코루틴 디스패처란?
Dispatcher라는 단어를 보면 코루틴 디스패처가 무슨 일을 하는지 대략 알 수 있다. Dispatch는 보내다, 전송하다 라는 뜻을 가지고 있다. 단어의 의미를 곱씹어서 알아보면 CoroutineDispatcher는 코루틴을 스레드로 보내서 실행시키는 주체라는 것을 알 수 있다.
코루틴 디스패처의 작동 흐름
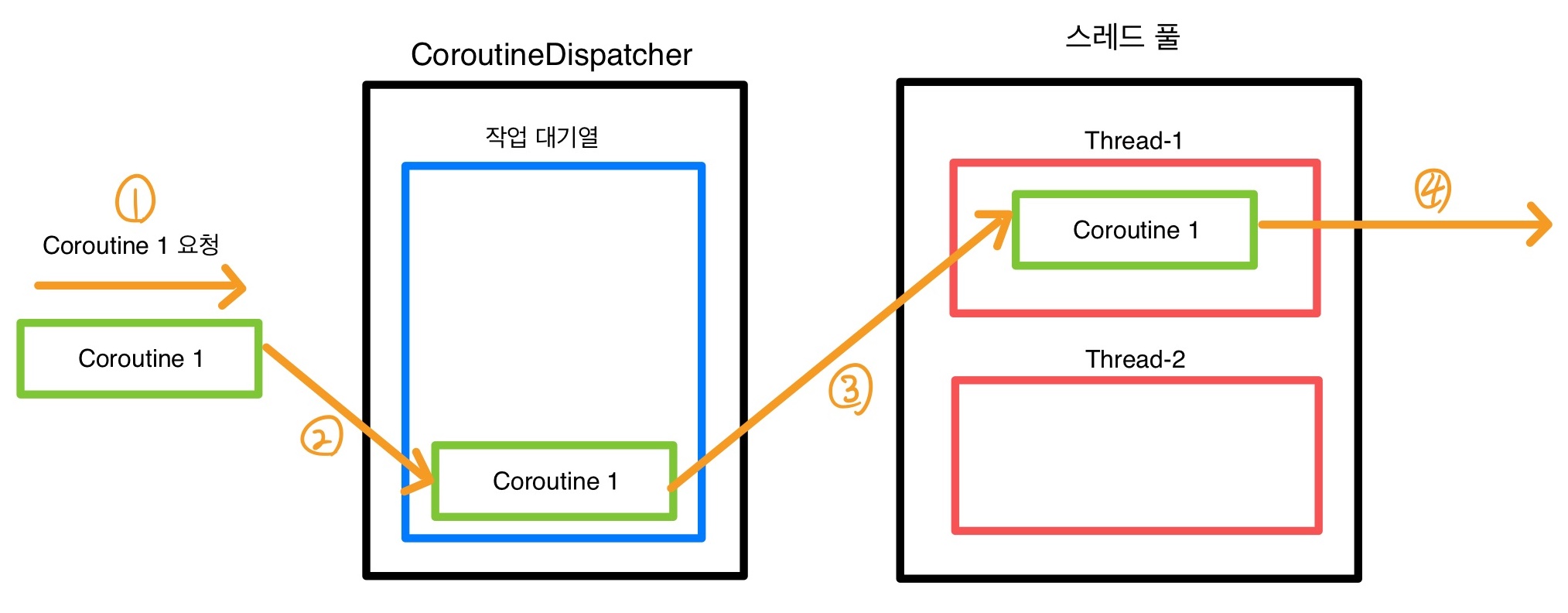
그림의 1, 2, 3, 4번에 따라서 대략적인 작동 흐름을 설명하겠다.
- CoroutineDispatcher 객체에 Coroutine 1 실행 요청
- CoroutineDispatcher 객체가 요청받은 코루틴을 작업 대기열(Queue)에 적재
- CoroutineDispatcher 객체가 사용할 수 있는 스레드가 있는지 확인하고 해당 스레드에 코루틴을 보내서 실행시킨다.
- Coroutine 1이 실행 완료 혹은 일시 중단 상태가 되면 스레드는 다시 자유로운 상태가 된다.
그림에서는 스레드 풀에 스레드가 두 개이기 때문에 그림에서의 CoroutineDispatcher는 멀티 스레드 디스패처이다. 하지만 스레드 풀에 스레드가 한 개면 디스패처는 싱글 스레드 디스패처라고 부른다.
만약 위의 예시에서 Thread-1과 Thread-2에 Coroutine 1, Coroutine 2가 실행중인 상태에서 Coroutine 3 실행 요청을 받는다면, 사용 가능한 스레드가 없으므로 작업 대기열에 Coroutine 3를 적재해둔다. 그 다음 실행 중인던 코루틴이 완료 혹은 일시중단되어 스레드의 사용 권한을 양보하면, 그 때 디스패처가 Coroutine 3를 사용 가능한 스레드에 보내고 실행시킨다.
미리 정의된 코루틴 디스패처
지금까지 코루틴 디스패처의 일반적인 작동 흐름을 설명했다. 하지만 사실 CoroutineDispatcher는 abstract class로, 이를 상속하는 클래스의 객체를 생성하거나, newFixedThreadPoolContext() 함수를 사용하여 디스패처 객체를 생성할 수 있다.
그런데 코루틴은 개발자가 직접 CoroutineDispatcher 객체를 생성하는 것을 권장하지 않는다. 특정 용도를 위해 만들어진 디스패처가 이미 존재하는데 그걸 모르고 다시 디스패처를 만들어 리소스를 낭비하게 될 가능성이 크기 때문이다. 보통 여러 개발자가 개발에 참여했을 때 이러한 상황이 발생할 수 있다. 그래서 이를 방지하기 위해 미리 정의된 코루틴 디스패처가 존재한다.
- Dispatchers.Main : 메인 스레드를 사용하기 위한 디스패처
- Dispatchers.IO : 네트워크 요청, 파일 입출력, DB 접근 등 입출력(I/O) 작업을 위한 디스패처
- Dispatchers.Default : CPU를 많이 사용하는 연산 작업(CPU 바운드 작업)을 위한 디스패처. 예를 들면 복잡한 수학 계산, 이미지 처리 또는 무거운 데이터 변환 작업, 정렬, 검색 등의 알고리즘 등이 있다.
Dispatchers.IO와 Dispatchers.Default는 같은 스레드풀을 사용한다
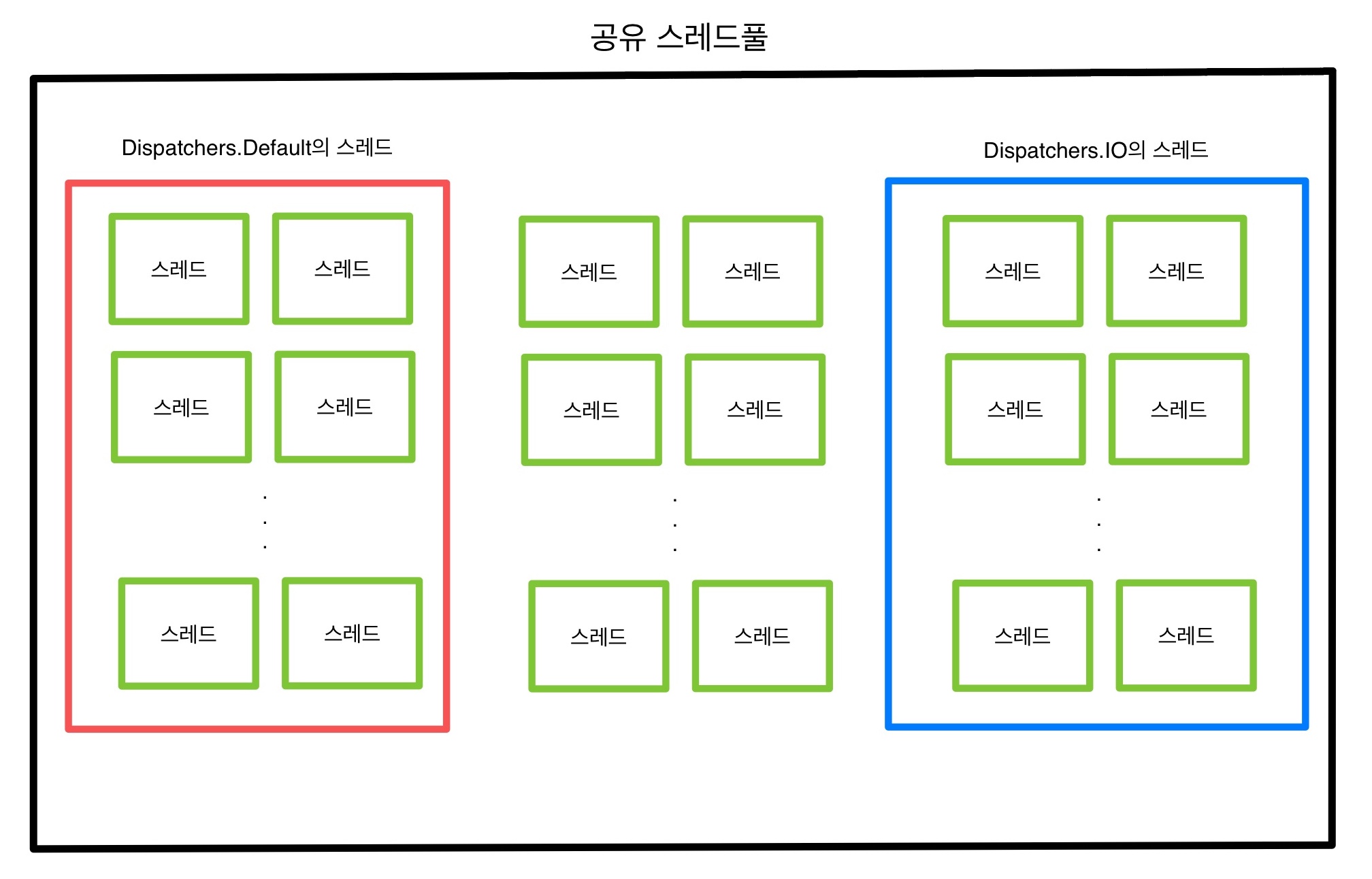
코루틴은 스레드의 생성과 관리를 효율적으로 할 수 있도록 애플리케이션 레벨의 공유 스레드풀을 제공하는데, Dispatchers.IO와 Dispatchers.Default는 이 스레드풀을 같이 사용한다. 공유 스레드 풀에서는 스레드를 무제한으로 생성 가능하다.
fun main() = runBlocking<Unit> {
launch(Dispatchers.IO) {
println("[${Thread.currentThread().name}] 실행")
}
launch(Dispatchers.Default) {
println("[${Thread.currentThread().name}] 실행")
}
}
// 출력 :
[DefaultDispatcher-worker-1] 실행
[DefaultDispatcher-worker-1] 실행코드로 확인 가능하다. 위 코드의 출력 결과에서 둘다 Thread.currentThread().name이 DefaultDispatcher-worker-1로 같은 것을 볼 수 있다. 이를 통해 Dispatchers.IO와 Dispatchers.Default가 같은 스레드풀을 사용한다는 것을 알 수 있다.
Dispatchers.IO와 Dispatchers.Default의 최대 사용가능한 스레드 수
Dispatchers.IO의 최대 사용가능한 스레드 수는 64와 사용가능한 프로세서의 수 중에서 더 큰 값으로 설정된다.
// Dispatchers.kt
@JvmStatic
public val IO: CoroutineDispatcher = DefaultIoScheduler
// Dispatcher.kt
internal object DefaultIoScheduler : ExecutorCoroutineDispatcher(), Executor {
private val default = UnlimitedIoScheduler.limitedParallelism(
systemProp(
IO_PARALLELISM_PROPERTY_NAME,
64.coerceAtLeast(AVAILABLE_PROCESSORS)
)
)
//...
}Dispatchers.IO는 DefaultIoScheduler 객체인데 선언된 곳을 보면 64.coerceAtLeast(AVAILABLE_PROCESSORS)라는 코드가 있다. coerceAtLeast() 함수는 두 개의 정수 중 큰 값을 리턴하는 함수이다.
Dispatchers.Default의 최대 사용가능한 스레드 수는 2와 사용가능한 프로세서의 수 중 더 큰 값으로 설정된다.
// Dispatchers.kt
@JvmStatic
public actual val Default: CoroutineDispatcher = DefaultScheduler
// Dispatcher.kt
internal object DefaultScheduler : SchedulerCoroutineDispatcher(
CORE_POOL_SIZE, MAX_POOL_SIZE,
IDLE_WORKER_KEEP_ALIVE_NS, DEFAULT_SCHEDULER_NAME
) { ... }Dispatchers.Default는 DefaultScheduler 객체인데 선언된 곳을 보면 CORE_POOL_SIZE라는 인자를 생성자로 전달한다.
/**
* The maximum number of threads allocated for CPU-bound tasks at the default set of dispatchers.
*
* NOTE: we coerce default to at least two threads to give us chances that multi-threading problems
* get reproduced even on a single-core machine, but support explicit setting of 1 thread scheduler if needed
*/
@JvmField
internal val CORE_POOL_SIZE = systemProp(
"kotlinx.coroutines.scheduler.core.pool.size",
AVAILABLE_PROCESSORS.coerceAtLeast(2),
minValue = CoroutineScheduler.MIN_SUPPORTED_POOL_SIZE
)CORE_POOL_SIZE가 작성된 곳의 주석 설명을 해석해보면, CPU 바운드 작업에 할당되는 최대 스레드 개수라고 해석할 수 있다. 그리고 AVAILABLE_PROCESSORS.coerceAtLeast(2) 코드를 보고 2와 사용 가능한 프로세서의 수 중 더 큰 값으로 설정된다는 것을 유추할 수 있다.
그런데 Kotlin 공식문서에서 IO와 Default 부분을 살펴보았는데, IO 문서에서는 "It defaults to the limit of 64 threads or the number of cores (whichever is larger)." 라는 문장이 있고, Default 문서에는 "By default, the maximum number of threads used by this dispatcher is equal to the number of CPU cores, but is at least two."라는 문장이 있다.
대략 해석해보면 IO는 "64개의 스레드 혹은 CPU 코어의 개수 중 큰 값으로 제한된다.", Default는 "최대 스레드 개수는 CPU 코어의 개수와 같다(적어도 2개)"로 해석할 수 있다. 프로세서와 CPU 코어는 다른 개념으로 알고 있는데 코드에서는 왜 AVAILABLE_PROCESSORS가 사용되었는지 모르겠다. 이 부분에 대해서는 좀더 알아본 뒤에 글을 수정할 예정이다.
참고자료
