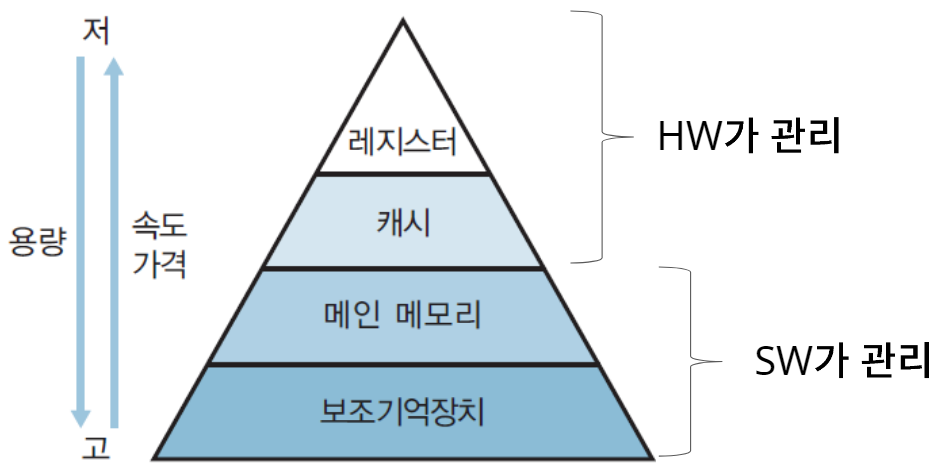
메모리
메모리 종류
메모리 전송 단위
Block
- 보조기억장치와 주기억장치 사이의 데이터 전송 단위
- Size: 1 ~ 4KB
Word
- 주기억장치와 레지스터 사이의 데이터 전송 단위
- Size: 16 ~ 64bits
메모리 관리
모든 프로그램은 메모리에 적재가 되어야 실행이 가능하다. 그렇기때문에 한정된 메모리를 여러 프로세스가 함께 효율적으로 사용하기위해 메모리 관리 방법이 필요하다.
즉, 메모리를 할당하고 제거하며 보호하는 활동을 메모리 관리라고 한다.
메모리 관리 정책
- 적재 정책(fetch policy)
디스크에서 메모리로 프로세스를 적재하는 시기를 결정하는 정책- 요구 적재 : 요청에 따라 프로세스를 메모리에 적재하는 방법
- 예상 적재 : 요청을 예상해서 미리 프로세스를 메모리에 적재하는 방법
- 배치 정책(placement policy)
프로세스를 메모리 어느 위치에 저장을 할 것인지 결정하는 정책- 최초 적합 : 크기가 충분한 첫번째 공간에 배치
- 최적 적합 : 프로세스 크기와 가장 비슷한 공간에 배치
- 최악 적합 : 가장 큰 공간에 배치
- 대치 정책(replacement policy)
현재 메모리에 적재된 프로세스 중 제거할 프로세스를 결정하는 정책- FIFO 대치 알고리즘
- 최근 최소 사용(LRU, Least Recently Used) 대치 알고리즘
메모리 구조
논리적 주소(=가상주소)
코드가 저장된 공간과 프로그램에서 사용하는 자료구조.
물리적 주소
적재하는 실제 주소. 메모리 칩이나 디스크 공간.
메모리 관리 장치(MMU)
논리적 주소 -> 물리적 주소 변환을 담당. 즉, 바인딩을 담당.
변환 방법으론 고정 분할, 동적 분할, 페이징 등이 있다.

바인딩(binding)
바인딩
논리적 주소 -> 물리적 주소를 매핑시켜주는 작업.- 언제 변환하냐에 따라 바인딩 종류가 나뉨.
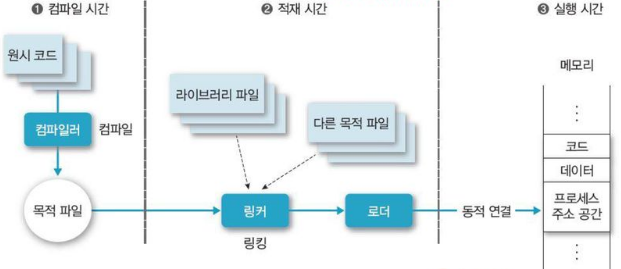
링커(linker)
컴파일러가 원시 코드를 파일로 생성하면 이 파일에 라이브러리와 다른 파일들을 결합.
exe 같은 파일이 링커를 통해 생성.
로더(loader)
지정 위치에서 시작하여 메모리에 프로그램을 배치. 흔히 얘기하는 로딩을 해주는 역할.
컴파일 시간에 바인딩(Compile time binding)
- 메모리에 적재될 위치를 컴파일러가 알 수 있는 경우
int a;를 선언했을 때a라는 변수의 메모리 주소는100으로 설정할 때- 코드 상에서 메모리 주소를 설정했기때문에 위치가 변하지 않음
- 프로그램 전체가 메모리에 올라가야함
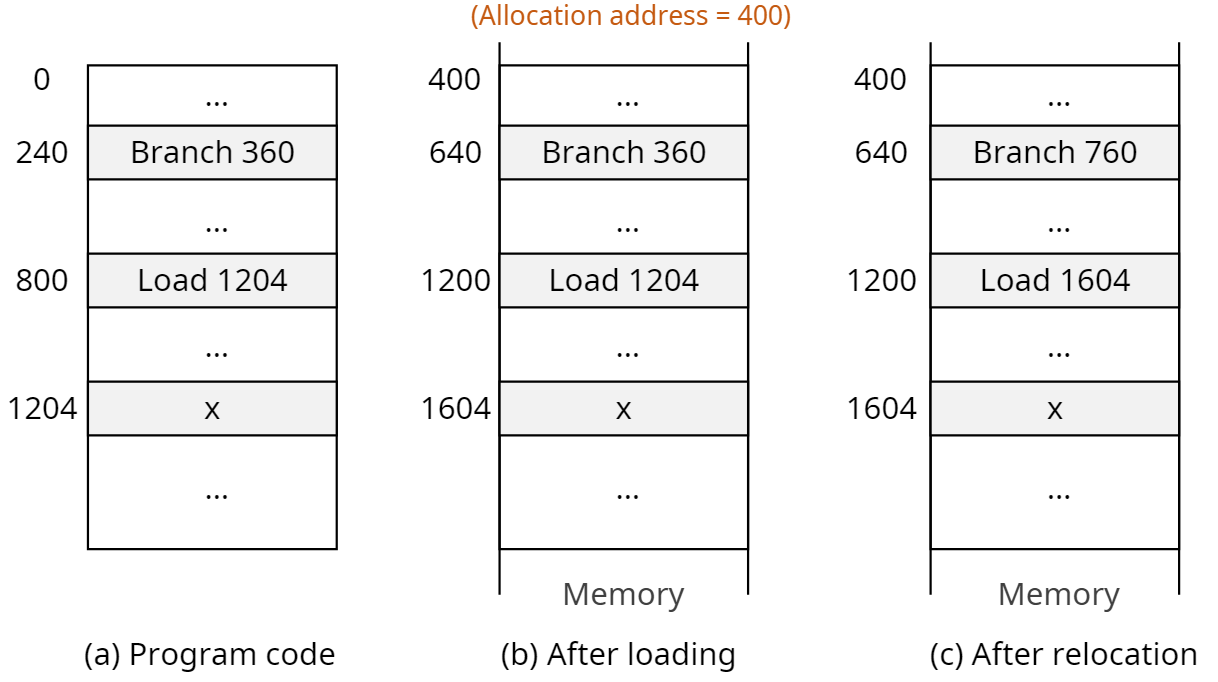
적재 시간에 바인딩(Load time binding)
- 메모리 적재 위치를 컴파일 시점에 모르면 대체 가능한 상대 주소를 생성
- 프로그램은 주소가
0번부터 시작된다고 가정한다. 0번을 기준으로 코드 상 주소를0+100,0+200으로 상대 주소를 만든다
- 프로그램은 주소가
- 적재 시점(Load time)에 시작 주소를 반영하여 코드 상 상대 주소를 다시 재설정한다.
- 프로그램 전체가 메모리에 올라가야함
실행 시간에 바인딩(Run time binding)
- 실행 시간(Running)까지 주소 바인딩(할당) 함
- 프로세스가 Running -> ready 상태가 되어 다시 Running을 할 경우 메모리 주소가 바뀜
- 매번 실행될 때마다 주소가 바뀐다
- 하드웨어(MMU: Memory Management Unit)의 도움이 필요
- 대부분 OS가 사용
동적 적재(Dynamic Loading)
- 디스크에 프로그램을 여러 루틴(function)으로 나눠 저장
- 해당 루틴이 실제 호출되기 전까지는 루틴을 메모리에 적재하지 않음
- 메인 프로그램만 메모리에 적재하여 수행
- 루틴이 호출되면 바인딩 수행
- 사용하지 않을 루틴은 메모리에 적재하지 않으므로 메모리를 매우 효율적으로 사용 가능.
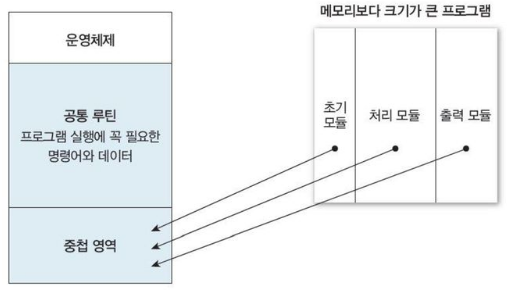
중첩(오버레이)
당장 필요하지 않는 프로그램의 일부를 중첩으로 설정하는 방식.
실행에 꼭 필요한 명령어와 데이터만 메모리에 적재하고 나머지는 메모리에 중첩영역을 따로 만들어 필요할 때 그 공간에 적재.
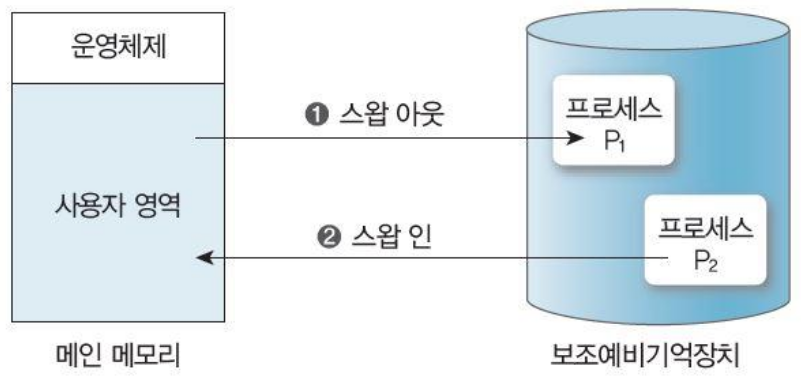
스와핑(프로세스 교체)
프로세스 할당이 끝나면 보조 기억장치로 프로세스를 보내고(스왑 아웃), 새로운 프로세스를 메모리에 적재하는 것(스왑 인).
디스크에 저장된 프로세스를 메모리로 올리고 메모리에 적재된 프로세스는 준비 큐에 대기시키는 중기 스케줄링에 해당된다.
속도가 빠른 보조기억장치가 필요하다.
항상 우선순위가 높은 프로세스 공간을 만들 수 있어 시스템에 유연성을 높임.
- 스와핑 불가
- 컴파일 또는 적재 시간에 바인딩을 하면 프로세스를 보조 기억장치 등으로 이동할 수 없어 스와핑이 불가하다.
- 입출력 버퍼가 사용자 메모리를 비동기적으로 엑세스하면 입출력 대기중이라도 스와핑을 할 수 없다.
- 스와핑 가능
- 오직 실행 시간에 바인딩을 할 때 스와핑 가능하다.
- 입출력 동작이 있는 프로세스는 스와핑 가능하다.
메모리 적재 방법
- 연속 메모리 적재
- 가변 분할
- 고정 분할
- 비연속(분산) 메모리 적재
- 가변 분할 : 세그먼테이션
- 고정 분할 : 페이징
연속 메모리 할당(Continuous Memory Allocation)
- 프로세스를 하나의 연속된 메모리 공간에 할당하는 정책
- 메모리 구성 정책이 필요
- 메모리에 동시에 올라갈 수 있는 프로세스 수(multiprogramming degree)
- 각 프로세스에게 할당되는 메모리 크기
- 메모리 분할 방법
단편화(Fragmentation)
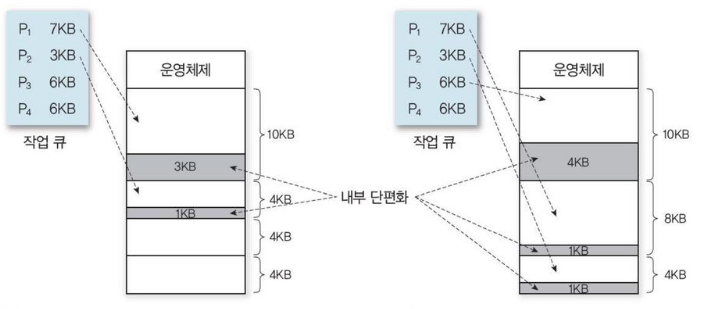
- 내부 단편화(Internal fragmentation)
메모리 파티션의 크기 > 프로세스 크기
메모리 남는 공간이 발생되어 메모리 낭비. - 외부 단편화(External fragmentation)
남은 메모리 크기(연속된 공간 아님) > 프로세스 크기
연속된 메모리 공간이 아니므로 프로세스에게 메모리를 할당 하지 못함.
메모리에 남는 공간이 있지만 사용하지 못하므로 메모리 낭비
메모리 보호 기법
여러 프로세스가 메모리에 올라가기때문에 이러한 프로세스를 보호할 수 있는 방법이 필요.
- 기준 레지스터
프로세스가 시작하는 물리적 주소. 경계 레지스터 중 하나가 기준 레지스터가 됨 - 경계 레지스터(Boundary register)
메모리 공간 상에서 각 파티션끼리 혹은 커널에 프로세스가 침범하지 않도록 하기위해 사용하는 주소.
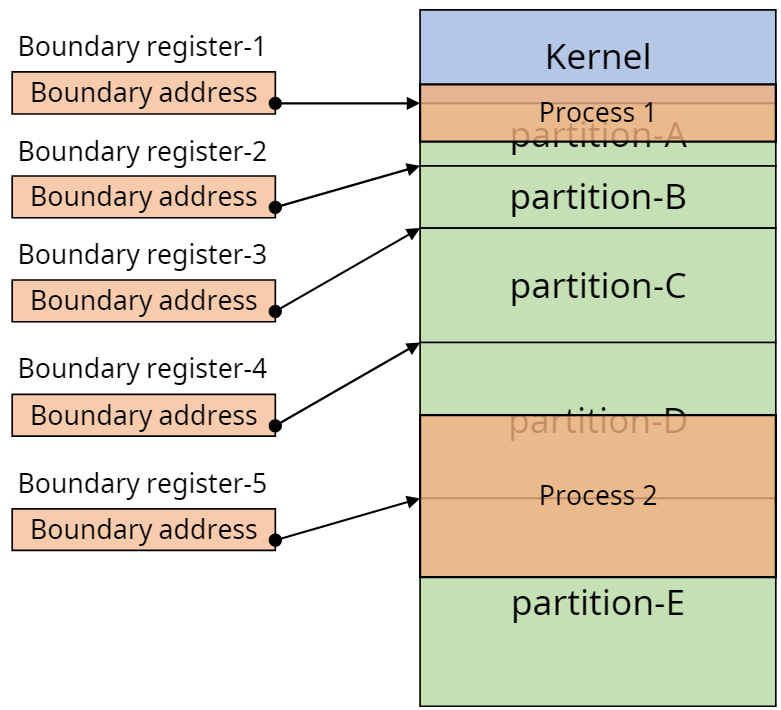
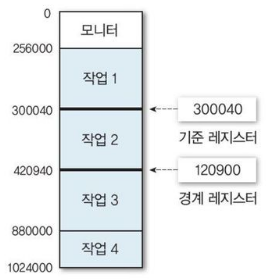
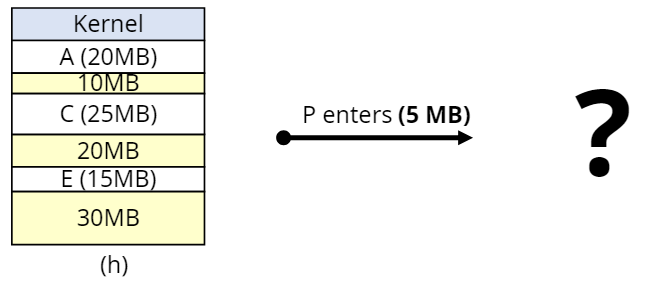
고정 분할 방법(Fixed Partition Multiprogramming)
- 메모리를 여러 개의 고정된 크기로 분할하여 할당하는 것.
- 메모리는 할당되기전 미리 분할되어 있음
- 각 프로세스는 하나의 파티션에 적재(1:1)
- 즉, 파티션의 수 = 프로세스의 수
- 물리적 주소 = 기준 레지스터(PBR) + 논리적 주소
- 논리적 주소가 분할된 메모리보다 크면 오류가 발생하고, 작으면 내부 단편화가 발생한다.
가변 분할 방법
- 필요한 만큼 메모리를 할당하는 것.
- 초기에는 전체가 하나의 영역
- 프로세스를 어디에 배치해야하는가에 대한 문제가 생김
- 배치 전략(Placement strategies)
- 최초적합 방법(first-fit)
충분히 큰 첫번째 공간에 할당.
공간 활용률이 떨어짐.
오버헤드가 낮음 - 최적적합 방법(best-fit)
프로세스가 들어갈 수 있는 공간 중 가장 작은 공간.
크기 순으로 정렬되어 있지 않으면 전체를 검색해야함.(오버헤드가 큼)
공간 활용률은 높으나 할당하기 위해 많은 시간이 소요.
작은 크기의 파티션이 많이 발생함 - 최악적합 방법(worst-fit)
가장 큰 사용 가능 공간에 할당.
최적적합과 마찬가지로 정렬되어 있지 않으면 전체를 검색해야함.
작은 크기의 파티션의 발생을 줄일 수 있음
큰 크기의 파티션을 확보하기 힘듦 - 순차 최초적합 방법(Next-fit)
최초 적합 전략과 유사
마지막으로 탐색한 위치부터 탐색
메모리 영역의 사용빈도 균등화
낮은 오버헤드
- 최초적합 방법(first-fit)
외부 단편화가 발생할 수 있음. 이 문제를 해결하기 위해 아래의 두 방법이 존재.
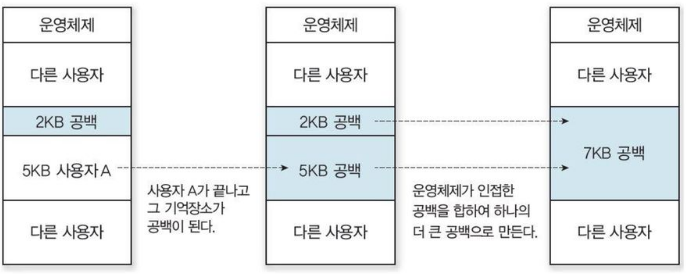
- 메모리 통합 방법(Coalescing holes)
- 프로세스가 메모리 사용이 끝나고 나가면 수행
- 낮은 오버헤드
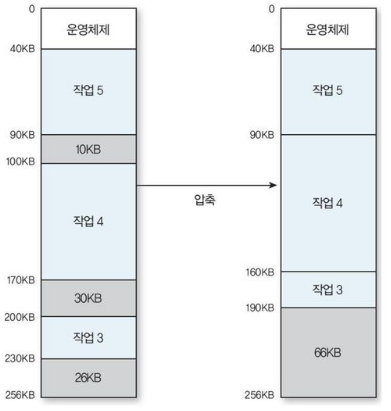
- 메모리 압축 방법
- 모든 빈 공간을 하나로 통합
- 메모리 압축은 주소변환(논리주소->물리주소)이 정적이고, 컴파일이나 적재할 때 바인딩이 실행되면 물리주소가 고정되기 때문에 압축을 수행할 수 없다.
- 압축하는 동안 시스템은 모든 일을 중지해야함.(실시간, 대화형 시스템에 부적합)
- 압축 작업을 자주해야해서 자원소모가 큼.
버디 시스템
큰 버퍼를 반복적으로 이등분하여 작은 버퍼(버디)들을 만들어 할당하고, 가능한 인접한 빈 버퍼들을 합치는 과정을 반복하는 시스템.
고정 분할 방법, 가변 분할 방법의 단점을 해결하기 위해 개발.
최근 운영체제들은 연속 메모리 할당을 선호하지 않지만, 유닉스의 커널 메모리나 병렬 처리 시스템에서는 사용됨.
분산 메모리 할당(Non-continuous allocation)
- 페이징 시스템
- 세그먼트 시스템
- 하이브리드리 페이징/세그먼트 시스템
분산 메모리 할당에서의 주소 매핑
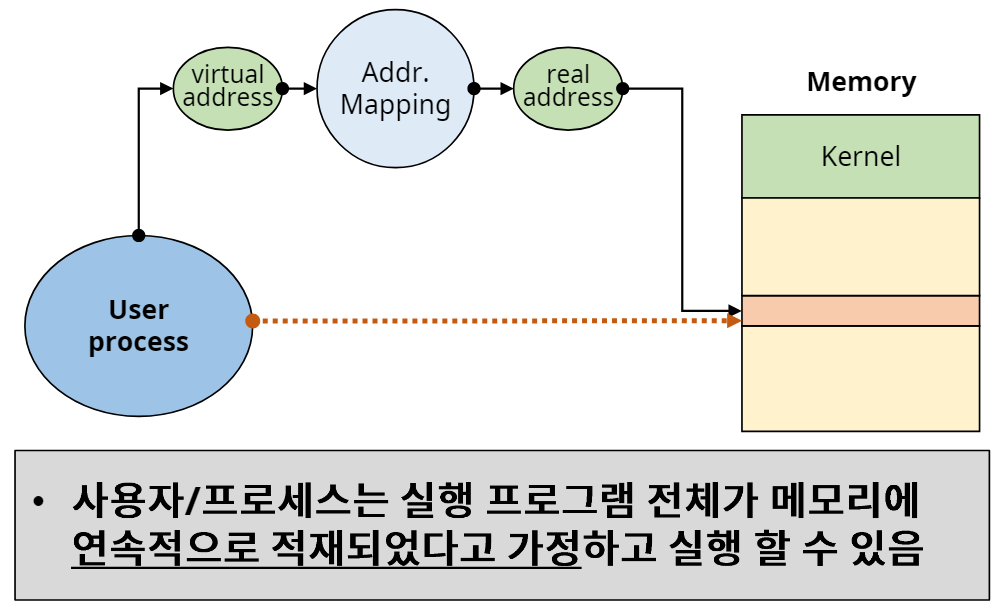
실제로 프로그램은 연속된 메모리에 할당된다고 가정하고 만들어진다. 하지만 분산 메모리에서는 프로세스가 메모리에 분산되어 올라가기 때문에 가상주소를 실제 메모리 주소로 매핑을 해야한다.
- 가상주소(Virtual address) = 논리주소(Logical address)
연속된 메모리 할당을 한다고 가정한 주소. - 실제주소(Real address) = 절대주소
실제 메모리에 적재된 주소.
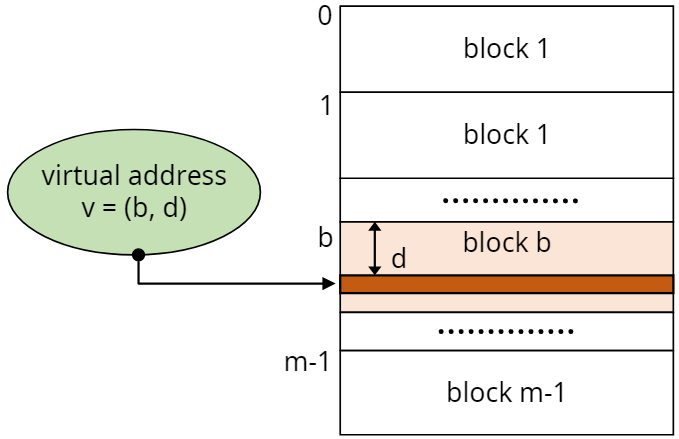
가상주소에서 실제주소로 매핑하는 방법은 block mapping을 사용한다.
- block mapping
사용자 프로그램을 block 단위로 메모리와 매핑해서 사용한다.
가상주소는b값과d값을 가지는데b는 블럭의 넘버를d는 해당 블럭의 시작점에서 떨어져있는 값을 나타낸다.
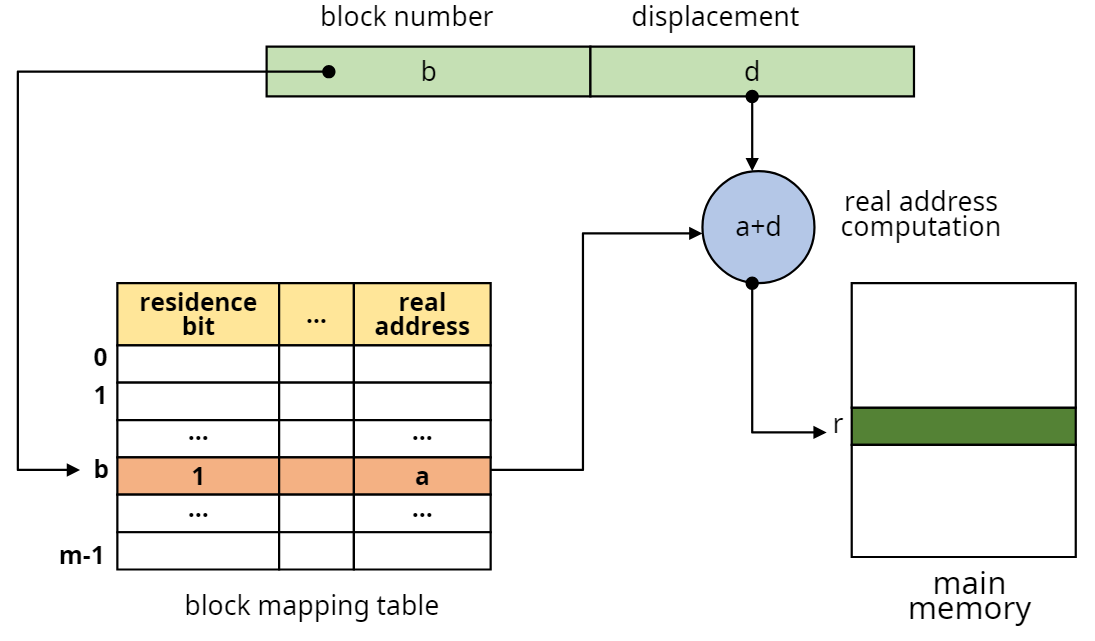
- block map table(BMT)
매핑된 주소를 관리하는 테이블이다. 이 테이블에 적힌 정보를 보고 가상주소를 실제주소와 매핑할 수 있다. 해당 테이블은 커널공간에 있으며, 프로세스마다 하나씩 가지고 있다. 테이블 안에는 해당 프로세스가 가지는블럭 번호와residence bit,실제주소가 기록되어 있다.
residence bit은 해당 블록이 메모리에 적재되었는지 여부(0:적재안됨,1:적재됨)가 담겨있다. - 매핑과정
- 프로세스 BMT에 접근
- BMT에서 블럭넘버(b)에 대한 항목을 찾음
- residence bit 검사
3-1. residence bit = 0이면, swap device(disk=가상메모리)에서 해당 블록을 메모리로 가져 와서 residence bit를 1로 바꾼 후 3-2를 수행
3-2. residence bit =1이면, BMT에서 b에 대한 실제 주소 값을 확인(a) - 실제 주소 계산(a+d)
- 실제 주소로 메모리 접근
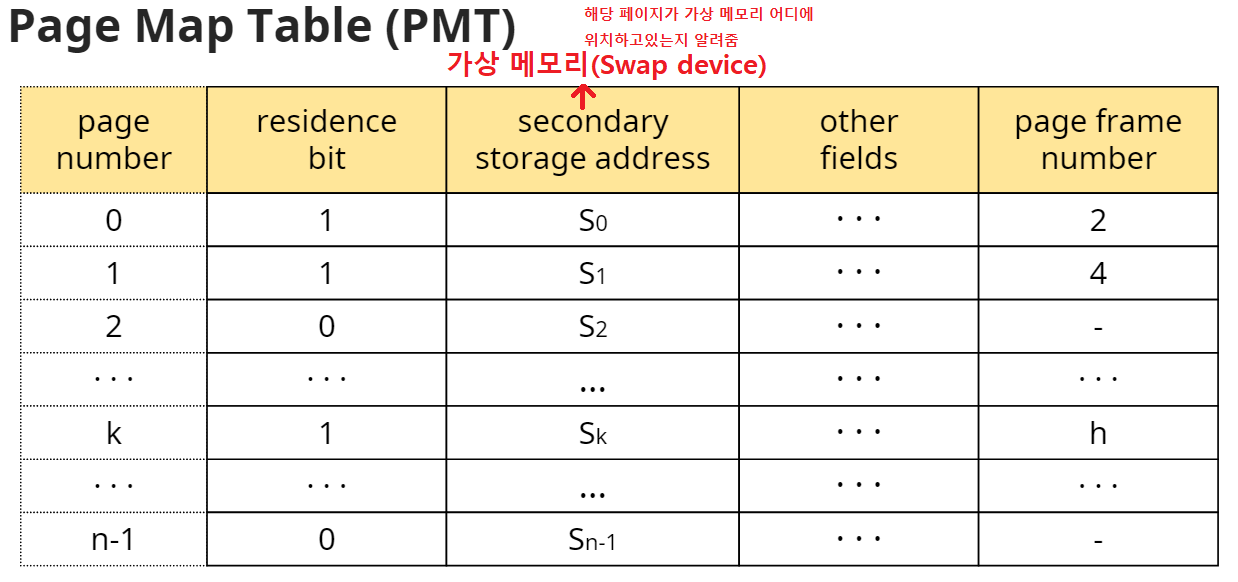
페이징
앞서 살펴본 주소 매핑에서 정의한 블럭을 페이지라고 한다. 페이지는 프로세스를 동일한 크기로 나눈 영역이라면 페이지 프레임은 메모리를 페이지와 동일한 크기로 나눈 영역을 말한다.
- 특징
- 크기에 따른 분할이기때문에 논리적 분할이 아니다. 그렇기때문에 페이지 공유 및 보호 과정이 복잡하다.(크기에 따라 분할했기때문에 하나의 함수가 여러 페이지에 조각나있을 수 있기때문)
- 단순히 크기에 따라 분할했기에 구현하기 쉽고 효율적이다.
- 페이지와 페이지 프레임이 동일한 크기이기때문에 외부 단편화가 일어나지 않는다. 다만 프로세스의 마지막 페이지의 경우 남은 부분을 하나의 페이지 만들기때문에 페이지 프레임보다 작을 수 있다. 이 경우에는 내부 단편화가 발생한다.
페이징 시스템에서의 주소 매핑방법은 블럭 주소 매핑 방법과 유사하다. 블럭넘버b와 d 대신 페이지넘버p와 d를 가지고, BMT 대신 PMT(Page Map Table)를 사용한다.
자세한 매핑 매커니즘은 아래와 같이 크게 3개로 나뉜다.
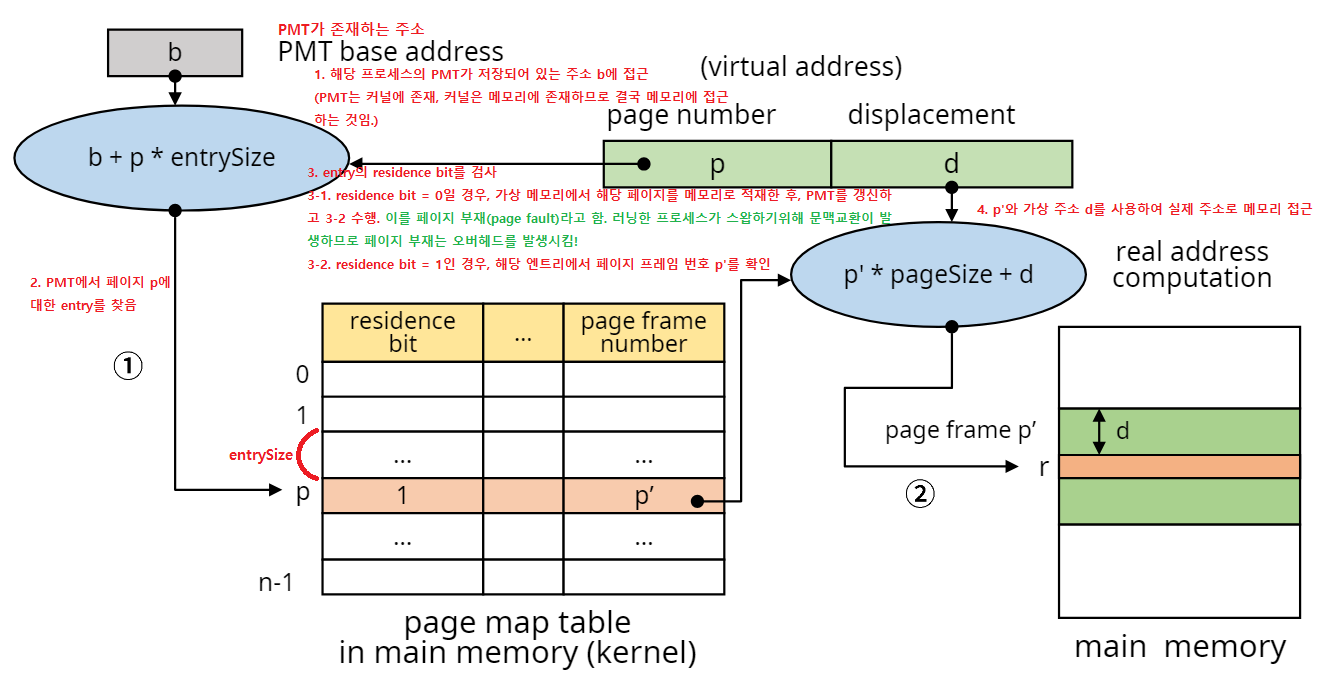
- 직접사상(Direct mapping)
block mapping과 매우 유사하다. PMT를 커널 안에 저장하기때문에 주소 매핑과정에서 메모리 접근 횟수가 2배(2번)되어 성능 저하 문제가 있다. (PMT는 커널안에, 커널은 메모리안에 있기때문에)
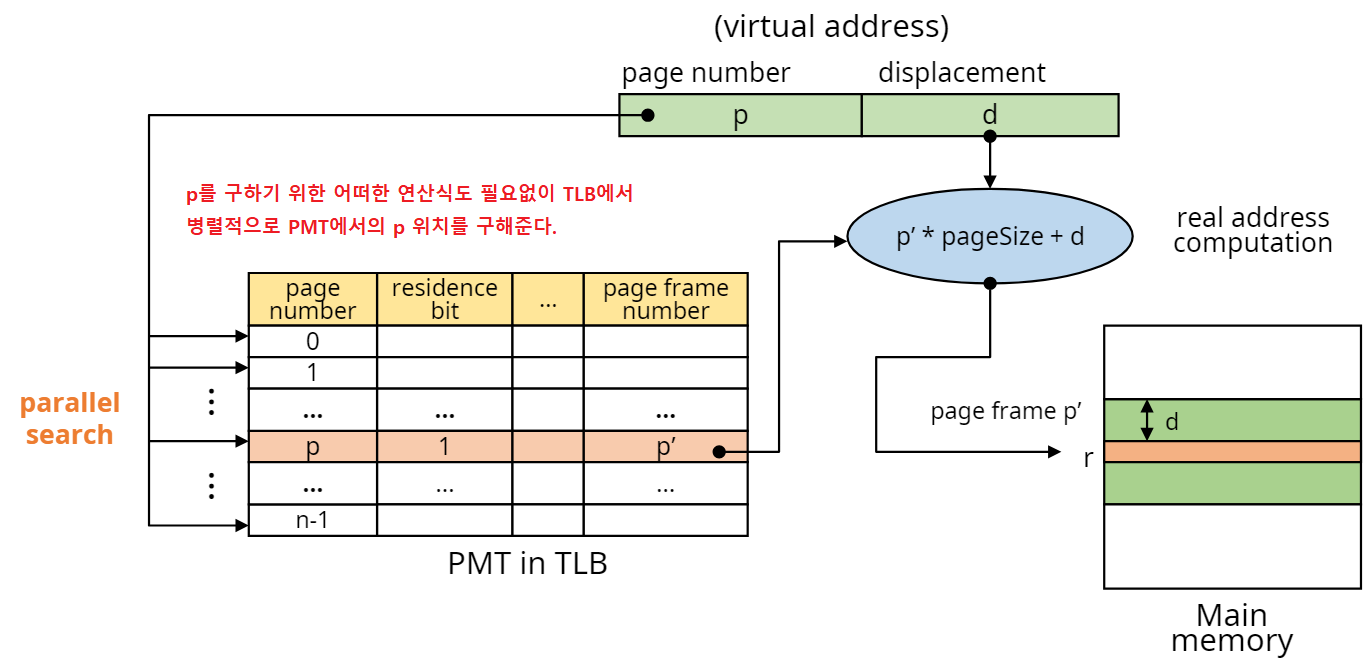
- 연관사상(Associative mapping)
커널이 아닌 TLB(Translation Look-aside Buffer)에 PMT 적재를 한다. 그렇기때문에 직접사상에서 메모리 접근 횟수 문제를 해결할 수 있다. TLB는 PMT를 탐색하기위한 전용 하드웨어로 PMT를 병렬적으로 탐색하기때문에 매우 빠른 속도를 가진다. 하지만 TLB는 굉장히 비싼 하드웨어라는 문제가 있다.
- 하이브리드 직접/연관 매핑
직접사상과 연관사상을 혼합하여 사용한 기법이다. 작은 크기의 TLB를 사용하여 하드웨어의 비용은 줄이고 PMT 중 일부 엔트리만(최근 사용된 페이지들) TLB에 저장한다. 즉, 캐시에서 보았던 지역성(Locality)를 활용한 방식이다. TLB에 페이지가 저장되어있는 경우 연관사상 방법을 수행하고 TLB에 저장되어 있지 않은 경우는 직접사상 방법을 사용한뒤 해당 PMT 엔트리를 TLB에 적재한다.
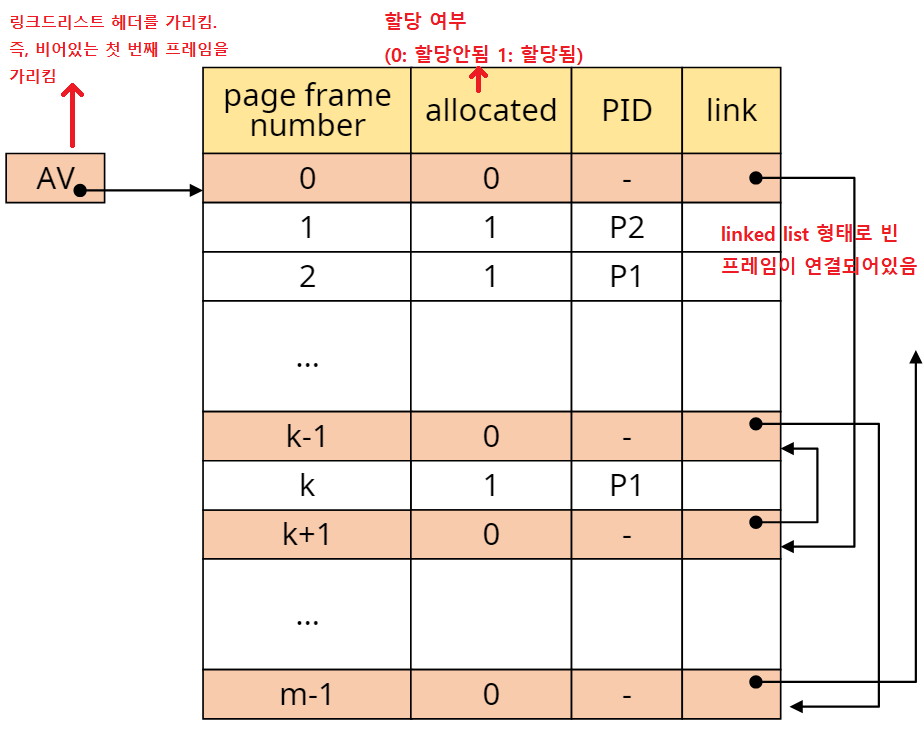
페이징 시스템에서는 메모리를 페이지와 같은 크기로 분할한 페이지 프레임을 사용한다고 했다. 프로세스를 매핑할 때 비어있는 메모리를 알고 있어야 매핑이 가능하므로 비어있는 페이지 프레임을 관리하는 테이블이 있다. 이를 프레임 테이플이라고 하고 프레임당 하나의 엔트리를 갖는다.
- 프레임 테이블
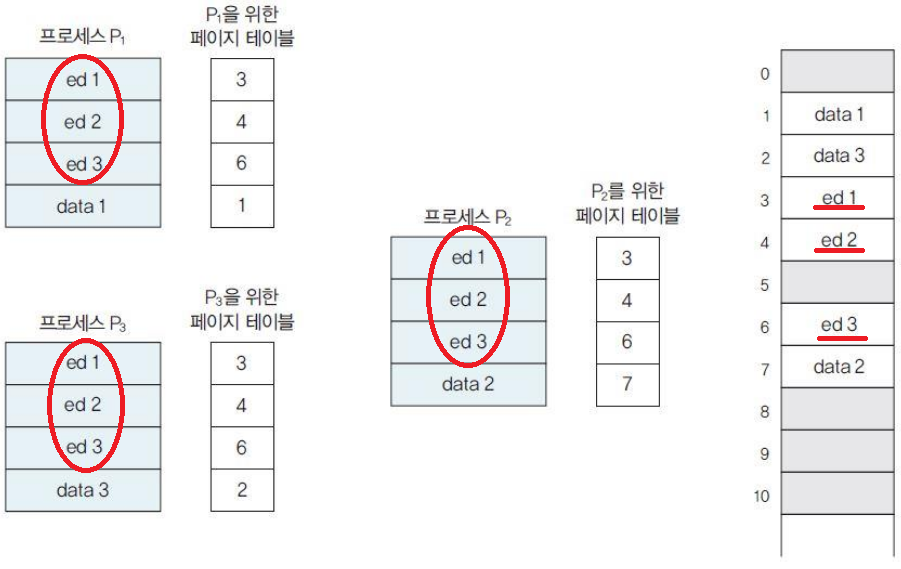
페이징 시스템에서는 여러 프로세스가 특정 페이지를 공유할 수 있다. 다만 같은 데이터에 여러 프로세스가 쓰기를 할 경우 무결성이 깨지므로 protection bit를 사용하여 데이터에 대한 프로세스 권한을 관리한다.
- 한글 프로그램을 3개 띄우고 사용하는 경우
같은 프로그램으로 코드가 겹치는 부분이 있으니 이 부분을 메모리상에서 공유한다.
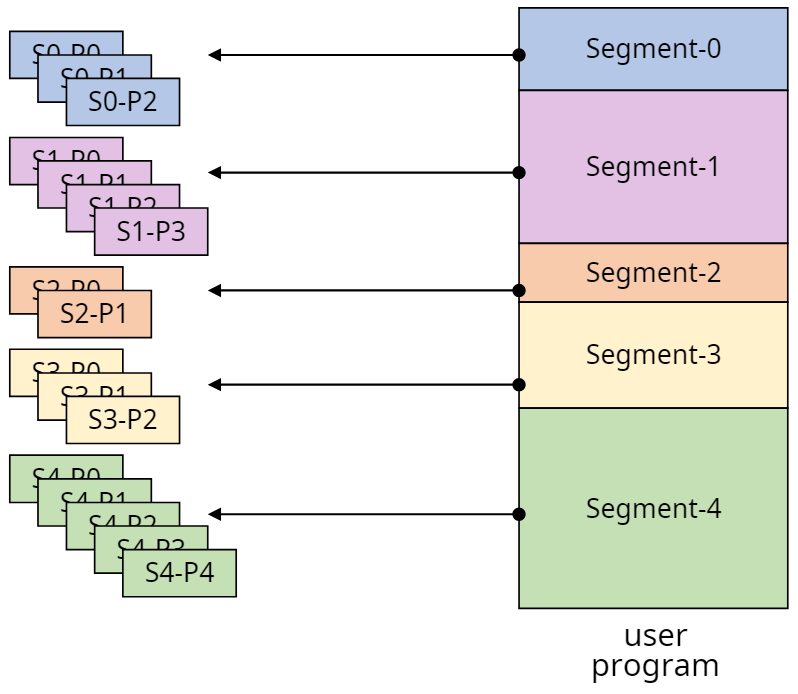
세그먼테이션
세그먼테이션은 프로그램을 논리적 블럭으로 분할(stack, heap, main code 등)하고 이 블럭을 세그먼트(segment)라고 한다.
- 특징
- 페이징 시스템은 논리적 분할이 아니여서 페이지를 공유 및 보호를 할 때 어려움이 있었다. 그 점을 보완한 것이 세그먼테이션 시스템이다.
- 블럭의 크기는 서로 다를 수 있고, 메모리도 미리 분할 하지 않는다(VPM과 유사).
- 프로그램을 논리적으로 분할하기 때문에 내부 단편화는 발생하지 않으나 외부 단편화는 발생할 수 있다.
- 논리적으로 나누었기 때문에 페이징 시스템에 비해 오버헤드가 큼
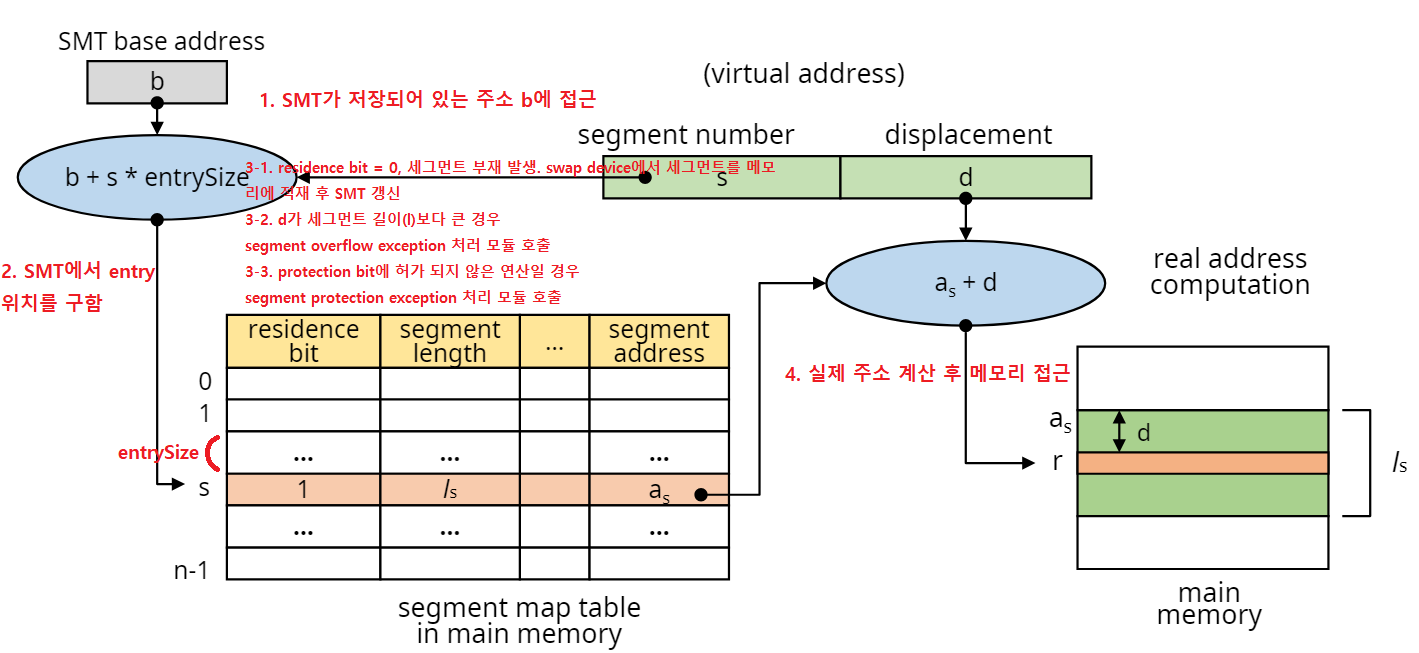
주소를 매핑하는 매커니즘은 페이징시스템과 유사하다. p와 d 대신 s와 d를 사용하고, PMT 대신 SMT를 사용한다. 자세한 메커니즘은 앞서 살펴본 페이징처럼 직접사상과 연관사상 하이브리드 등이 있다.
- SMT
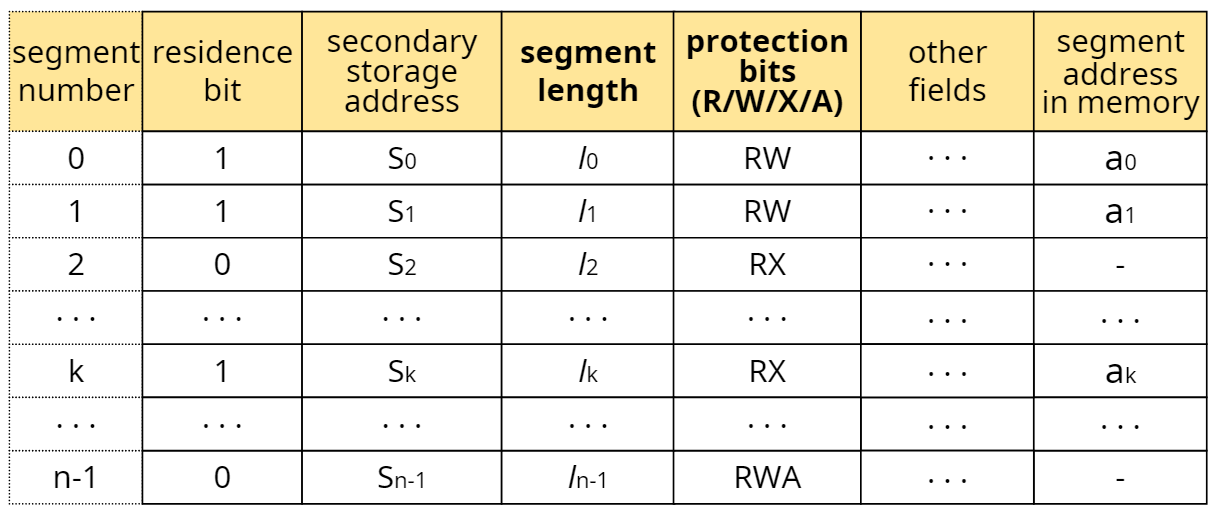
- 매핑과정(직접사상의 경우)
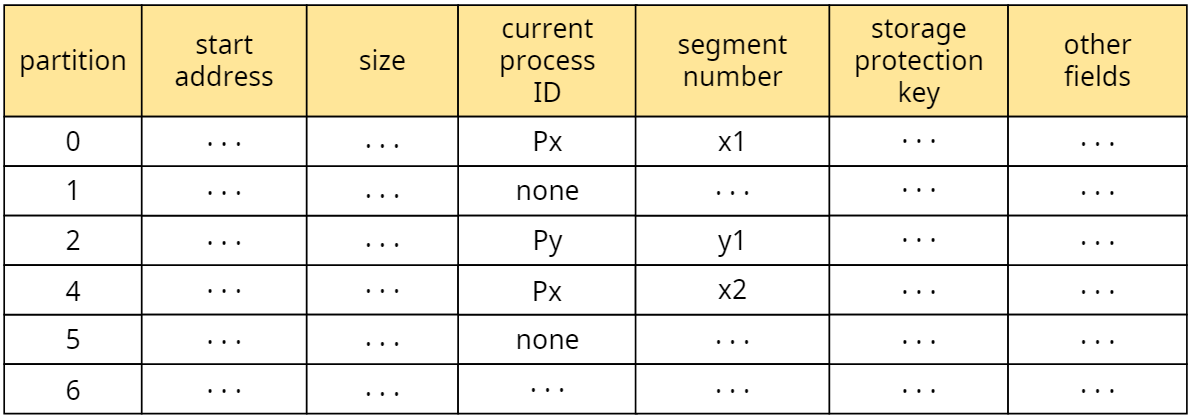
페이징 시스템에서의 프레임 테이블처럼 세그먼테이션에서도 비슷한 파티션 테이블로 메모리를 관리한다.
- 파티션 테이블
페이징 시스템 VS 세그먼테이션 시스템

하이브리드 페이징/세그먼테이션 시스템
- 페이징 + 세그먼트의 장점 결합
- 프로그램을 논리 단위의 세그먼트로 분할 후 각 세그먼트를 고정된 크기의 페이지로 분할.
- 페이지 단위로 메모리에 적재
- 전체 테이블의 수가 증가(PMT, SMT 둘다 가짐)하여 메모리 소모가 큼. 매핑과정 또한 복잡함.