조원들과 자주 이용하던 바나프레소를 벤치마킹하여 카페 주문 시스템을 개발했다.
이번 글에서는 카페 주문 시스템을 개발하며 경험한 동시성 이슈 중 하나인 즐겨찾기 동시성 문제에 대한 원인과 해결 과정을 정리해보고자 한다.
1. 문제 발견
 프로젝트에서 즐겨찾기 기능을 구현하고 로컬에서 테스트할 때는 문제가 없었다.
프로젝트에서 즐겨찾기 기능을 구현하고 로컬에서 테스트할 때는 문제가 없었다.
클릭하면 즐겨찾기가 잘 추가되고, 카운트도 정상적으로 올라는데
하지만 출근 시간대에 많은 사람들이 카페를 정말 많이 이용하는데
"실제로 피크타임에 여러 사용자가 하나의 상품에 대해서 동시에 즐겨찾기를 하면 어떻게 될까?"라는 의문이 들었다.
실제 서비스 환경에서는 다수의 사용자가 동시에 같은 기능을 사용할 수 있다.
특히 프로모션이나 인기 상품의 경우, 순간적으로 집중된 트래픽이 발생할 수 있다고 생각한다.
이런 상황을 시뮬레이션하기 위해
1000명의 동시 요청을 테스트 시나리오로 설정했다.
(실제로는 100명만 동시 접속해도 충분히 문제가 발생할 수 있지만, 여유를 두고 더 극단적인 상황을 가정했다.)
2. 원인 분석
Race Condition이란?
여러 사용자가 동시에 같은 데이터를 읽고 쓸 때, 실행 순서에 따라 결과가 달라지는 상황을 말한다.
즐겨찾기 카운트를 증가시키는 것을 아래 3단계로 나뉜다.
1. 현재 값 읽기 (Read)
2. 1 증가시키기 (Modify)
3. 증가한 값 저장하기 (Write)문제는 여러 사용자가 동시에 이 과정을 실행할 때 발생한다.
사용자 A : count = 5 읽기 → 6으로 변경 → 저장
사용자 B : count = 5 읽기 → 6으로 변경 → 저장
↑ 둘 다 5 를 읽어버린다 !두 사용자가 모두 "5"를 읽고 "6"으로 저장하면서,
실제로는 2번 증가해야 하는데 1번만 증가하게 된다.
이것을 바로 Race Condition(경쟁 상태)라고 말한다.
Race Condition의 발생 조건은 아래와 같다.
1. 공유 자원 (Shared Resource)
여러 스레드가 접근하는 데이터 (예: DB의 count)
2. 동시 접근 (Concurrent Access)
여러 스레드가 동시에 접근
3. 최소 하나의 쓰기 (At Least One Write)
읽기만 하면 문제 없음, 쓰기가 있어야 문제 발생이를 해결하기 위해
낙관적 락 / 비관적 락 / 원자적 UPDATE 방식을 비교하여
최선의 해결 방안을 찾아보려고 한다.
3. 테스트 환경
개발 환경
- Java: 21 (LTS)
- Spring Boot: 3.2.x
- ORM: Spring Data JPA (Hibernate 6.x)
- Database: MySQL 8.0 (로컬 환경)
테스트 구성
- 테스트 프레임워크 : JUnit 5
- 동시성 제어 :
CountDownLatch+ExecutorService - 시나리오 : 1000명이 동시에 아이스 아메리카노 즐겨찾기 추가
- Thread Pool 크기 : 100개 스레드
- 반복 횟수 : 각 테스트 1회 실행
테스트 코드 전체적인 공통 틀
private static final int THREAD_COUNT = 1000;
private static final int POOL_SIZE = 1000;
@Test
void 낙관적_락_동시성_테스트() {
ExecutorService executorService = Executors.newFixedThreadPool(POOL_SIZE);
CountDownLatch latch = new CountDownLatch(THREAD_COUNT);
long productId = 1; // 아이스아메리카노에 대한 product id
for (int i = 0; i < THREAD_COUNT; i++) {
final long memberId = i + 1L; // 1 ~ 1000번 memberId를 사용자
executorService.execute(() -> {
try {
favoriteService.addFavorite(1L);
} catch (Exception e) {
} finally {
latch.countDown();
}
});
}
latch.await();
}즐겨찾기 count를 해야하는 product 엔티티
public class Product {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "product_id")
private Long id;
@Column(name = "product_name")
private String productName;
@Column(name = "product_content")
private String productContent;
@Column(name = "product_photo")
private String productPhoto;
private Integer price;
@Column(name = "favorite_count", nullable = false, columnDefinition = "bigint default 0")
@Builder.Default
private Long favoriteCount = 0L;
@Column(name = "version", columnDefinition = "bigint default 0")
private Long version = 0L;
// 1:N
@OneToMany(mappedBy = "product", cascade = CascadeType.ALL, orphanRemoval = true)
private List<ProductOption> options = new ArrayList<>();
// 1:1
@OneToOne(mappedBy = "product", cascade = CascadeType.ALL, orphanRemoval = true)
private NutritionInfo nutritionInfo;
// 1:N
@OneToMany(mappedBy = "product", cascade = CascadeType.ALL, orphanRemoval = true)
private Set<Allergen> allergens = new HashSet<>();
// 1:N - Category
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "category_id", nullable = false)
private Category category;
// 1:N 관계 매핑 (즐겨찾기만)
@OneToMany(mappedBy = "product", cascade = CascadeType.ALL, fetch = FetchType.LAZY)
private List<Favorite> favorites = new ArrayList<>();
// 1:N - Hashtag
@OneToMany(mappedBy = "product", cascade = CascadeType.ALL, orphanRemoval = true)
private Set<Hashtag> hashtags = new HashSet<>();
public void increaseFavoriteCount() {
if(this.favoriteCount == null) {
this.favoriteCount = 1L;
} else {
this.favoriteCount++;
}
}
public void decreaseFavoriteCount() {
if(favoriteCount > 0) {
this.favoriteCount--;
}
}
}4. 해결 방법 탐색
위에서 말했던 세 가지 방안을 테스트하기 앞서
우선 락 없이 1000명이 동시에 즐겨찾기 하는 상황을 테스트해보았다.
4.1 락 없음 (문제 상황)
Respository
 Service
Service
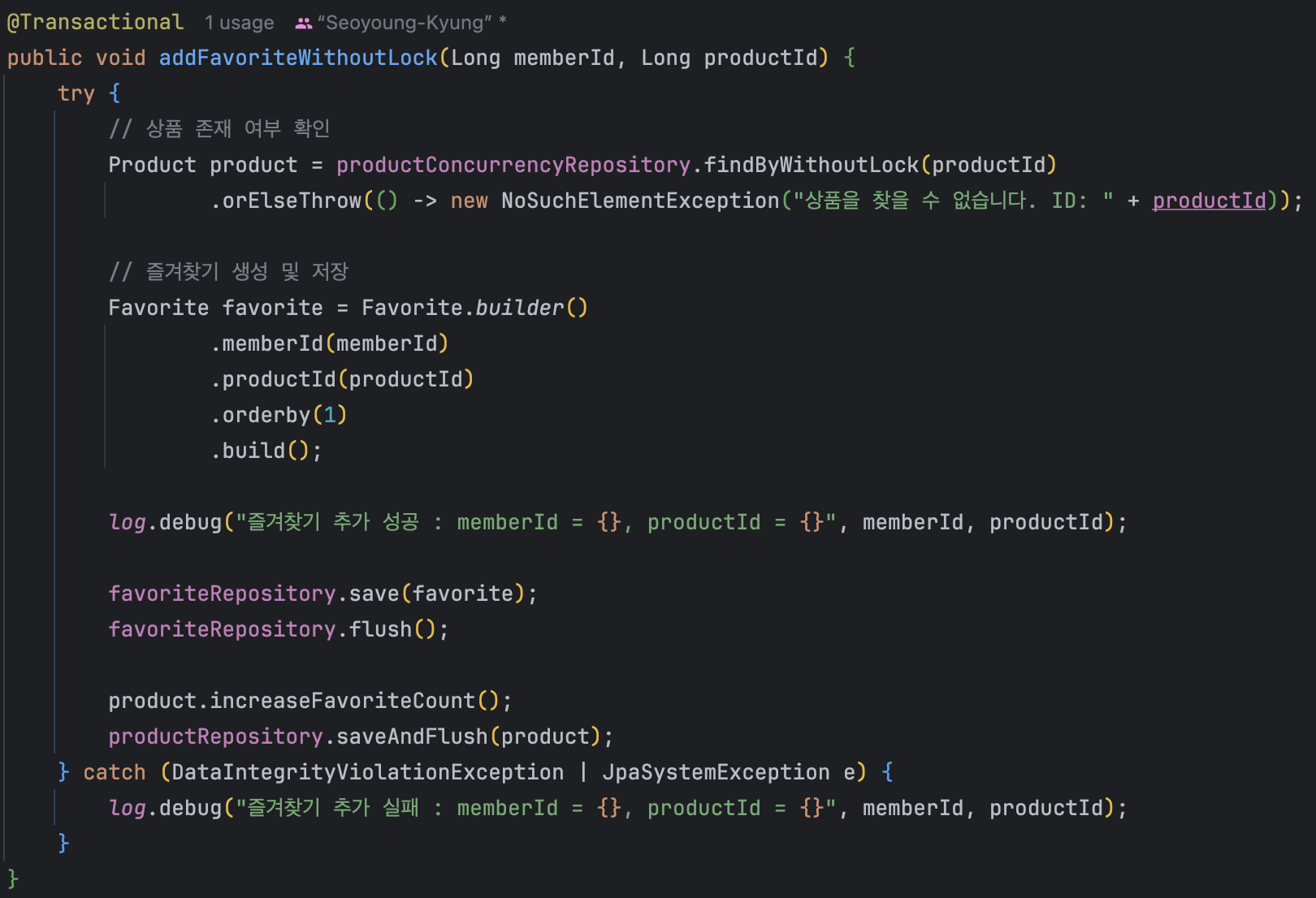
이 코드는 3단계로 동작한다 :
1. Product 조회 (favoriteCount 읽기)
2. Favorite 생성 및 저장
3. Product의 favoriteCount 증가 및 저장Race Condition 발생 시나리오 :
초기 상태 : Product의 favoriteCount = 100
[Thread A] [Thread B]
1. count = 100 읽기
1. count = 100 읽기 ← 동시에 같은 값!
2. Favorite 저장
2. Favorite 저장
3. count = 101로 증가
3. count = 101로 증가 ← 둘 다 101!
4. count = 101 저장
4. count = 101 저장 ← 덮어씀!
결과 : favoriteCount = 101 (기대값: 102)두 사용자가 모두 즐겨찾기를 추가했지만,
카운트는 "1"만 증가한다 !
 실제로 1~1000번의 memberId를 돌았는데도 불구하고 처참한 테스트 결과가 나왔다.
실제로 1~1000번의 memberId를 돌았는데도 불구하고 처참한 테스트 결과가 나왔다.
테스트 결과 : 1540ms, 실패율 5.7%
1000개의 요청 모두 성공적으로 요청되었지만 실제로 DB에 반영된 즐겨찾기는 265개 밖에 되지 않았다.
1000명이 즐겨찾기를 시도했을 때 265명을 제외한 나머지 사람들은 즐겨찾기에 실패했다는 것이다.
실제 서비스에서는 절대 이런 일이 일어나선 안된다는 것을 체감했다.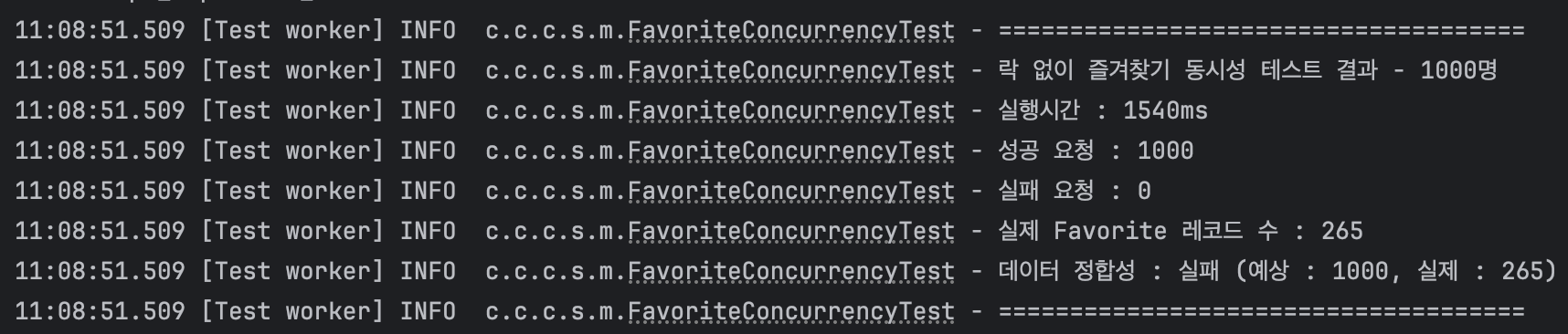
4.2 낙관적 락 (@Version)
데이터 충돌이 자주 발생하지 않을 것이라 낙관적으로 가정하고, 충돌이 발생하면 그때 충돌을 처리하는 방식을 말한다.
장점
- 동시에 여러 트랜잭션이 데이터에 접근하고 변경할 수 있기 때문에 동시성이 높아지고, 시스템의 처리량이 향상된다. (반드시 되는 건 아님)
- 락을 사용하지 않기 때문에 다른 트랜잭션에서 데이터를 읽을 수 있다.
- 충돌이 발생했을 때 롤백을 피하고 충돌을 해결할 수 있는 기회를 제공한다.
단점
- 충돌이 발생할 경우 롤백이 발생할 수 있다. 다른 트랜잭션에서 변경한 데이터와 충돌이 발생하면 예외가 발생하고 롤백 발생
Entity
낙관적 락을 수행하기 위해 JPA에서 제공하는 @Version 애너테이션을 사용한 Version 컬럼을 추가해주었다.

Respository
product 엔티티를 조회하는 쿼리에는 @Lock 애너테이션을 이용하여 Entity 수정시에만 발생하는 낙관적 잠금이 읽기 시에도 발생하도록 설정하였다.
이는 읽기시에도 버전을 체크하고 트랜잭션이 종료될 때까지 다른 트랜잭션에서 변경하지 않음을 보장한다.
 Service
Service
낙관적 락은 비관적 락과 달리 충돌에 낙관적이기 때문에 충돌 했을 때 재시도할 수 있도록 재시도 로직을 구현하였다.
초반엔 최대 재시도 횟수를 작성하지 않았었는데
제한을 두지 않으면 테스트가 무한 루프에 빠져 종료되지 않는 문제가 발생했다.
그래서 제한 횟수를 정하기로 하였고, 약간 여유를 두고 10번으로 지정하였다.
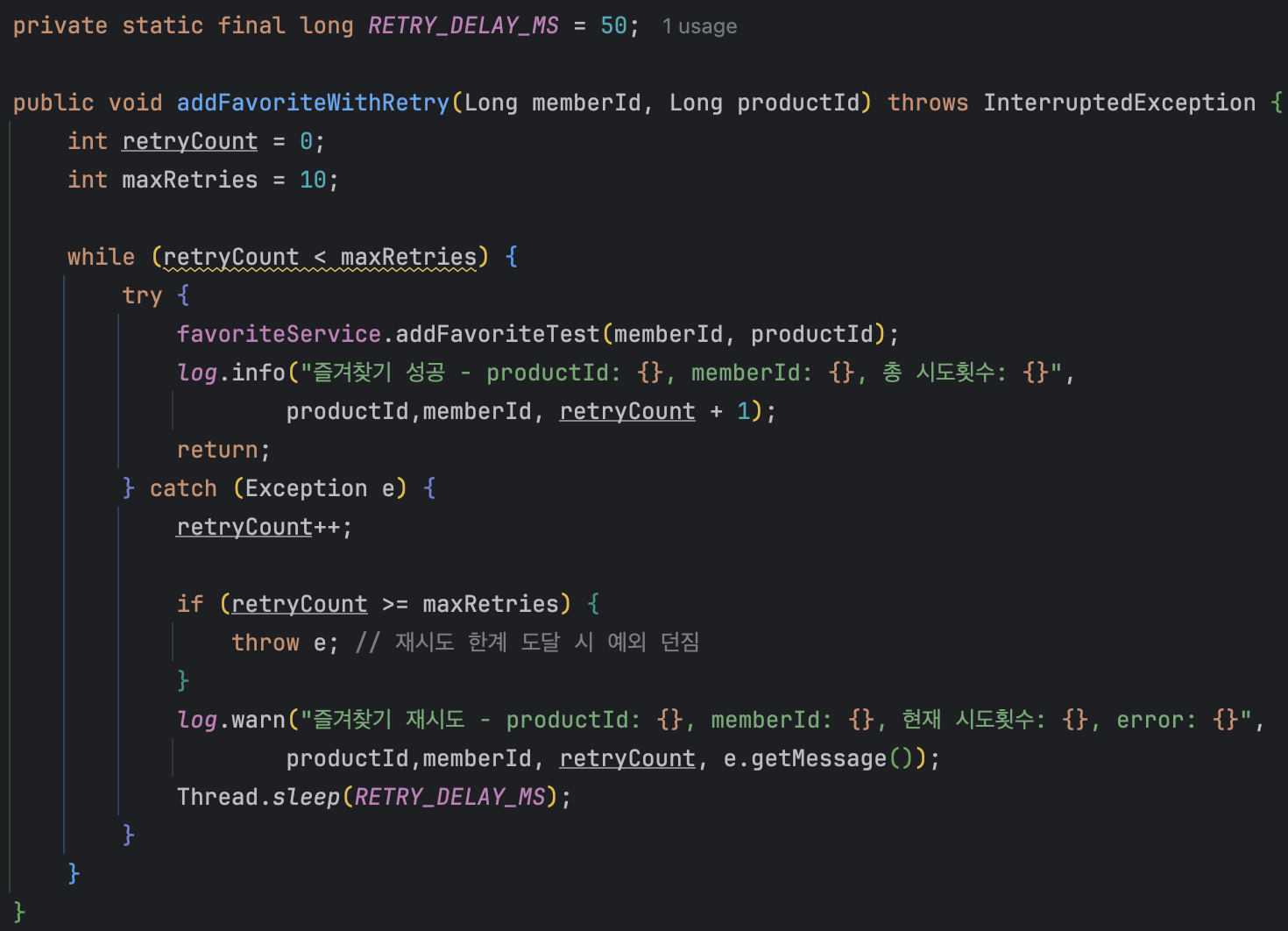

10번을 재시도했는데도 불구하고 최대 재시도 횟수를 초과하여 실패하는 경우가 발생했다.
테스트 결과: 3781ms
낙관적 락 적용 시, 비동기 환경에서도 충돌 빈도가 감소하며 전반적인 성공률이 향상되었다. 다만 일부 요청에서는 여전히 버전 충돌이 발생했으며, 재시도 횟수를 늘릴 경우 100% 성공을 달성할 수 있었지만, 운영 환경에서의 성능 부담을 고려해 최대 재시도 횟수는 10회로 제한하였다. 10번의 재시도에도 실패하는 테스트 결과를 보니 충돌이 너무 심한 상황에서는 낙관적 락의 한계를 보였다.

4.3 비관적 락 (PESSIMISTIC_WRITE)
동시에 누가 수정할 것이라 비관적으로 가정하고, 데이터를 읽는 시점 부터 다른 트랜잭션이 건들지 못하도록 잠그는 방식이다.
이로 인해 데이터를 수정할 땐 다른 트랜잭션이 접근하여 읽거나 수정할 수 없다.
장점
- 데이터를 접근하는 동안 다른 트랜잭션이 접근하지 못하도록 제어할 수 있다. 데이터의 일관성과 동시성을 보장할 수 있다.
- 데이터에 대한 잠금을 설정하여 다른 트랜잭션의 변경을 차단함으로써 충돌을 방지할 수 있다.
단점
- 동시성이 낮아진다. 데이터를 잠그기 때문에 다른 트랜잭션에서 해당 데이터에 접근하거나 변경하는 것이 제한된다.
- 락을 사용하므로 다른 트랜잭션이 해당 데이터를 읽을 수 없다.
- 잠금을 설정한 상태에서 해당 트랜잭션의 작업이 오래 걸리면 다른 트랜잭션들이 대기하게 되어 시스템 성능이 저하될 수 있다.
Repository
비관적 락의 LockModeType은 다른 트랜잭션이 읽고 쓰는 동안 읽는 걸 막기 위해 PESSIMISTIC_WRITE로 걸었다.
 Service
Service
서비스 코드는 락 없이 테스트 했을 때와 동일하게 작성하였다.
테스트 결과: 2274ms, 성공률 100%
성공률 100%를 확인했고 낙관적 락에 비해 실행시간이 적게 걸렸지만 여전히 느린 속도였다.

4.4 원자적 UPDATE
여러 스레드나 트랜잭션이 동시에 같은 데이터를 수정하더라도 데이터가 꼬이지 않도록 보장하는 갱신 방식이다.
읽기-수정-쓰기를 데이터베이스 레벨에서 한 번에 처리하여
중간에 다른 작업이 끼어들 수 없다.
Respository
JPA에서는 @Modifying과 JPQL UPDATE를 사용해 한 번의 SQL로 수정 연산을 처리할 수 있다.
이 방식으로 원자적 UPDATE 방식을 수행했다.

테스트 결과: 954ms, 성공률 100%
테스트 결과 모든 테스트 케이스 중에서 가장 짧은 실행시간을 보였고 100% 성공률을 확인했다.
5. 성능 비교
| 방식 | 실행시간 | 성공률 | 특징 |
|---|---|---|---|
| 락 없음 | 1540ms | 26.5% | 빠르지만 데이터 손실 |
| 낙관적 락 | 3781ms | 89.6% | 안전하지만 느림 |
| 비관적 락 | 2274ms | 100% | 안전하지만 느림 |
| 원자적 UPDATE | 954ms | 100% | 빠르고 안전 |
6. 최종 선택과 이유
세 가지 동시성 제어 방식을 비교 분석한 결과, 최종적으로 원자적 UPDATE 방식을 선택했다.
선택 근거
-
단순성과 효율성의 균형
- 별도의 버전 관리 필드나 락 획득 로직이 필요 없어 코드가 간결하다.
- 데이터베이스 수준에서 원자성이 보장되므로 추가적인 동시성 제어 로직이 불필요하다.
-
성능상의 이점
- 낙관적 락처럼 재시도 로직이 필요 없어 불필요한 오버헤드가 없다.
- 비관적 락보다 락 대기 시간이 짧아 처리량이 높다.
- 단일 쿼리로 조회와 업데이트를 동시에 처리할 수 있다.
-
좋아요 기능의 특성에 적합
- 좋아요 카운트는 단순 증감 연산이므로 복잡한 비즈니스 로직이 필요 없다.
- 높은 동시성 환경에서도 안정적으로 동작한다.
- 일시적인 정확도보다 최종적인 일관성이 더 중요한 요구사항에 부합한다.
7. 배운 점
이번에 다양한 락 전략을 직접 테스트해보면서,
이론으로만 알고 있던 개념들이
실제 환경에서 어떻게 다른 결과를 만드는지 체감할 수 있었다.
특히 세 가지 방식을 동일한 조건에서 비교해보니 생각보다 차이가 분명했다.
락 없이 동작하던 코드는 실제 동시 요청 상황에서 데이터 손실이 발생했고, 테스트에서도 1000명 중 265명만 정상 반영되었다.
이를 통해 동시성 제어가 선택이 아니라 필수라는 점을 다시 느꼈다.
낙관적 락은 충돌이 적을 때는 효율적이지만,
충돌이 많아지면 재시도 비용이 빠르게 증가했다.
재시도 횟수를 늘리면 성공률을 높일 수 있었지만 그만큼 시스템 부하도 커졌다.
반면 비관적 락은 안정적으로 동시성을 제어했지만,
처리량이 줄어 전체 실행 시간이 가장 오래 걸렸다.
흥미로웠던 점은 원자적 UPDATE 방식이 가장 빠르고 안정적인 결과를 보였다는 것이었다.
복잡한 락 없이도 DB의 원자성을 활용하면 애플리케이션 부담을 줄이면서 문제를 해결할 수 있다는 점을 직접 확인할 수 있었다.
이번 테스트를 통해 단순히 기능이 동작하는지를 넘어,
동시 요청과 높은 부하 상황에서 어떤 문제가 발생할 수 있는지까지 고려하는 시각이 중요하다는 것을 배웠다.
