1. 데이터베이스 기본 개념
요약
- 데이터베이스 : 데이터를 많이 모아놓은 베이스. 컴퓨터 시스템에 저장된 정보나 데이터를 모두 모아 놓은 집합
- 사용 목적: 데이터를 휘발성으로 사라지게 하지 않고, 오래 기간 저장하며, 동시에 체계적으로 보관.
1-1. Database 기초 이해
💡 데이터베이스의 개념 (By Oracle)
A database generally refers to a structured collection of structured information or data stored electronically in a computer system. The database is usually controlled by a database management system (DBMS). Data and DBMS are referred to as 'database systems' along with related applications, and are also collectively referred to as 'databases' for short. (Oracle)
- 컴퓨터 시스템에 저장된 정보나 데이터를 모두 모아 놓은 집합
- 데이터를 많이 모아놓은 베이스
- 데이터들은 데이터베이스 관리시스템 (DBMS, Database Management System) 으로 제어하고 관리한다.
데이터베이스 시스템(or 데이터베이스 or DB)
데이터 + 데이터베이스 관리 시스템 + 연관된 다른 어플리케이션들
1-2. 데이터베이스를 사용하는 이유
- 데이터를 오랜기간 저장 및 보존하기 위해서
작은 어플리케이션에서도 임시로 저장할 수는 있다. 그러나 컴퓨터를 껐다 켜면 사라지듯이 메모리의 데이터는 오래 보존이 되지 않고 다시는 읽어들일 수 없다. 따라서, 필요한 자료를 계속 보존하기 위해 데이터베이스를 사용한다.
데이터베이스 왜 쓸까?
서버에 계속 저장한다면?
특정 기간에 트래픽이 급격히 증가하는 서비스를 개발한다고 하자
- 서버 대수를 늘리거나(이중화): 데이터 통일해서 관리가 안됨
- 서버 사양을 높이거나: 하나가 죽으면 다 터진다
참고)
서버 노드js 데이터베이스 포트를 다르게 설정하면 컴터 1대에 서버, DB 모두 설치할 수 있다
- 데이터를 체계적으로 보존하고 관리하기 위해서
필요할 때 언제든 내가 원하는 자료를 쉽게 읽어낼 수 있어야만 의미 있는 정보라고 할 수 있다. 데이터베이스에는 데이터가 아무렇게나 어질러 저장되지 않고 체계적으로 정리되어 입력된다.
2. 관계형 데이터베이스
요약
- 관계형 데이터베이스는 모든 데이터를 2차원 테이블에 저장.
- 테이블에 저장된 데이터들의 관계에 따른 분류: one-to-one, one-to-many, many-to-many
- one-to-one : A 테이블의 한 데이터는 B 테이블의 데이터 하나와만 연결.
- one-to-many : A 테이블의 데이터가 B 테이블의 여러 데이터와 연결.
- many-to-many : A 테이블과 B 테이블 모두 서로 여러 데이터와 연결.
Database의 분류
- 관계형 데이터베이스(RDBMS)
- 비관계형(Non-relational) database aka. "NoSQL"
2-1. 관계형 데이터베이스
RDBMS, Relational DataBase Management System
데이터 사이의 관계에 기초를 둔 데이터베이스 시스템.
ㄴ관계: 표들 사이의 관계
관계형 데이터베이스에서 모든 데이터는 2차원 테이블(table)로 표현할 수 있다.
예) My books 테이블
행(row)과 열(column)으로 구성된 2차원 테이블.
- Column (열) : 컬럼은 테이블의 각 항목 (id, 책 제목, 작가, 출판사, 가격).
- Row (행) : 로우는 각 항목들의 실제 값.

각 로우는 저만의 고유 키(Primary Key)가 있다.
테이블의 가장 첫 컬럼은 언제나 id 이다. 각 로우는 언제나 고유한 번호를 갖고 있으며 이를 고유 키(Primary Key)라고 한다.
예)
- 개미 : id가 4인 데이터
- 개미의 primary key = 4번
Primary Key를 통해서 특정 로우를 찾거나, 인용(reference)할 수 있다.
관계형 데이터베이스는 각각의 테이블들이 서로 상호관련성 을 가지고 서로 연결되어 있다.
2-2. 테이블 사이 관계의 종류
테이블끼리의 연결에는 3가지 종류 : One to One(일대일), One to Many(일대다), Many to Many(다대다) 관계.
One to One(일대일)
테이블 A의 로우와 테이블 B의 로우가 정확히 일대일 매칭이 되는 관계

- 한 사람은 하나의 주민등록번호를 갖는다.
- 하나의 주민등록번호는 오로지 한 사람의 것이다
테이블 A의 로우(row) 하나는 테이블 B의 로우(row) 하나와 연결된다. 반대로 테이블 B의 로우 하나도 테이블 A의 로우 하나와 연결된다.
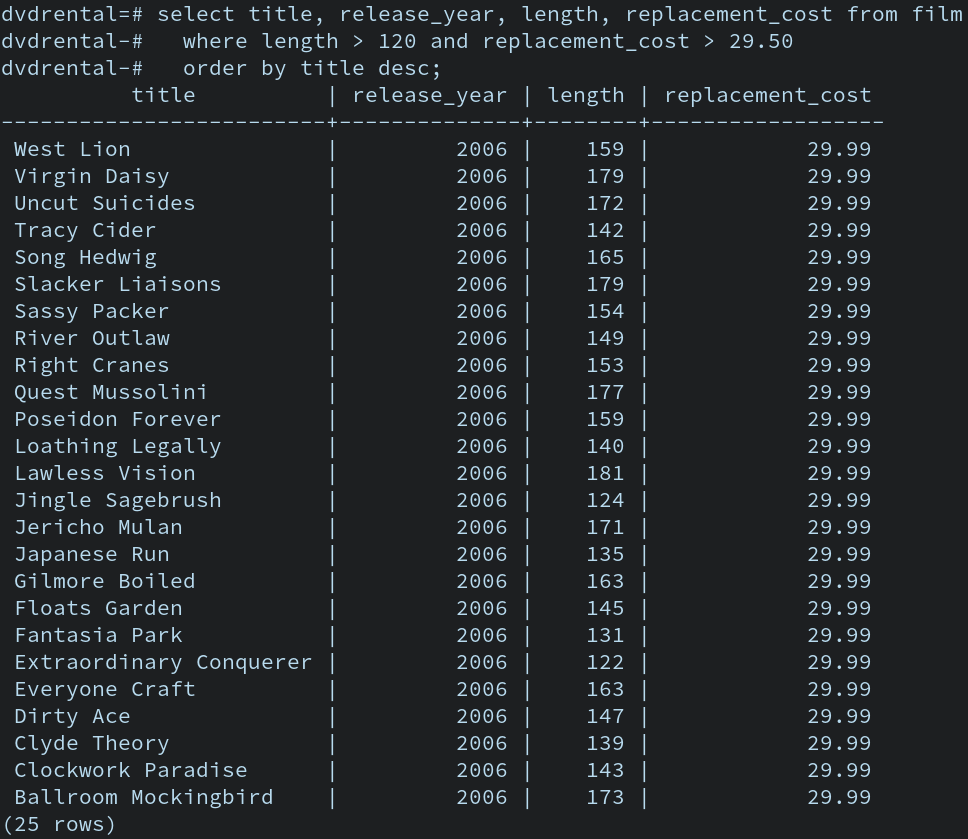
👉 해당 테이블 사이의 관계 : 일대일 관계.
- user_id 컬럼: 해당 주민등록번호의 주인인 사람의 id를 기록해둔 컬럼.
identification numbers 라는 테이블은 원래 아래와 같은 형태였을 것이다

users 라는 테이블에 이름 데이터들을 이미 저장했는데, 같은 이름들을 중복 해서 저장하면 불필요한 메모리를 사용하므로 user_id 를 저장해주는 것이다.
: 참조한다
예)
- Identification numbers 테이블의 user 컬럼은 users 테이블의 id(pk)를 참조한다
다른 테이블의 pk를 참조한 컬럼에 입력되어 있는 숫자들에도 이름이 있다.
: Foreign Key, 외래키
identification numbers 테이블의 user_id 는 모두 FK 라고 부른다.
👉 테이블 Users와 테이블 Indentification은 서로 일대일 관계이다.
One To Many(일대다)
테이블 A의 로우가 테이블 B의 여러 로우와 연결이 되는 관계.
예) 작성자(one) - 댓글들(many)
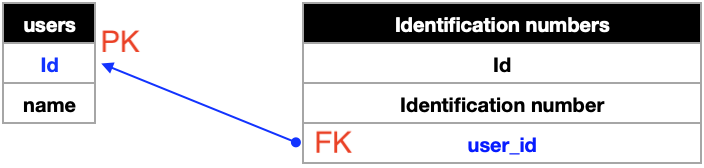
예) 펫 서비스
- 사용자를 관리하는 users 테이블
- 고객의 반려동물을 관리하는 pets 테이블
- 어떤 동물의 주인이 누구인지: pets 테이블의 user_id
Users 테이블의 로우 하나는 Pets 테이블의 여러 로우와 연결된다.
Pets 테이블의 로우 하나는 Users 테이블의 로우 하나와 연결된다.
👉 One To Many 관계, 일대다 관계, 1:N
👉 users 테이블이 one, pets 테이블이 many
pets 테이블의 user 컬럼은 users 테이블의 id(pk)를 참조한다
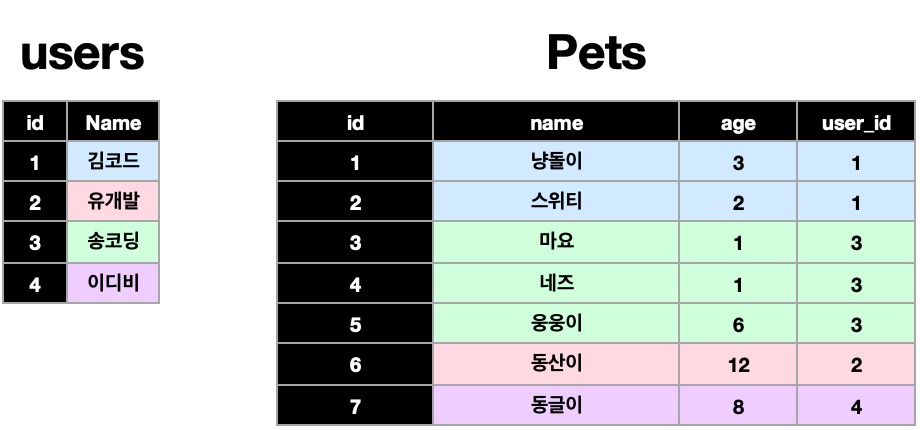
1:1은 두 테이블이 서로가 서로의 오로지 한 로우에만 연결되어야 한다.
1:N은 한 테이블의 로우 하나에 다른 테이블의 로우 여러개가 연결될 수 있다.
Many To Many(다대다)
테이블 A의 여러 로우가 테이블 B의 여러 로우와 연결이 되는 관계를 many to many 라고 한다.
예) 작가(many) - 책(many)
- 한 작가는 여러 권의 책을 쓸 수 있다.
- 한 책에도 작가는 여러명이 될 수 있다.
👉 [id,작가] < [id, 작가_id, 책_id](중간 테이블) > [id,책]
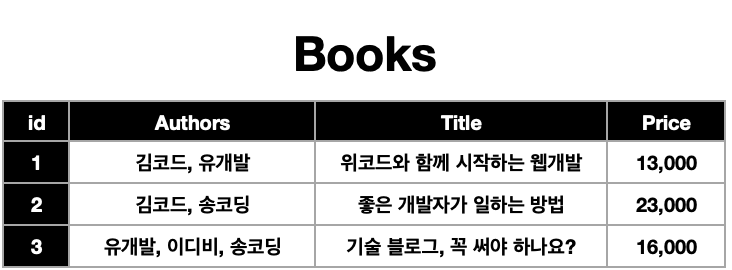
- 도서 이름이 book 이라는 컬럼,
- authors 컬럼에는 작가들의 이름,
- price 컬럼에는 책 가격
👉 authors 컬럼에 해당하는 로우 하나에 너무 여러 데이터가 들어가있기 때문에 데이터베이스에는 이런 형식으로 저장할 수 없다. (정규화 제 1법칙 위반: 테이블의 행 하나에는 딱 하나의 데이터만 들어가야 한다)
아래와 같이 풀어서 테이블을 만들어야 한다:
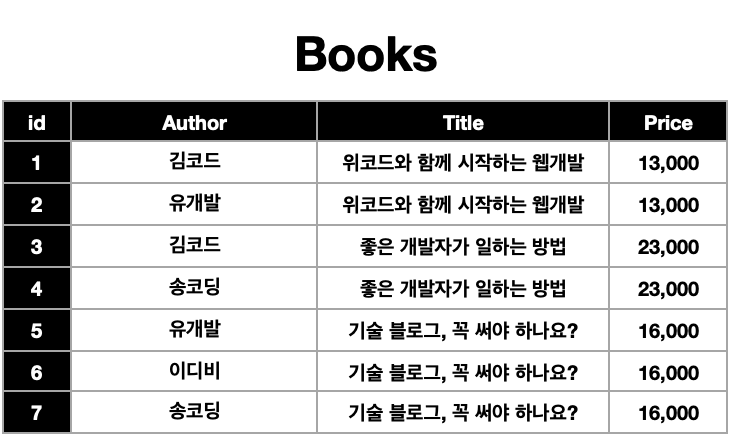
-
책 한 권이 늘어날 때마다, 작가의 수에 맞춰서 똑같은 데이터를 또 여러번 저장해 주어야 하는 문제 발생
👉 Foreign Key 를 이용하면 중복된 데이터를 줄일 수 있다 -
Authors 테이블의 로우 하나는 Books 테이블의 여러 로우와 연결된다.
-
Books 테이블의 로우 하나 또한 Authors 테이블의 여러 로우와 연결된다
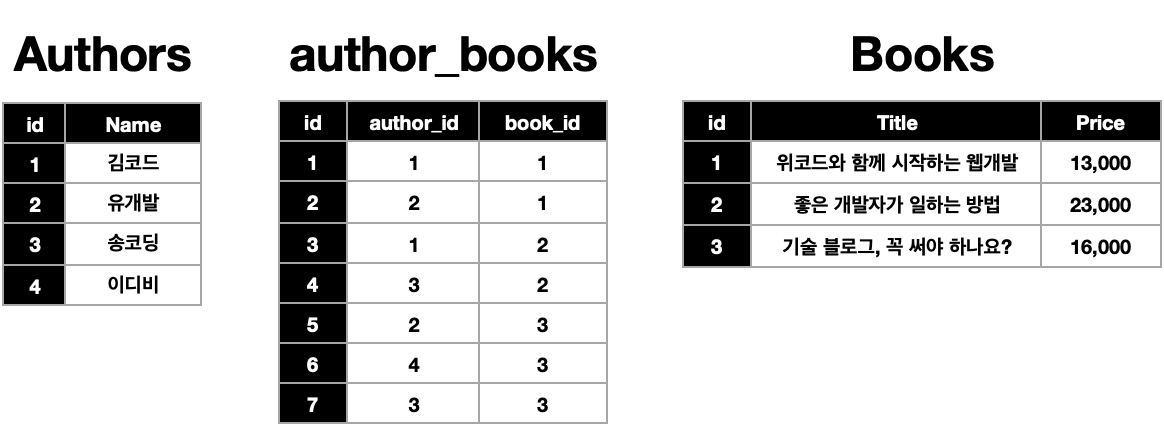
이렇게 두 테이블이 서로 각자 다른 테이블의 여러 데이터와 연결 될 때에는 두 테이블에 속한 데이터의 조합을 입력하기 위한 중간 테이블이 하나 생성된다.
👉 Many To Many 관계, 다대다 관계, N:N

👉 테이블 authors와 테이블 books는 서로 다대다 관계이다.
2-3. 어떻게 테이블과 테이블을 연결하는가?
Foreign key(외부키) 라는 개념을 사용하여 주로 연결한다
- one to one 예)에서
user_profiles 테이블의 user_id 컬럼은 users 테이블에 걸려있는 외부 키라고 지정한다.
즉 데이터베이스에게 user_id의 값은 users 테이블의 id 값이며 그러므로 users 테이블의 id 컬럼에 존재하는 값만 생성될 수 있다.
만일 users 테이블에 없는 id 값이 user_id 에 지정되면 에러가 발생한다.
2-4. 왜 테이블들을 연결하는가?
하나의 테이블에 모든 정보를 다 넣으면 동일한 정보들이 불필요하게 중복되어 저장된다.
더 많은 디스크를 사용하게 되고, 잘못된 데이터가 저장 될 가능성이 높아집니다.
- 예를 들어, 고객의 아이디는 동일한데 이름이 서로 다른 로우들이 있다면? 정확한 이름은?
- 여러 테이블에 나누어서 저장한 후 필요한 테이블 끼리 연결시키면
👉 중복된 데이터를 저장하지 않아 디스크를 더 효율적으로 쓰고,
👉 서로 같은 데이터이지만 부분적으로만 내용이 다른 데이터가 생기는 문제가 없어진다.
이것을normalization(정규화)이라고 합니다.
