Focal Loss에 대해 Class Imbalance 문제에 적용하기 좋은 Loss 함수라는 느낌만 갖고 있었다. 어떻게 Loss를 계산하는지는 잘 몰랐기에 처음 Focal loss 함수를 소개했던 논문을 참고해 정리해 보려고 한다.
논문: Focal Loss for Dense Object Detection
1. Introduction
기존의 Object dectector들은 proposal-driven mechanism 으로, two-stage에 기반을 두고 있었다. 첫 번째 stage에서는 sparse한 object location의 후보군을 만들어 내고, 두 번째 stage에서는 배경인지 물체인지 classification을 수행한다. 이러한 방법은 기존 object detection 문제에서 좋은 성능을 보였지만 이 문제를 한개의 stage으로는 비슷한 성능을 보이지 못할까? 라는 의문이 생겼고 그 결과 YOLO, SSD 와 같은 one-stage detector들이 나왔다.
이 논문에서는 one-stage detector들이 학습중에 직면하는 Class imbalance 문제를 해결하고자 새로운 함수를 제안한다.
왜 class imbalance 문제가 생길까? 뒤에서 설명!
two-stage model의 경우 물체의 물체의 후보군수를 줄임으로서 대부분의 배경 sample을 줄이고 두 번째 stage 단계에서 heuristics한 sampling을 통해 foreground-to-background의 비율을 1:3로 만든다.
그러나 one-stage model의 경우 물체의 후보군(candidate object locations)을 많이 처리하게 된다. heuristic한 sampling을 적용해도 background sample에 쉽게 dominant되어 효율적이지 못하다. 이를 bootstrappin or hard example mining을 적용하여 문제를 해결해 왔다.
이 논문에서는 이러한 class imbalance 문제를 해결하기 위해 Cross-Entropy에 동적으로 scaling되는 loss 함수를 제안한다. 여기서 scaling factor는 올바른 class에 confidence가 증가할 수록 0으로 감소한다.이는 학습에서 쉽게 판별할 수 있는 예시 들의 기여를 줄이고 판별이 어려운 예시들에 좀더 집중하는 효과를 불러온다.
기존의 robust한 Loss함수를 만들기 위해 큰 loss를 갖는 sample을 down-weighting 하여 outlier의 기여를 줄였다면 Focal loss는 쉬운 sample을 down-weighting 하여 어려운 sample에 집중하는 것이다.
Focal Loss
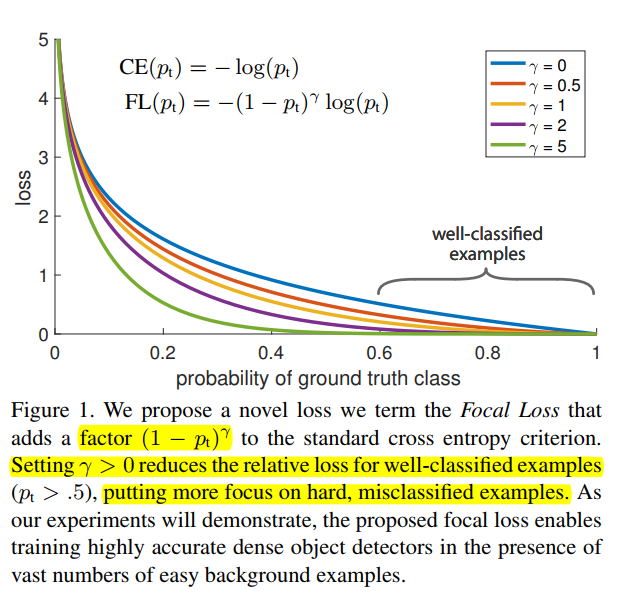
기존의 Cross Entropy를 편의를 위해 CE(p_t)라 정의하면 Focal Loss는 다음과 같이 정의된다.
class imbalance를 해결하고자 제안된 balanced Cross Entropy, 의 경우 positive/negative의 importance를 균형을 잡아줄 수 있으나 easy/hard example를 구분하지는 앟는다. 하지만 Focal Loss의 경우 modulating factor인 를 이용하여 easy example을 down scaling 하고 hard한 example에 집중한다.
예시로 만약 한 example이 잘못 분류되어 가 작다면 modulating gactor가 1에 근사하여 loss는 영향받지 않을것이다. 하지만 가 1에 가까울수록 factor는 0에 가까워지고 잘 분류되는 example들은 down-weighted 될 것이다. focusing parameter인 는 easy example들이 down-weighted 되는 비율을 조정한다.
- 논문에서는 a-balanced된 focal loss를 이용했을때 기본 focal loss 대비 성능이 좀 더 향상됬다고 했다.
- 그리고 최종적으로 Loss layer를 sigmoid와 결합했을때 계산의 안정성이 더 높다고 헀다고 한다.
- Model을 초기화할때 binary classification 기준 0.5,0.5로 예측하도록 했다면 rare한 class 를 0.01, 많은 class를 0.99로 초기화하면 heavy한 class 불균형에 대해 문제를 잘 해결
- alpha - balanced를 통해 sampling의 효과를 기대
구현 코드 출처: https://github.com/clcarwin/focal_loss_pytorch/blob/master/focalloss.py
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.autograd import Variable
class FocalLoss(nn.Module):
def __init__(self, gamma=0, alpha=None, size_average=True):
super(FocalLoss, self).__init__()
self.gamma = gamma
self.alpha = alpha
if isinstance(alpha,(float,int,long)): self.alpha = torch.Tensor([alpha,1-alpha])
if isinstance(alpha,list): self.alpha = torch.Tensor(alpha)
self.size_average = size_average
def forward(self, input, target):
if input.dim()>2:
input = input.view(input.size(0),input.size(1),-1) # N,C,H,W => N,C,H*W
input = input.transpose(1,2) # N,C,H*W => N,H*W,C
input = input.contiguous().view(-1,input.size(2)) # N,H*W,C => N*H*W,C
target = target.view(-1,1)
logpt = F.log_softmax(input)
logpt = logpt.gather(1,target)
logpt = logpt.view(-1)
pt = Variable(logpt.data.exp())
if self.alpha is not None:
if self.alpha.type()!=input.data.type():
self.alpha = self.alpha.type_as(input.data)
at = self.alpha.gather(0,target.data.view(-1))
logpt = logpt * Variable(at)
loss = -1 * (1-pt)**self.gamma * logpt
if self.size_average: return loss.mean()
else: return loss.sum()