
CPU
CPU는 RAM에 저장되어 있는 명령어(프로그램 코드)들을 실행함으로써 프로그램 수행이라는 기본적인 기능을 수행한다.
메모리에서 명령을 가져와서 필요한 작업을 수행하고 출력을 다시 메모리로 보낸다.
또한 운영 체제 및 애플리케이션을 실행하는 데 필요한 모든 컴퓨팅 작업을 처리.
- Instruction Fetch - RAM으로 부터 명령어를 읽어온다.
- Instruction Decode - 수행해야 할 동작을 결정하기 위해 명령어를 해독한다.
(여기서 1번 2번 동작은 모든 명령어가 공통 수행한다.)- Data Fetch - 명령어 실행을 위해 데이터가 필요한 경우에는 RAM 혹은 I/O device 로부터 그 데이터를 읽어온다.
- Data Process - data에 대한 산술적 or 논리적 연산을 수행.
- Data Store : 수행한 결과를 저장한다.
(3,4,5 동작은 필요한 경우에만 수행)
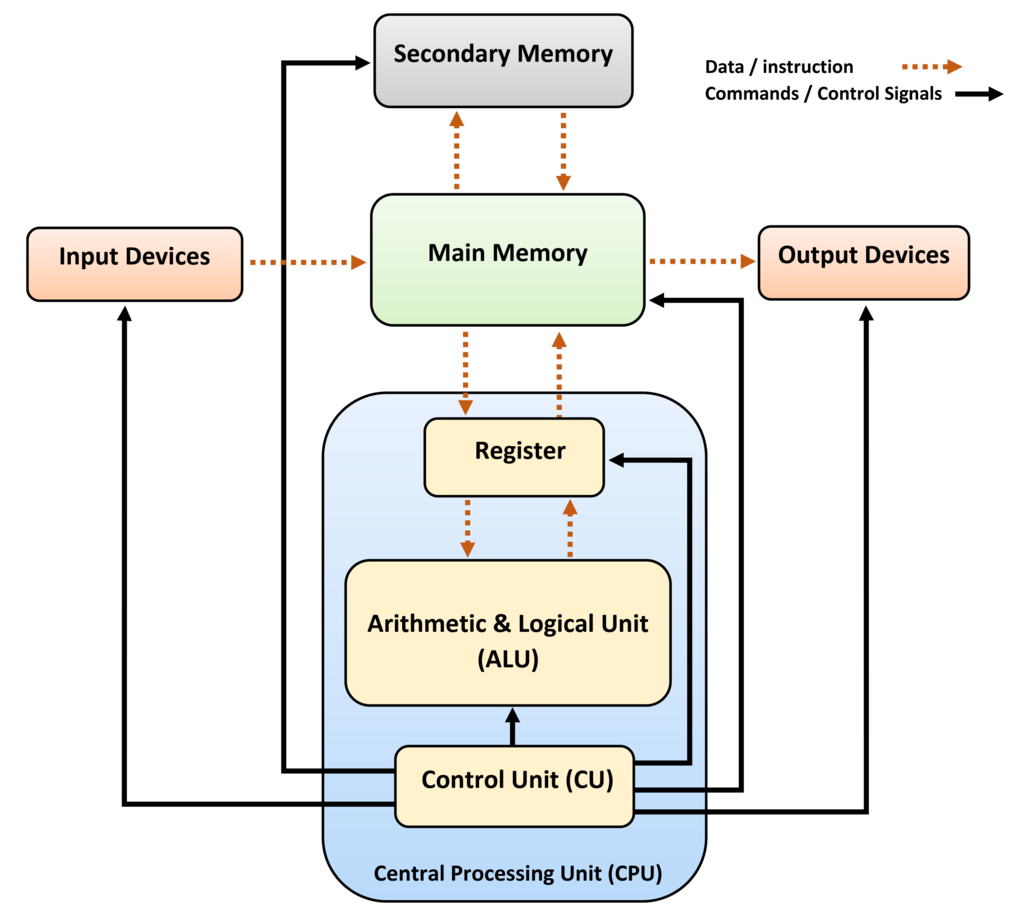
CPU Architecture

위는 CPU의 전체 architecture를 단순화한 다이어그램이다.
CPU 구성요소
CPU는 ALU(Arithmetic Logic Unit) 와 Register Set 및 CU(control unit)으로 구성된다.
이들은 CPU가 명령어를 해독하고 실행하기 위해 필요한 하드웨어적인 요소들을 나타낸다.
ALU : 산술 및 논리 연산을 수행하는 부분이다. 이는 덧셈, 뺄셈, 곱셈, 논리 연산(AND, OR, NOT 등) 등을 처리. ALU는 데이터 처리의 핵심 부분으로, 주로 산술 명령어에 따라 데이터를 계산하고 처리하는 하드웨어 모듈이다.
Register : 레지스터는 CPU 내부에 있는 고속 메모리로, 명령어 실행 중에 사용되는 데이터나 주소를 일시적으로 저장하는 데 사용된다. 레지스터는 명령어의 피연산자를 저장하거나 계산 중간 결과를 보관하며, 데이터의 빠른 액세스를 가능하게 한다.
Control Unit : 제어 장치는 CPU의 작동을 조정하고 제어하는 부분으로, 명령어를 해석하고 실행하는 역할을 담당한다. 이는 명령어를 해독하고 실행 유닛들에게 적절한 신호를 보내어 명령어를 실행하도록 한다. 또한 명령어 순서를 관리하고 예외 상황을 처리하기도 한다.
CPU 명령어 실행단계
CPU는 RAM에 저장되어 있는 명령어들을 인출하여 실행함으로써 작업을 수행한다.
CPU가 한 개의 명령어를 실행하는 데 필요한 전체 과정을 Instruction Cycle(명령어 사이클)이라고 한다. 그리고 명령어 사이클은 CPU가 기억장치로부터 명령어를 읽어 오는 Instruction Fetch(명령어 인출) 단계와 인출된 명령어를 실행하는 Instruction Execution(명령어 실행) 단계로 이루어짐. 이 때, 각각의 subcycle을 Fetch Cycle(인출 사이클)과 Execution Cycle(실행 사이클) 이라고 한다. Instruction Cycle은 프로그램 실행을 시작한 순간부터 전원을 끄거나 회복이 불가능한 오류가 발생하여 중단될 때까지 반복하여 수행된다.
Fetch Cycle : CPU가 memory의 지정된 위치로부터 명령어를 읽어오는 과정
CPU는 각 명령어 사이클의 시작 단계에서 PC가 가리키는 기억장치의 위치로부터 명령어를 인출해 온다. 그런 다음에 CPU는 PC의 내용을 1씩 증가시킴으로써 명령어들을 기억장치에 저장되어 있는 순서대로 읽어올 수 있도록 해준다.
Execution Cycle : CPU가 인출된 명령어 코드를 decode하고 그 결과에 따라 필요한 연산을 수행하는 과정
Interrupt : 대부분의 컴퓨터들은 프로그램 처리 중에 CPU로 하여금 순차적인 명령어 실행을 중단하고 다른 프로그램을 처리하도록 요구할 수 있는 메커니즘.
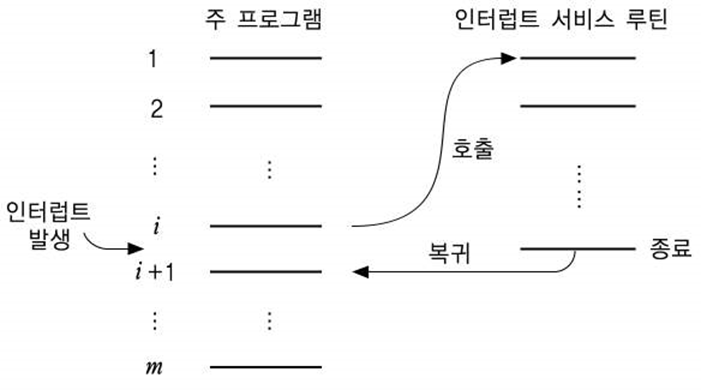
Interrupt Cycle : 인터럽트 요구 신호를 검사하고 현재의 PC 내용을 stack에 저장한 다음, PC에 해당 ISR의 시작 주소를 적재하는 과정
CPU 제조사 별 분류
주요 제조사는 Intel, AMD, ARM 3곳으로 나뉜다.
Intel
x86 아키텍처 기반의 프로세서를 주로 생산.
주로 데스크톱, 노트북, 서버 시장에서 널리 사용.
인텔의 프로세서는 주로 대용량 캐시, 높은 클럭 속도, 강력한 싱글 코어 성능으로 유명.
인텔은 최신 기술을 적극적으로 도입하여, 인텔 프로세서는 대부분의 컴퓨터 시스템에서 사용되는 표준적인 선택지이다.
AMD
x86 아키텍처 기반의 프로세서를 생산하며, 최근에는 ARM 기반 프로세서도 개발 중.
AMD는 인텔과 경쟁하며, 가격 대비 성능이 우수한 제품을 제공.
AMD의 프로세서는 뛰어난 멀티코어 성능과 가격 대비 성능 비율로 유명하다.
AMD는 게이밍 컴퓨터부터 서버까지 다양한 분야에서 사용되는 프로세서를 제공한다.
ARM
ARM은 주로 모바일 기기, 임베디드 시스템, IoT 디바이스를 위한 프로세서를 생산.
ARM 프로세서는 저전력이며 효율적으로 설계되어 있어, 모바일 기기의 배터리 수명을 연장하고, 냉각 요구를 줄이는 데 기여한다.
ARM의 프로세서는 다양한 라이센싱 모델을 통해 다른 회사들이 커스텀 디자인하여 사용할 수 있다. 따라서 ARM 아키텍처는 매우 다양한 제품과 산업 분야에서 사용된다.
ARM은 최근에는 노트북 및 서버 시장에도 진출하여 기존 x86 시장에서 경쟁하고 있다.
Memory
맥락에 따라 메모리란 단어가 지칭하는 뜻이 조금 상이하지만, 컴퓨터에서 memory라 하면 RAM과 하드디스크(HDD,SSD)를 지칭한다. 운영체제가 굉장히 복잡해진 이유도 메모리의 종류가 다양해졌기 때문이다. 만약 컴퓨터에 메모리가 딱 하나라면 운영체제는 복잡해질 이유가 없다. 오히려 운영체제가 없는게 효율적이다. 우리가 깔아놓은 수많은 프로그램들은 HDD/SSD에 저장되어 있다. 하지만 프로그램을 실행시키려면 프로세스가 CPU위에 올라가야만 한다. 그런데 CPU는 데이터를 저장할수 없기 때문에 어떤 프로그램을 실행시키려면 SSD에 잇는 명령어를 CPU 위에 올려줘야 한다.
근데 SSD와 CPU사이에 명령어를 실행시키는 거리가 너무 멀기 때문에 명령어를 처리할 수 있는 시간이 낭비가 된다. 이를 해결하기 위해 CPU와 SSD사이에 여러 개의 메모리를 둬서 CPU가 필요한 데이터를 빠르게 끌어다 쓸 수 있도록 하면 된다. 여러 개의 메모리는 "RAM"이다.
CPU는 필요한 데이터를 메모리에 요청하고, 만약에 메모리에 해당 데이터가 없으면 운영체제가 SSD에서 데이터를 가져오는 구조로 생각하면 된다.
RAM(Random Access Memory)
사용자가 자유롭게 내용을 읽고 쓰고 지울 수 있는 메모리.
메인 메모리에 주로 사용되는 RAM은 일반적으로 전원이 차단되면 내용이 지워지는 휘발성 기억 장치이다. 이런 특성으로 인해 속도는 느리지만 전원이 끊어져도 정보를 저장할 수 있는 자기 테이프, 플로피 디스크, 하드 디스크 같은 보조 기억 장치가 나오게 되었다.
컴퓨터가 켜지는 순간부터 CPU는 연산을 하고 동작에 필요한 모든 내용이 전원이 유지되는 내내 RAM에 저장된다. 램의 용량이 클수록 동시에 할 수있는 일이 많아지기 때문에 RAM을 "책상"에 비유하기도 한다. 책상이 넓을수록 그 위에 여러가지 책(어플리케이션)을 올려두고 읽을 수 있고 이후 그 책을 다시 회수(전원off)하면 그 물품이 있었다는 기록은 사라지기 때문이다.
Virtual Memory
프로그램이 혼자 메모리를 사용하는 것처럼 메모리를 가상화한 것을 말한다.
멀티태스킹이 없던 옛날에는 항상 하나의 프로그램이 모든 메모리를 직접 사용한다는 전제하에 만들었다. 이후 멀티태스킹이 도입될 때 문제가 되던 것 중에 하나가 각자의 프로그램이 동시에 작동한다고 했을때 메모리를 어떻게 분배할지에 대한 것이 있었다.
일반적으로 프로그램이 메모리에 데이터를 읽거나 쓸 때 실행 파일에 저장된 특정 위치에 특정 데이터를 저장한다. 이때 만약 같은 프로그램을 2개 실행한다고 하면 두 프로그램이 메모리의 같은 위치에 데이터를 읽고 쓰게 되고, 두 프로그램이 서로 충돌해 오동작하게 된다.(예를 들면 메모장을 두 개 키면, 기본적으로 충돌 나서 실행 중에 멈추거나 오류가 날 것이고, 만약 실행에 문제가 없다고 해도 한 메모장에 글자를 적으면 다른 메모장에도 글자가 표시된다거나 해서 동시에 사용하는 의미가 없어진다.)
이를 해결하기 위한 여러 방법들 중 하나가 각 프로그램이 별도의 메모리를 혼자 사용하는 것처럼 가상화하는 것이다.
물론 실제로 프로세스가 실행될 수 있는 메모리 공간은 램 크기 만큼이지만 운영체제가 가상메모리 공간을 프로세스에게 제공해줌으로써 프로세스는 자신을 모두 메모리에 적재했다는 착각을 한다. 프로세스 입장에서는 가상메모리 공간도 물리메모리 공간으로 인식하는 것이다. 그리고 운영체제는 가상메모리에 걸쳐서 적재된 프로세스의 부분이 실제로 적재가 필요하다면 물리메모리 공간과 swap(변경) 해준다. 프로세스의 모든 코드가 한번에 물리메모리에서 돌아가는 일은 없다.
필요한 부분만 실제 물리 메모리로 올라가기만 하면 되기 때문에, 이 부분을 운영체제가 계속 swapping 해주는 것을 통해 가상메모리를 구현한다.
Swapping
두개의 프로세스를 통째로 바꿔치기 하는 개념.
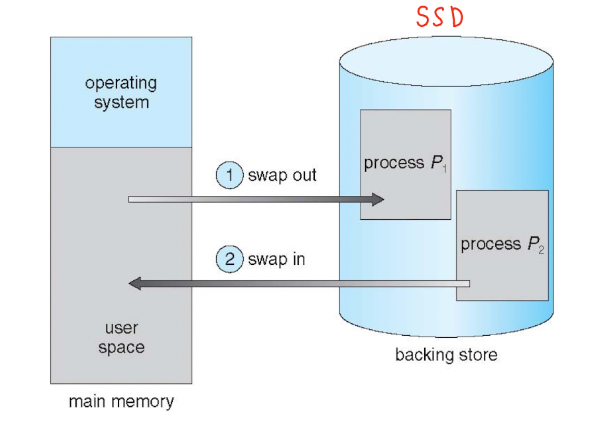
process P1은 memory -> SSD , process P2는 SSD -> memory(SSD에 swapping되면 swaparea라는 곳으로 저장됨)
근데 이 방법은 현대의 OS에서는 사용을 잘 하지않는다. SSD와 메모리사이에 프로세스를 통째로 옮기는것이 성능적으로 비효율적이기 때문.
Paging / Demand Paging
Paging
메모리 관리 기법 중 하나로, 프로그램이 실행될 때 메모리를 일정한 크기의 페이지로 나누어 관리하는 것을 말한다. 이때 각 페이지는 주소를 가지고 있으며, 필요한 페이지만 메모리에 로드하여 사용한다.
Demand Paging
Swapping과정을 최소화,해결하기 위해 나온 개념이다.
당장 사용될 주소 공간을 Page 단위로 메모리에 적재하는 방법을 의미한다. 여기서 중요한 점은 당장 실행할 페이지이며, 이 부분만 메모리에 적재하기 때문에 메모리 사용량이 감소하고, 입출력 오버헤드를 감소시킬 수 있다.
예를 들어 게임을 다운받고 실행한다고 가정해보자. 요즘 게임은 수십GB를 훌쩍 넘기는데 그걸 메인메모리에 모든 데이터를 담고 플레이한다면 과부화가 걸릴 것이다. 그래서 현재 플레이하고 있는 맵의 정보만 메모리 위에 두고 해당 루틴이 불려질 때 메모리에 올려주면 된다.(게임 플레이시 맵이 바뀔 때 로딩 시간이 있는 이유이기도 함.)
