위의 이미지는 구글에 "제주도 맛집"을 검색했을때 페이지 제일 아래의 모습을 보여준다.
열개의 페이지가 넘는 정보들을 확인할 수 있지만 고작해봤자 두번째 페이지, 많아야 세번째 페이지정도까지 둘러보는 나의 모습을 보았다.

사실 몇개까지의 페이지를 제공할지 궁금해서 넘어가다보니 17번째에서 멈추고 또 다시 검색할 수 있도록 도와주고 있었다......😳
현재 우리가 사용하는 웹은 이처럼 우리가 감당할 수 없는 수많은 양의 정보들을 가지고 있다. 매일 수천,수억가지의 정보들이 추가되고 사라지기도 할 것이다. 구글과 같은 검색엔진은 매일 이런 전세계의 정보들을 '구글봇'이라는 로봇을 사용해서 이용자가 검색할 만한 키워드를 미리 예상하여 의미있는 검색의 결과들을 보여준다.
💁만일 그렇지 않았다면 전혀 상관도 없는 내용의 정보들까지도 우리들이 하나하나 확인해야했을지도..?💁
구글봇과 같은 로봇은 웹페이지의 HTML코드를 가지고 그 의미를 분석하고 인지하는데 그 의미는 코드안에 시맨틱 요소가 있느냐에 따라 달라진다.
**non-semantic 요소**
- div, span 등이 있으며 이들 태그는 content에 대하여 어떤 설명도 하지 않는다.
**semantic 요소**
- form, table, img 등이 있으며 이들 태그는 content의 의미를 명확히 설명한다
위의 코드의 결과값은 아래처럼 "제주도 맛집" 동일하지만 의미적으로는 완전히 다르다.
첫번째 "제주도 맛집"은 의미론적으론 어떤 의미도 가지고 있지 않다. 즉 작성자의 의도가 명확하지 않다. 단순히 스타일의 변화를 준 데이터라는 것을 나타내고 있다.
하지만 두번째의 "제주도 맛집"은 semantic tag인 h1(header)를 사용하여 웹문서의 제목이라는 의미를 명확히 전달한다.

앞서 말한 것처럼 검색엔진은 HTML코드를 분석하여 그 의미를 인지하기에 semantic tag를 사용한 두번째 요소가 검색엔진의 인덱싱 과정중 높은 확률로 포함된다. 또한 이러한 과정들을 통해 semantic web이 실현되면 정보시스템의 효율성과 생산성이 극대화될 것이라는 것을 충분히 이해할 수 있을 것이다.
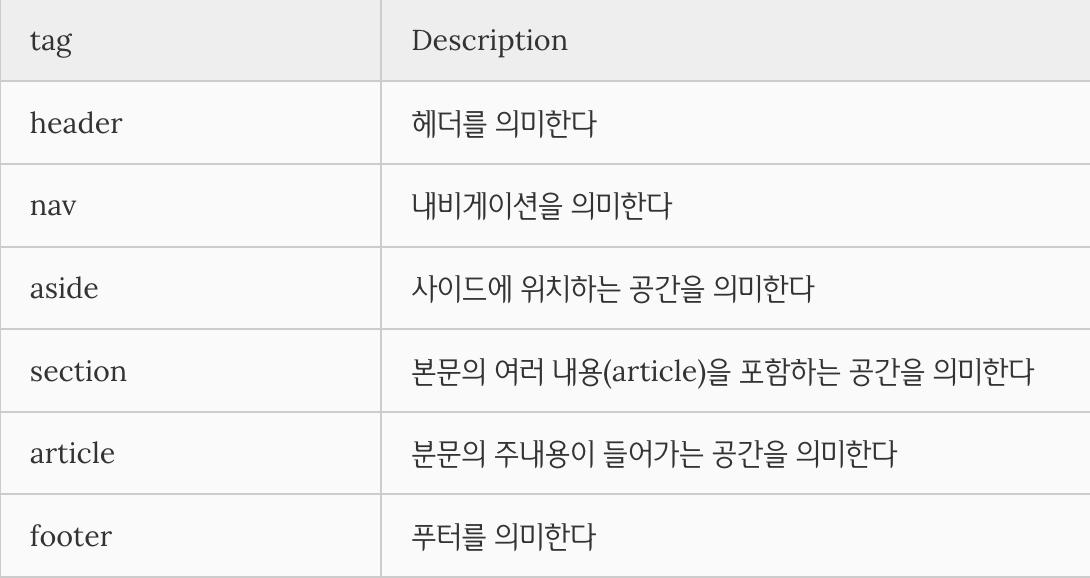
마지막으로 HTML5에서 새롭게 추가된 시맨틱 태그들을 확인해보며 글을 마치려한다.
이번 내용들을 정리하며 "아는만큼 보인다" 라는 말이 생각났다.
바로 전 블로그에서 이런 글을 사용했었다.
"사실 레이아웃을 구성을 위해서는 거의 block요소인 div를 사용했기에 제일 처음 구조를 만들때는 어떤 속성을 가진 tag를 사용해야하는지 그렇게 어렵지 않았다."
전혀 몰랐다. 왜 저런 태그들을 사용해서 HTML문서를 만들어야했는지... 그냥 div로 span으로 웹페이지를 구성해도 전혀 괜찮을 줄 알았는데 전혀 괜찮지가 않았던 것이다😅😅
그래도 내일부터는 HTML을 작성할때 semantic tag를 사용해서 semantic web을 지향하는 개발자가 될 수 있을 것 같아 뿌듯하다.
