Reference
https://arxiv.org/pdf/1506.02640.pdf
YOLO가 나오기 전에는 Object Detection을 Region Proposal과 Classification을 두 단계로 나누어서 진행을 해왔다. 2-Stage로 진행을 하면 정확도가 높지만, 시간이 오래걸린다는 단점이 있는 반면에, Yolo에서는 1-Stage로 진행을 하여 초당 45 프레임의 속도까지 나온다고 한다. Fast YOLO일 경우에는 초당 155 프레임을 검출하며, 다른 실시간 측정 모델보다 mAP가 두 배 정도 높다. 이번 포스팅에서는 어떻게 YOLO가 1-Stage를 구현했는지, 간단하게 살펴 볼 예정이다..
Yolo의 특징
- 간단한 구조로 인한 빠른 속도
- 다른 네트워크와 달리 전체적인 이미지 정보를 활용
- 객체의 일반화 가능한 표현을 학습
Unified Detection
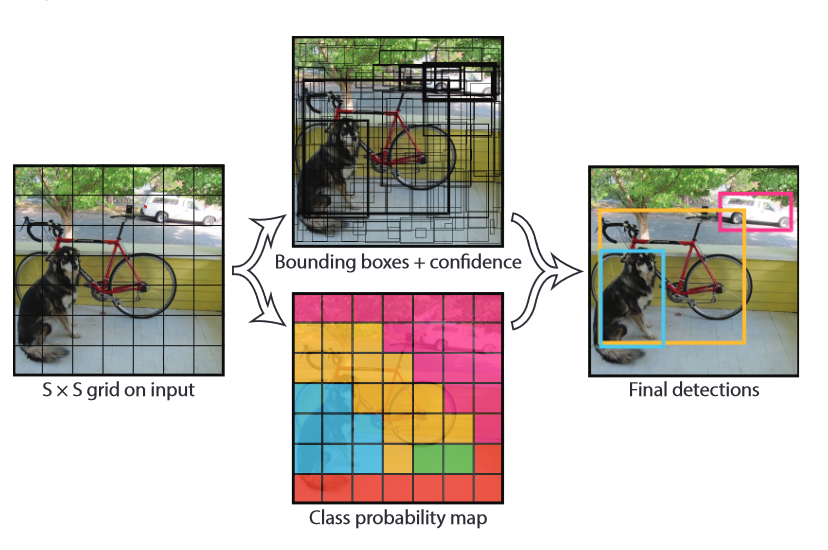
YOLO는 전체 이미지에서 각각의 bounding box를 찾고, 동시에 클래스를 예상한다.
의 grid cell로 이미지를 분할을 하고, 객체가 이 grid 중앙에 있다면 그 grid는 객체를 검출할 수 있다. 각각의 grid는 개의 bounding box와 confidence score를 예상하는데, 이 네트워크에서는 일반적인 confidence score랑은 다르게 계산한다.
이 점수는 box가 object에 잘 맞는지와 박스 안의 class가 맞는지의 확률을 의미합니다.
예측한 정보는 의 tensor로 나타내어 진다.
Network Design

네트워크의 구조는 Google Net의 영향을 많이 받았다고 한다. 24개의 Conv layer와 24개의 FC layer로 이루어져 있다. 각각의 Conv layer는 1x1 conv를 통해 파라미터의 급격한 증가를 억제하고 원하는 channel의 수로 바꿀 수 있다.
Training
학습을 할 때는 ImageNet 1000-class dataset으로 pretrain된 conv layer20개를 사용했다고 한다. 그리고 전체적인 프레임워크는 Darknet의 구조를 사용했다.
Detection을 하기 위해 이 논문에서는 랜덤하게 intialized된 4개의 Conv 층과 2개의 FC layer를 사용한다. 마지막 층에서는 class의 확률과 bounding box의 좌표 두개를 모두 예측한다.
활성화 함수로는 마지막 층은 linear함수를 쓰고 나머지에서는 leaky relu를 쓴다. 최적화는 SSE(Sum Square Error)를 사용하였다. 이렇게 하면 쉽게 최적화 할 수 있지만, localization 과 classification이 이상적이지 않아 문제가 일어난다. 또한, grid cell안에 object가 없을 경우, confidence score가 0으로 나와, cell 안에 object가 있는 것에 큰 영향을 받을 수가 있다.
이러한 문제를 해결하기 위해 bounding box 좌표의 loss는 더 크게, confidence loss는 더 낮게 하는 방법을 사용하였다.
: i번 째 cell안에 객체가 있는지의 정보 (있다면 1)
: i번째 cell에서 j번째 bounding box 의 예상한 정보
: grid 안의 bounding box 개수
: grid안에 class가 있으면 1
: 예측한 bounding box의 confidence score
위의 식에서 첫번째 항과 두 번째 항은 Localization loss, 세 번째와 네 번째 항은 Confidence loss, 마지막 항은 Classification에 관한 loss 이다.
이렇게 간략하게 YOLO모델에 대해서 알아보았다. YOLO를 기점으로 object detection이 많은 발전을 하였고, 앞으로 더욱 더 다양한 모델에 대해서 알아 볼 계획이다.
