참고한 내용
Overview
강화 학습(RL)
- 강화 학습은 환경과 상호작용하여 input을 수집하고 feedback을 취함
- 해당 세계와 상호 작용하는 동안 취해야 하는 최상의 조치를 출력
RL이 기존의 ML과 다른 점
- 감독이 없음
- 훈련 데이터 세트가 없으며, 환경과 상호작용하여 데이터 세트를 수집함
- 반복적으로 결정을 내리고 input에 대한 추론을 한 번 실행해 예측 생성
- RL을 이용하면 추론을 반복적으롷 실행하고 실제 환경을 탐색하면서 이동함
Markov 결정 과정(MDP)
RL 문제를 풀기 위해서는 문제를 MDP로 재구성할 필요가 있다.
MDP의 구성 요소
- Agent
- RL 문제를 훈련시킬 모델
- Environment
- Agent가 상호 작용하는 환경
- State
- 특정 시점에서 환경의 상태
- Action
- Agent가 취하는 행동
- Reward
- Action의 결과로 얻는 강화(보상)
- 의도한 대로 행동했다면 Positive Reward
- 잘못된 행동을 했다면 Negative Reward
- Action의 결과로 얻는 강화(보상)
MDP 구성 시 유의사항
- Agent / Env.
- Agent와 Env.의 역할과 범위를 정해야 한다
- State
- State에 포함된 데이터 요소와 표현 방식을 결정해야 한다.
- Agent가 추가 정보를 요구하지 않도록 필요한 모든 정보를 State 내에 정의해야 한다 (캡슐화)
- State에 포함된 데이터 요소와 표현 방식을 결정해야 한다.
- Action
- Reward
- Agent가 학습하고자 하는 behavior를 반영해야 함
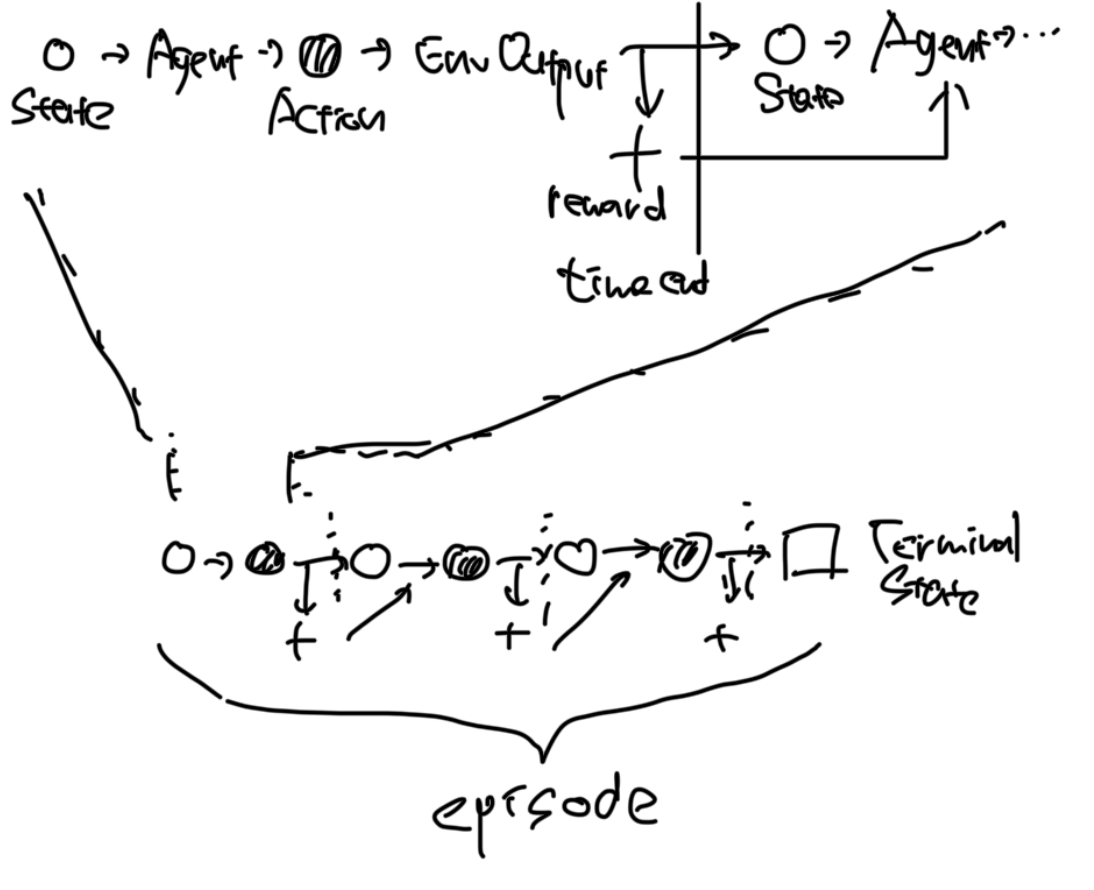
MDP의 작동 방식
ex) Tic-Tac-Toe 게임을 이용해 RL 문제를 풀 때,
- 초기 상태
- State: 놓여 있는 모든 토큰의 위치
- Agent의 행동 결정
- Action
- 이미 배치된 토큰을 피해 토큰 배치
- Env.의 출력 + 다음 State와 reward
- Feedback
- State와 Reward를 Agent에게 입력
- 하나의 time step 끝, 2부터 5까지 반복하여 Terminal State까지 도달
Agent의 목표는 보상의 총량을 최대화하는 것
보상의 총량 = 즉각적인 보상 + 누적 보상
- 전체적인 흐름
Trajectory
Trajectory(궤적)는 하나의 time step에서의 state, action, next time step에서 참고할 현재의 reward를 정의한다
- 여기서 는 time step을 나타낸다.
Episode
- 시작 상태부터 time step을 반복하여 도달한 끝 상태까지의 일련의 순서
- episode가 끝나면 시작 상태(initial state)로 reset
- 각 episode는 서로 무관함
Agent와 Env.의 state-action 전이(transition) 제어
- 현재 상태를 고려해 agent가 next action을 결정
- 현재 상태와 next action이 결정되면 next state의 전이와 reward는 env.에 의해 control됨
Agent가 action을 선택하는 법
agent는 state에서 다음 3가지를 기반으로 action을 결정함
- Return
- Policy
- Value
Return, Policy, Value
Return
- 누적 보상
action 기간 동안 누적된 총 보상- discount factor를 적용해 즉각적인 보상에 신경쓰도록 하며, time step이 많아져도 reward가 무한히 커지지 않도록 함
- = discount factor, = time step
- n제곱의 이유:
- 이므로 누적 보상 값이 수렴하도록 하기 위함
- later reward를 더 많이 깎음으로써 즉각적인 reward에 더 가치를 두도록 하기 위함
- 같은 보상이면 더 빨리 받도록 한다.
- Agent는 Return이 높도록 action을 선택한다.
Policy
- action을 선택하도록 하는 전략
- state를 next action에 매핑
-
Deterministic policy (결정적 정책)
특정 상태 특정 행동으로 고정 -
Stochastic policy (확률적 정책)
action의 확률에 따라 state에 대한 action을 변경 -
Agent는 시작할 때 대개는 useful policy가 없음
- RL을 통해 helpful policy를 천천히 학습
Agent의 목표는 Return을 최대화하는 Policy를 따르는 것임
Value
-
policy를 따라 action을 선택했을 때, 얻을 수 있는 Return의 기댓값 (평균)
-
Value의 두가지 유형
-
State Value
-
State-action Value
- Q-Value라고도 함
-
Value와 Return, Reward의 관계
| 종류 | 설명 |
|---|---|
| Reward | 단일 action 즉시 reward |
| Return | episode 누적 discounted reward |
| Value | 다수의 episode에 대한 Return의 기댓값 |
Value가 policy에 영향을 받는 이유
Value는 reward에 의한 return에 따름
-> Reward는 state와 그에 따른 action에 따라 다름
-> action은 policy에 따라 다름
Policy 비교를 위한 Value function
- = policy
-
각 정책을 따라 수행 후, Return을 평가해 각 정책에 따른 , 를 결정할 수 있다.
-
각 Value function이 있으면 Value function을 이용해 Policy를 비교할 수 있다
-
Value function이 더 높은 policy는 higher Return을 산출하므로, better policy라고 할 수 있음
-
policy 중 best policy, 즉 highest Return을 내는 policy는 optimal policy라고 함
RL 문제의 목표는 Optimal policy를 찾는 것임
