SimpleRNN, LSTM, GRU에 대해 알아보자
혼자 공부하는 머신러닝 딥러닝
혼공머신이 드디어 끝났다..!
마지막 주제인 시게열 데이터 분석에서 RNN, LSTM, GRU를 배웠는데.
원리가 잘 이해가 되지 않아서 따로 구글링하면서 공부를 해보았다.
1. Simple RNN
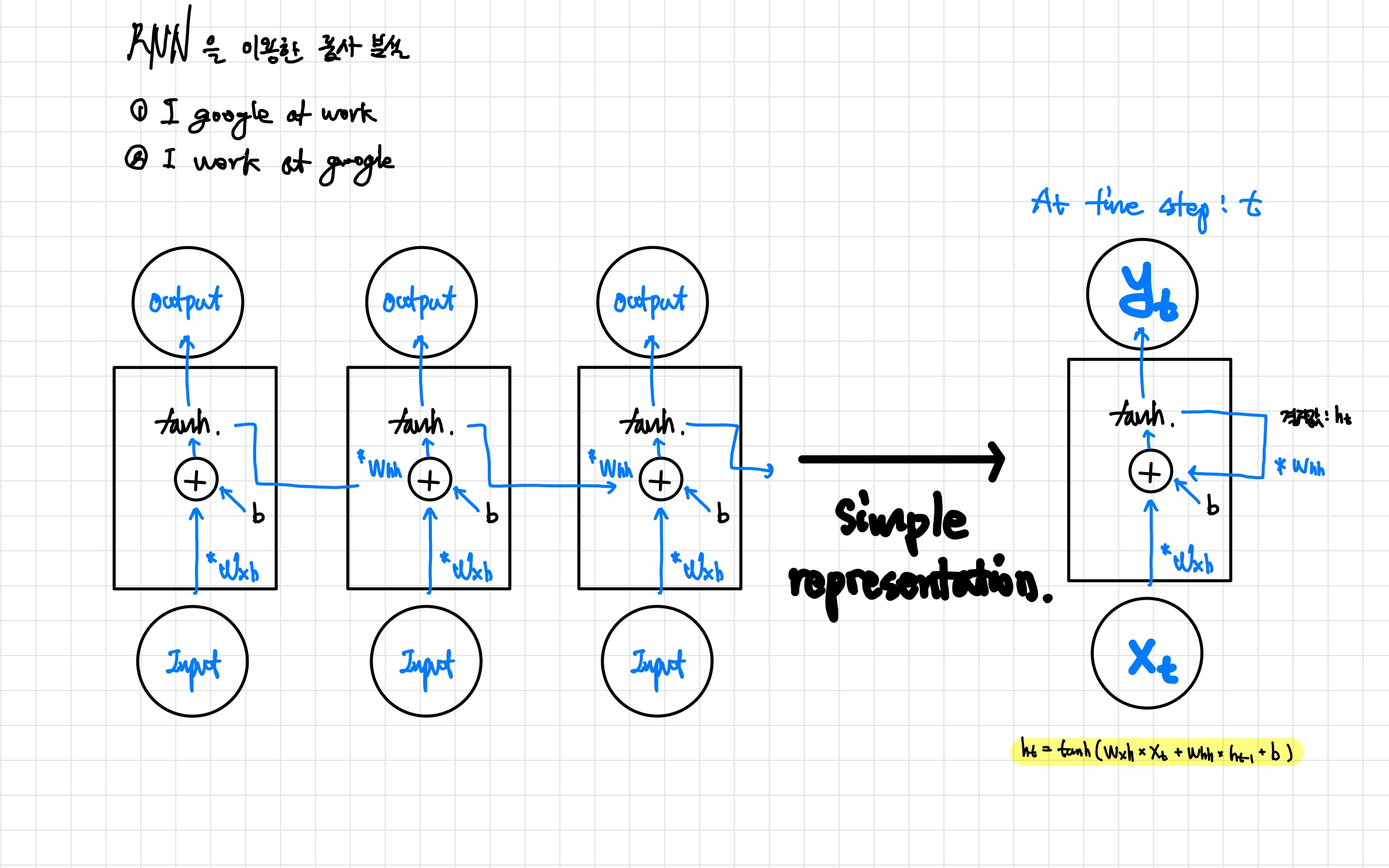
- 입력값 , 입력값에 대한 가중치 , 은닉층값에 대한 가중치 , 출력값 , 절편 b라고 할 때.
- 모든 타임 스텝에 있는 가중치 , 는 동일하다.
- 이로 인해서 gradient exploding / vanishing 문제가 나타난다.
- 가중치 W>1인 경우 → , W<1인 경우 → 0
- 입력값 , 와 편향값 를 생략한다면 다음과 같이 나타낼 수 있다.
simple RNN은 말 그대로 '심플'한 구조이다.
위의 셀이 계속 반복 되는 모델인데, 하나의 셀만 계속 반복되어 사용되기 때문에, 모델 내의 가중치 , 가 모든 셀에서 계속 사용된다.
이 때문에 모델이 학습할 데이터가 길어질 경우, gradient exploding과 gradient vanishing 문제가 나타난다.
2. LSTM
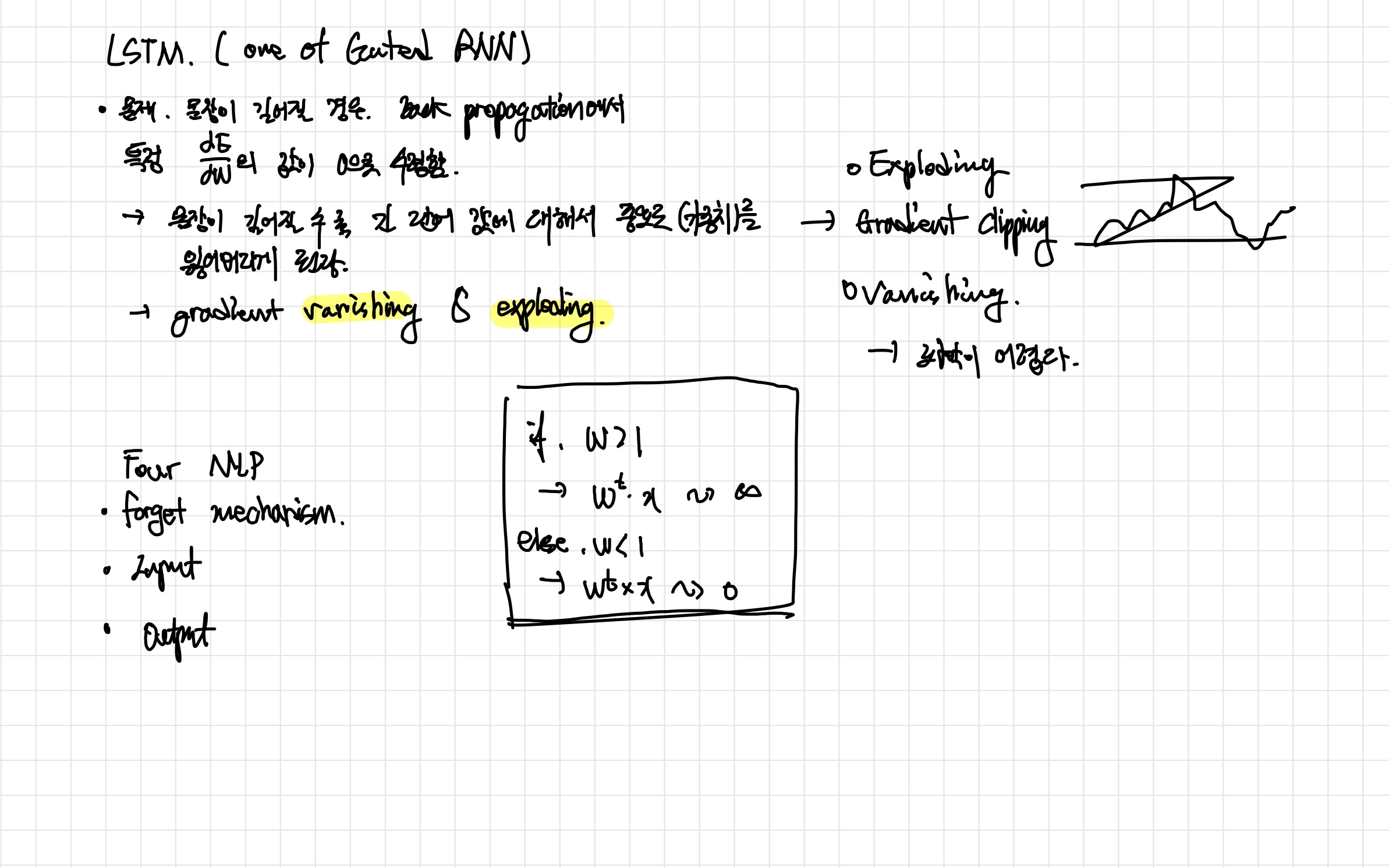
- 위에서 말한 gradient Vanishing / Exploding을 설명 한 것.
- Gradient exploding의 경우 gradient clipping을 통해 해결 할 수 있지만, gradient vanishing은 파악이 어렵다고 한다. (모델이 수렴하는 건지 vanishing 하는 건지 확실하지 X)
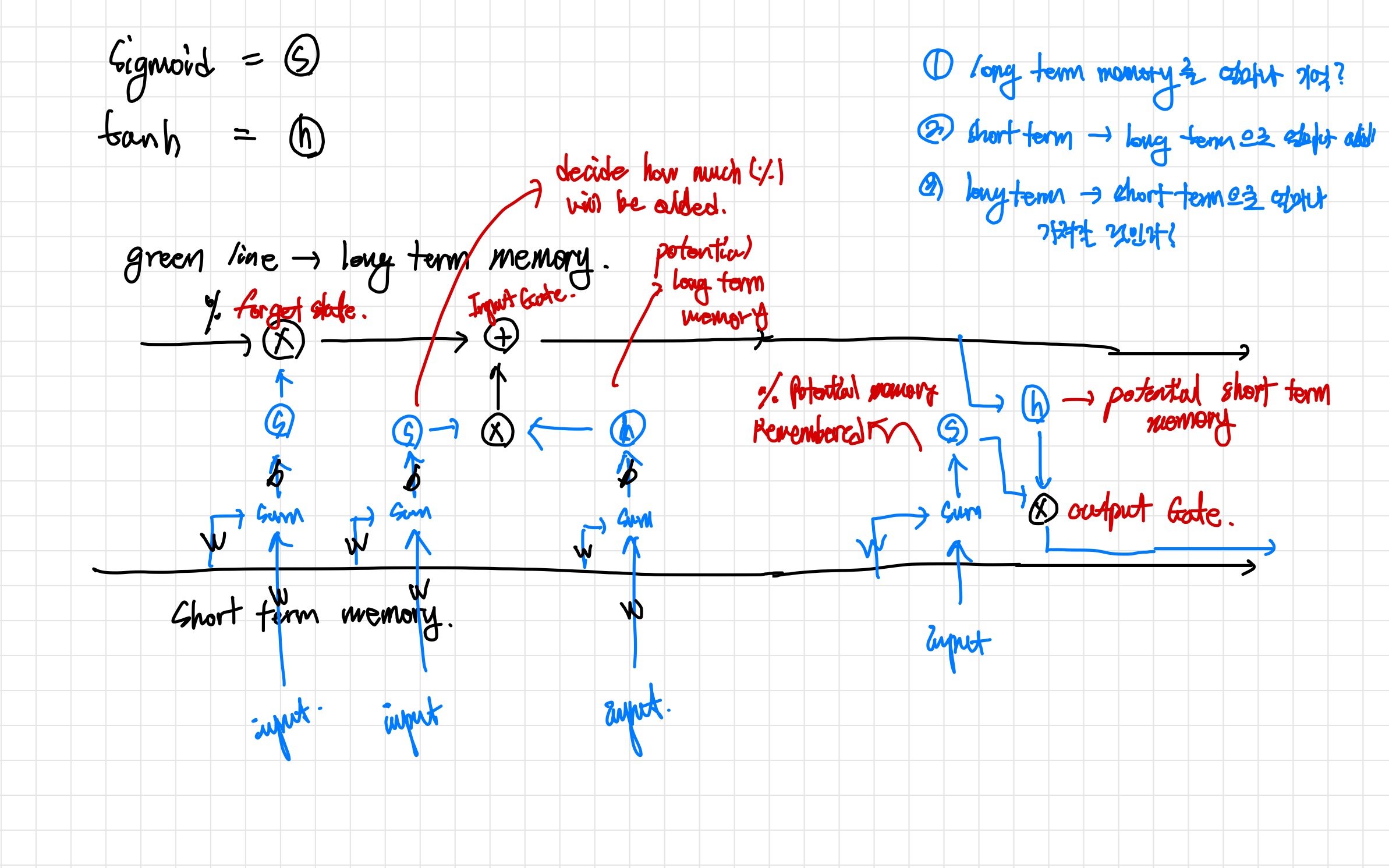
- LSTM은 3가지의 게이트를 가지고 있다.
- Forget Gate
- long term memory를 얼마나 기억할 것인지 판단. (0…1 을 곱해서 남긴다)
- 입력값: short term memory, input
- Input Gate
- short term memory를 얼마나 long term memory에 더할 것인지 구한다.
- 좌측 cell : potential long term memory를 얼마나 더할 것인지 정한다.
- 우측 cell : potential long term memory를 구한다. (tanh를 통해 -1에서 1 사이.)
- Output Gate
-
long term memory를 short term memory에 남긴다.
-
입력값: long term memory, short term memory, input
-
위쪽 cell : long term memory를 tanh에 통과 시킨 값 (그냥 long term memory)
→ potential short term memory
-
아래쪽 cell: short term memory와 input 값을 통해 potential short term memory를 얼마나 남길지 정한다.
-
- Forget Gate
- RNN과 다르게 각 게이트 마다 가중치 (W)와 편향값 (b)이 다르다.
3. GRU
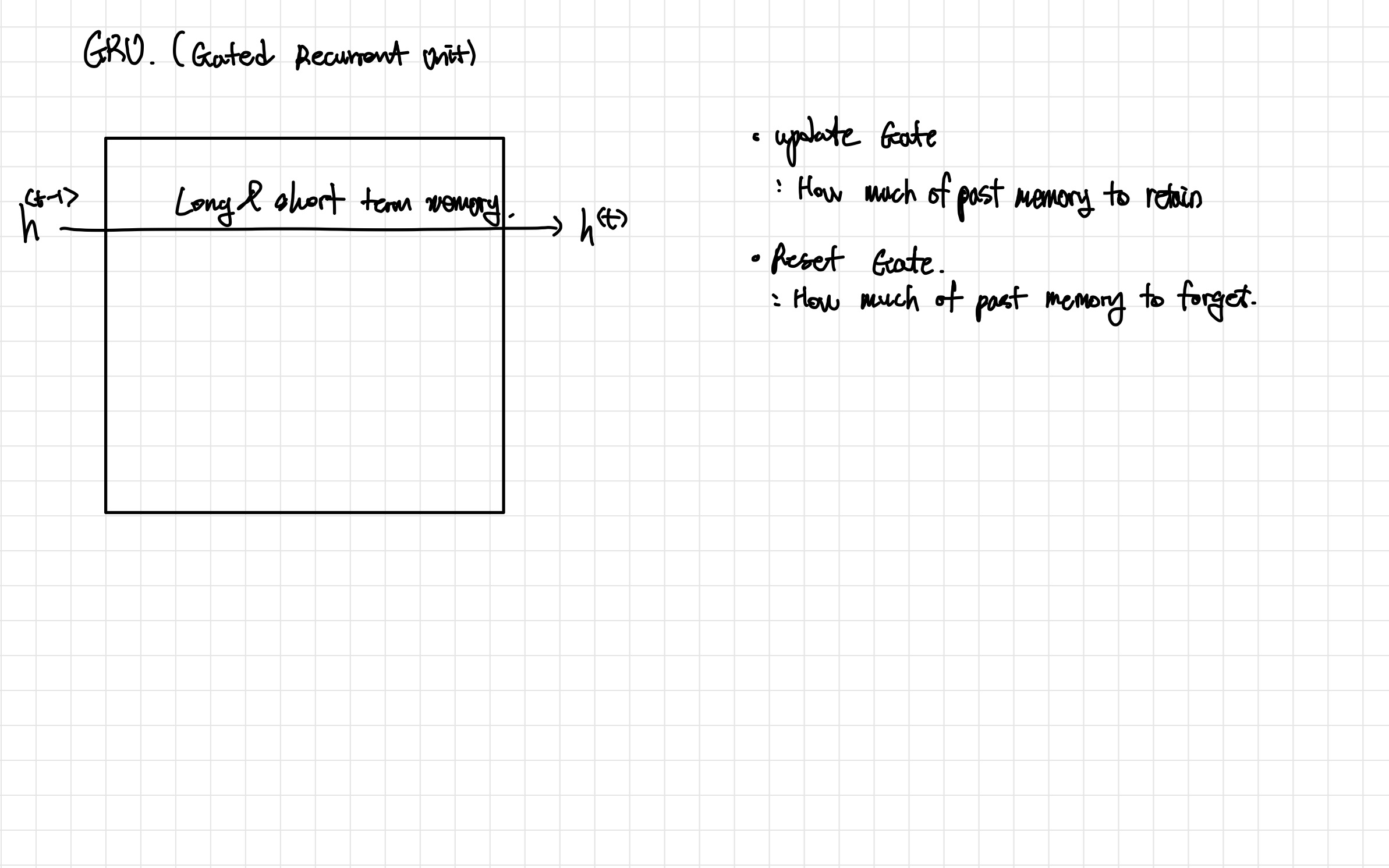
- LSTM과 다르게 short - long term memory를 같이 관리 한다.
- Update Gate와 Reset Gate를 가진다.
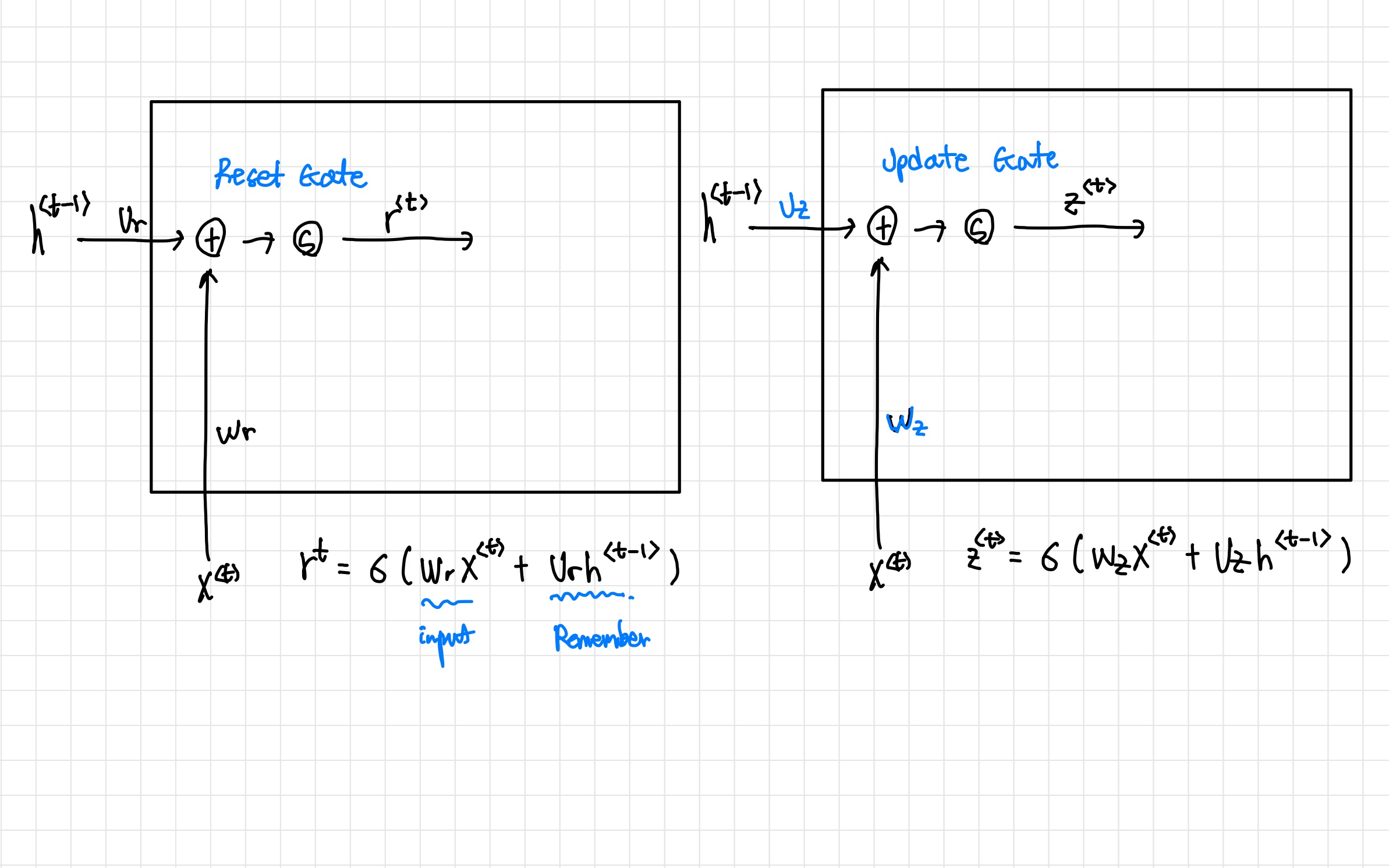
- Reset Gate와 Update Gate는 동일한 구조를 가진다.
- 저번 결과값 과 이번 입력값 에 대해 더하고, 시그모이드 함수를 적용한다.
- 과 은 가중치이다.
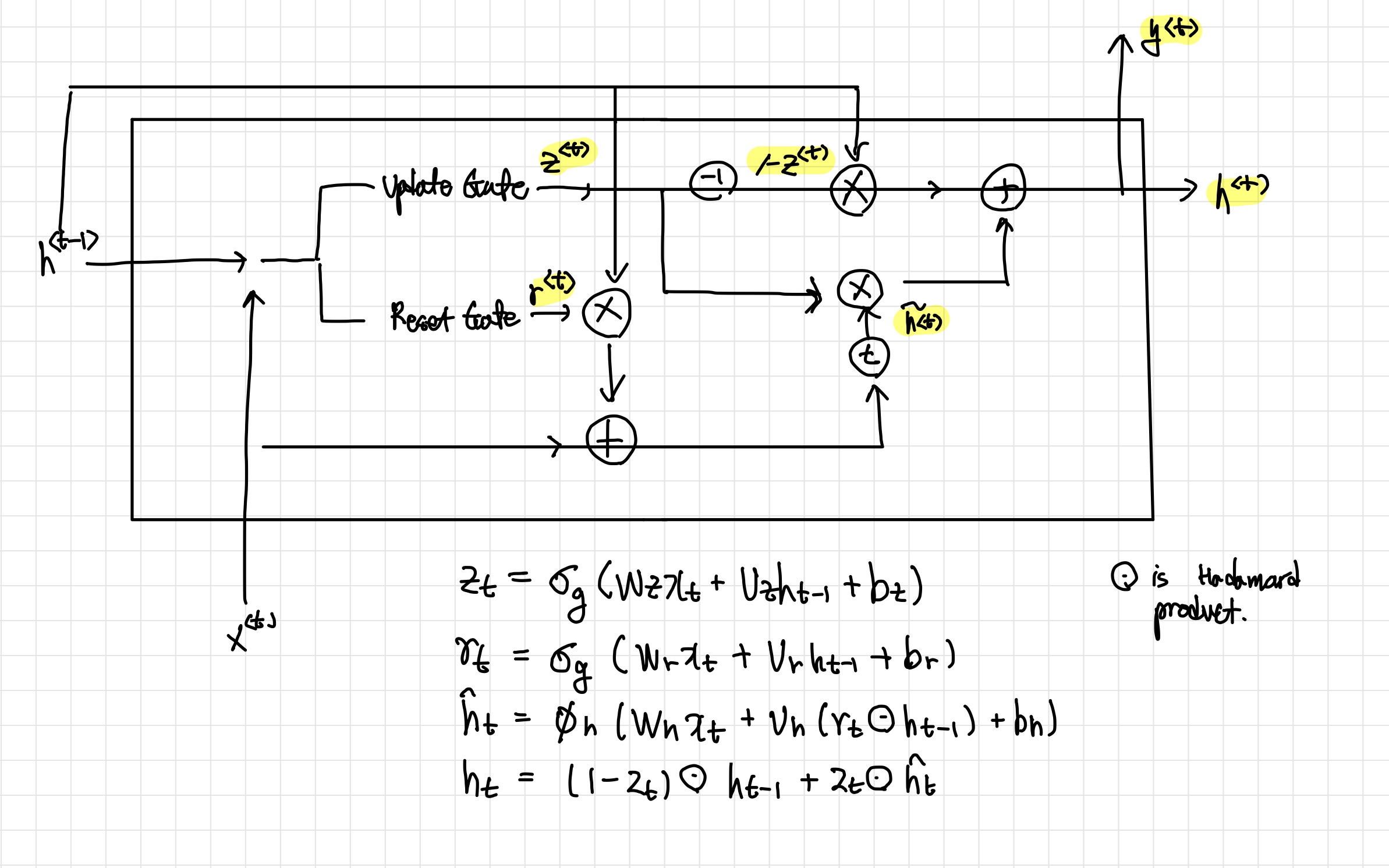
- GRU셀의 전체적인 구조.
- 앞서 update gate와 reset gate를 이용해 추가적인(다소 복잡한..) 연산을 수행한다.
참고자료
https://www.youtube.com/watch?v=YCzL96nL7j0
https://www.youtube.com/watch?v=tOuXgORsXJ4
https://www.youtube.com/watch?v=bX6GLbpw-A4

대규의 개발로그