서비스에 카프카 도입 후, 적절한 모니터링 툴을 찾아보다가 KaDeck free버전 설치 시 professional 7일 평가판을 사용할 수 있어 클러스터를 적용해 보았다.
설치 및 적용이 매우 간단하고 모니터링까지 너무 괜찮았지만, free버전으로 전환된 후 확인해보니 실제로 사용할 수 있는 기능이 매우 적어 결국 서비스에 적용하진 못했다.
설치 및 클러스터 등록
설치 링크 : https://www.getkadeck.com/#/thankyoudesktop
KaDeck Support : https://support.xeotek.com/hc/en-us
-
설치 후 약관동의
-
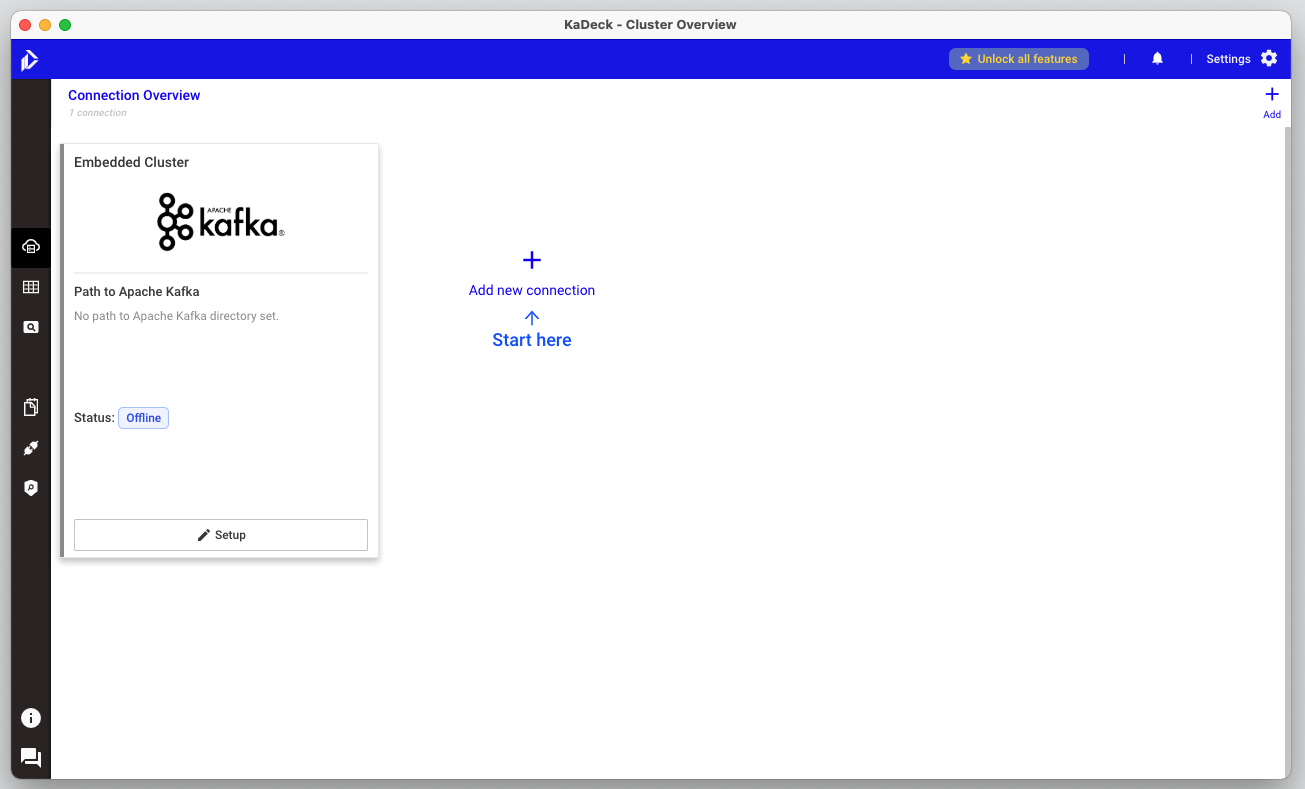
초기화면
-
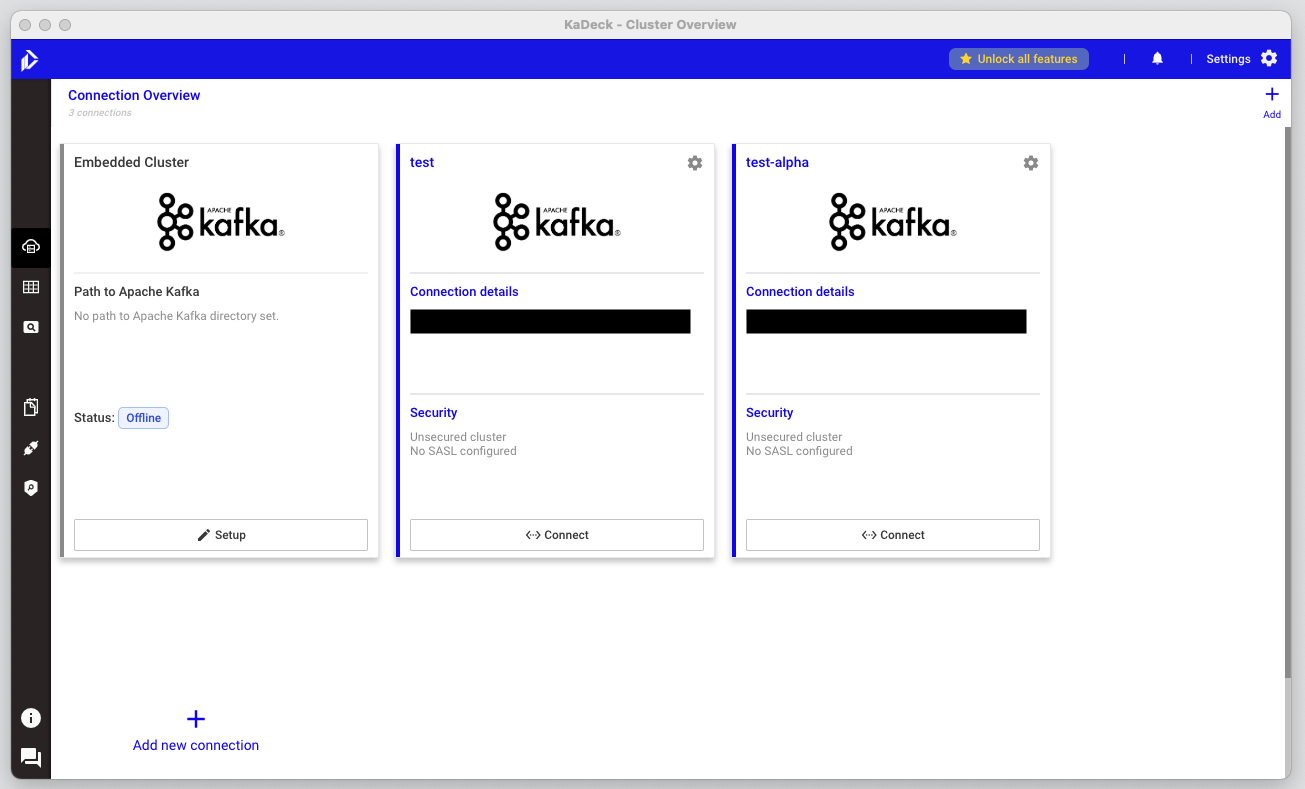
카프카 클러스터 등록
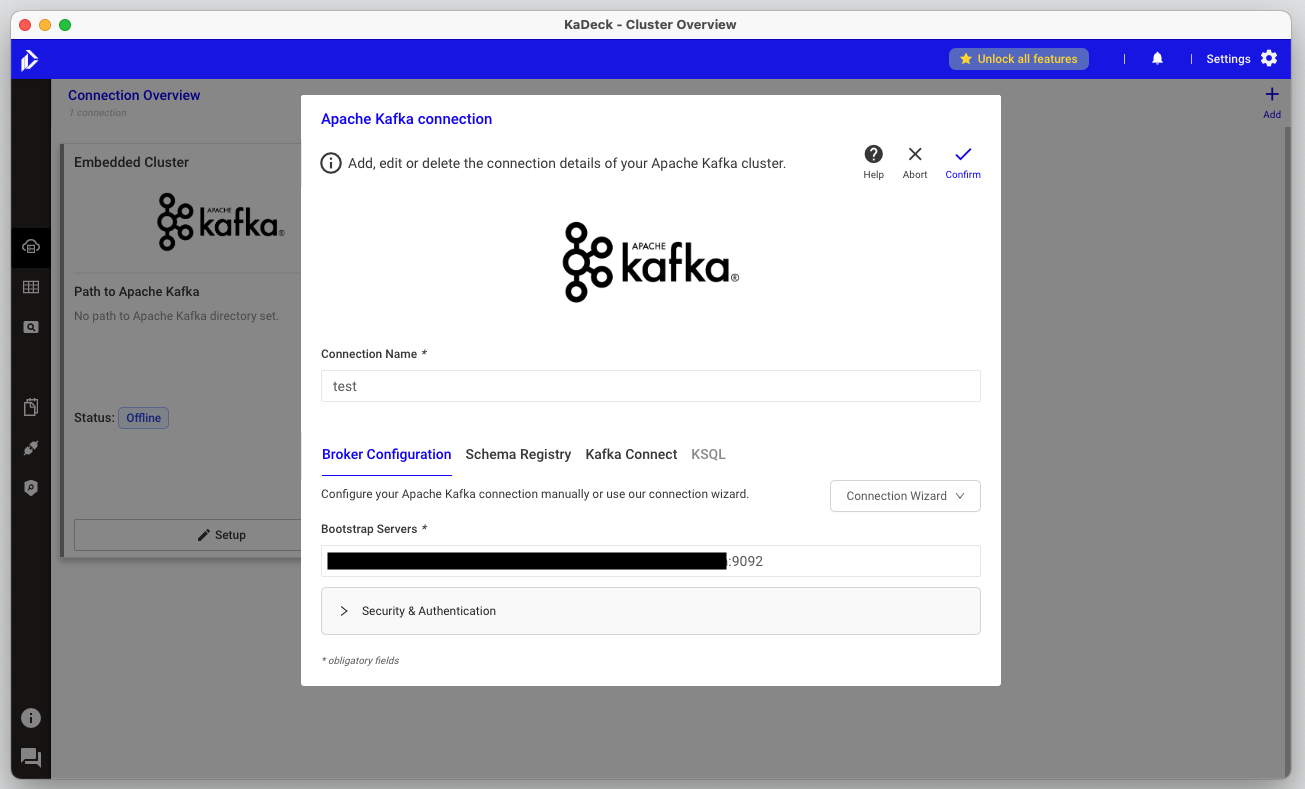
-
등록 시 초기화면
connect/disconnect로 클러스터 연결/해제
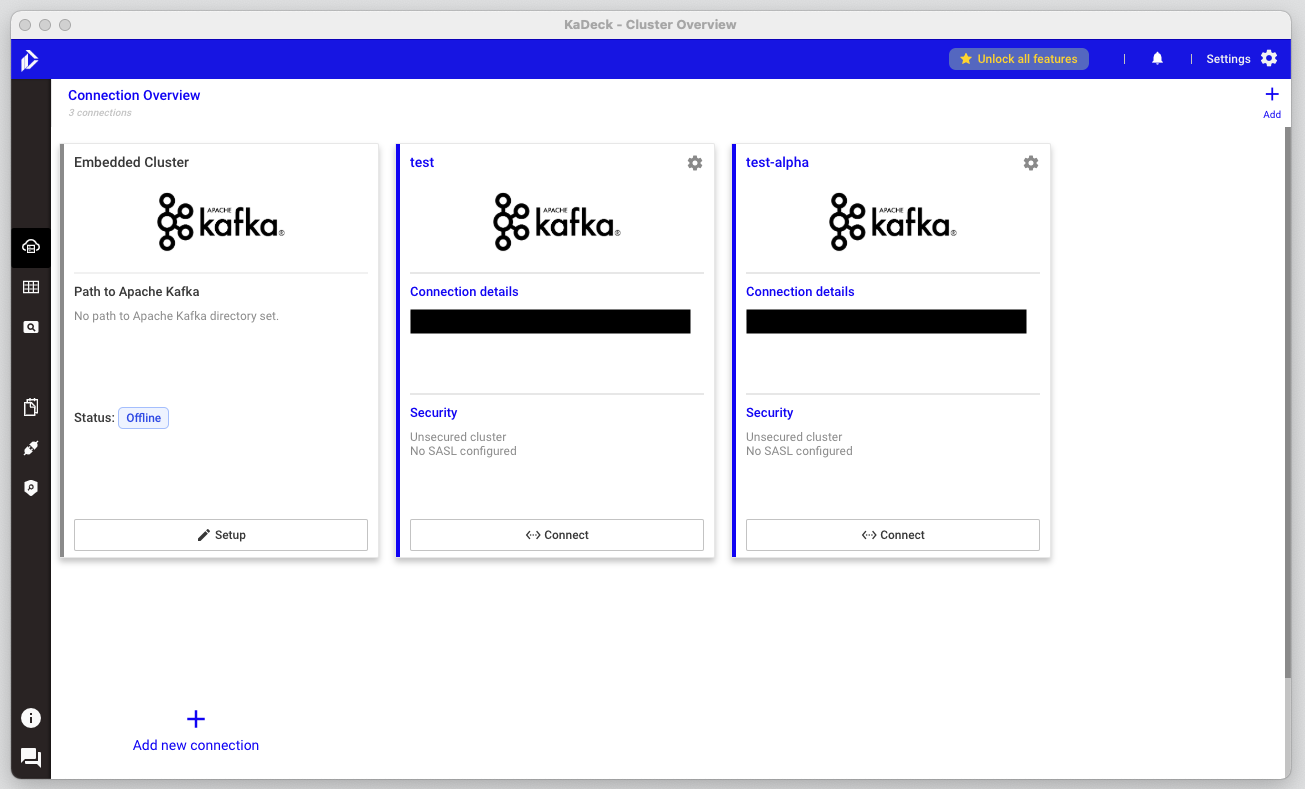
UI
Manage Connection
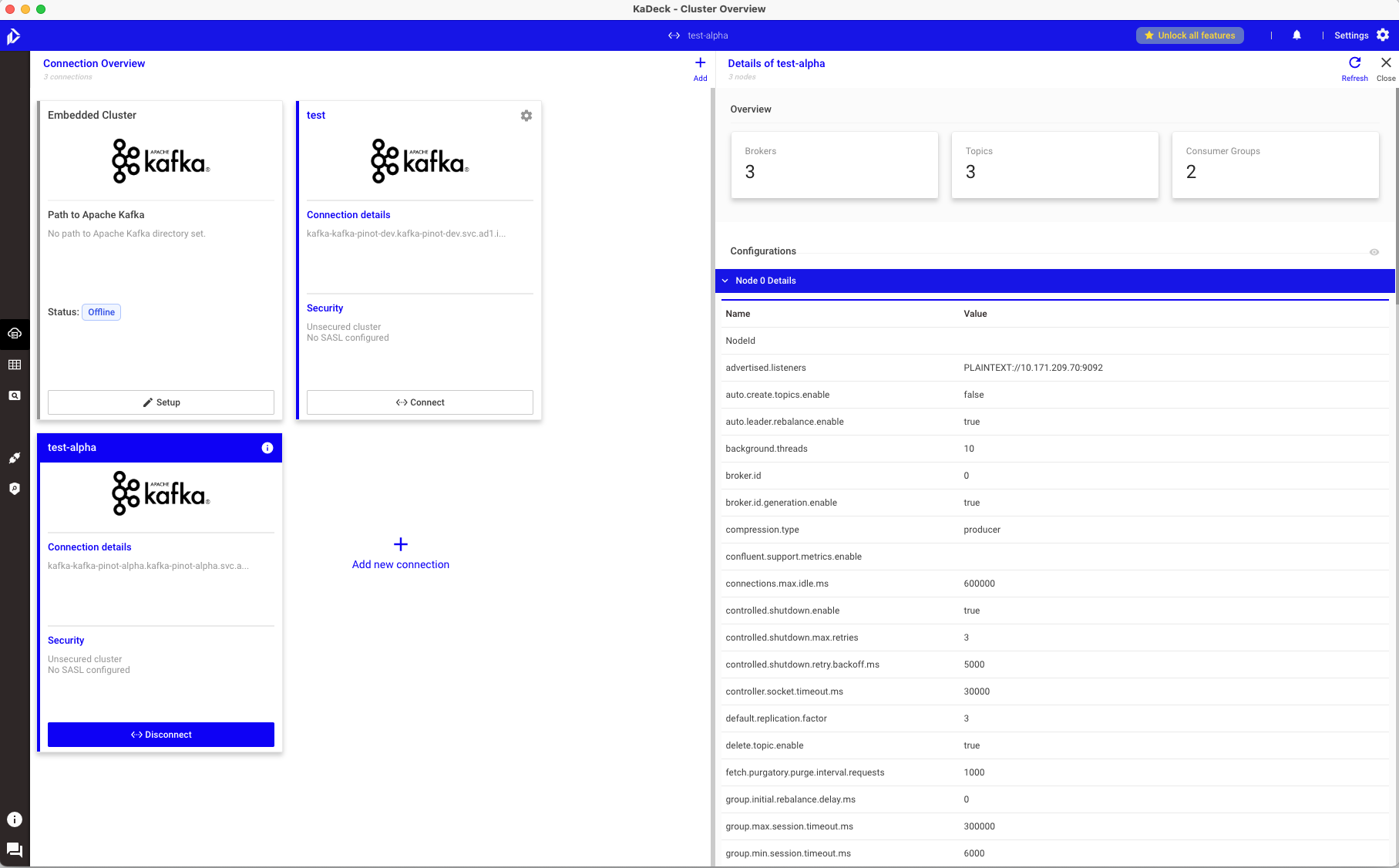
- 카프카 커넥션 리스트 조회
- 특정 카프카 연결 시
- 현재 브로커/토픽/컨슈머 그룹 확인
- 노드 상세정보 확인
Data Browser
Data Browser 가이드 : https://support.xeotek.com/hc/en-us/articles/360013603520-Topic-Browser?ci=a10339922b1188b11b11c124488a1099
기본 UI
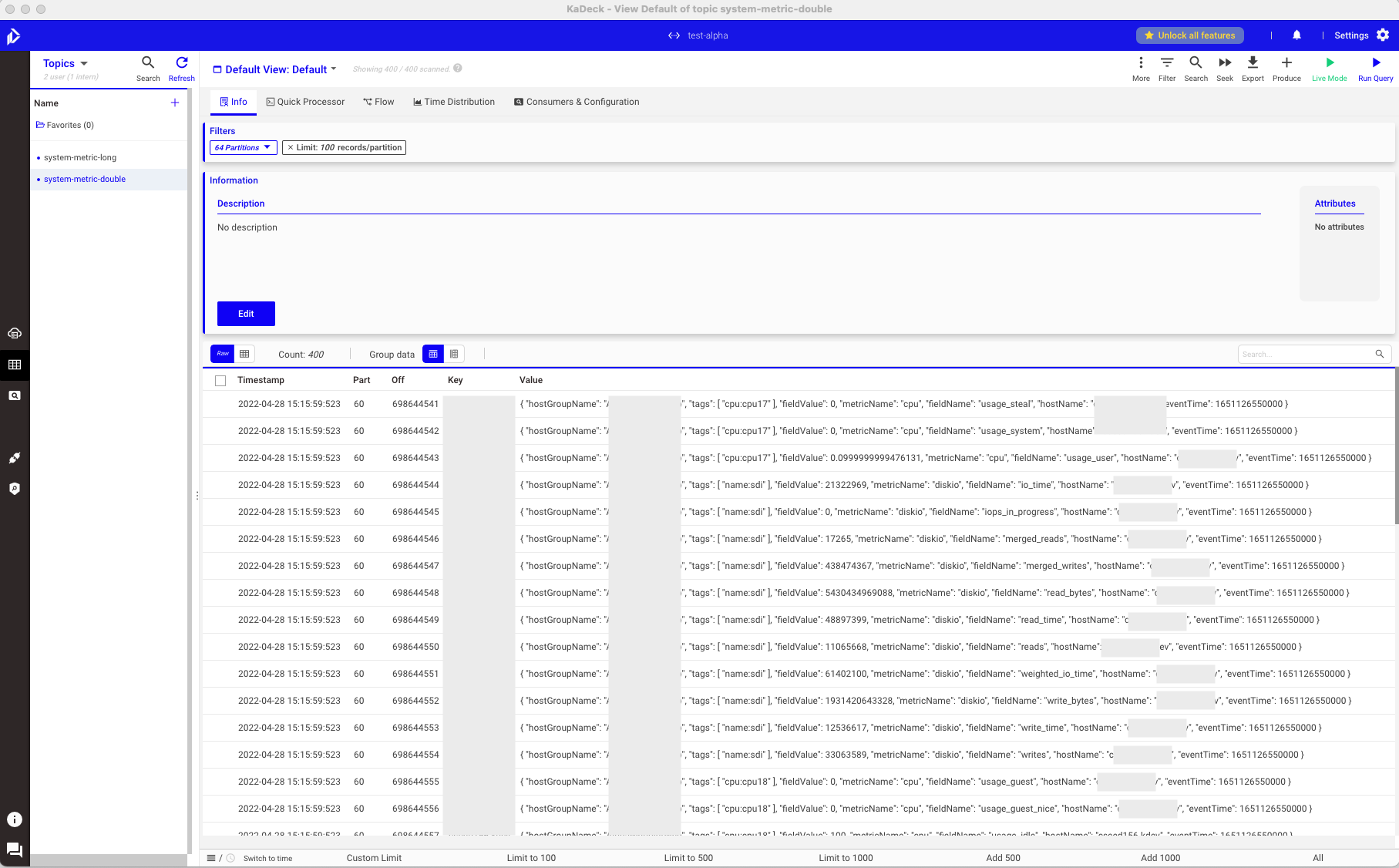
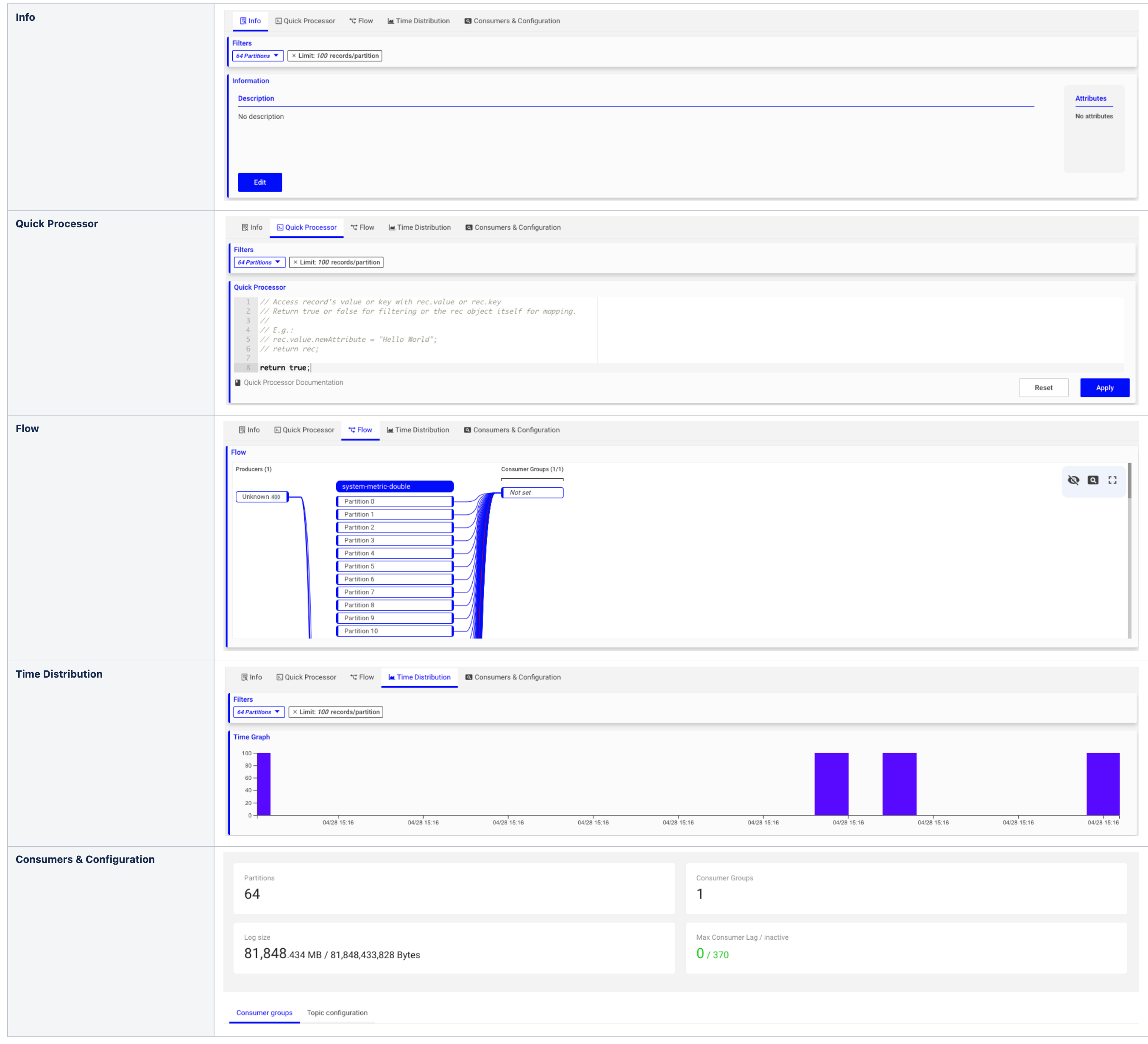
상세 기능
-
토픽 조회
- 토픽 조회/검색/생성
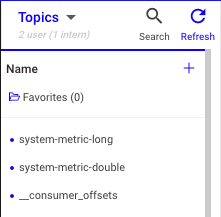
- 토픽 삭제, 토픽 내 레코드 비우기
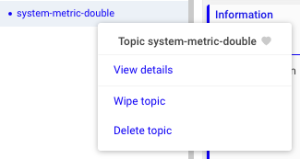
- 토픽 명에 마우스 오버 시 해당 토픽의 파티션 개수와 로그 사이즈 조회
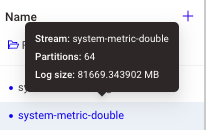
- 토픽 config 조회/수정/추가

- 토픽 조회/검색/생성
-
View 관리
- 사용자 지정 구성을 저장
- key/values에 대한 코덱 선택
- 각 헤더의 key 별 헤더 코덱 선택
- 속성 필터
- 값 검색
- 속성/숨겨진 열
- 타임윈도우
- 빠른 프로세서 코드
- 사용자 지정 구성을 저장
-
레코드 조회
- Row Data & Column View


- 실시간 조회
- Group by key

- 조회된 레코드 export
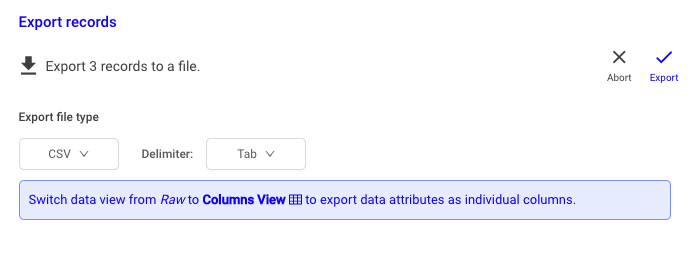
- 레코드 지정 가능
- export 형식 지정 가능 (CSV/JSON)
- 구분자 지정 가능 (comma/tab/semicolon)
- 조회된 레코드 클릭 시 상세 조회
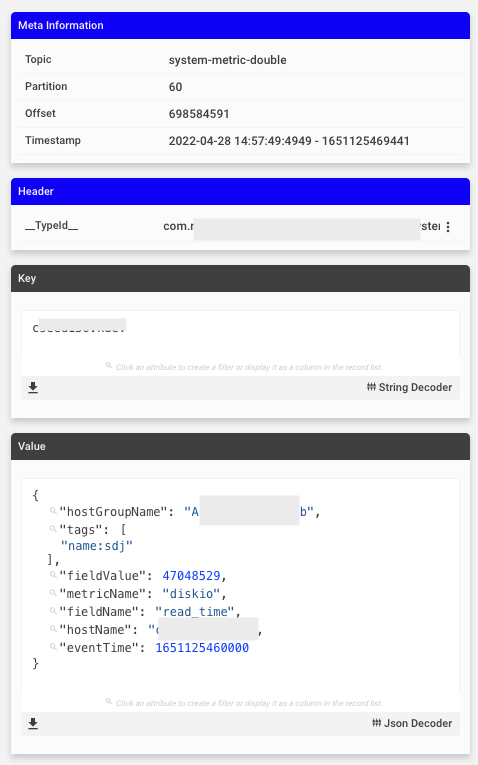
- Meta Information, Header, Key, Value
- Value에서 특정 값을 선택하여 필터 생성 가능
- 해당 정보 JSON 형식으로 다운로드 가능
- 오프셋 또는 타임스탬프별 레코드 검색
- 정규표현식으로 레코드 검색
- 사용 시 regex: 입력
- Quick Processor
- https://support.xeotek.com/hc/en-us/articles/360011414520?ci=a10339922b1188b11b11c124488a1099
- JavaScript를 사용하여 필터 생성 및 레코드 수정 가능
- Row Data & Column View
-
레코드 관리
- 레코드 추가
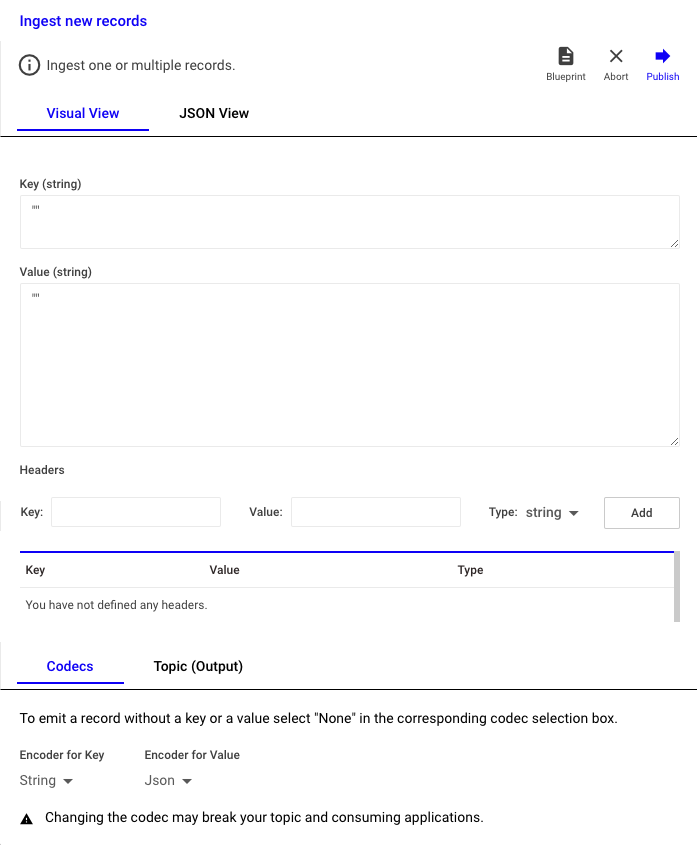
- 레코드 추가
-
컨슈머 조회

- 파티션 개수 확인
- 컨슈머 그룹 검색/확인
- 로그 사이즈 확인
- 컨슈머 lag 확인
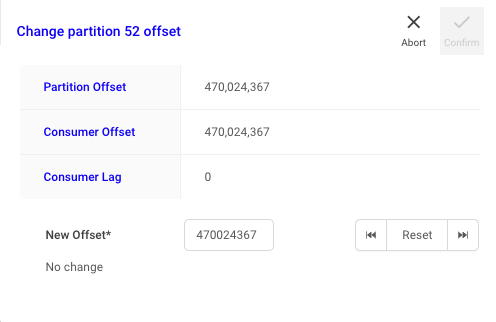
- 파티션 및 오프셋 확인
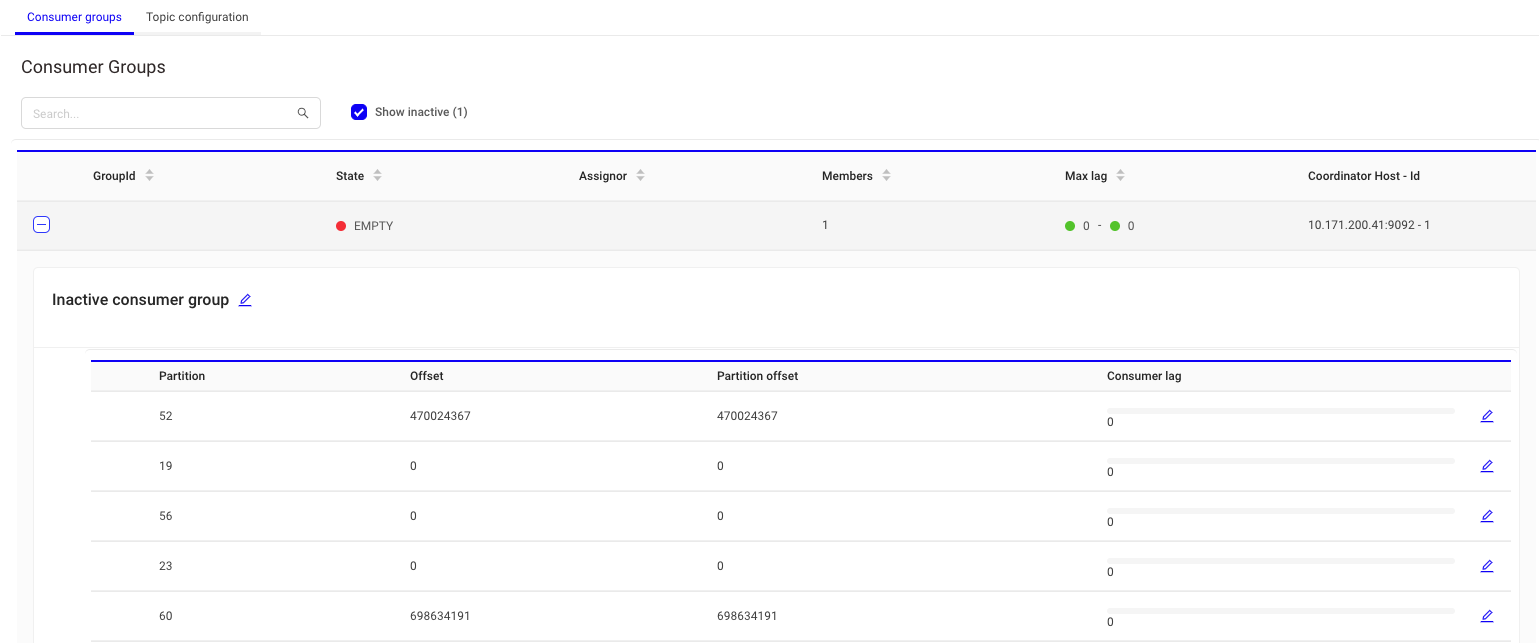
참고
-
스키마 레지스트리
- 카프카와 별도로 구성된 독립적 애플리케이션으로, 프로듀서/컨슈머와 직접 통신 (HTTP 기반)
- 장점
- 데이터 트러블슈팅 감소
- 용이한 데이터 포맷 확인
- 데이터 스키마 관련 커뮤니케이션 감소
- 데이터 처리 시 유연성 확보
- 동작 원리
- 프로듀서는 스키마 레지스트리에 스키마 등록
- 스키마 레지스트리는 등록된 스키마 정보를 카프카 내부 토픽에 저장
- 프로듀서는 스키마 레지스트리에 등록된 스키마의 ID와 메시지를 카프카로 전송
- 마 ID를 스키마 레지스트리로부터 읽어온 후 프로듀서가 전송한 스키마 ID와 조합해 메시지를 읽어옴
- 레지스트리가 지원하는 포맷을 사용해야 함
- Avro
- 시스템, 프로그래밍 언어, 프로세싱 프레임워크 사이에서 데이터 교환을 도와주는 오픈소스 직렬화 시스템
- 빠른 바이너리 데이터 포맷을 지원하며 JSON형태의 스키마를 정의할 수 있는 매우 간결한 데이터 포맷
- 데이터 필드마다 데이터 타입 정의 가능, doc을 이용해 각 필드의 의미를 정확하게 전달 가능
- JSON
- 메시지마다 필드 네임들이 포함되어 전송되므로 효율이 떨어짐
- 프로토콜 버퍼
- Avro
- 운영 환경에서 스키마 레지스트리는 카프카와 분리된 별도의 서버에서 실행하는 것이 일반적임, 또한 이중화(m/s) 구성 추천
- 스키마 레지스트리 옵션
- kafkastore.topic : 스키마 레지스트리에서 스키마 저장과 관리 목적으로 카프카의 토픽 사용
- 순서가 중요하기 때문에 토픽의 파티션 수는 항상 1
- schema.compatibility.level : 스키마 호환성 레벨 (BACKWARD/FORWARD/FULL)
- kafkastore.topic : 스키마 레지스트리에서 스키마 저장과 관리 목적으로 카프카의 토픽 사용
-
카프카 커넥트
- 아파치 카프카의 오픈소스 중 하나로, 데이터베이스 같은 외부 시스템과 카프카를 손쉽게 연결하기 위한 프레임워크
- 효율적이고 빠르게 클라이언트를 구성하고 적용 가능
- 장점
- 데이터 중심 파이프라인 : 커넥트를 이용해 카프카로 데이터를 보내거나 카프카로부터 데이터를 가져옴
- 유연성과 확장성 : 단독/분산 모드 실행 가능
- 재사용성과 기능 확장 : 기존 커넥터 활용 가능, 빠른 확장이 가능해 운영 오버헤드를 감소시킬 수 있음
- 장애 및 복구 : 분산 모드로 실행 시 워커 노드의 장애 상황에도 유연하게 대응가능하므로 고가용성 보장
- 소스 → 소스 커넥트 → 카프카 → 싱크 커넥트 → 싱크
- 커넥트 구성
- 워커 : 카프카 커넥트 프로세스가 실행되는 서버 또는 인스턴스 등을 의미, 커넥터나 태스크들이 워커에서 실행됨
- 커넥터 : 직접 데이터 복사 X, 데이터를 복사 경로 정의 및 관리, 각 태스크들을 워커에 분산
- 태스크 : 커넥터가 정의한 작업을 직접 수행하는 역할
