
❗️ 계속해서 업데이트 될 예정...
잘못된 부분이 있다면 알려주세요 🙏
이진 검색
이진 검색(Binary Search)
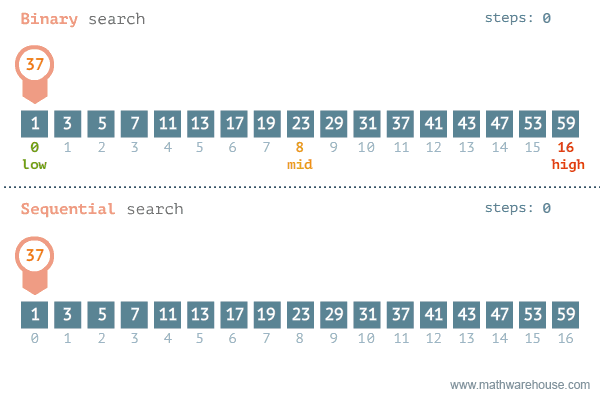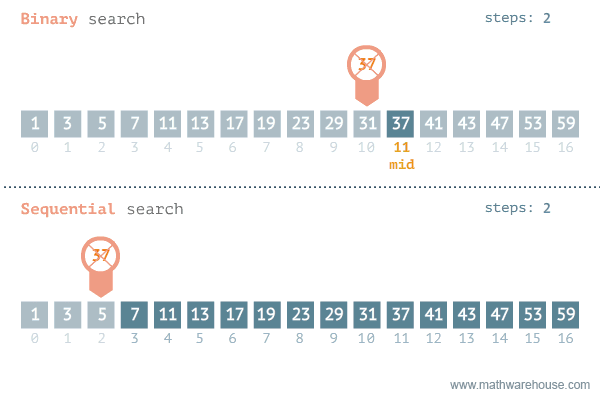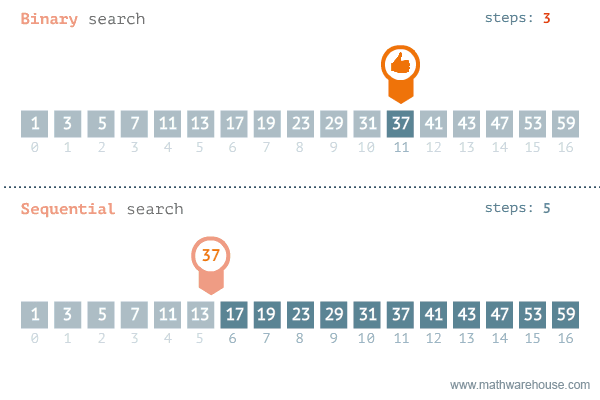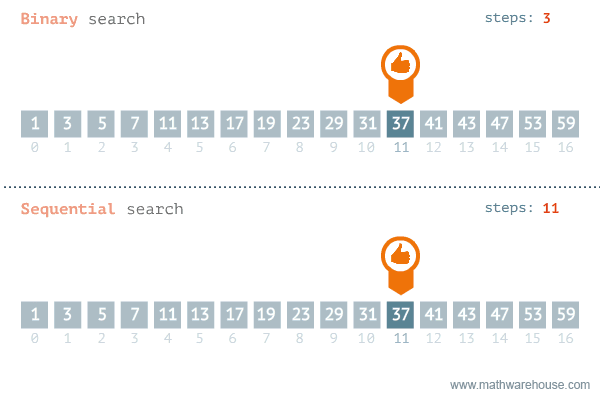
정렬된 배열에서 타겟을 찾는 검색 알고리즘.
시간 복잡도는 O(log n)이다.
흔히 리스트에 들어있는 값의 인덱스를 구할 때 index() 메소드를 사용한다. 하지만 이 메소드는 앞에서부터 하나씩 찾아가는 방식으로 시간 복잡도가 O(n)이다. 찾는 값이 앞쪽에 있을 때는 index()가 빠르겠지만 뒤쪽에 있으면 항상 일정한 시간 복잡도를 갖는 이진 검색 O(log n)이 빠르다.
파이썬에서는 이진 검색을 구해주는 모듈 bisect이 존재한다.
bisect
정렬된 리스트에 새로운 값을 삽입 후에 다시 정렬할 필요 없도록, 새로운 값을 어느 인덱스에 집어넣어야 정렬 상태를 유지하는지 알려준다.
bisect.bisect_left(a, x, lo=0, hi=len(a))
리스트a에 새로운 값x를 삽입할 위치를 찾는다. 기본적으로 전체 리스트a에서 삽일 될 위치를 찾지만, 매개변수lo와hi를 넣어주면 리스트a의 범위를 지정할 수 있다. 만약,a에x가 있으면 기존x값 왼쪽에 삽입된다.bisect.bisect_right(a, x, lo=0, hi=len(a))
bisect.bisect(a, x, lo=0, hi=len(a))
기본적인 부분은bisect.bisect_left과 같지만, 새로운 값을 삽입하는 위치가 오른쪽이다.
이진 검색 문제 풀이
문제 1920
✏️ 내가 작성한 코드
import bisect
N = int(input())
A = list(map(int, input().split()))
M = int(input())
arr = list(map(int, input().split()))
A.sort()
for i in arr:
index = bisect.bisect_left(A, i)
if index < N and A[index] == i:
print(1)
else:
print(0)시간 제한이 있기때문에
bisect모듈을 사용하면 쉽게 풀린다.
💡 흥미로운 코드
import sys
input = sys.stdin.readline
N = int(input())
A = set(input().split())
M = int(input())
result = ''
for i in input().split():
result += '1\n' if i in A else '0\n'
print(result)
input().split()을 하면 자동으로 리스트에 값이 들어간다. 단지, 요소가str로 들어갈뿐이다.
이 문제에서는 요소가str이든int이든 상관 없기 때문에 굳이 list로 바꿔줄 필요 없다.
그렇기때문에for i in input().split()처럼 따로input().split()을 할당 안 해줘도 된다.
문제 2805
✏️ 내가 작성한 코드
N, M = map(int, input().split())
height = list(map(int, input().split()))
start, end, result = 0, max(height), 0
while start <= end:
mid = start + (end-start)//2 # 중간값
tree = sum([i-mid for i in height if i >= mid]) # 나무 길이 - 중간 값
if M > tree: # 나무 길이가 부족하면
end = mid - 1
else: # 나무 길이가 충분하면
result = max(result, mid)
start = mid + 1
print(result)이진 검색을 할 때 흔히,
mid = (start+end)//2로 오류를 범한다. 자료형에는 항상 최대값이 존재하는데,start+end는 항상start와end보다 크게 되어 오버플로우가 발생할 수 있다.
그래서 항상mid = (start+end)//2대신에,mid = start + (end-start)//2를 사용해야한다.
