Web Crawling 을 해보쟈!
0
1. 웹 크롤링! 정적, 동적 페이지!
소상공인분들의 입점처 주문서 수집을 자동화 할 일이 생겨버렸다!
일단은 해결 했던 사소해서 너무나 찾아다녔던, Pain point,, 공식 문서에서 설명하는 방식으로 이벤트 처리가 되지 않아서 이리저리 해매다 보니, 아래와 같이 webdriver와 script를 함께 사용하라더라, 다행히 해결!
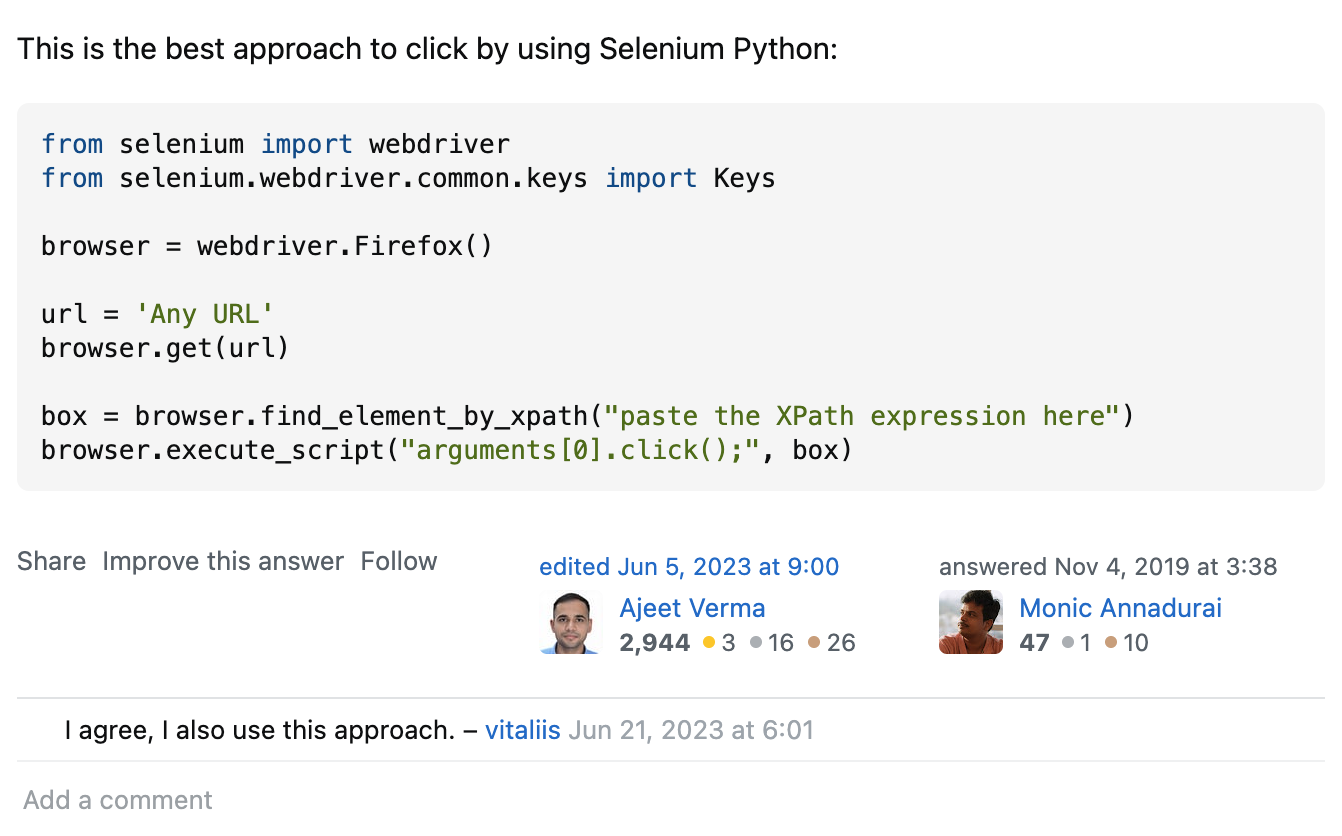
2. DRF, SWAGER, SCRAPY, SELENIUM, BEAUTIFULSOUP, CELERY, REDIS, FLOWER, BEAT 등등 전통적인 방식의 크롤링을 진행한다!
설치 진행시켜!

# requirements.txt
# scrapy==2.11.2 # web crawling
# scrapy-user-agents==0.1.1 # web crawling
# scrapy-selenium==0.0.7 # web crawling
# webdriver-manager==4.0.2 # web crawling
# selenium==4.24.0 # web crawling
# beautifulsoup4==4.8.2 # web crawling
# # captcha solving
# captcha_solver==0.1.5 # captcha solver
# pytesseract==0.3.13 # tessaract-ocr
# # Proxy and User-Agent Rotation
# rotating-free-proxies==0.1.2 # rotating free proxies
# fake-useragent==1.5.1 # fake user agent
# # redis
# redis==5.0.8 # for celery, message broker
# # flower
# flower==2.0.1 # celery monitoring
# # beat
# django-celery-beat==2.7.0 # celery schedule
pip install -r requirements.txt대략 이런 모양세가 될 듯?!
myproject/
├── manage.py
├── myproject/
│ ├── __init__.py
│ ├── settings.py
│ ├── urls.py
│ ├── wsgi.py
│ └── asgi.py
├── scraping/
│ ├── __init__.py
│ ├── admin.py
│ ├── apps.py
│ ├── tasks.py
│ ├── views.py
│ ├── urls.py
│ ├── models.py
│ ├── serializers.py
│ └── tests.py
├── mycrawler/
│ ├── __init__.py
│ ├── items.py
│ ├── middlewares.py
│ ├── pipelines.py
│ ├── settings.py
│ ├── spiders/
│ │ ├── __init__.py
│ │ └── dynamic_spider.py
│ └── __init__.py
├── celery.py
├── requirements.txt
├── Dockerfile
└── docker-compose.yml# 프로젝트 생성 => dJango rest framework 에 통합해서 사용 할 예정
scrapy startproject naver
# 스파이더(크롤러) 생성 => 명령어로 생성 해도 되고, 그냥 파일 직접 만들어도 된다!
scrapy genspider naver www.naver.com # crawling 시작! crawl 명령어가 받는 인자는 위에서 genspider로 만든 이름!
# ex) scrapy genspider naver www.naver.com => scrapy crawl naver
scrapy crawl dynamic_spider3. DRF에 SCRAPY 양념하기
scraping django app 과 service_crawler scrapy project를 프로젝트 루트 안에 생성!
django-admin startproject service_crawling_project
django-admin startapp scraping
scrapy startproject service_crawler
The Man Who Lift