
❗️ 계속해서 업데이트 될 예정...
잘못된 부분이 있다면 알려주세요 🙏
정렬
정렬
값을 특정 순서대로 넣는 알고리즘.
보통 숫자식 순서(Numerical Order)와 사전식 순서(Lexicographical Order)로 정렬한다.
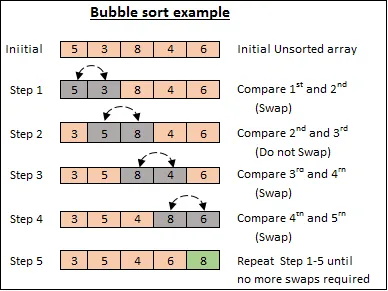
버블 정렬
바로 옆에 있는 값과 비교해서 크면 오른쪽, 작으면 왼쪽으로 정렬. 배열 전체를 모두 살펴보는 것이기 때문에 시간복잡도는 항상 O(n**2)이다.
다른 알고리즘에 비해 매우 비효율적인 알고리즘.
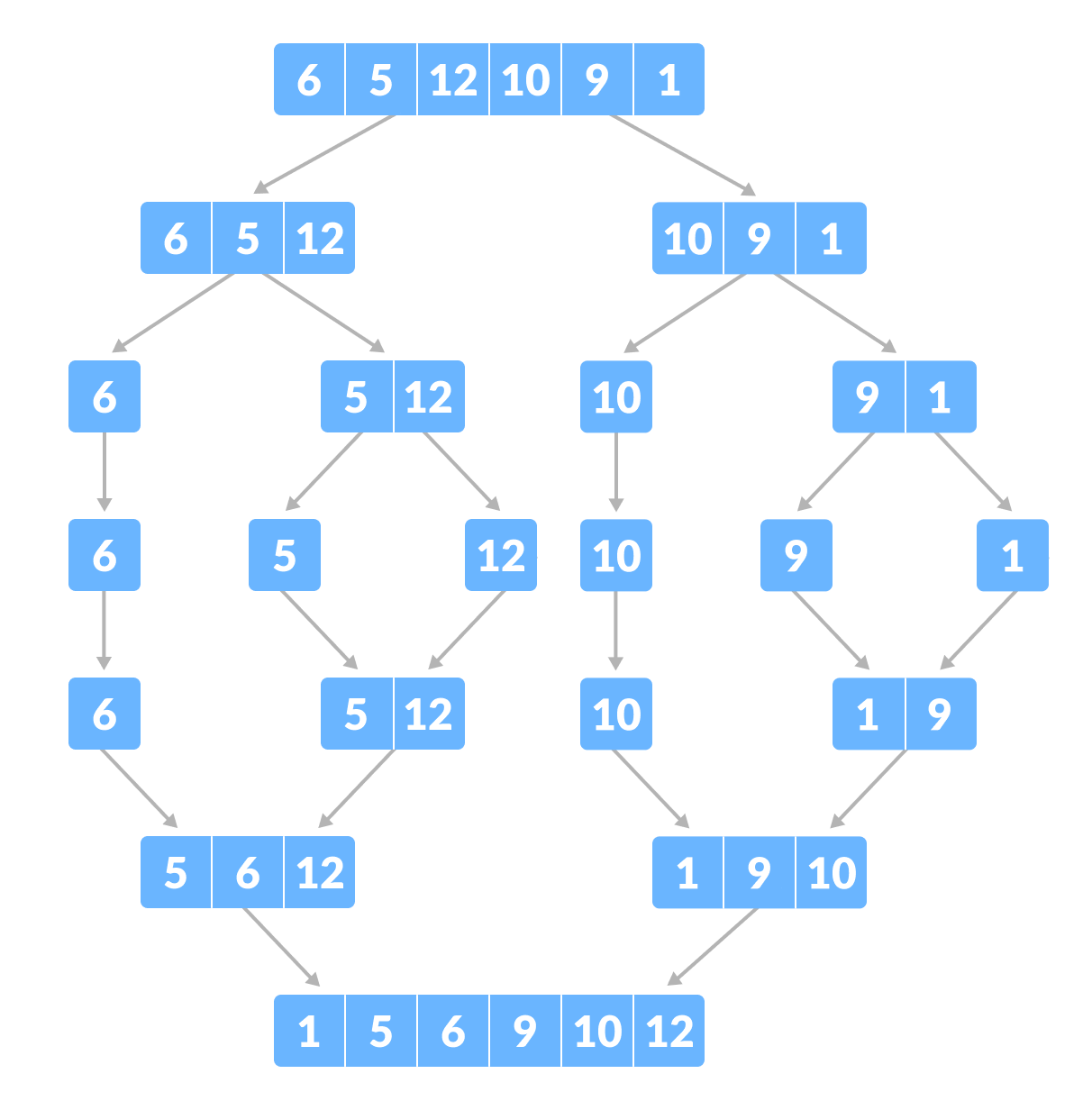
병합 정렬
대부분의 경우 퀵 정렬보다 느리지만 일정한 실행속도(항상 O(nlogn)뿐만 아니라 안정 정렬이라는 점에서 여전히 많이 쓰인다.
다만, 별도의 저장공간에 계속 데이터를 저장하므로 공간이 부족할 경우 퀵 정렬을 이용해야한다.
분할한 후, 다시 정렬하며 합치는 분할 정복 알고리즘이다.
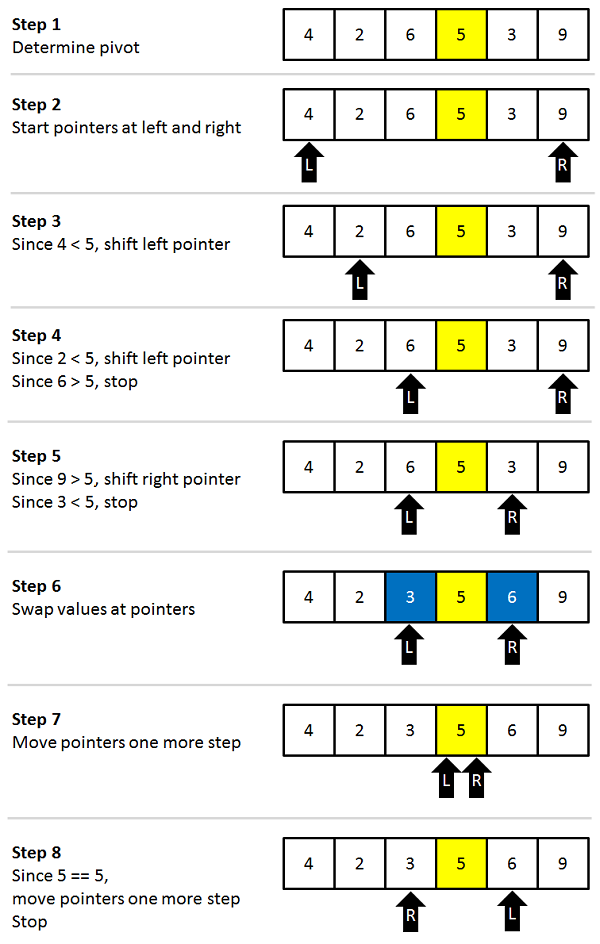
퀵 정렬
피벗(기준점)을 정해 피벗보다 작으면 왼쪽, 크면 오른쪽과 같은 방식으로 파티셔닝하면서 쪼개 나가는 알고리즘이다.
매우 빠르고 효율적인(평균 O(nlogn)) 알고리즘이지만 최악의 경우 O(n**2)가 된다. 이미 정렬된 배열이 들어 올 경우 파티셔닝이 이뤄지지 않기 때문에 버블 정렬과 다를 바 없어진다.
병합 정렬처럼 분할한 후, 다시 정렬하며 합치는 분할 정복 알고리즘이다.
팀소트(Timsort)
- 파이썬이 사용하는 정렬 알고리즘
- C로 구현한 알고리즘
- '실제 데이터는 대부분 이미 정렬되어 있을 것이다' 라고 가정함
- 병합 + 삽입 정렬을 합침
정렬 풀이
문제 2751
✏️ 내가 작성한 코드
import sys
N = int(input())
s = list(map(int,sys.stdin.readlines()))
s.sort()
for i in s: print(i)readline
한 줄씩 읽기
readlines
각 줄을 리스트의 요소로 받음
read
모든 줄을 한번에 읽음
문제 11650
✏️ 내가 작성한 코드
import sys
N = int(input())
point_xy = []
for _ in range(N):
x, y = map(int, sys.stdin.readline().split())
point_xy.append([x, y])
sorted_xy = sorted(point_xy)
for i in sorted_xy:
print(i[0],i[1])sorted
python 에서 sorted는 새로운 리스트를 만들어 정렬해주는데 이때 정렬 기준을 사용자가 직접 정할 수 있다. 디폴트는 이번 문제처럼[[a,b],[c,d],[e,f]]에 사용하면 첫번째 요소로 한번 정렬한 뒤 요소 값이 같다면 그 다음 요소로 정렬을 시도한다.
Reference
문제 11651
✏️ 내가 작성한 코드
import sys
N = int(input())
point_yx = []
for _ in range(N):
x, y = map(int, sys.stdin.readline().split())
point_yx.append([y, x])
sorted_yx = sorted(point_yx)
for i in sorted_yx:
print(i[1],i[0])위에 문제에서 x와 y의 자리만 바꿔주면 된다.
문제 11651
✏️ 내가 작성한 코드
import sys
from operator import itemgetter
N = int(input())
member = []
for _ in range(N):
age, name = sys.stdin.readline().split()
member.append([int(age), name])
sorted_mem = sorted(member, key=itemgetter(0))
for i in sorted_mem:
print(i[0],i[1])파이썬에서 정렬 함수에는
key라는 매개 변수를 갖고있는데, 이를operator모듈을 이용하면 다중 정렬일때 어떤 값을 기준으로 정렬할 것인지 정할 수 있다.
위 문제에서는age를 기준으로 정렬을 시도하는데 조건을 보면나이가 같으면 먼저 가입한 사람이 앞에 오는 순서로 정렬하라고 한다. 파이썬에서의 정렬은 원래 순서를 보장해주므로 가입한 순서를 보장해준다.
Reference
문제 10825
✏️ 내가 작성한 코드
import sys
N = int(input())
result = []
for _ in range(N):
name, kor, eng, math = sys.stdin.readline().split()
result.append([name, kor, eng, math])
result.sort(key = lambda x: (-int(x[1]), int(x[2]), -int(x[3]), x[0]))
for i in result:
print(i[0])
sorted에서 사용 가능한 매개변수는sort에서도 사용 가능하다. 또한 다중 조건에 경우itemgetter를 사용해도 되지만, 이 문제 같은 경우에는 조건 마다 감소, 증가가 다르므로lambda표현식을 이용했다.
import sys
from operator import itemgetter
N = int(input())
result = []
for _ in range(N):
name, kor, eng, math = sys.stdin.readline().split()
result.append([name, 100-int(kor), int(eng), 100-int(math)])
result.sort(key = itemgetter(1,2,3,0))
for i in result:
print(i[0])물론 위 방식으로
itemgetter를 이용할 수도 있다.
문제 10989
✏️ 내가 작성한 코드
import sys
N = int(input())
arr = [0]*10001
for _ in range(N):
arr[int(sys.stdin.readline())] +=1
for i in range(10001):
if arr[i] != 0:
for _ in range(arr[i]):
print(i)메모리 초과 문제를 해결하는게 관건인 문제다.
readlines로 받아도 리스트가 두번 생겨나는 경우가 되어 메모리 초과가 난다.
해결 방법은 위 코드처럼 리스트의 인덱스를 input 값으로 보고 몇 번 반복하는지만 리스트의 해당 인덱스에 기록하면 된다.
문제 11652
✏️ 내가 작성한 코드
import sys
from collections import Counter
N = int(input())
card = list(map(int, sys.stdin.readlines()))
cnt = Counter(sorted(card))
print(cnt.most_common(1)[0][0])최대한
Counter에most_common을 활용해서 풀고 싶었다.
card를 먼저 정렬을 해서 조건에가장 많이 가지고 있는 정수가 여러 가지라면, 작은 것을 출력을 해결했다.
그 후로는 간단히most_common매개 변수를 이용하면 된다. 참고로most_common는 값이 같을 경우 먼저 들어온 값을 우선 시 한다.
Reference
문제 11004
✏️ 내가 작성한 코드
N, K= map(int, input().split())
arr = list(map(int, input().split()))
arr.sort()
print(arr[K-1])