※ 전남대학교 박태준 교수님의 운영체제 강의를 듣고, 정리한 내용입니다.
무엇을 기준으로 평가할 것 인지?
스케줄링 알고리즘을 평가하는 기준은 다양한 기준들이 존재합니다.
그 중 대기 시간과 반환 시간을 중점적으로 살펴 볼 예정입니다.
( 이것들이 빨라야 일반적으로 좋은 알고리즘! )
평가 기준
- 대기 시간 ( Waiting Time ) : 프로세스가 준비 큐 내에서 대기하는 시간의 총합
- 평균대기시간 : 모든 프로세스의 대기 시간을 합한 뒤 프로세스의 수로 나눈 값
- 반환 시간 ( Turn - around Time ) : 프로세스가 시작해서 끝날 때 까지 걸리는 시간
- 평균반환시간 : 모든 프로세스의 반환 시간을 합한 뒤 프로세스의 수로 나눈 값
- 응답 시간 ( Response Time ) : 첫번째 응답이 오기 시작할 때 까지의 시간
- CPU 사용률 ( CPU Utilization ) : 전체 시스템 시간 중 CPU 가 작업을 처리하는 시간의 비율
- 처리량 ( Throughput ) : CPU 가 단위 시간당 처리하는 프로세스의 개수
평균 대기시간과 평균 반환시간의 간단한 예시를 살펴보면, 아래 그림과 같습니다.
( 이때 작업은 비선점 알고리즘이라고 가정 )
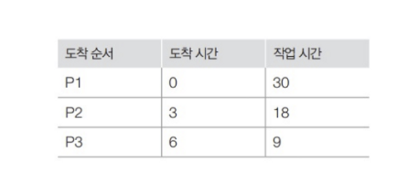
프로세스의 도착 순서, 도착 시간, 작업 시간
- 시간 = 0 일 때 P1 도착
- P1 의 대기 시간 = 0 ( 가장 먼저 왔으니 )
- 시간 = 3 일 때 P2 도착
- P2 입장에서 P1 이 처리중이니 끝날 때 까지 대기
- 비선점 알고리즘이기 때문!
- 시간 = 6 일 때 P3 도착
- P3 입장에서 P1 이 처리중이니 끝날 때 까지 대기
- P2 의 현재 대기 시간 = 3
- 시간 = 30 일 때 P1 의 작업 종료, P2 와 교대
- P2 의 전체 대기 시간 = 27
- P3 의 현재 대기 시간 = 24
- P1 의 반환 시간은 0초에 들어와서 30초에 끝났으니, P1 의 반환 시간 = 30
- 시간 = 48 일 때 P2 의 작업 종료, P3 와 교대
- P3 의 전체 대기 시간 = 42
- P2 의 반환 시간은 3초에 들어와서 48초에 끝났으니, P2의 반환 시간 = 45
- 시간 = 57 일 때 P3 의 작업 종료
- P3 의 반환 시간은 6초에 들어와서 57초에 끝났으니, P3의 반환 시간 = 51
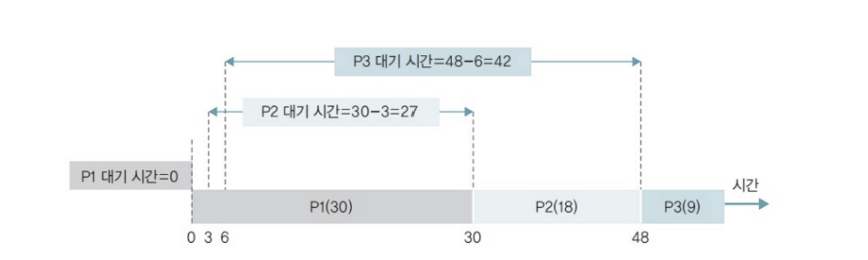
표로 정리해보면 다음과 같습니다.
| P1 | P2 | P3 | |
|---|---|---|---|
| 대기시간 | 0 | 27 | 42 |
| 반환시간 | 30 | 45 | 51 |
만약 평균 대기시간을 구하고싶다면 대기시간들을 다 더한 후 프로세스의 갯수로 나눠주면 평균 대기시간을 구할 수 있습니다.
( 평균 반환시간도 마찬가지! )
알고리즘 종류 먼저 총정리!
FCFS ( First Come First Served )
- 비선점 스케줄링
- 도착한 순서대로 쓰레드를 준비 큐에 넣고 도착한 순서대로 처리
SJF( Shortest Job First )
- 비선점 스케줄링
- 가장 짧은 쓰레드 우선 처리
Shortest Remaining Time First
- 선점 스케줄링
- 남은 시간이 짧은 쓰레드가 준비 큐에 들어오면 이를 우선 처리
Round - Robin
- 선점 스케줄링
- 쓰레드들을 돌아가면서 할당된 시간 ( 타임 슬라이스 ) 만큼 실행
Priority Scheduling
- 선점 / 비선점 둘다 가능
- 우선 순위를 기반으로 하는 스케줄링
- 가장 높은 순위의 쓰레드 먼저 실행
Multilevel Queue Scheduling
- 선점 / 비선점 둘다 가능
- 쓰레드와 큐 모두 N 개의 우선순위 레벨로 할당
- 쓰레드는 자신의 레벨과 동일한 큐에 삽입
- 높은 순위의 큐에서 쓰레드 스케줄링
- 높은 순위의 큐가 빌 때 아래 순위의 큐에서 스케줄링
- 쓰레드는 다른 큐로 이동하지 못함
Multilevel Feedback Queue
- 선점 / 비선점 둘다 가능
- 큐만 N 개의 우선순위 레벨을 둠
- 쓰레드는 레벨 없이 동일한 우선순위
- 쓰레드는 제일 높은 순위의 큐에 진입
- 큐 타임슬라이스가 다하면 아래 레벨의 큐로 이동
- 낮은 레벨의 큐에 오래 있으면 높은 레벨의 큐로 이동
FCFS ( First Come First Served ) : 선입선출
가장 단순한 형태 ( 큐 그자체 ) 인 알고리즘 입니다.
먼저 도착한 ( 큐의 맨 앞에 있는 ) 쓰레드 먼저 스케줄링을 진행합니다.
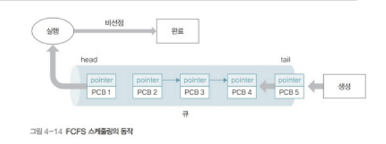
특징 정리
- 비선점 스케줄링
- 우선 순위 X
- 기아 현상 X
- 처리율 낮음
- 호위 효과 ( convoy effect ) 발생
- 처리 시간이 긴 쓰레드가 CPU 를 오래 사용하면, 늦게 도착한 처리 시간이 짧은 쓰레드는 오랫동안 기다려야 함
SJF ( Shortest Job First ) : 최단 작업 우선 스케줄링
예상 실행 시간이 가장 짧은 쓰레드를 우선적으로 선택하는 알고리즘입니다.
쓰레드가 도착할 때, 예상 실행 시간이 짧은 순서로 큐에 들어가게 됩니다.
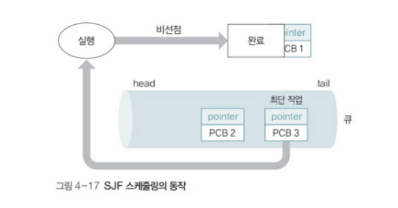
특징 정리
- 비선점 스케줄링이지만, 선점 스케줄링으로도 변환 가능
- 선점 스케줄링으로 바꿀경우 SRTF ( Shortest Remaining Time First ) 라고 부름
- 우선 순위 X
- 기아 현상 O
- 지속적으로 짧은 쓰레드가 도착하면, 긴 쓰레드는 언제 실행 기회를 얻을 지 예측할 수 없기 때문에 기아 현상이 발생할 수 있음
- 짧은 쓰레드가 먼저 실행되므로 평균 대기 시간이 최소화
- 하지만.. 실행 시간의 예측이 사실상 불가능 → 현실에선 거의 안씀
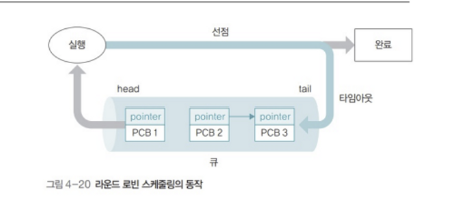
Round - Robin
쓰레드들에게 공평한 실행 기회를 주기 위한 알고리즘입니다.
큐에 대기중인 쓰레드들에게 타임 슬라이스를 주기로 돌아가면서 CPU 에 들어가게 됩니다.
- 도착하는 순서대로 쓰레드들을 큐에 삽입
- 타임 슬라이스가 지나면 큐 끝으로 이동
- 아직 작업이 완료되지 않았을 경우
특징 정리
- 선정 스케줄링
- 우선 순위 X
- 기아 현상 X
- 쓰레드간 우선 순위가 없고, 타임 슬라이스가 정해져 있어 일정 시간이 지나면 쓰레드가 무조건 실행되기 때문!
- 공평하고, 기아 현상이 없고, 구현하기 쉬움
- 하지만.. 잦은 스케줄링으로 인해 전체 스케줄링 오버헤드가 큼
- 특히 타임 슬라이스가 작을 경우, 더 자주 교체하게 되니 스케줄링 오버헤드가 더 커짐
- 균형된 처리율
Priority Scheduling ( 우선순위 )
우선순위에 따라 쓰레드를 실행시키는 알고리즘입니다.
현재 쓰레드가 종료되거나 더 높은 순위의 쓰레드가 도착할 때, 가장 높은 순위의 쓰레드를 선택합니다.
- 고정 순위 알고리즘
- 한번 우선순위를 부여받으면 종료될 때 까지 우선순위 고정
- 구현이 쉽지만, 시시각각 변하는 시스템의 상황을 잘 반영하지 못함 → 효율성이 떨어짐
- 변동 우선순위 알고리즘
- 일정 시간마다 우선순위가 변하여 우선순위를 새로 계산하고 이를 반영함
- 복잡하지만 시스템의 상황을 반영 가능 → 효율적인 운영 가능
특징 정리
- 선점 / 비선점 스케줄링
- 선점 : 더 높은 쓰레드가 도착할 때 현재 쓰레드 강제 중단 후 스케줄링 진행
- 비선점 : 현재 실행 중인 쓰레드가 종료되고나서 스케줄링 진행
- 우선 순위 O
- 기아 현상 O
- 지속적으로 높은 순위의 쓰레드가 도착하는 경우, 언제 실행 기회를 얻을 수 있을지 예측할 수 없음
- 이 경우, 큐의 대기 시간에 비례하여 일시적으로 우선순위를 높이는 에이징 방법으로 해결 가능
- 높은 우선순위의 쓰레드일수록 대기 / 응답 시간이 짧기 때문에, Real-Time OS 에서 유리함
HRN 스케줄링 ( Highest Response ratio Next )
SJF 알고리즘의 문제점이었던 기아 현상을 완화하기 위해 만들어진 알고리즘입니다.
( 기본적으로 SJF 의 변형 )
서비스를 받기 위해 기다린 시간과 CPU 사용 시간을 고려하여 스케줄링을 진행합니다.
🖥️ 우선순위 = ( 대기시간 + CPU사용시간 ) / CPU사용시간즉 오래 기다릴 수록 우선순위가 올라가고, CPU를 많이 쓸수록 우선순위가 떨어지도록 설계한 알고리즘입니다.
특징 정리
- 비선점 스케줄링
- 만약 선점이라면 → 핑퐁 현상 발생
- 우선순위를 계산하면서 어느 값은 1 늘어나고, 어느 값은 1 줄어들고 → 계속해서 Context Switching 이 발생함
- 우선 순위 O
- 기아 현상 발생할 확률 매우 낮음
- 대기시간이 긴 쓰레드일수록 우선순위가 높아짐
MLQ ( Multi - Level Queue )
쓰레드들을 N 개의 우선순위 레벨로 구분하여, 레벨이 높은 쓰레드들을 우선적으로 처리하기 위한 알고리즘입니다.
- 고정된 N 개의 큐 사용, 각 큐에 고정 우선순위 할당
- Queue 의 레벨이 높다 → 우선 순위가 높다!
- Level 이 높은 큐 안에 작업들이 다 처리가 돼야 그 다음 순위의 큐에서 스케줄링 진행
- 쓰레드들의 우선순위도 N 개의 레벨로 분류
- 각 큐 나름대로의 기법으로 스케줄링 진행
- 기아 현상을 줄이고자 큐 자체에 스케줄러가 있을 수도 있음
- 쓰레드는 도착 시 우선 순위에 따라 해당 레벨 큐로 삽입
- 가장 높은 순위의 큐가 비어있다면, 그 다음 순위의 큐에서 스케줄링 진행
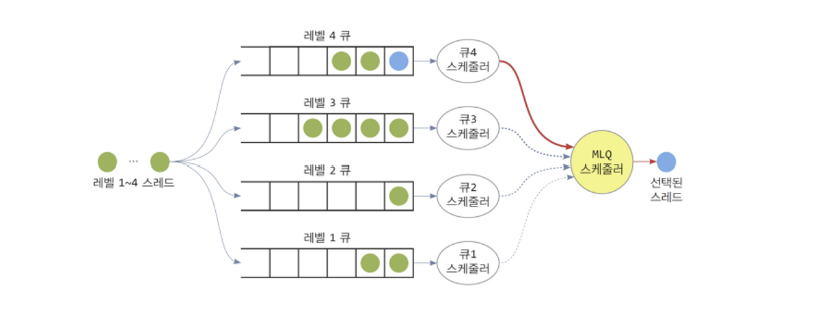
일반적으로 Queue 의 우선순위대로 처리하다보니, 기아현상이 발생할 수 있습니다.
이를 해결하고자 MLFQ 가 등장하게 되었습니다.
MLFQ ( Multi-Level Feedback Queue )
기아 현상을 없애고자 여러 레벨의 큐 사이에 쓰레드들이 이동할 수 있도록 설계된 알고리즘입니다.
MLQ 와 동일하게 N 개의 고정된 큐가 존재하며, 큐마다 서로 다른 스케줄링 알고리즘을 적용할 수 있습니다.
차이점은 큐마다 쓰레드가 머무를 수 있는 큐 타임슬라이스가 존재하며, 낮은 레벨의 큐일수록 더 긴 타임 슬라이스를 갖게 됩니다.
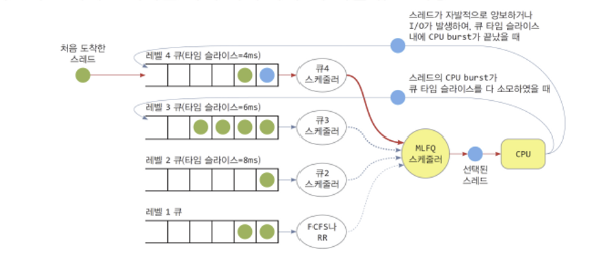
- 쓰레드는 도착시 최상위 레벨의 큐에 삽입
- 가장 높은 레벨의 큐에서 쓰레드 선택
- 큐가 비어있다면, 그 아래의 큐에서 쓰레드 선택
- 쓰레드의 CPU-burst 가 큐 타임 슬라이스를 초과하면 강제로 아래 큐로 이동시킴
- 즉 쓰레드가 작업을 다 완료하지 않은 상태에서 큐의 타임 슬라이스가 끝나면, 작업을 중단하고 아래 큐로 이동
- 쓰레드가 자발적으로 중단한 경우, 동일한 레벨 큐 끝에 삽입
- 쓰레드가 I/O 로 실행이 중단된 경우, I/O가 끝나면 동일한 레벨 큐 끝에 삽입
- 큐에 있는 시간이 오래되면 ( 대기시간이 길어지면 ) 기아 현상을 막기 위해 하나 위의 레벨 큐로 이동

훌륭한 글이네요. 감사합니다.