[논문 리뷰]Are Large Language Models Capable of Generating Human-Level Narratives?

2024 EMNLP Main
서론
선행 연구
- 최근 HCI 연구들에서 LLM이 생성하는 스토리텔링의 능력을 지적하고 있다. GPT-4나 Claude와 같은 LLM은 유창해보이는 narrative를 생성할 수 있다. 하지만, 플롯의 허점이 있거나 주제가 반복적으로 생성되는 경향이 있다는 것이 밝혀졌다. 또한, LLM이 생성하는 narrative는 인간이 생성하는 narrative보다 감정적으로 흥미롭지 않다는 문제점이 밝혀졌다.
- narrative를 정량적으로 평가하기 위한 프레임워크가 확립되지 않았다.
선행 연구의 한계 해결 방법
- 해당 연구는 계산적인 프레임워크를 확립하고자 하는 첫 번째 시도다.
- story arc(이야기 구조): 거시적인 수준에서 narrative가 어떻게 진행되는지 평가한다.- turning point: story arc보다 작은 수준에서의 흐름 변화를 평가한다.
- affective dimension: 미시적인 수준에서 감정의 역동성을 평가한다.
제안한 방법
LLM의 narrative 생성 능력을 영화 데이터를 통해서 정량적으로 분석하고자 한다.
실험 과정
- 데이터 준비
- wikipedia에서 최근 영어권 영화의 줄거리를 수집하여 데이터셋을 구축한다.- 유명한 영화는 제외하기 위하여 wikipedia 페이지 길이를 기준으로 필터링하여 819개 영화의 줄거리를 선정하였다.
- GPT-4를 이용하여 제목과 주요 설정을 변경한 819개의 narrative를 추가 생성하였다.
- 분석 접근 방식
- 인간이 작성한 줄거리(wikipedia)를 분석하여 연구자가 수동으로 story arc와 tuning point를 주석 달았다. -> 16명의 문학 및 스토리 분석 경험이 있는 전문가가 참여하였다.- spearman 상관계수, cohen kappa를 이용하여 신뢰도를 평가하였다.
- affective dimension을 평가하기 위해서 arousal, valence 지표를 만들고 측정하였다.
- GPT-4를 이용해서 주요 캐릭터의 감정을 나타내는 형용사 3개를 추출하고 NRCVAD 감정 사전을 사용하여 감정 점수를 할당하였다. 스토리의 각 문장별 감정 변화를 시각화하여 인간과 LLM의 narrative를 비교하였다.
선행 연구의 한계가 해결 되었는가?
- LLM의 narrative 생성을 객관적으로 평가하는 방법이 존재하지 않았기 때문에 밴치마크를 제안한다. -> 선행 연구의 한계가 해결될 수 있다고 생각한다.
- 인간 자원이 많이 드는 실험 방법이기 때문에 후에 새로 나오는 모델들을 평가하기에는 쉽지 않을 것 같다.
실험
-
대조군: 인간이 생성한 narrative
-
실험군: LLM이 생성한 narrative, LLM 모델들끼리도 비교하였다.
-
LLM은 Gemini Pro, Claude 3 Opus, Llama3, GPT-3.5, GPT-4를 평가하였다.
대조군과 실험군의 결과 차이
- LLM이 생성한 이야기는 전개 속도가 인간에 비하여 부자연스러웠다. 아래의 이미지에 나와 있는 것처럼, TP1에서 TP3까지는 인간과 LLM이 유사하지만, TP4와 TP5는 LLM에서 더 빠르게 등장한다.
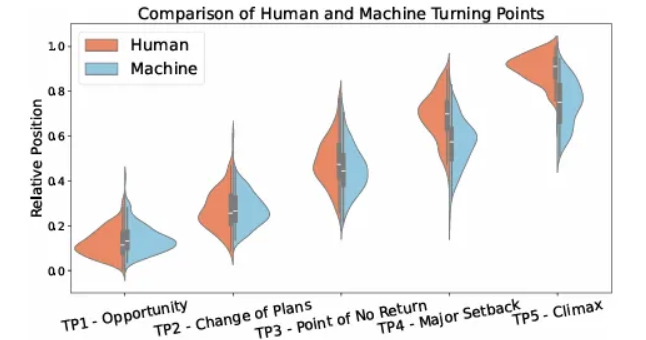
- 논문의 저자는 위와 같은 이유 떄문에 이야기의 흐름이 평탄해지고, 긴장감을 낮춘다고 주장하였다.
- 인간이 생성한 이야기를 읽을 때와 LLM이 생성한 이야기를 읽을 때의 흥분 곡선으로 근거를 제시하였다. (아래 이미지)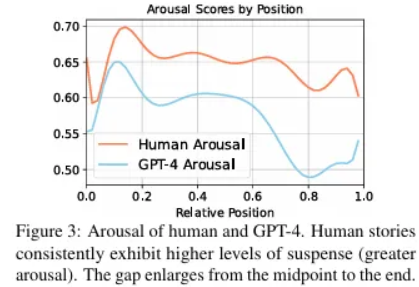
평가 방법이 적절한가?
- 인간과 유사한 narrative를 생성하게 하는 것이 목표이기 떄문에 인간이 생성한 narrative와 LLM이 생성한 narrative의 유사한 정도를 평가하는 것은 적절하다고 생각한다.
결과
-
논문에서는 모델이 개요를 생성할 때 TP3, TP4, TP5를 명시적으로 포함하게 하고, 이 개요를 기반으로 전체 이야기를 생성하게 하면 인간과 비슷한 narrative를 생성하는 것에 도움이 될 것이라고 하였다.
-
또한, 이야기의 상승과 하락 횟수를 명시적으로 지정하게 하면 좋다고 주장하였다.
-
인간과 LLM의 비교를 수행한 결과들 중, 절반 정도는 GPT-4의 결과만 이용되었는데, 평가에 사용되는 모든 주석은 GPT-4를 이용해서 달기 떄문에 GPT-4의 성능이 대체로 좋게 측정되었을 수도 있다는 생각이 들었다.
-
짧은 줄거리를 기준으로 실험이 수행되었기 때문에 긴 이야기에서는 적용하기 어려운 방법일 수도 있다는 생각이 들었다.

AI 전공. Story Generation, Agent 분야 논문을 주로 리뷰합니다. RAG도 조금 합니다.