PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation 를 읽고...
Abstract
-
point cloud 같은 3d 데이터를 input으로 해서 딥러닝을 적용하는 것은 challenging
→ point cloud 가 irregular, unordered 한 형태를 가지기 때문에.
→ 그럼 균일한 3d voxel 이나, image collections 으로 바꾸면 되지 않나?
이렇게 하면 지나치게 데이터의 부피가 커짐 -
본 논문에서는 raw point cloud 를 input 으로 취하면서도 딥러닝을 적용해 classification, segmentation 등을 수행할 수 있는 'pointNet' 을 고안
-
이 네트워크의 대표적인 특징, permutation invariance : 포인트가 unordered 하게 들어와도 출력이 유지되는 특성
1. introduction
- 딥러닝에서 typical 한 CNN 구조는 Input으로 ordered 한 데이터를 요구.
→ point cloud 나 mesh 는 unordered 데이터라, 이런 raw 입력에 딥러닝을 취하는 것은 무리가 있음.
기존의 해결 방법
-
모델 학습이전에 irregular form (point cloud, mesh ...) → regular form (3d voxel, 2d image collections ...) 으로 바꾸려는 시도가 있었음
→ 지나치게 이미지의 부피가 커진다는 단점 (학습 시간, 메모리의 문제)
→ 데이터의 quantization 을 도입하려는 시도도 있었으나, 데이터의 natural invariances 를 해칠 수 있음. -
고로 본 논문에서는 raw 한 포인트 클라우드 데이터를 입력으로 취하더라도 강건하게 동작하는 모델을 구축하고자 함.
3d Data vs. 2d data
- 2d 이미지 데이터는 ordered 한 matrix 형태, (w,h) 가 고정되어 있으며 거기에 rgb 정보가 담긴 형태
- 3d 는 unordered 한 벡터 형태. 예를 들어서 2d 는 이미지의 밀도가 균일한 편이지만 3d 는 이미지의 밀도도 불균일 한 것 처럼 (어떤 곳은 포인트가 빽빽한데, 어떤 곳은 듬성듬성...) 고로 균일한 matrix로 나타낼 수 없음
point cloud 가 가져야하는 성질
-
permutaion invariance : point cloud 는 unordered 이므로, 어떤 순서로 들어오더라도 그 특성이 변화해서는 안됨.
예를 들어 어떤 포인트 클라우드 내에 N 개의 점이 있다고 쳤을 때, 입력 순서로 N! 개의 조합이 존재할 수는 있으나, 그게 어떻게 들어오더라도 출력이 변화해서는 안됨 -
rigid motion invariant: 어떤 transformation (회전, 평행이동...) 이 point cloud 내의 모든 점에 취해지더라도, point 간의 거리, 방향은 그대로 유지 되어야 함.
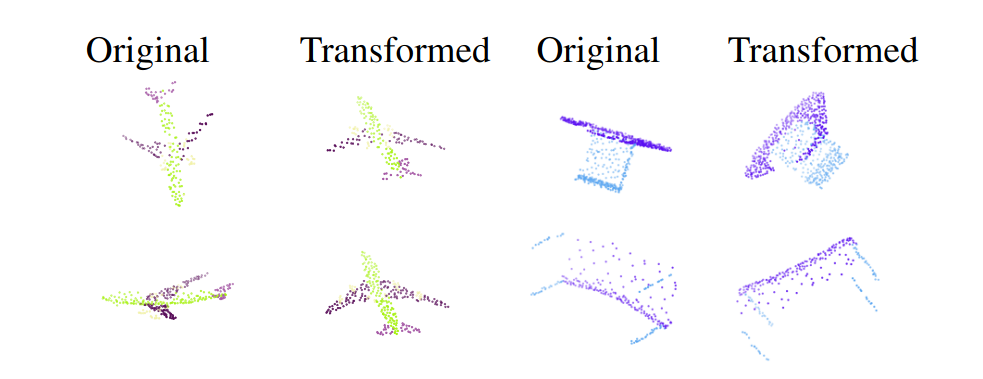
위의 사진은 다른 논문(IT-Net)에서 차용해온거긴 한데, 포인트 클라우드의 transformation 은 이런것을 의미하는 것 인가보다.
pointNet의 구조
-
입력: raw point cloud ( 단지 (x,y,z) + 로 이루어진... )
-
출력: class label (classification) 또는 segmentation 결과 (sementic segmentation)
-
key point: 이처럼, pointNet 은 입력 포인트 클라우드가 국부적인 key points 들의 집합으로 축약되도록 학습 된 모델이라는 것
뒤에서 왜 pointNet 이 outlier 나 missing data 에도 강한지를 보일 것임
2. related works
point cloud features
- unoredered 한 3d data 형태이다
- transformation 에도 invariant 한 특징을 갖고 있도록 되어있다
- local / global feature 로 분류 되어 있다
Deep learning on 3D data
3d 데이터에 딥러닝을 적용시켜보려는 연구 다수 존재
- 3d CNN to voxel data: data sparsity, computaional cost 심각
- 2d data로 바꾸려는 시도: classification엔 괜찮은데, Scene understanding, segmentation 같은데는 약해.
- spectral CNN: mesh 에 대해 CNN 적용. 근데 manifold mesh 에서 성능 약하고 non-isometric shape에 적용하는게 명확치 않음
Feature based DNN: 3D Data 를 벡터로 변환. (쨌든 별로래)
Deep learning on Unordered sets
- point cloud 데이터는 unordered 한 벡터의 집합 형태
- unordered 데이터에 딥러닝을 적용한 연구는 그리 많지 않았다고 함. 자연어 처리에서는 시도가 있었으나 geometry 정보를 포함한 set에 대해서는 많지 않았음
3. problem statement
pointNet 구조
- input: unordered point set (point cloud의), 본래 (x,y,z) + 구조지만 본 논문에서는 (x,y,z) 정보만 사용
- output
object classification: k class 후보에 대한 k score
sementic segmentation: n * m score ( n: points, m: sementic sub-categories)
4. deep learning on among points
4.1 Properties of Point Sets
- 3d point data 의 특성은 크게 세가지
- unordered: 그래서 N개의 포인트를 입력으로 받는 네트워크는 N! 개의 입력 조합에 대해 invariant 한 출력을 내놔야 함
- interaction among points : Neighborhood points 간에 연관성이 있기 때문에, local structure에서 neighbor points 들을 관찰할 필요성이 있음
- invariance under transformation: 어떤 rigid transformation 이 있더라도 ( 회전, 이동...) point set의 특징 (point segmentation, global feature) 이 변화해서는 안됨.
4.2 PointNet Architecture
- network 의 key point layer는 세가지
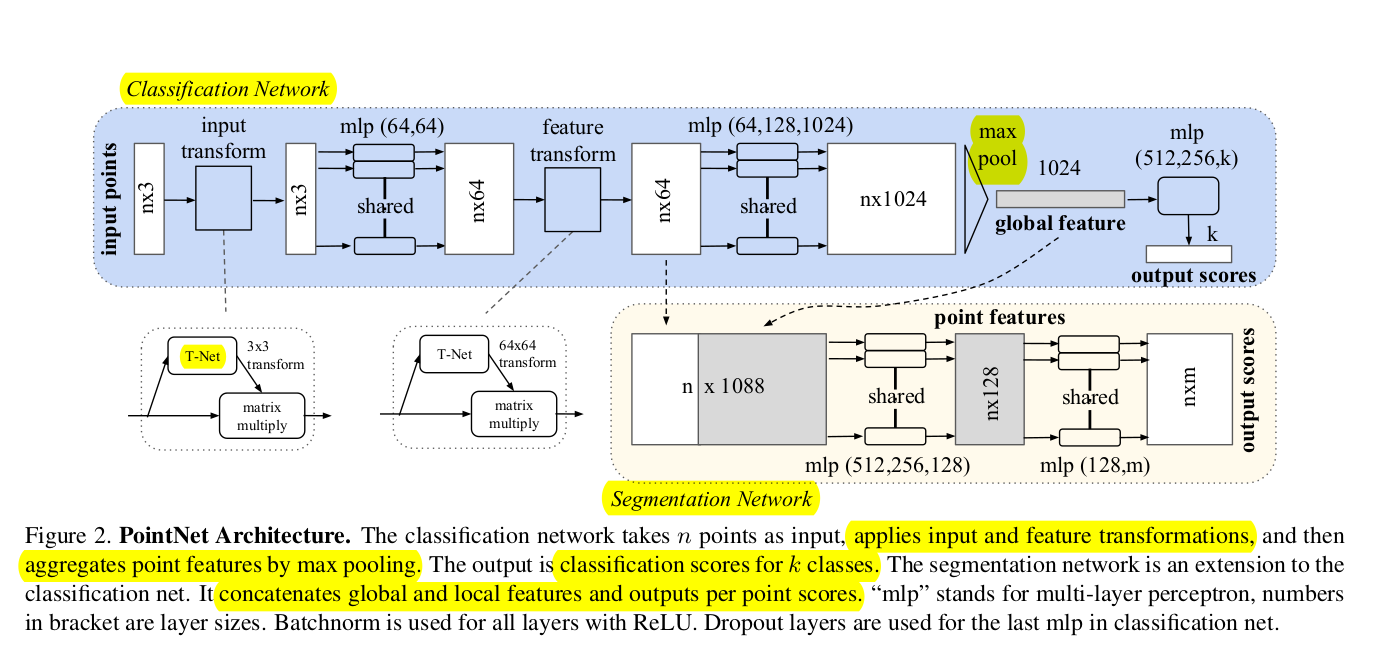
symmetric layer
classification 을 위한 모델과 segmentation을 위한 모델에 동일하게 들어가는 레이어
아까 permutation invariance 가 필요하다고 언급했었고 대표적으로 세가지 방법들이 있음
- input 을 canonial 하게 정렬 함 (성능 좋지 않음)
- RNN을 사용 (성능 bad. small length 데이터엔 용이하지만, point cloud 와 같은 방대한 데이터는... 절레절레)
- 부가적인 레이어 사용 (본 논문 택함)
논문에선 부가적인 maxpooling layer 사용. 원리는 다음과 같음

h: MLP 네트워크
g: max pooling function
포인트 셋의 각기 다른 특성을 찾을 수 있는 f function 을 h, g 로 근사해서 얻을 수 있음
Local and Global information Aggregation
이거는 segmentation 을 위한 부가적인 네트워크
-
위의 과정으로 부터 포인트 셋의 global 한 특징인, 을 출력으로 얻을 수 있음.
-
segmentaion에선 neighborhood point 와의 관계, local feture 도 매우 중요. 이 두개를 합쳐야할 필요가 있음
-
global feature 를 symmetric maxpooling layer 로 부터 구함
-
maxpooling 이전 단계에서 구해진 point feature과 global feature를 concatinate 해서, 새로운 per points feature을 구해냄, 여기엔 local + global feature 가 모두 담긴 형태가 될 것.
Joint alignment Network
- 아까도 말했듯이, 어떤 geometric, rigid transform (회전, 이동 ...) 이 포인트 셋에 있더라도 labeling 결과가 변화해선 안됨.
- 기존에는 feature extract 를 하기 이전에 canonial 하게 정렬하는 방법도 있었지만...
- 본 논문에서는 T-net 구조를 2개 사용하여 affine transform 을 수행 (input transform 에서 한번, feature transform 에서 한번)
- feature에서 transform 하는게 spatial 에서 transform 하는 것보다 high dimension 이라, optimization 이 어렵다는 문제점. 그래서 규제항을 추가함

4.3 Theorical analysis
- 왜 pointNet 이 outlier 나 missing data 에 강한지 수식적으로 접근하는 내용이 나와있어서 일단 pass...
- 핵심적인 건, max pooling layer 를 사용했기 때문에 이상치에 강건하게 반응
근데 후에 point-PWC 논문을 읽어보면 알겠지만 Maxpooling layer는 scene flow 에는 적합하지 않다는 것을 알게될 수 있음. 이건 다음에 point-PWC 리뷰에서!
5. Experiment
- classification 에 대한 결과
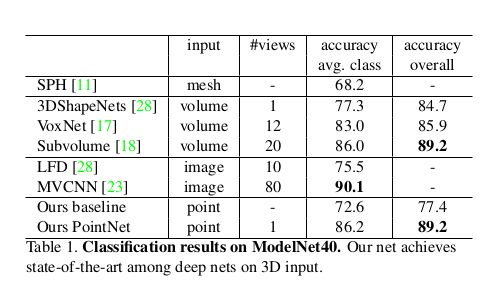 fully connected layer 와 max pooling layer 를 사용해서 연산 속도도 높일 수 있겠구나 ...
fully connected layer 와 max pooling layer 를 사용해서 연산 속도도 높일 수 있겠구나 ...
- 3d object part segmentation 에 대한 결과
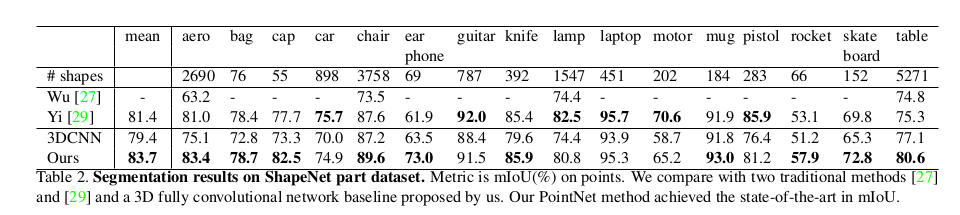
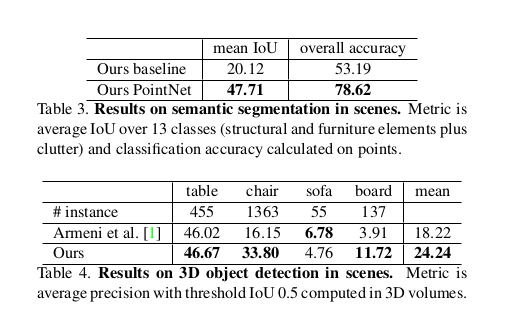
- scene 에서의 segmentation 결과

논문 원본 내용이 너무 어려워서 이해하기 힘들었는데, 깔끔한 리뷰 감사합니다!!