Array와 ArrayList는 모든 데이터가 메모리 상에 연속적으로 존재하지만, LinkedList(연결 리스트)는 메모리상에서 불연속적으로 존재하는 데이터를 서로 연결(link)한 상태로 구성되어 있다.
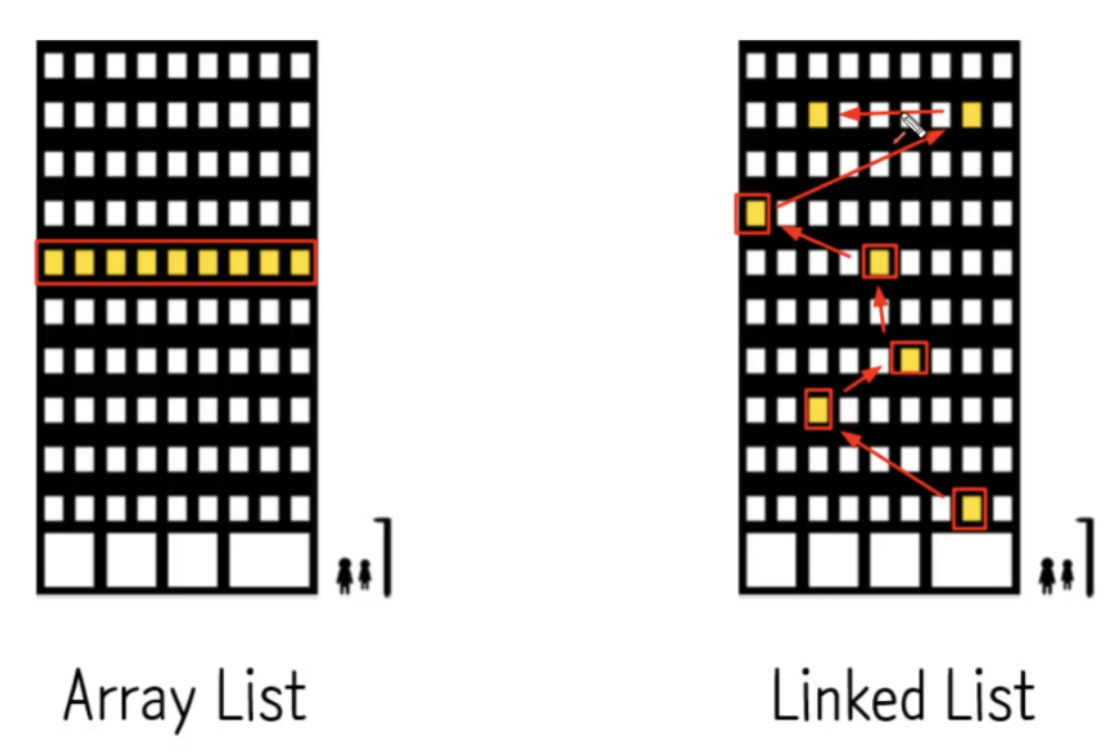
ArrayList와 LinkedList의 메모리 상에서의 모습을 그림으로 비유하자면 위와 같다.
LinkedList(연결 리스트)의 종류에는 단방향 연결 리스트(singly linked list), 양방향 연결 리스트(doubly linked list), 양방향 원형 연결 리스트(doubly circular linked list), 이렇게 3가지가 존재한다.
Kotlin에서 LinkedList를 사용하면 Java의 LinkedList를 사용하는데, Java의 LinkedList는 양방향 연결 리스트(doubly linked list)이므로 양방향 연결 리스트에 대해 좀더 중점적으로 알아보겠다.
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}Java의 LinkedList는 내부적으로 Node 객체를 사용하는데 Node는 item, next, prev로 이루어져있다. item은 요소 값이고 next는 다음 Node 메모리 주소값을 저장하며 prev는 이전 Node 메모리 주소값을 저장한다. prev와 next는 조금 더 전문적인 용어로 포인터라고 부르는데 포인터는 메모리 주소값을 저장하는 변수를 의미한다. 그림으로 표현하면 다음과 같다.

그리고 맨처음 노드를 Head라고 부르며 맨 마지막 노드를 Tail이라고 부른다. Head 노드의 prev와 Tail 노드의 next는 null이다. 파란색 화살표는 서로 연결되어 있다는 것을 나타내기 위해 그렸다. 양방향으로 연결되어 있기 때문에 양방향 연결 리스트 또는 이중 연결 리스트라고 부른다.
LinkedList는 메모리 상에서 불연속적으로 존재하기 때문에 인덱싱이 빠르게 이루어지지 않는다. LinkedList에서 get과 set을 할 때 내부적으로 호출하는 node(int index) 메서드를 살펴보자.
Node<E> node(int index) {
// assert isElementIndex(index);
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}size >> 1는 LinkedList의 size에서 우측 쉬프트 연산을 한 것인데 예를 LinkedList의 size가 10이라면 size >> 1은 5가 된다. 사실상 size를 2로 나눈 것으로 생각해도 된다. 만약 get 혹은 set하려는 index가 size/2 보다 작으면 앞에서부터 반복문을 통해서 찾고, 그렇지 않으면 뒤에서부터 반복문을 통해서 찾는다.
Array와 ArrayList는 메모리 상에서 연속적으로 존재하기 때문에 무작위 접근(random access)이 가능하다. 그러나 LinkedList는 메모리 상에서 불연속적으로 존재하기 때문에 연결된 노드에 의존할 수밖에 없다.
그래서 순차접근(sequential access)만 가능하기 때문에 반복문을 통해 앞에서부터 혹은 뒤에서부터 차례대로 찾는 것이다. 그래서 LinkedList는 Array 및 ArrayList보다 읽기(get)/쓰기(set) 작업이 비효율적으로 이루어진다.
하지만 LinkedList는 리스트 중간에 요소를 삽입/삭제할 때 빛을 발한다. 먼저 중간에 요소를 삽입할 때를 살펴보자. 중간에 요소를 삽입하고 싶으면 linkedList.add(2, 4) 이런 식으로 작성하면 된다.
public void add(int index, E element) {
checkPositionIndex(index);
if (index == size)
linkLast(element);
else
linkBefore(element, node(index));
}index가 size와 같으면 맨 마지막에 노드를 추가하겠다는 의미이므로 linkLast(element)가 호출된다. 위 메서드가 아닌 element만을 파라미터로 가지는 public boolean add(E e) 메서드를 호출해도 내부적으로 linkLast(element)가 호출된다.
여기서는 중간에 요소를 삽입할 때를 살펴볼 것이므로 linkBefore() 메서드만 살펴보겠다. 먼저 아까 봤던 node() 메서드가 사용되어 해당 index의 기존 노드를 인자로 전달한다.
void linkBefore(E e, Node<E> succ) {
// assert succ != null;
final Node<E> pred = succ.prev;
final Node<E> newNode = new Node<>(pred, e, succ);
succ.prev = newNode;
if (pred == null)
first = newNode;
else
pred.next = newNode;
size++;
modCount++;
}사실 코드를 설명하려고 했는데 말로 설명하기는 너무 어렵다. 이 부분은 글의 초반 부분의 이미지를 참고하여 직접 그려보면서 이해해보기를 바란다. 나도 직접 그려보니 이해가 잘 되었다. 간략하게 설명하자면, 해당 인덱스에 존재하던 기존 노드(succ)의 prev에 새로 생성한 노드를 할당하고, succ 이전 노드의 next에 새로 생성한 노드를 할당함으로써 두 개의 노드 사이에 새로운 노드를 링크하여 끼워넣는 것이다.
LinkedList에서 요소를 삭제할 때는 여러 메서드가 있지만 중간에 있는 요소를 삭제할 때는 내부적으로 unlink() 메서드를 호출한다.
E unlink(Node<E> x) {
// assert x != null;
final E element = x.item;
final Node<E> next = x.next;
final Node<E> prev = x.prev;
if (prev == null) {
first = next;
} else {
prev.next = next;
x.prev = null;
}
if (next == null) {
last = prev;
} else {
next.prev = prev;
x.next = null;
}
x.item = null;
size--;
modCount++;
return element;
}사실 이것도 코드로 설명하려니 좀 어려워서, 그림으로 그려서 이해해보기를 바란다. 하지만 요소를 삽입할 때와 원리는 비슷하다. 여기서는 중간에 삭제하려는 노드 x를 기준으로, x 이전 노드의 next와 x 다음 노드의 prev를 다시 설정하면서... 동시에 삭제하려는 노드 x의 prev, item, next를 모두 null로 만든다.
정리하자면,
1. 읽기/쓰기 작업은 순차접근하기 때무에 무작위 접근하는 Array, ArrayList보다 비효율적이다.
2. 하지만 중간에 요소를 삽입/삭제하는 작업은 단순히 포인터를 변경하여 link, unlink하는 방식이기 때문에, 배열 일부분을 복사하여 앞뒤로 이동시키는 ArrayList보다 효율적이다.
3. 그래서 읽기(get)/쓰기(set) 작업이 빈번하게 일어나는 작업보다는 삽입(add)/삭제(remove)가 빈번하게 일어나는 작업에 더 적합하다.
4. LinkedList의 또다른 단점은 prev와 next도 저장해야 하기 때문에 데이터 그대로 저장하는 Array와 ArrayList보다 추가적인 메모리가 필요하다는 점이다.
5. 불연속적으로 존재하는 데이터를 연결(link)한 형태로 구성되어 있기 때문에 메모리 공간의 제약이 존재하지 않는다.
추가적으로, 단방향 연결 리스트(singly linked list)는 prev가 존재하지 않고 next만을 가지고 있는 연결 리스트이며 양방향 원형 연결 리스트(doubly circular linked list)는 첫번째 노드와 마지막 노드를 연결하여 원형처럼 연결되어 있다.
다른 연결 리스트에 대해 좀더 자세히 대해서 알아보려면 이 글을 참고하자. 지금까지 내가 작성한 내용을 이해했다면 이해하기 어렵지 않을 것이다.
참고자료
