Hashtable을 살펴보기 전에 잠깐 Java의 Map을 먼저 살펴보자.
public interface Map<K, V> {
// ...
interface Entry<K, V> { ... }
// ...
}Map은 Key-Value(키-값) 쌍을 Entry 타입으로 데이터를 저장하는 자료구조이다. 키는 고유하기 때문에 중복이 불가능하지만 값은 중복이 가능하다.
public class Hashtable<K,V>
extends Dictionary<K,V>
implements Map<K,V>, Cloneable, java.io.Serializable { ... }Java의 Hashtable은 이러한 Map을 구현한 클래스이다.
Hash function이란?
Hashtable을 알기 위한 사전 지식으로 Hash function이라는 것이 있다. 일반적인 의미로는 임의의 크기를 가지는 데이터를 고정된 크기의 해시값으로 변환하는 함수를 Hash function(해시 함수)라고 한다. Hashtable에서는 Key를 Object 클래스의 hashCode() 함수를 통해서 정수로 변환하는데, 여기서 hashCode()가 해시 함수이다.
Hashtable은 어떻게 동작하는가?
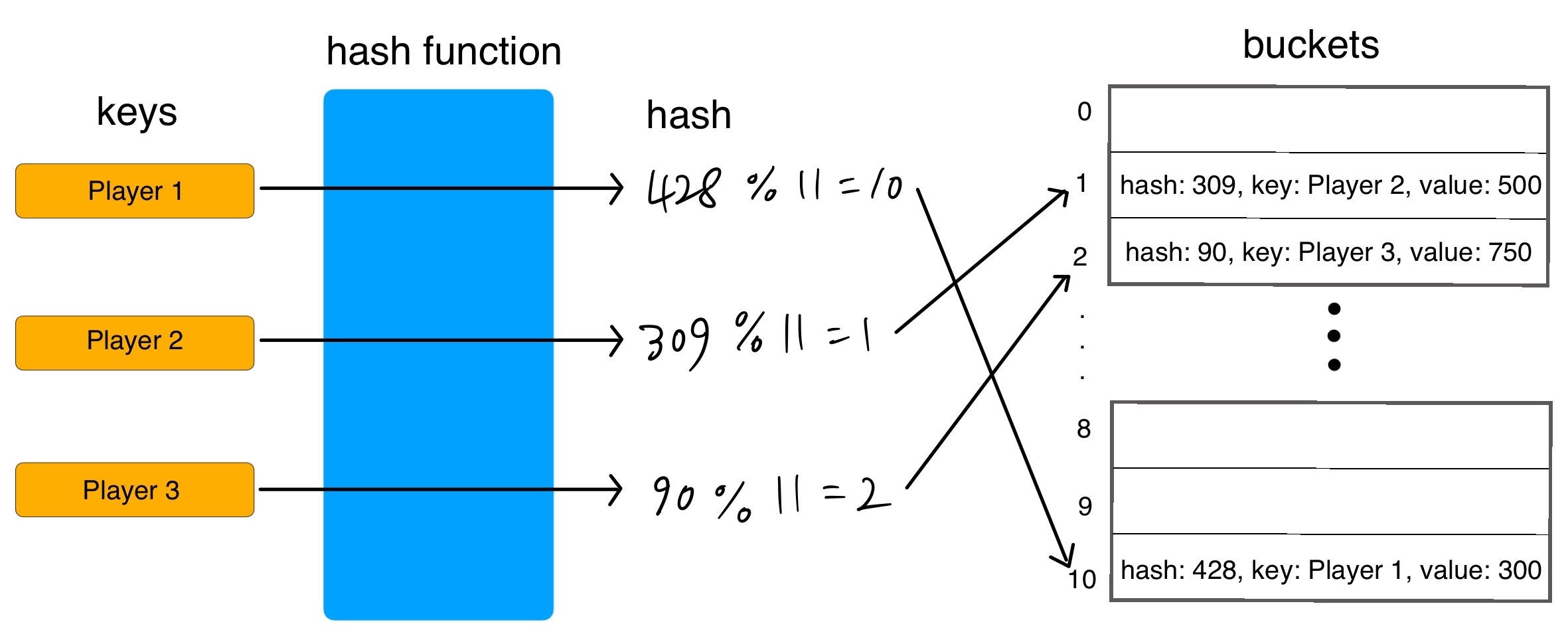
위의 그림은 게임 플레이어 닉네임을 key로 하고 각각의 점수를 value로 가지는 데이터를 Hashtable에 저장하는 것을 표현한 것이다.
프로그래밍 언어마다 세부적인 구현 내용은 다르겠지만, 대략적으로 Hashtable이 동작하는 과정은 위와 같다.
Hashtable은 내부적으로 배열을 통해서 요소를 관리하는데 배열의 크기를 capacity라고 한다. 위 그림에서 capacity는 11이다. 이 배열 각각의 공간을 bucket 혹은 slot이라고 부른다.
값이 저장되는 과정은 다음과 같다.
1. key와 해시 함수를 통해서 hash를 생성한다.
2. hash를 모듈로 연산자(나머지 연산자)를 통해서 나머지를 구한다. 나머지는 데이터가 저장될 bucket의 index이다.
3. 해당 bucket에 hash, key, value가 저장된다.
즉 고정된 크기를 가진 배열에 정수인 hash를 모듈로 연산을 통해 배열에 나눠서 저장하는 것이다. 그래서 배열의 장점인 무작위 접근(Random access) 덕분에 Hashtable은 조회 속도가 매우 빠르다. 시간 복잡도는 O(1)로 상수 시간이라는 의미이다.
Hash Collision (해시 충돌)
위와 같이 값을 저장하면 bucket마다 하나의 데이터만 편하게 저장할 것 같지만 실제로는 그렇지 않다.
1. key는 다른데 hash가 같을 때 (즉 hash % capacity도 같음)
2. key도 hash도 다른데 hash % capacity가 같을 때
이러한 경우 하나의 bucket에 들어가야 하는 데이터가 두 개 이상이 되는 상황이 발생한다. 이러한 상황을 Hash Collision, 해시 충돌이라고 한다.
해시 함수 알고리즘을 아무리 잘 설계해도 데이터가 많아질수록 해시 충돌은 일어날 수밖에 없다.
해시 충돌을 해결하는 방법에는 크게 두 가지가 있는데 오픈 어드레싱(Open Addressing) 방식과 개별 체이닝(Separate Chaing) 방식이다.
Open Adderssing (오픈 어드레싱)
오픈 어드레싱 방식은 해시 충돌 발생 시 탐사(Probing)을 통해서 빈 공간을 찾는 방식이다. 여기서는 가장 간단한 선형 탐사(Linear Probing)방식의 예를 살펴보겠다. 그림에서 bucket에 저장되는 데이터는 value만 표시되어 있다.
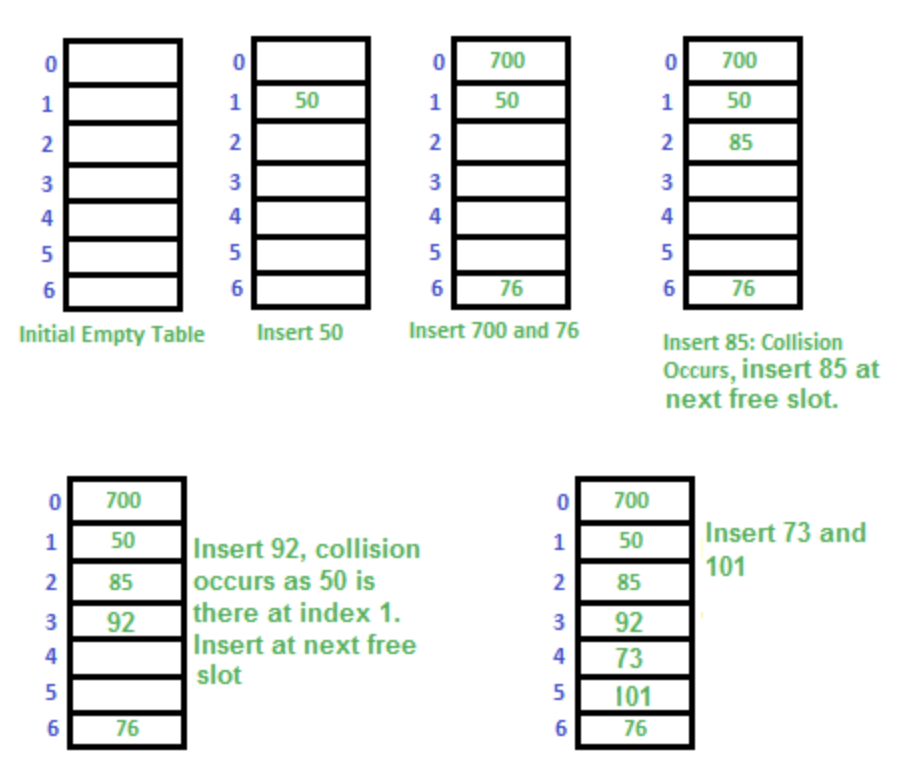
- 3번째 그림까지는 데이터 50, 700, 76을 문제없이 저장하였다.
- 4번째 그림에서 충돌이 발생했다. index가 1인 bucket에 85를 저장하고 싶은데 이미 50이 저장되어 있다. 다음 index의 bucket이 비어있는 것을 확인 후 85를 index 2 bucket에 저장하였다.
- 92를 index 1 bucket에 저장하고 싶은데 또 충돌이 발생하였다. 다음 index 2 bucket을 확인했는데 이미 85가 저장되어 있다. 그래서 그다음 index 3 bucket에 저장했다.
- 마지막 그림은 아무 문제 없이 다른 데이터를 저장한 모습이다.
이렇게 오픈 어드레싱 방식은 비어있는 다른 bucket을 찾아서 비어있는 bucket에 저장하는 방식이다.
Separate Chaining (개별 체이닝)
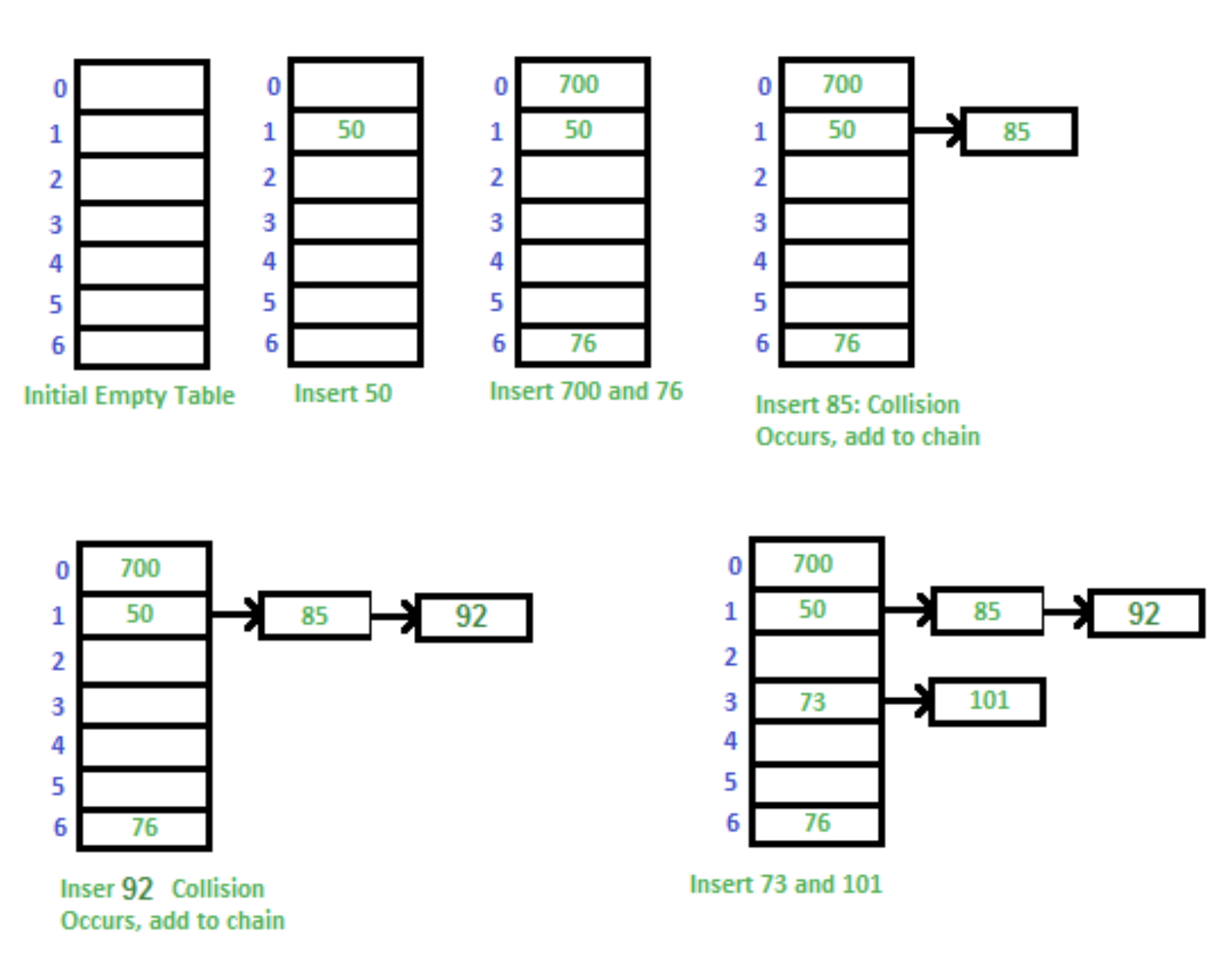
- 3번째 그림까지 데이터 50, 700, 76을 문제없이 저장하였다.
- 4번째 그림에서 충돌이 발생했다. 이때부터 연결 리스트(LinkedList) 방식으로 데이터가 저장된다. 그림에서는 단방향 연결 리스트이다.
- 5번째 그림에서 또다시 충돌이 발생하였고 체인을 추가하여 계속 연결 리스트로 데이터를 저장한다.
- 마지막 그림도 마찬가지로 연결 리스트를 통해 충돌을 해결한 모습이다.
Java의 Hashtable은 개별 체이닝 방식을 사용하고 있다.
Java의 Hashtable
이제부터는 코드로 Java의 Hashtable을 살펴볼 것이다. 먼저 Hashtable의 주요 필드를 살펴보자.
public class Hashtable<K,V>
extends Dictionary<K,V>
implements Map<K,V>, Cloneable, java.io.Serializable {
private transient HashtableEntry<?,?>[] table;
private transient int count;
private int threshold;
private float loadFactor;
// ...
}table 필드는 HashtableEntry 타입의 배열이다. 이 배열을 통해서 요소를 관리한다.
count는 해시 테이블에서 HashtableEntry의 총 개수이다.
threshold는 해시 테이블의 크기(capacity)를 증가시키는 기준값을 말한다.
loadFactor는 해시 테이블의 현재 버킷이 얼마나 찼는지를 나타내는 비율을 의미한다.
여기서 HashtableEntry 클래스도 살펴보자.
private static class HashtableEntry<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
HashtableEntry<K,V> next;
protected HashtableEntry(int hash, K key, V value, HashtableEntry<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
// ...
}데이터를 저장할 때 HashtableEntry 타입으로 저장되는데 HashtableEntry는 hash, key, value, next로 구성되어 있다.
hash를 저장하는 이유는 capacity(용량)가 늘어나면 모듈로 연산을 다시 진행하여 각각의 index를 다시 지정해야 한다. 이때 미리 저장해놓은 hash를 통해 모듈로 연산을 진행한다. 만약 hash를 저장해놓지 않는다면, key와 hash function으로 hash를 다시 만들어야 하는 불필요한 작업이 생긴다.
next는 버킷에서 연결리스트로 데이터가 관리될 때 사용된다. 다음 Entry를 가리키기 위한 포인터이다. 만약 이중 연결 리스트였다면 prev, next 둘다 있었겠지만 단방향 연결 리스트이기 때문에 next만 존재한다. 만약 가리키는 Entry가 없다면 next는 null이다.
val hashtable = Hashtable<String, Int>() 이러한 코드를 작성했을 때 해시테이블이 어떻게 생성되는지 살펴보자.
public Hashtable() {
this(11, 0.75f);
}생성자 인자로 아무것도 전달하지 않으면 다른 생성자가 호출되는데 11과 0.75f가 인자로 전달된다.
public Hashtable(int initialCapacity, float loadFactor) {
// ...
this.loadFactor = loadFactor;
table = new HashtableEntry<?,?>[initialCapacity];
// ...
threshold = (int)Math.min(initialCapacity, MAX_ARRAY_SIZE + 1);
}loadFactor가 0.75f로 초기화되고, table이 initialCapactiy가 11인 배열로 초기화되고, threshold는 initialCapacity와 배열의 max size 중 최소값이므로 사실상 initialCapacity와 같은 값이다.
이번엔 hashtable.put("Player 1", 300) 이렇게 put했을 때의 코드를 살펴보자.
public synchronized V put(K key, V value) {
// ...
HashtableEntry<?,?> tab[] = table;
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
@SuppressWarnings("unchecked")
HashtableEntry<K,V> entry = (HashtableEntry<K,V>)tab[index];
for(; entry != null ; entry = entry.next) {
if ((entry.hash == hash) && entry.key.equals(key)) {
V old = entry.value;
entry.value = value;
return old;
}
}
addEntry(hash, key, value, index);
return null;
}tab[] 지역변수를 선언하고 table로 초기화한다. 그리고 key의 hashCode() 메서드를 활용해서 정수 hash를 초기화한다.
그 다음 (hash & 0x7FFFFFFF) % tab.length로 모듈로 연산을 통해서 index를 초기화한다. 여기서 hash & 0x7FFFFFFF 부분에서 &는 AND 비트 연산자이다. hash가 음수가 나오면 & 0x7FFFFFFF로 비트 연산을 하여 양수로 바꿔주기 위함이다.
그 다음 반복문을 통해서 만약 hash가 같고 key도 같은 Entry를 발견하면 value를 새로운 value로 업데이트한다. 이것은 put() 메서드가 단순히 값을 추가하는 용도가 아니라 기존값을 업데이트하는 데에도 사용된다는 것을 의미한다. 만약 값을 업데이트하는 게 아니라면 addEntry()를 통해서 Entry를 추가한다.
private void addEntry(int hash, K key, V value, int index) {
HashtableEntry<?,?> tab[] = table;
if (count >= threshold) {
// Rehash the table if the threshold is exceeded
rehash();
tab = table;
hash = key.hashCode();
index = (hash & 0x7FFFFFFF) % tab.length;
}
// Creates the new entry.
@SuppressWarnings("unchecked")
HashtableEntry<K,V> e = (HashtableEntry<K,V>) tab[index];
tab[index] = new HashtableEntry<>(hash, key, value, e);
count++;
modCount++;
}만약 threshold보다 count가 크거나 같으면 rehash()를 통해서 capacity를 늘린 후에, 해당 Entry의 hash와 index를 다시 계산하고 새로운 entry를 생성한다.
그런 경우가 아니라면 새로운 entry를 생성하는 것만 진행한다.
HashtableEntry<K,V> e = (HashtableEntry<K,V>) tab[index] 이 과정은 기존의 Entry를 e라는 변수에 할당하는 과정이다.
tab[index] = new HashtableEntry<>(hash, key, value, e); 이 과정은 새로운 Entry를 기존의 자리에 할당하는 것이다. 여기서 e가 next 파라미터의 자리로 전달되는 것을 볼 수 있다.
이것은 새로운 entry가 기존 entry의 next로 설정되는 것이 아니라, 기존 entry가 새로운 entry의 next로 설정되는 것이다. 좀 더 쉽게 말하면 새로운 entry가 뒤로 붙는 것이 아니라 앞에 붙어서 연결 리스트 형태를 띄는 것이다.
마지막으로 rehash()를 통해서 어떻게 capacity를 늘리는지 확인해보자. 코드가 길어서 두 개로 나눴다.
protected void rehash() {
int oldCapacity = table.length;
HashtableEntry<?,?>[] oldMap = table;
// overflow-conscious code
int newCapacity = (oldCapacity << 1) + 1;
if (newCapacity - MAX_ARRAY_SIZE > 0) {
if (oldCapacity == MAX_ARRAY_SIZE)
// Keep running with MAX_ARRAY_SIZE buckets
return;
newCapacity = MAX_ARRAY_SIZE;
}
HashtableEntry<?,?>[] newMap = new HashtableEntry<?,?>[newCapacity];
// ...oldCapacity는 현재 initialCapacity이므로 11이고 newCapacity는 계산결과 23이다. capacity가 23인 새로운 HashtableEntry 타입의 배열을 newMap에 할당한다.
// ...
modCount++;
threshold = (int)Math.min(newCapacity * loadFactor, MAX_ARRAY_SIZE + 1);
table = newMap;
for (int i = oldCapacity ; i-- > 0 ;) {
for (HashtableEntry<K,V> old = (HashtableEntry<K,V>)oldMap[i] ; old != null ; ) {
HashtableEntry<K,V> e = old;
old = old.next;
int index = (e.hash & 0x7FFFFFFF) % newCapacity;
e.next = (HashtableEntry<K,V>)newMap[index];
newMap[index] = e;
}
}
}newCapacity(23)과 loadFactor(0.75f)를 곱한 값과 MAX_ARRAY_SIZE + 1 중 최소값을 int로 형변환한다. 그리고 그 값을 threshold에 할당한다. 현재 값들을 기준으로 계산 결과 threshold는 17이 될 것이다.
그리고 table 필드에 새로운 배열인 newMap을 할당한다. 마지막으로 반복문을 통해 각각 Entry의 index를 다시 계산하여 Entry를 재분배한다.
배열의 크기는 초기화 이후 변경되지 않기 때문에, 이렇게 배열을 새로 생성하여 새로운 메모리 공간에 할당하고 table의 참조를 새로 생성한 배열로 바꾸는 것이다.
이렇게, 리해시(Rehash)란 해시 테이블(Hash Table)의 용량을 확장하거나 축소할 때, 기존의 키-값 쌍들을 새로운 해시 테이블로 다시 배치하는 과정을 말한다. 리해시는 주로 로드 팩터가 일정 수준을 초과할 때 발생한다.
참고자료
