글이 어수선할 수 있습니다.🙏
계속해서 업데이트 될 예정...
파이썬의 특징
- 인터프리터 언어 : 컴파일 단계가 없으므로 개발 시간 단축, 대화형으로 사용할 수 있어 테스트하기 쉬움.
- 간결하고 읽기 쉽게 작성 : 수준 높은 자료형(딕셔너리 등) 덕분에 복잡한 연산을 한 문장으로 표현 가능.
- 다른 언어와 다르게 괄호 대신 들여쓰기를 이용해 코드를 나눔.
- 동적 타이핑 : 변수나 인자의 타입을 선언할 필요 없음.
CPython
C로 작성되었고, 파이썬 언어에 대한 모든 의사 결정을 담당. CPython의 인터프리터 프로세스는 GIL(Global Interpreter Lock)을 사용함. 즉, 단일 프로세스내에서 한번에 하나의 스레드만 파이썬 코드를 처리할 수 있다.
CPython 뜯어보기
PyPy
파이썬으로 작성된 인터프리터. 기계어를 자동 번역하는 JIT(Just In Time) 컴파일러 기능을 갖고 있음. CPython보다 나은 성능을 보임.
- JIT
프로그램을 실제 실행하는 시점에 기계어로 번역하는 컴파일 기법.
CPython vs PyPy
CPyhon은 일반적인 인터프리터. PyPy는 실행 추적 JIT(Just In Time) 컴파일을 제공하는 인터프리터.
IDLE(Integrated Development Environment)
Python 용 통합 개발 환경
보통 파이썬을 설치하면 내장되어있다.
하지만 자동완성이나 들여쓰기등 편리한 기능을 지원하지 않아 이런 기능을 지원해주는 파이참, vscode를 많이 쓴다.
인터프리터
Python은 인터프리터 언어. 파이썬의 가장 큰 특징은 한 줄씩 소스 코드를 해석해서 그때그때 실행해 결과를 바로 확인할 수 있다. 즉, 이 말은 인터프리터의 특징이기도 하다. 아래처럼 프로그래밍 언어는 컴파일링 언어와 인터프리터 언어로 나눌 수 있다.

컴파일러와 인터프리터는 모두 고급언어를 기계어로 바꾸는 역할을 한다. 차이점은 컴파일러는 한번 실행시 완전한 프로그램을 만들고, 인터프리터는 한번 실행시 명령어 한줄이 실행된다. 그래서 컴파일러를 사용하는 언어는 명령어를 한줄씩 실행하는 것이 불가능 하다. 실행속도는 컴파일러가 빠르고 인터프리터는 느리다.
객체(Object)
파이썬의 모든 변수는 객체다. 객체라는 것은 어떠한 속성값(attributes or value)과 행동(methods)을 가지고 있는 데이터. string 타입의 객체에서는 split, rsplit과 같은 메서드를 가진다. 코드를 작성할 때 객체.메서드로 입력을 한다.
파이썬에서의 객체 타입은 객체를 만든 클래스를 의미한다.
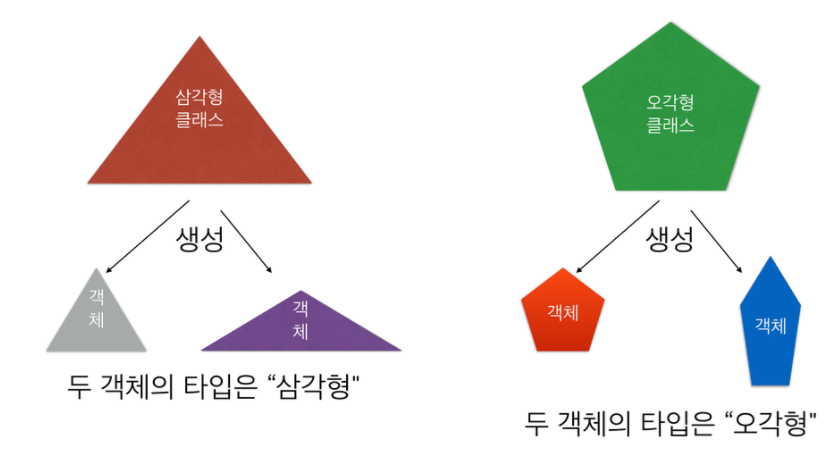
그래서 클래스를 통해 객체가 가질 속성과 메소드를 결정한다.
인스턴스
클래스에 의해 만들어진 객체를 의미한다.
class Singer: # 가수를 정의하겠느니라…
def sing(self): # 노래하기 메서드
return "Lalala~"
taeji = Singer() # tagji가 인스턴스객체와 인스턴스 차이
클래스로 만든 객체를 인스턴스라고 한다. 인스턴스는 특정 객체가 어떤 클래스의 객체인지를 관계 위주로 설명할 때 사용한다.
a = Cookie()위 코드에서는 a는 인스턴스라는 말보다 객체라는 말이 맞다. a는 Cookie의 객체라는 말보단 a는 Cookie의 인스턴스라는 표현이 맞다.
파라미터(Parameter)와 변수(variable) 그리고 인수(Argument)
파라미터(매개변수)는 어떠한 함수에 Input 값으로 사용되는 변수를 의미. 변수이긴 하지만 좀 더 특별한 변수인셈이다.
def test(A): # A는 Parameter
pass
test(B) # B는 Argument메서드(method)
클래스 내부에 존재하는 함수.
class BusinessCard:
def set_info(self, name): #set_info가 메서드
self.name = name
라이브러리와 프레임워크
- 라이브러리
개발자가 모듈을 사용하여 무언가를 개발함. 정상적인 제어방법.
ex- math, sys - 프레임워크
모듈이 개발자의 코드를 모듈처럼 사용하여 무언가를 개발함. 개발자가 모듈이 원하는 방식대로 코드 몇줄만 짜면 알아서 만들어주는 것. 즉, 제어 역전(IoC)가 일어남.
ex- Flask, Django
네이밍 컨벤션
각 단어를 밑줄 _로 구분하여 표기하는 스네이크 케이스를 사용한다.
객체지향프로그래밍
객체지향프로그래밍은 프로그래밍을 하는 방식의 하나이다. 객체의 모임으로 코드를 구성하여 객체끼리 상호작용하여 코드를 실행되도록 하는 것. 파이썬은 객체로 구성되어있고 객체지향 프로그래밍을 가능하게 하는 언어이지만, 그렇다고 객체지향프로그래밍을 강제하지 않는다.
여기 에 파이썬을 이용한 객체지향프로그래밍에 대해 정리한 좋은 글이 있다.
함수형 프로그래밍
아주 오래된 개념이지만, 소프트웨어의 크기가 커짐에 따라 코드의 양도 많아져, 코드를 유지보수하는 것이 벅차다고 생각되는 요즘 새로 떠오르는 프로그래밍 방식이다.
거의 모든 것을 함수로 나누어 문제를 해결하는 방식으로 가독성을 높이고 유지보수를 용이하게 해준다고 한다.
파이썬 또한 함수형 프로그래밍이 가능한데 방법은 여기에 정리되어있다.
Comprehension(컴프리헨션)
lambda(람다) 표현식보단 컴프리헨션을 사용하는 것이 훨씬 가독성에 좋고 속도가 빠르다. 조건문이 두개가 넘어가게 되면 가독성이 떨어지므로 그럴 경우 억지로 컴프리헨션을 쓰는 방식은 옳지 않다. 또한 람다 표현식보다 좋다고 해서 람다 표현식을 쓰면 안된다는 의미가 아니라는 것을 유의하자. 컴프리헨션으로 표현하지 못하지만 람다로 표현할 수 있는 경우도 있다.
[x*2 for x in range(6)] # [0, 2, 4, 6, 8, 10]
[x for x in range(1, 10+1) if x % 2 == 0] # [2, 4, 6, 8, 10]
[ (x, y) for x in ['쌈밥', '치킨', '피자'] for y in ['사과', '아이스크림', '커피']]
# [('쌈밥', '사과'),('쌈밥', '아이스크림'),('쌈밥', '커피'), ('치킨', '사과'),('치킨', '아이스크림'),('치킨', '커피'),('피자', '사과'),('피자', '아이스크림'),('피자', '커피')]
is 와 ==
is는 id()값을 비교하는(할당된 메모리 주소를 비교) 함수이고, ==는 값을 비교하는 함수이다. None 같은 경우 값이 없기때문에 ==는 사용을 할 수 없고 is만 사용가능하다.
a = [1, 2, 3]
a == copy.deepcopy(a) # Output: True
a is copy.deepcopy(a) # Output: Falsecopy.deepcopy()로 복사한 결과 값은 같지만 ID는 다르기 때문에 위와 같은 결과가 나타난다.
copy
참조 관계를 갖지 않도록 리스트를 복사해야하는 경우 copy()나 deepcopy()로 처리하는 방법이 있다.
copy()는 얕은 복사에 해당되고 deepcopy()의 경우 깊은 복사에 해당된다.
- 얕은 복사
copy()
얕은 복사의 경우 리스트를 새로운 값에 할당한다. 즉, 새로운 id가 부여된다.
다만, 리스트 안의 리스트가 존재하는 경우 전체 id 값은 다르지만 리스트 안의 리스트(2차원 리스트) 각각의 id는 동일한 주소를 갖고 있다. 이러한 다중 리스트의 경우deepcopy()를 사용해야한다.
import copy
a = [1, 2, 3]
b = copy.copy(a)
a == b # Output: True
a is b # Output: False
c = [[1,2,3],[4,5,6]]
d = copy.copy(c)
c == d # Output: True
c is d # Output: False
c[0] == d[0] # Output: True
c[0] is d[0] # Output: True- 얕은 복사
[:]
모듈을 따로 불러오지 않아도[:]를 사용해서 얕은 복사를 수행할 수 있다.
a = [1, 2, 3]
a == a[:] # Output: True
a is a[:] # Output: False- 깊은 복사
deepcopy()
c = [[1,2,3],[4,5,6]]
d = copy.deepcopy(c)
c == d # Output: True
c is d # Output: False
c[0] == d[0] # Output: True
c[0] is d[0] # Output: FalseZIP
a = [1,2,3]
b = [4,5,6]
e = list(zip(a,b))
print(e)
[(1, 4), (2, 5), (3, 6)]map
list(map(함수, 리스트))
list(map(함수, iterable))
tuple(map(함수, 튜플))
a = [1.2, 2.5, 3.7, 4.6]
a = list(map(int, a))
print(a)
[1, 2, 3, 4]
a = list(map(str, range(10)))
print(a)
['0', '1', '2', '3', '4', '5', '6', '7', '8', '9']리스트의 요소를 지정된 함수로 처리해주는 함수. 원본 리스트를 변경하지 않고 새로운 리스트를 생성한다.
iterable 과 iterator
이터레이터(iterator)는 값을 차례대로 꺼낼 수 있는 객체이다.
반복 가능한 객체(iterator)는 요소가 여러 개 들어있고, 한번에 하나씩 꺼낼 수 있는 객체이다. 즉, 문자열, 리스트, 딕셔너리, 세트가 반복 가능한 객체이다.
객체가 반복 가능한지 확인하는 방법은 객체에 iter 이라는 메서드가 존재하는지 보면 된다.

[1,2,3].__iter__()
<list_iterator object at 0x03616630>리스트에 iter 메소드를 호출하면 이터레이터가 나온다.

위 사진은 for에서 이터레이터의 대표적인 예인 range가 iter 메서드를 실행하여 이터레이터를 얻는 과정이다. next 메서드로 숫자를 하나씩 꺼내 저장한다.
제너레이터
특별한 종류의 이터레이터. 이터레이터를 만들기 위해 __iter__, __next__, __getitem__ 메서드가 필요하지만, 제너레이터는 함수 안에 yield만 있으면 간단하게 작성 할 수 있다. 그래서 우아한 방식의 이터레이터라고 부르기도 한다. 모든 제너레이터는 이터레이터이지만 이터레이터라고 해서 모두 제너레이터가 아니다.
def number_generator():
yield 0
yield 1
yield 2
for i in number_generator():
print(i)retrun 명령어가 없이 오직 yield로 구성되어 있다. 또한 이터레이터와 동일하게 __next__ 메서드를 호출할 수 있다.
yield
함수가 실행되는 중에 값을 함수 바깥으로 전달한다. 'return'은 실행 즉시 값을 함수 바깥으로 전달하고 함수가 종료되지만yield는 함수 바깥으로 값을 전달하지만 함수를 끝까지 실행한다.
이러한 제너레이터를 쓰는 이유는 무엇일까?
no_gener = list(range(1000000)) # [0, 1, 2, 3, 4 ...]
gener = range(1000000) # range(0, 1000000)
len(no_gener) # 1000000
len(gener) # 1000000
# 메모리 점유율
import sys
sys.getsizeof(no_gener) # 8697464
sys.getsizeof(gener) # 48
# 인덱스로 제너레이터 바로 접근
gener[999] # 999바로 메모리를 효율적으로 사용할 수 있기때문. 제너레이터가 없다면 1억개의 숫자를 만들 때 메모리에 숫자가 1억개가 저장되어 있어야 한다. 하지만 제너레이터가 있다면 일단 제너레이터만 생성해두고 필요할 때 언제든 숫자를 만들어 낼 수 있다. 제너레이터는 1억개의 데이터를 한번에 만들지 않고 next()를 이용해 값을 하나씩 만들기 때문이다. 즉, 값을 그 때 그 때 생성한다.
generator = (i for i in range(10) if i % 2) # 제너레이터 생성
print(next(generator)) # 값 출력 Ouput: 1
print(next(generator)) # 값 출력 Ouput: 3제너레이터를 생성하는 방법은 리스트 컴프리헨션과 비슷하다. 단지, []를 ()로 바꿔주면 된다.
자세한 내용은 여기를 참고하면 된다.
튜플과 리스트의 차이
리스트는 원소를 변경 가능하지만 튜플은 변경불가. 튜플에 모든 기능은 리스트에 포함되므로 리스트 자료구조만 이용해도 코드를 작성할 수 있다. 다만 튜플이 속도가 빠르다는 장점이 있음.
따라서 한번 저장해둔 값을 바꿀 필요가 없다면 튜플을 사용하는 것이 훨씬 효율적.
함수의 호출과정

함수가 호출되면 인자와 변수들이 메모리에 할당되고, 함수가 종료되면 메모리에서 삭제. 이는 여러 함수를 호출하는 코드에서 메모리를 과도하게 사용하는 것을 막아줌. 그래서 함수가 종료되고 나서 함수내 변수들을 참조할 수 없는 것.
그럼 함수 내부의 변수를 함수 밖에서 사용하려면 그 변수를 return을 이용해 함수 밖으로 내보내야 함.
__name__
이 변수는 특정 파이썬 파일이 직접 실행된 것인지 다른 파일을 import한 것인지 확인하는 용도로 사용됩니다. print(__name__)을 하면 이 코드를 입력한 파일에서는 결과로 __main__이 나옵니다. 하지만 import를 한 파일에서는 임포팅한 파일의 명으로 출력됩니다. 이 변수는 보통 언제 사용할까요?
if __name__ == "__main__":
print(cal_upper(10000))
print(cal_lower(10000))
print(__name__)가장 많이 사용하는 방식은 모듈을 테스트하는 코드가 임포트했을 때도 출력되는 문제를 해결할 때 사용합니다. 위와 같이 코드를 작성하면 직접 이 파일을 출력할 때만 아래의 print가 출력이 될 것입니다. 임포트를 한 경우에는 물론 출력이 안되겠죠.
from A import B
A라는 모듈로부터 B라는 함수를 import 하라는 의미. 그래서 이때는 A 모듈에서 B함수의 기능밖에 사용 못합니다.
import os
dir()
['__builtins__', '__doc__', '__loader__', '__name__', '__package__', '__spec__', 'os']from os import listdir
dir()
['__builtins__', '__doc__', '__loader__', '__name__', '__package__', '__spec__', 'listdir']
os.listdir()
Traceback (most recent call last):
File "<pyshell#4>", line 1, in <module>
os.listdir()
NameError: name 'os' is not defined
listdir() # 이렇게만 사용가능이때는 os 모듈을 임포트 한것은 아니기에 '모듈명.함수명'으로 작성하면 오류가 뜬다. 그렇기에 이런 경우에는 함수명으로만 코드를 작성해야한다.
enumerate 함수
내장 함수로 시퀸스 자료형(리스트, 튜플, 문자열)를 input해 enumerate 객체로 반환합니다. 아래와 같이 시퀸스 자료형의 값과 인덱스를 함께 구하고 싶을 때 자주 사용됩니다.
for i, stock in enumerate(['Naver', 'KAKAO', 'SK']):
print(i, stock)
0 Naver
1 KAKAO
2 SK클래스(class)
객체의 구조와 행동을 정의하고 반복된 행위를 계속해서 할 수 있도록 해준다. 흔히 클래스는 설계 도면이고 객체는 설계도면을 보고 만든 피조물을 뜻한다.
이러한 클래스를 사용하면 개발자가 원하는 새로운 타입을 만들 수 있다.
self 인자
클래스 내부에 메서드의 첫 번째 인자는 반드시 self여야 한다. 'self.변수명'같은 형태를 띠는 변수를 인스턴스 변수라고 한다.
self 라는 인자를 사용하는 이유는 class를 처음 생성할 때는 사용자가 이 class의 인스턴스로 무엇으로 설정할지 모르기때문에 인스턴스를 임시로 self로 설정한 것이다.
class BusinessCard:
def set_info(self, name, email, addr):
self.name = name
self.email = email
self.addr = addr위와 같이 class를 생성한 뒤, 사용자가 아래와 같은 인스턴스를 정의한다.
member1 = BusinessCard()그럼 이제 이 class의 인스턴스는 member1이 된다. 그럼 self에 member1이라는 인스턴스가 바인딩되어 member1.name과 같이 메서드내 변수에 접근할 수 있어진다.
a = BusinessCard()
a.set_info() # 인스턴스를 통한 메소드 호출
BusinessCard.set_info() # 클래스 이름을 통한 메서드 호출인스턴스를 통해 메서드를 호출하는 방법과 클래스의 이름을 통해 메서드를 호출하는 방법이 있는데 둘에 큰 차이점은 없지만 보통 '인스턴스.메서드()' 방식을 사용한다.
__init___ 생성자
클래스의 인스턴스 생성과 초깃값 입력을 한번에 처리할 수 있도록 하는 메서드.
class BusinessCard:
def set_info(self, name, email, addr):
self.name = name
self.email = email
self.addr = addr
def print_info(self):
print("--------------------")
print("Name: ", self.name)
print("E-mail: ", self.email)
print("Address: ", self.addr)
print("--------------------")
member1 = BusinessCard()
member1.set_info("kim", "kim@gmail.com", "USA")
member1.print_info()위 코드는 __init__ 메서드가 없어서 인스턴스를 생성한 뒤 초깃값을 따로 입력했다. 이를 __init__를 통해 한번에 처리하는 코드가 바로 아래쪽에 있는 코드다.
class BusinessCard:
def __init__(self, name, email, addr):
self.name = name
self.email = email
self.addr = addr
def print_info(self):
print("--------------------")
print("Name: ", self.name)
print("E-mail: ", self.email)
print("Address: ", self.addr)
print("--------------------")
member1 = BusinessCard("Kangsan Lee", "kangsan.lee", "USA")
member1.print_info()네임스페이스
변수가 객체를 바인딩할 때 그 둘 사이의 관계를 저장하고 있는 공간. 네임스페이스가 존재하기 때문에 클래스 내의 변수에 접근할 수 있다.
class Stock:
market = "kospi"
dir() # 객체의 변수와 메서드를 보여줌
['Stock', '__builtins__', '__doc__', '__loader__', '__name__', '__package__', '__spec__'] 클래스가 정의되면 하나의 독립적인 네임스페이스가 생성된다. 여기에는 클래스 내의 변수나 메서드가 딕셔너리 형태로 들어간다.

해당 클래스의 네임스페이스를 파이썬 코드로 확인하려면 클래스의 __dict___속성을 확인하면 된다.
Stock.__dict__
mappingproxy({'market': 'kospi', '__module__': '__main__', '__dict__': <attribute '__dict__' of 'Stock' objects>, '__doc__': None, '__weakref__': <attribute '__weakref__' of 'Stock' objects>})같은 클래스라도 두 개의 인스턴스로 생성하면 네임스페이스 또한 두개가 생긴다.
s1 = Stock()
s2 = Stock()
id(s1)
50572464
id(s2)
50348240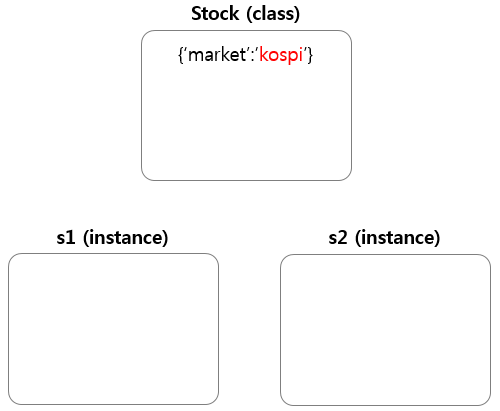
비어있는 인스턴스에 변수를 이용하여 값을 저장할 수 있다.
s1.market = 'kosdaq'
s1.__dict__
{'market': 'kosdaq'} # market 변수에 kosdaq 값이 저장됨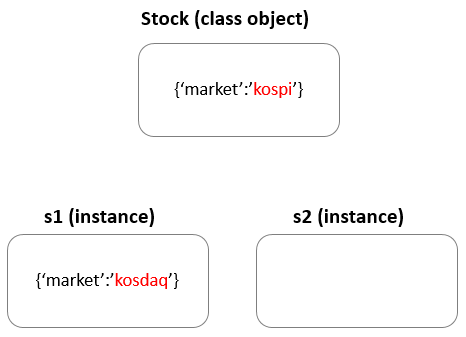
비어있는 s2 인스턴스에 market 변수를 호출하면 어떻게 될까?
s2.market
'kospi'네임스페이스에 해당 변수가 없으면 클래스의 네임스페이스를 참고한다.
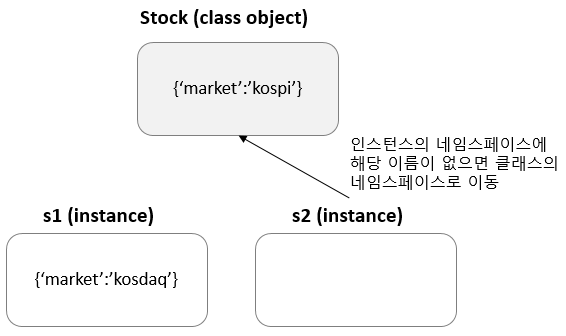
클래스 변수와 인스턴스 변수
class Account:
num_accounts = 0 # 클래스 변수
def __init__(self, name): # 생성자
self.name = name # 인스턴스 변수
Account.num_accounts += 1
def __del__(self): # 소멸자
Account.num_accounts -= 1위 코드의 num_accounts처럼 클래스 내부에 선언된 변수를 클래스 변수라고 하고 self.name과 같이 self가 붙은 변수를 인스턴스 변수라고 한다.
언제 클래스 변수를 사용하고 인스턴스 변수를 사용해야할까?
바로 여러 인스턴스 간에 서로 공유해야 하는 값은 클래스 변수를 사용해야한다. 인스턴스 네임스페이스에 없는 이름은 클래스 네임스페이스에서 찾아보기 때문에 이를 이용해서 클래스 변수가 모든 인스턴스에 공유될 수 있다.
kim = Account("kim") # 인스턴스 생성
lee = Account("lee")
kim.num_accounts
2
lee.num_accounts
2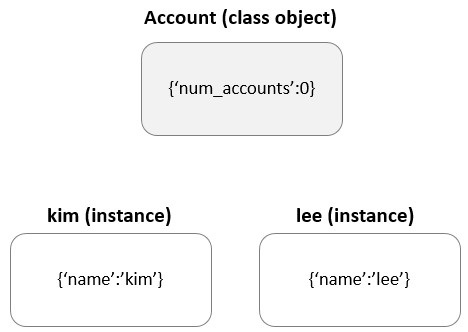
클래스 상속
다른 클래스에 이미 구현된 메서드나 속성을 상속한 클래스는 그 메서드와 속성을 그대로 사용할 수 있다.
class Parent:
def can_sing(self):
print("Sing a song")
class LuckyChild(Parent): # Parent 클래스를 상속받음
pass
child1 = LuckyChild()
child1.can_sing() # Parent 클래스에 있는 메서드 사용
Sing a song 아스테리스크(*)
파이썬에서 *는 패킹과 언팩을 한다. 보통의 경우에는 언팩을 하지만 파라미터에서 사용되었을 경우 패킹을 한다.
# Unpack
fruits = ['lemon', 'pear', 'watermelon', 'tomato']
print(*fruits) # lemon pear watermelon tomato'
a, *b = [1,2,3,4]
a # 1
b # [2,3,4]
# Pack
def f(*params):
print(params)
f('a','b','c') # ('a','b','c') 위와 같이 파라미터로 사용했을 경우 함수에 파라미터가 1개 밖에 없지만 3개의 인수를 받았다. 그래서 오류가 나야하지만 *를 사용했기 때문에 3개의 인자를 하나로 패킹되어 함수가 정상적으로 실행된다.
*가 한번 쓰인 경우에는 위 예시처럼 리스트 또는 튜플 등의 시퀸스를 언패킹하고, 만약 ** 처럼 두번 쓰인 경우 키/값(dictionary)를 언패킹한다.
# ** Unpack
date_info = {'year':'2020', 'month':'01', 'day':'7'}
new_info = {**data_info, 'day':'14'}
new_info # {'year':'2020', 'month':'01', 'day':'14'}파이썬의 역슬래시(\)
구문이 길어질 때, 다음 줄까지 구문을 이어가겠다는 의미.
a = [1,2,3, \
4,5,6]
print(a) # [1,2,3,4,5,6]딕셔너리와 리스트의 속도차
방대한 양의 데이터를 입력해야하고, 그 데이터의 순서 입력이 필요없다면 딕셔너리를 사용하는것이 효율적이다.
리스트 연산 속도

딕셔너리 연산 속도

딕셔너리 연산
이전 버전에는 딕셔너리의 순서가 보장되지 않았지만, 파이썬 3.7 버전부터는 순서가 보장된다. 또한 3.9 버전부터는 병합 연산자와 업데이트 연산자 두 개가 추가되었다.
병합 연산자( | )
d = { 'spam': 1, 'eggs': 2, 'cheese': 3}
e = { 'cheese': 'cheddar', 'aardvark': 'Ethel'}
d | e
# { 'spam': 1, 'eggs': 2, 'cheese': 'cheddar', 'aardvark': 'Ethel'}
e | d
# { 'cheese': 3, 'aardvark': 'Ethel', 'spam': 1, 'eggs': 2}d와 e처럼 두 딕셔너리에 키가 겹치면 오른쪽 딕셔너리의 값을 따른다.
업데이트 연산자( =| )
d = {'spam': 1, 'eggs': 2, 'cheese': 3}
e = {'cheese': 'cheddar', 'aardvark': 'Ethel'}
d |= e
# {'spam': 1, 'eggs': 2, 'cheese': 'cheddar', 'aardvark': 'Ethel'}업데이트 연산자도 병합 연산자와 같이 두 키가 겹치면 오른쪽 딕셔너리 값을 따른다.
여기를 보면 좀 더 자세히 알 수 있다.
타입 힌트
파이썬 3.7 버전부터 사용가능해진 타입 힌트 기능은 typing 모듈을 import하여야 했다. 하지만 3.9 버전부터는 빌트인이 되어졌다.
super()
- 부모 클래스의 원하는 함수를 호출해줌
super().메서드형식으로 사용 가능
# super를 사용하지 않았을 때
class A:
def __init__(self):
print('A __init__')
self.parents = '부모 클래스'
class B(A):
def __init__(self):
print('B __init__')
self.child = '자식 클래스'
test = B()
print(test.child)
print(test.parents) # 부모 클래스의 속성을 출력하려고 하면 에러가 발생함
class Person:
def A(self):
print('A __init__')
self.parents = '부모 클래스'
class B(A):
def __init__(self):
print('B __init__')
super().__init__() # super()로 기반 클래스의 __init__ 메서드 호출
self.child = '자식 클래스'
test = B()
print(test.child)
print(test.parents)