Flow에서 Buffering은 데이터 스트림의 생산(production)과 소비(collecting) 속도가 다를 때 데이터를 임시로 저장하여 균형을 맞추는 방식이다.
1. Buffering이 필요한 이유
fun simple(): Flow<Int> = flow {
for (i in 1..3) {
delay(100) // 비동기적으로 100ms를 기다린다고 가정
emit(i) // 다음 값을 방출
}
}
fun main() = runBlocking<Unit> {
val time = measureTimeMillis {
simple().collect { value ->
delay(300) // 300ms 동안 처리한다고 가정
println(value)
}
}
println("총 수집 시간: $time ms")
}
/* 결과 :
1
2
3
Collected in 1230 ms
*/예를 들어 simple Flow의 방출이 느려서 하나의 값을 생산하는 데 100ms가 걸리고, 수집도 느려서 수집된 값을 처리하는 데 300ms가 걸린다고 가정하자. 그러면 모든 수집이 끝나는 데 총 100 + 300 + 100 + 300 + 100 + 300 = 1200ms 가량 시간이 소요된다.
이것은 기본적으로 컨텍스트 보존의 특성에 따라 하나의 코루틴에서 데이터의 생산과 소비가 일어나서 순차적으로 처리되기 때문에 이 정도의 시간이 소요된다.
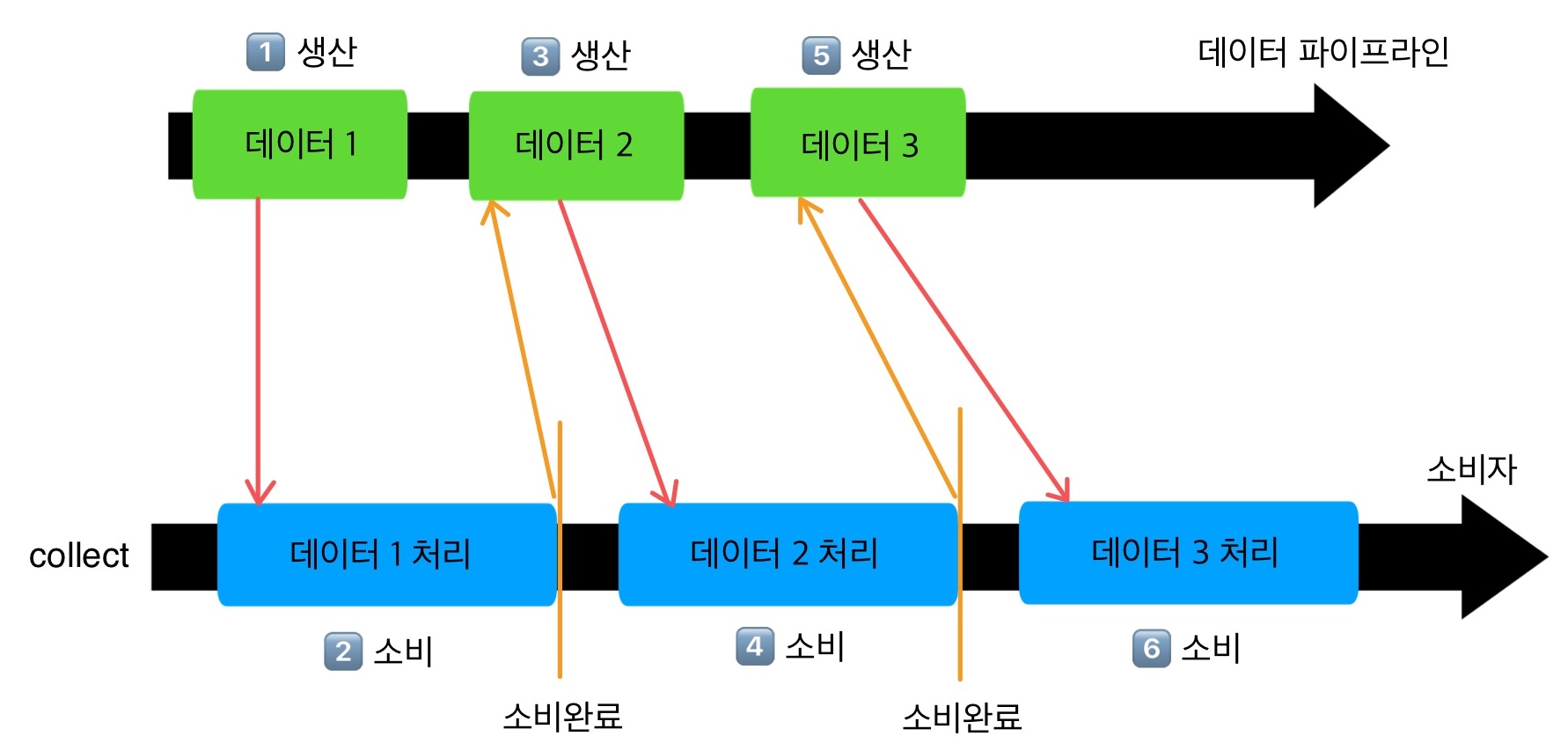
그림과 같이 1.생산 -> 2.소비 -> 소비완료 후 3.생산 -> 4.소비 -> 소비완료 후 5.생산 -> 6.소비 의 과정을 순차적으로 거치기 때문이다. 이 과정을 효율적으로 처리하기 위한 것이 buffer이다.
2. buffer 연산자
buffer의 의미를 사전에서 찾아보면 "어떤 장치에서 다른 장치로 데이터를 송신할 때 일어나는 시간의 차이나 데이터 흐름의 속도 차이를 조정하기 위해 일시적으로 데이터를 기억시키는 장치"라고 되어있다. 일시적으로 데이터를 기억시키는 존재라는 점을 buffer 연산자와 연관지어서 생각해보면 이해가 수월하다.
fun simple(): Flow<Int> = flow {
for (i in 1..3) {
delay(100) // 비동기적으로 100ms를 기다린다고 가정
emit(i) // 다음 값을 방출
}
}
fun main() = runBlocking<Unit> {
val time = measureTimeMillis {
simple()
.buffer() // 방출을 버퍼링하여 기다리지 않음
.collect { value ->
delay(300) // 300ms 동안 처리한다고 가정
println(value)
}
}
println("총 수집 시간: $time ms")
}
/* 결과 :
1
2
3
Collected in 1050 ms
*/첫번째 방출을 위해 100ms만을 기다리고 방출된 값들을 처리하는 데 각각 300ms의 시간이 걸리는 효율적인 처리 파이프라인을 생성한 것이다. 그래서 전체 실행 시간이 100 + 300 + 300 + 300 = 1000ms 가량 소요된다.
이처럼 buffer 연산자를 사용하여 simple Flow의 방출 코드를 수집 코드와 동시에 실행할 수 있다. 방출과 수집을 위한 코루틴으로 서로 다른 코루틴을 사용하였기에 가능한 일이다.
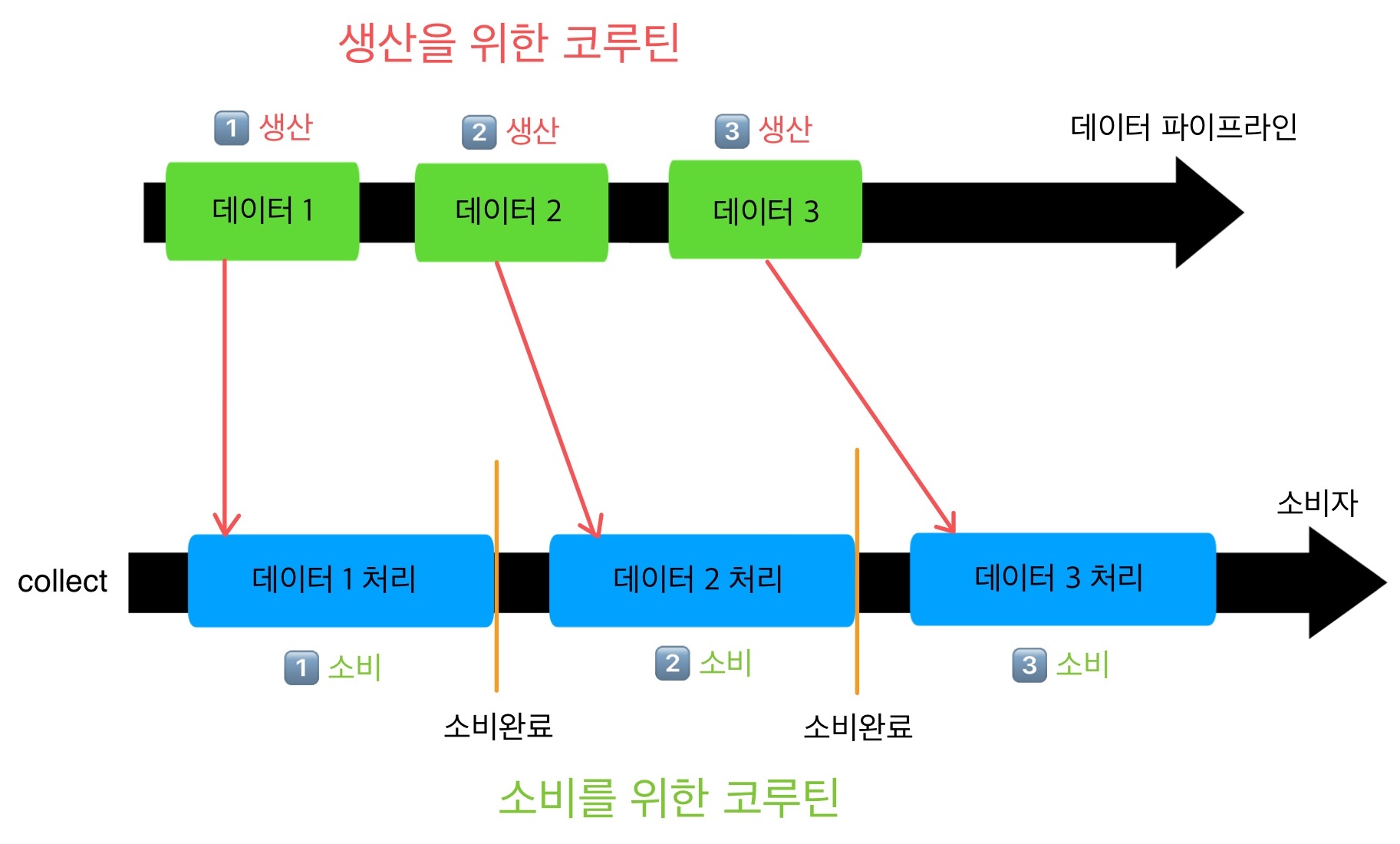
데이터 생산은 별도의 코루틴에서 수행되므로 계속해서 생산이 일어나고, 생산된 값의 소비가 끝나는 대로 바로바로 다음 데이터가 소비하는 쪽으로 전달된다. 이를 통해 데이터 생산에 발생하는 지연을 방지할 수 있다.
fun simple(): Flow<Int> = flow {
for (i in 1..3) {
delay(100)
emit(i)
println("Emit: ${Thread.currentThread().name}")
}
}
fun main() = runBlocking<Unit> {
val time = measureTimeMillis {
simple()
.buffer()
.collect {
delay(300)
println("Collect: ${Thread.currentThread().name}")
}
}
println("Collected in $time ms")
}
/* 결과 :
Emit: main @coroutine#2
Emit: main @coroutine#2
Emit: main @coroutine#2
Collect: main @coroutine#1
Collect: main @coroutine#1
Collect: main @coroutine#1
Collected in 1053 ms
*/실제로 코드를 통해 방출과 수집이 일어나는 코루틴은 다른 코루틴이라는 것을 확인할 수 있다. buffer라는 단어의 의미를 되새겨 보면, 일시적으로 방출된 값을 기억하였다가 이전 값의 소비가 끝났을 때 기억했던 값을 제공하기 위한 연산자라는 의미로 buffer라는 이름이 함수의 이름으로 사용되지 않았을까 추측한다.
3. buffer 연산자의 순차처리 여부와 컨텍스트 보존 여부
일단 위의 예시 코드의 결과에서 볼 수 있듯이 순차처리가 이루어지지 않는다는 것을 확인 할 수 있다. buffer 연산자를 사용하면 순차처리가 이루어지지 않는다.
컨텍스트 보존 특성도 지켜지지 않는다. 다른 코루틴을 사용한다는 거 자체가 코루틴 컨텍스트 요소 중 하나인 Job이 다르다는 것을 의미한다.
fun simple(): Flow<Int> = flow {
for (i in 1..3) {
delay(100)
println("Emitting: ${currentCoroutineContext()}")
emit(i)
}
}
fun main() = runBlocking<Unit> {
simple()
.buffer()
.collect {
delay(300)
println("Collecting: ${currentCoroutineContext()}")
}
}
/* 결과 :
Emitting: [ProducerCoroutine{Active}@e580929, BlockingEventLoop@1cd072a9]
Emitting: [ProducerCoroutine{Active}@e580929, BlockingEventLoop@1cd072a9]
Emitting: [ProducerCoroutine{Active}@e580929, BlockingEventLoop@1cd072a9]
Collecting: [ScopeCoroutine{Active}@13969fbe, BlockingEventLoop@1cd072a9]
Collecting: [ScopeCoroutine{Active}@13969fbe, BlockingEventLoop@1cd072a9]
Collecting: [ScopeCoroutine{Active}@13969fbe, BlockingEventLoop@1cd072a9]
*/현재 코루틴 컨텍스트를 출력하는 currentCoroutineContext()를 통해 출력 결과를 살펴보면 다른 Job을 사용하고 있다는 것을 알 수 있다.
4. buffer 연산자는 채널을 사용하여 방출된 요소를 전달한다
buffer 연산자가 방출된 값을 소비를 위한 코루틴에 어떻게 전달하는지를 알고 싶어서 Kotlin 공식 api 문서를 참고하였다. 이 파트에서 보여주는 코드는 모두 공식 api 문서에서 볼 수 있다.
flowOf("A", "B", "C")
.onEach { println("1$it") }
.buffer() // <--------------- onEach와 collect 사이에 버퍼
.collect { println("2$it") }이 코드는 코드를 실행하기 위해 두 개의 코루틴을 사용한다.
P : -->-- [1A] -- [1B] -- [1C] ---------->-- // flowOf(...).onEach { ... }
|
| channel // buffer()
V
Q : -->---------- [2A] -- [2B] -- [2C] -->-- // collect(공식문서에서 코루틴을 표현하는 데 P와 Q를 사용했는데 특별한 약자는 아닌 것 같다.)
이 코드를 호출하는 코루틴 Q는 collect를 실행하고, buffer 연산자 이전의 코드인 flowOf(...).onEach { ... }는 별도의 새로운 코루틴 P에서 실행된다. 즉 서로 다른 코루틴 P와 Q에서 동시에 실행된다. 여기까지는 글 상단의 이전 파트에서 봤던 내용과 비슷한 내용이다.
근데 여기서 코루틴 P에서 방출된 요소를 코루틴 Q로 전달하기 위해 두 코루틴 사이에 채널이 사용되었다는 것을 확인할 수 있다. 채널(Channel)은 코루틴끼리의 통신을 위한 기본적인 방법이다.
fun <T> Flow<T>.buffer(
capacity: Int = BUFFERED,
onBufferOverflow: BufferOverflow = BufferOverflow.SUSPEND
): Flow<T>buffer 함수로 두 가지 파라미터가 전달되는데 모두 채널이라는 개념과 관련된 파라미터이다.
먼저 capacity는 채널의 버퍼 크기를 결정하는 파라미터로 무조건 0 이상이어야 한다. 기본값은 Channel.Factory의 상수 BUFFERED인데 명시적으로 0 이상의 Int값을 지정하는 것도 가능하다.
/**
* `Channel(...)` 팩토리 함수에서 기본 버퍼 용량을 가진 버퍼된 채널을 요청합니다.
* 오버플로 시 [BufferOverflow.SUSPEND]에 의해 일시 중단되는 채널의 기본 용량은
* 64이며, JVM에서 [DEFAULT_BUFFER_PROPERTY_NAME]을 설정하여 재정의할 수 있습니다.
* 일시 중단되지 않는 채널의 경우 용량이 1인 버퍼가 사용됩니다.
*/
public const val BUFFERED: Int = -2아까 capacity는 0 이상이어야 한다고 했는데 -2이다. 이것은 기본 버퍼 용량 사용을 위한 플래그로 사용될 뿐 실제 용량과는 관계가 없다. 번역된 주석을 보면 기본 capacity(용량)이 64로 지정된다는 것을 알 수 있다.
다른 상수는 아래와 같다.
UNLIMITED : 무제한 용량의 버퍼 사용
RENDEZVOUS : 버퍼를 가지지 않음
CONFLATED : 버퍼의 용량은 1이고 onBufferOverflow 정책을 DROP_OLDEST로 설정함으로써, 마지막에 제공된 데이터만 보장
두번째 파라미터로 onBufferOverflow는 버퍼가 오버플로우되었을 때의 정책을 결정한다. 만약 방출하는 데 소요되는 시간은 짧은데 방출된 요소를 소비하는 데 시간이 오래 걸린다면, 버퍼에 방출된 요소가 계속 쌓이고 결국 오버플로우가 발생할 것이다. 그래서 그러한 상황일 때 어떻게 처리할 것인지 정책을 결정한다.
SUSPEND : 더이상의 데이터를 버퍼에 받아들이지 않도록 방출을 일시중단한다.
DROP_OLDEST : 버퍼의 가장 오래된 값이 버려지고 최신 방출된 값이 버퍼에 추가된다.
DROP_LATEST : 버퍼를 그대로 유지하면서 방출 중인 최신 값을 버린다.
buffer 연산자에서 onBufferOverflow의 기본값은 SUSPEND이다.
5. buffer 연산자와 flowOn 연산자의 차이점

Kotlin 공식 가이드의 Buffering 파트 설명에 따르면 flowOn 연산자는 CoroutineDispatcher을 변경해야 할 때 동일한 buffering 메커니즘을 사용한다. 하지만 buffer 연산자는 flowOn이 실행 Context(코루틴 컨텍스트)를 변경하는 것과 다르게 명시적으로 buffering을 요청한다.
일단 첫 번째 문장에서 두 가지가 동일한 buffering 메커니즘을 사용한다고 하는데, 안타깝게도 이 부분에 대해 내부 코드에서 자세히 파악하지는 못했다. 하지만 코드에서 유사성을 발견할 수 있었다.
public fun <T> Flow<T>.buffer(capacity: Int = BUFFERED, onBufferOverflow: BufferOverflow = BufferOverflow.SUSPEND): Flow<T> {
// ...
return when (this) {
is FusibleFlow -> fuse(capacity = capacity, onBufferOverflow = onBufferOverflow)
else -> ChannelFlowOperatorImpl(this, capacity = capacity, onBufferOverflow = onBufferOverflow)
}
}
public fun <T> Flow<T>.flowOn(context: CoroutineContext): Flow<T> {
checkFlowContext(context)
return when {
context == EmptyCoroutineContext -> this
this is FusibleFlow -> fuse(context = context)
else -> ChannelFlowOperatorImpl(this, context = context)
}
}동일하게 ChannelFlowOperatorImpl 객체가 사용되기 때문에 동일한 buffering 메커니즘을 사용한다고 설명한 것 같다. 아마 flowOn 연산자도 내부적으로 채널의 버퍼를 이용하여 코루틴 간 통신을 지원하는 것으로 추측된다.
그리고 두 번째 문장을 해석하자면, flowOn을 통해 CoroutineDispatcher를 변경했을 때는 실행 코루틴 컨텍스트가 변경되어 다른 스레드에서 실행되는 것과 다르게, buffer 연산자는 명시적으로 buffering을 요청하기 때문에 같은 스레드에서 실행된다.
참고자료
