토픽 모델링(Topic Modeling)이란 텍스트 마이닝 기법 중에서 가장 많이 사용되는 방법이라고 할 수 있습니다. 저 역시 토픽 모델링을 활용하여 많은 논문을 게재하였으며, 텍스트 마이닝을 할 때 유용하게 사용하고 있습니다. 토픽 모델링은 주로 대량의 문서를 분석하기 위해 사용되는 방법으로, 분석에 사용되는 데이터가 상당히 중요하다고 할 수 있습니다.
1. LDA(Latent Dirichlet Aollocation)
1.1. 개요
LDA(Latent Dirichlet Aollocation)의 기본적인 가정은 문서에는 그 문서를 구성하는 여러 토픽이 존재하며, 각 토픽은 단어들의 집합으로 구성되었다는 것입니다. Latent(잠재적인)의 의미는 토픽이 글에서 명시적으로 확인되지 않기 때문에 붙여진 이름입니다. 그리고 Dirichlet Aollocation은 문서의 토픽 분포가 디리클레 분포를 따르기 때문인데 디리클레 분포란 연속 확률 분포 중 하나로 모든 값을 더하면 1이 되는 경우에 대해 확률값이 정의되는 분포입니다. 한 문서에 세 토픽의 비중이 있다면 세 토픽의 비중의 합이 1이 된다고 생각하시면 됩니다.
1.2. LDA 모형의 구조
아래의 그림은 LDA 모형의 구조를 표현합니다. 은 문서의 수를 나타내므로 가장 바깥 부분의 사각형은 전체 문서를 표현합니다. 는 문서의 토픽 분포를 말하고 디리클레 분포를 따릅니다. 그 디리클레 분포는 에 의해 결정됩니다. 는 문서에 있는 단어 가 속한 토픽을 나타내며, 문서의 토픽 분포와 각 토픽의 단어 분포가 결합되어 문서의 단어 분포가 결정됩니다. 는 단어 분포를 결정하는 매개변수입니다. 즉, , , 토픽의 개수는 하이퍼 파라미터인데, Perplexity와 Coherence를 통해 결정됩니다.
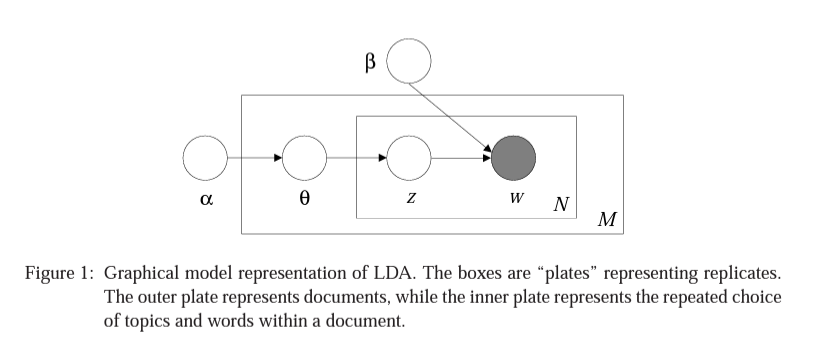
1.3. LDA 평가 및 토픽 개수 결정
LDA 토픽 모델링의 평가와 토픽 개수의 결정은 Perplexity와 Coherence로 결정됩니다. Perplexity는 낮을 수록, Coherence는 높을 수록 좋습니다. 즉 Perplexity(복잡도)는 낮으면서 Coherence(응집도)는 높아야 하는 것입니다. Coherence는 주제의 일관적인 정도라고 생각하시면 되고, Perplexity가 높으면 토픽이 문서를 잘 반영하지 못한다는 것을 의미합니다.
2. BERTopic
2.1. 개요
LDA 토픽 모델링은 공분산의 구조가 서로 다르거나, 정규분포 가정에서 크게 벗어난다면 성능이 낮아집니다. 또한, 리뷰 데이터와 같이 길이가 짧고 조금의 오타가 있는 경우에도 성능이 낮아질 수 있습니다.
2.2. BERTopic 순서
BERTopic은 아래와 같이 크게 세 단계로 구분되어 진행됩니다. 각각 임베딩 모델, 차원 축소 모델, 클러스터링 알고리즘 등 원하는 것을 사용할 수 있다는 것이 큰 장점입니다.
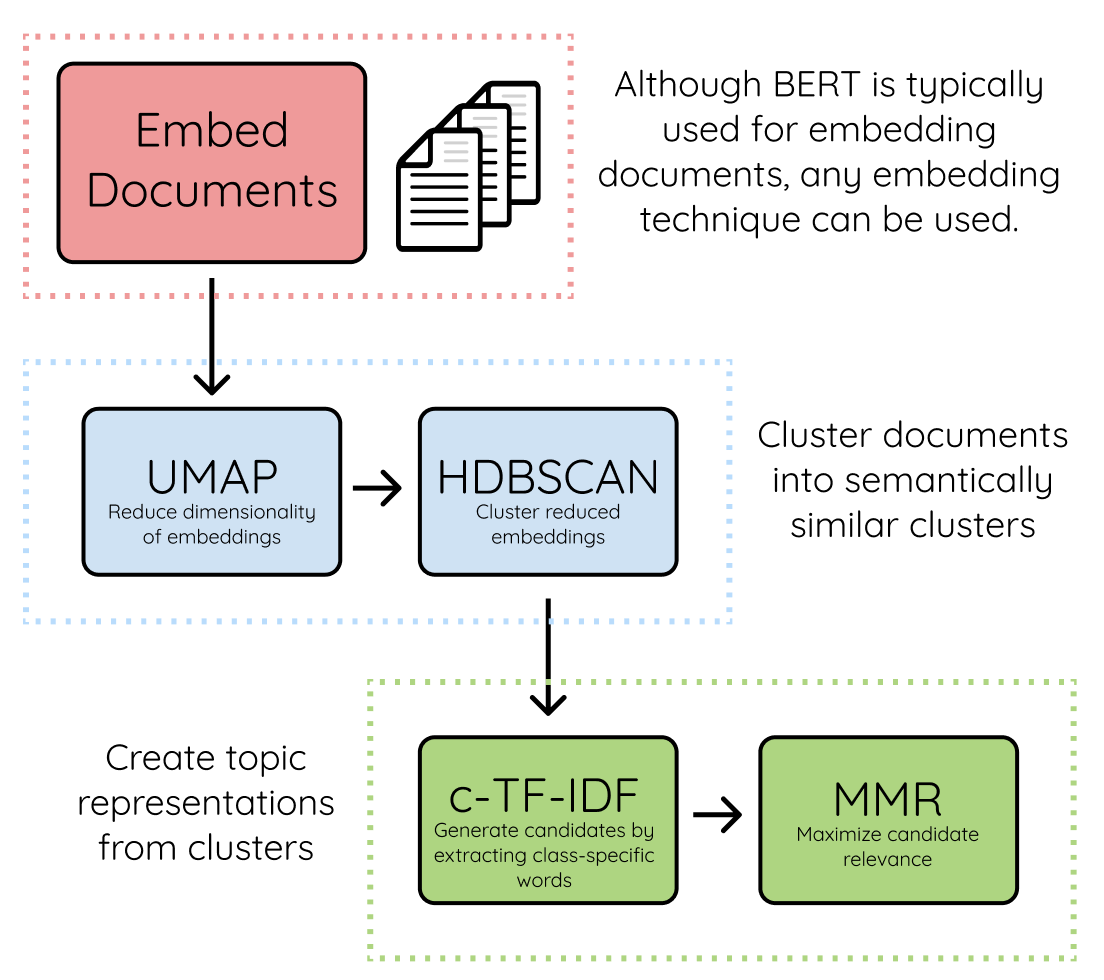
2.2.1 문서 임베딩
먼저 문서 임베딩 입니다. 여기서는 주로 SBERT를 활용하여 임베딩을 하게 됩니다. 그 이유는 유사한 문서끼리 클러스터링을 진행할 때, SBERT를 활용해야 하기 때문입니다.
2.2.2 차원 축소와 클러스터링
이제 차원 축소와 클러스터링을 진행합니다. 유사한 문서끼리 클러스터링을 통해 하나의 주제를 도출하기 위한 과정입니다. 차원 축소에는 보통 UMAP, 클러스터링에는 HDBSCAN이 활용됩니다.
2.2.3 토픽 표현
마지막 토픽의 표현은 C-TF-IDF를 활용합니다. 클러스터링이 된 이후에 클러스터 내에서 이를 대표할 수 있는 단어들을 추출하는 것입니다.
3. Topic Modeling 활용 사례
활용 사례는 제가 작성한 논문에서 가져왔습니다. 두 연구 모두 한국전자거래학회에 게재되어 있습니다.
사례1) 텍스트 마이닝 기반 고령자 관련 법제도 개선을 위한 분쟁 유형 도출방법론 제안 (김세형, 윤태영, 강주영)
저는 텍스트 마이닝을 사용하여 고령자 관련 법제도 개선을 위해 토픽 모델링 기법을 활용하였습니다. 로톡, 법률신문 등 고령자 관련 문서를 수집하고 여기서 공통되는 토픽을 도출하였습니다.
자, 아래의 그림은 최적의 토픽을 계산하기 위해 Perplexity와 Coherence를 도출한 것입니다. 낮은 Perplexity와 높은 Cohrence를 추출하기 위해 29개로 설정하였습니다!
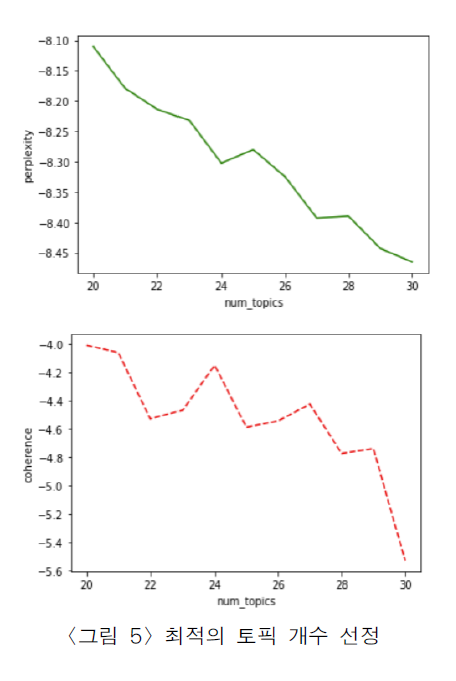
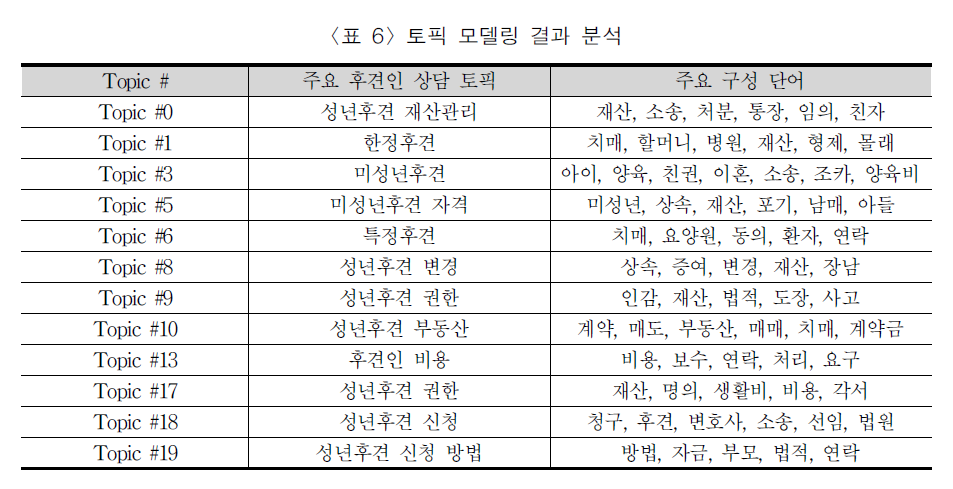
이제 아래는 도출된 토픽입니다. 제가 토픽 모델을 도출하고 토픽의 판별은 법률 전문가에게 요청하였습니다. 분석에 의미 없는 토픽들은 제거해 주셨습니다.
사례2) BERTopic과 소셜 네트워크 분석 기반 고령화 단계별 판례분석을 통한 분쟁 유형 도출에 관한 연구 (김세형, 윤태영, 강주영)
이 연구는 비교적 최근에 게재된 연구입니다. 올해 초에 게재되었습니다. 여기서는 판례 데이터를 이용하였고 판례의 판시사항에 대해 BERTopic을 활용하여 토픽 모델링을 진행하였습니다.
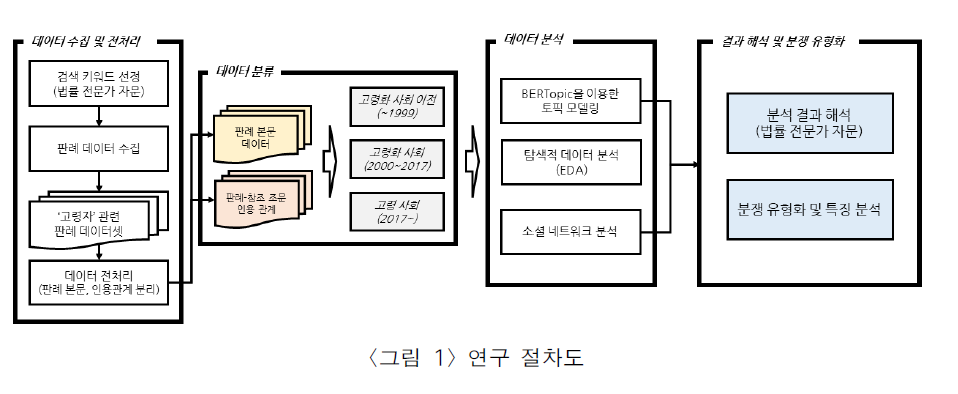
자, 아래의 그림은 BERTopic을 활용하여 토픽 모델링을 진행할 때 UMAP을 통해 2차원으로 축소하고 HDBSCAN으로 클러스터링을 진행한 결과입니다. 이제 각 클러스터는 하나의 주제를 도출하게 되는 것입니다.

🧑💻참고문헌
- 파이썬 텍스트 마이닝 완벽 가이드
Blei, D. M., Ng, A. Y., & Jordan, M. I. (2003).- Latent dirichlet allocation. Journal of machine Learning research, 3(Jan), 993-1022.
- 김세형, 윤태영, & 강주영. (2022). 텍스트 마이닝 기반 고령자 관련 법제도 개선을 위한 분쟁 유형 도출방법론 제안. 한국전자거래학회지, 27(3), 45-65.
- 김세형, 윤태영, & 강주영. (2023). BERTopic 과 소셜 네트워크 분석 기반 고령화 단계별 판례분석을 통한 분쟁 유형 도출에 관한 연구. 한국전자거래학회지, 28(1), 123-144.

이렇게 유용한 정보를 공유해주셔서 감사합니다.