안녕하세요. DevOps Engineer 백수현입니다. 여름이지만 추운 IT 겨울 준비 잘하고 계신가요?
저희 조직은 최근 효과적인 겨울나기를 위해 FinOps를 도입했습니다.
들어가며
모두들 어디까지 비용을 줄여 보셨나요? 비용을 줄이는 게 과연 항상 좋은 것일까요?
저는 이 두 가지 질문에 항상 고민했습니다. 그리고 항상 모두에게 도움이 되는 방향과 해결책을 찾으려 했어요.

원래 저는 비용에 관심이 많았어요. 비용을 줄이면 실적이 오르니 성과 반영이 아주 쉬워요. 개발적으로 성장하는 것도 정말 중요하지만 회사 생활은 전략이니 저는 항상 새로운 곳에 가면, 그곳에 비용 관리를 어떻게 하는지 먼저 살펴봐요. 아직까지는 성숙하게 Cloud를 사용하는 기업은 국내에 그렇게 많지 않아요. 그래서 어느 정도 관심만 가지고 보면 어떻게 비용을 줄일 수 있는지 포인트가 보여요. 정말 쉬운 방법 몇 가지 공유를 드리면
내 계정의 현황을 살펴보자.
먼저 저는 CostExplorer를 통해서 가장 비용이 많이 나오는 서비스들을 살펴봐요. 당연 대부분 EC2, RDS가 일반적이겠죠? 그럼 그다음에는? 네 대부분 S3, CW, DynamDB 등등 다양해요.
EC2를 살펴봐요.
제가 비용을 볼 때는 비용을 절감을 목표로 하는 것이 아니라 어떻게 하면 비용을 효율적으로 사용할까? 고민해요. 아시다시피 Spot instance는 상황에 따라 약 90%의 할인율을 가지고 있어요. 그렇지만 Spot을 상용에 사용한다면 언제 죽을지 모르는 서버가 되겠죠? 또 Test 환경이라고 하더라도 AWS에 Spot이 잘 나오지 않는 Type을 사용한다면 다른 사람들 다 퇴근하고 나서 새벽에나 사용할 수 있겠죠? 이럴 땐 인력 비용이 더 들어가요. 개발자의 몸값이 비싼 요즘 서버 비용 아끼려다 개발자를 낭비하죠. 그래서 저는 그럴 땐 On-demand를 사용하도록 권장해요. 그렇다고 서버 비용을 다 내냐고요? 아뇨 Job을 이용해 퇴근시간에 정지시키죠. 그리고 개발자는 출근하면 켜면 돼요. 이것도 자동화할 수 있고요.
S3를 살펴봐요.
S3를 살펴볼 때는 가장 사이즈가 큰 버킷을 먼저 살펴요. 과연 이게 다 저장되어야 하나? Lifecycle을 걸어 주기적으로 삭제할 필요는 없을까? 아니면 Class를 변경해 비용을 줄일 수는 없을까? 이런 것들을 먼저 살펴봐요.
Cloud Watch를 살펴봐요.
주로 많은 데이터들이 저장되어 있는데, 혹시 안 보는 데이터가 더 많지 않나요? 아니면 오래된 데이터가 몇 년이고 무제한으로 쌓이고 있지는 않은가요? 아니면 다른 곳에도 저장되는 데이터가 중복으로 쌓이고 있지는 않나요?
DynamoDB를 살펴봐요.
DynamoDB도 RI가 있다는 걸 모르시는 분들이 많아요. 그리고 Test 양과 횟수가 적다면 On-demand로 설정해 읽기 쓰기 횟수에 따라 비용을 지불하는 것을 권장 드려요. 그리고 박스 형태로 사용량이 유지된다면 그 외에도 사용량 패턴이 많은데 일정하다면 프로비저닝으로 RI까지 적용하면 정말 많은 비용을 절감할 수 있어요.
FinOps
아마 앞서 소개한 작업만 잘 해도 많은 분들이 벌써 올 하반기 성과를 올리셨을 거예요. 그럼 이제 본격적으로 FinOps에 대해 살펴볼게요.
FinOps는 재무와 운영을 통합한 단어에요. 비용을 지불하는 부서와 Cloud를 운영하는 부서 사이에 기술적인 간극을 좁히고 원하는 지표들을 제공해 주면서, 실제 비용을 어떻게 효과적으로 관리하느냐가 가장 중요한 포인트라고 생각했어요. 기술적인 전문지식이 부족한 재무팀에게 비용 구조를 설명하기란 정말 어려운 부분이지만, 이 부분은 상호 이해도를 맞추는 작업은 필요해요. 그런 작업에 보조 지표들을 제공함으로써, 간극을 좁히는 것을 목표로 FinOps를 도입했어요. 그럼 제가 단계적으로 FinOps를 어떻게 도입했는지 말씀드릴게요.
1. 용어 정리
먼저 들어가기 전에 Reserved Instances, Savings Plans, Normalization Factor, CUR 용어 정리 먼저 할게요.
RI(Reserved Instances), SP(Savings Plans)
instance를 약정으로 구매하는 요금제 유형이에요. 간략하게 말해서 1년 or 3년으로 시간당 서버를 일정 수량 이용하겠다. 약정을 하고 일시불 또는 할부 형태로 구매를 해요.
(단, 시간당 서버 수량을 모두 사용하지 않더라도 비용이 나가요. 그리고 시간당 사용량은 이월이 안돼요. 꼭 그 시간에 정해진 수량만큼 사용해야 해요. 이점은 주의해 주세요.)
SP에는 크게 SPC(SP Compute) SPE(SP EC2instance) 두 가지가 있어요
SPC(SP Compute)의 경우 모든 instance Type, OS, 리전에 상관없이 유연하게 적용이 돼요. 다만 할인율이 SP instance 보다 대체적으로 10~13%(1년 약정 기준) 정도 적어요.
SPE(SP EC2instance)의 경우 instance의 리전에 종속되고 공유도 같은 Family Type 안에서만 가능해요. 장점은 할인율이 SPC보다 상대적으로 10~13%(1년 약정 기준) 높아요.
RI는 RDS의 경우 리전, Family, Engine에 종속돼요. ES와 Cache는 instance Type에 한정되어 있어 조금 더 제약이 많고 Cache는 Engine에도 종속돼요
저는 관리 편의를 위해서 SP는 EC2 만 구매하고, RI는 RDS, ES, Cache를 구매했어요. SP가 유연하고 좋은 점이 많지만 RDS, ES, Cache에는 적용이 안돼요.
NF(Normalization Factor)
NF(Normalization Factor)는 instance type을 small을 1로 잡고 모든 type에 대해서 정량적인 숫자로 표현하는 값이에요. 예를 들면 t3.small의 경우 1, medium의 경우 2, large의 경우 4 이렇게 각 size 별로 수치화 한 값이라고 생각하면 돼요. NF는 RI/SP 구매 전 과거 지표를 참고할 때 아주 중요해요. 사용 중인 instance를 모두 NF로 계산하고 이를 시간당 사용량으로 표현하면 최적의 RI/SP를 찾을 수 있는 지표가 돼요.
CUR
AWS에서 제공해 주는 시간 단위의 비용 row 데이터에요. 시간 단위로 되어 있고 저는 FinOps 도입을 CUR 데이터를 기반으로 작업했어요.
2. RI/SP를 효과적으로 관리하기
Infra를 변경하지 않고 가장 쉽게 비용을 절감할 수 있는 RI/SP를 어떻게 전략적으로 구매했는지 알아볼게요.
RI/SP 1년, 3년 약정 너무 긴데 구매하기 너무 무서워요!
가장 많이 고민하는 게 RI/SP를 어떻게 얼마나 구매할까요? 갑자기 인프라가 늘면 추가 구매해야 하나요? 줄어들어서 다 못쓰면 어떡하죠? 돈을 쓰기 전에 항상 망설여지죠. 비용을 담당하는 분들이라면 이게 바로 실적과 연결되니 두려워요. 저는 리스크를 최소화하며 약정을 쪼개는 방법으로 일부 해결했어요.
저는 3년은 IT업계에선 강산도 변하는 기간이라고 생각해요. 그래서 되도록 3년 약정은 하지 않아요. RI/SP는 1년 약정 기준으로만 앞으로 말씀드릴게요.
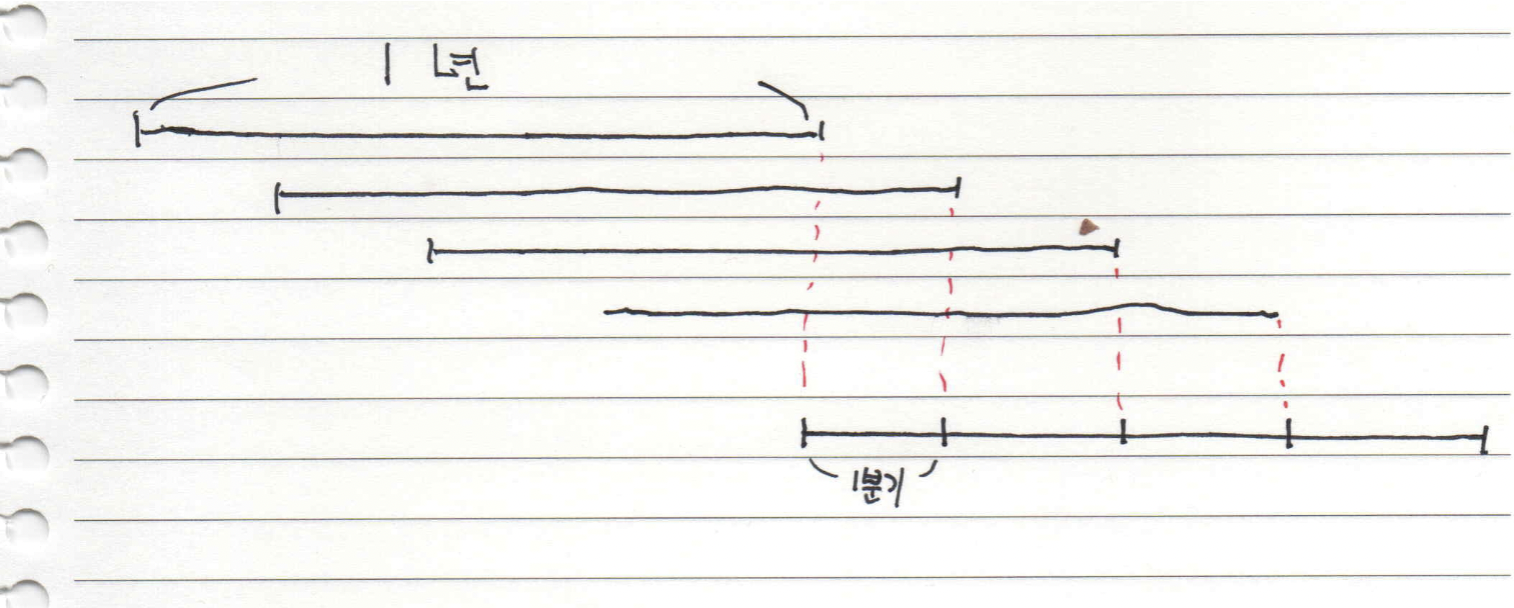
저는 우선 분기별로 구매를 했어요. 예를 들면 1, 4, 7, 10월에만 RI를 구매하는 거죠. 사용량이 줄었다면 다음 분기 수량을 줄이고, 사용량이 늘었다면 다음 분기 수량을 늘렸어요. 이런 식으로 구매를 하면 가장 큰 장점이 마치 RI/SP 구매 주기가 3개월인 것처럼 사용이 가능해요. 그리고 만약 신규 Type Instance가 나왔다면 분기별로 나눠서 전환을 한다면 1년 주기보다는 대응을 빠르게 할 수 있어요.
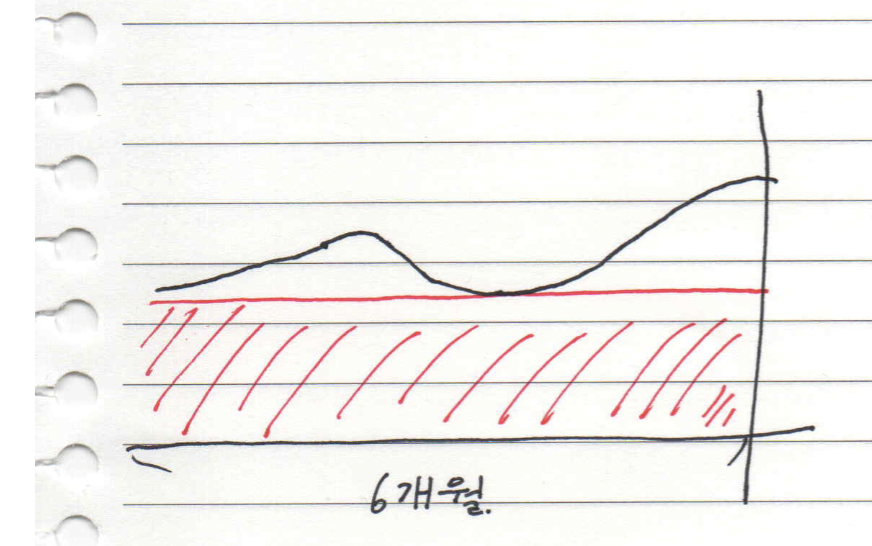
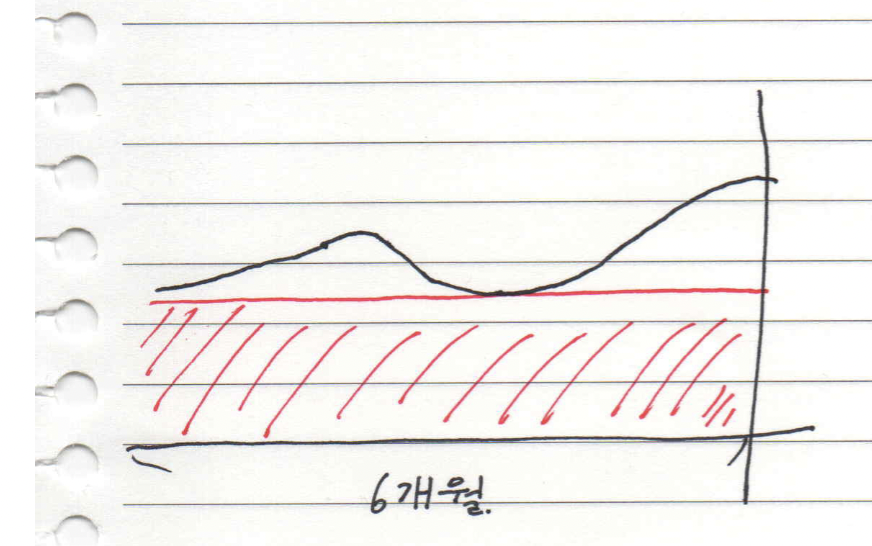
이미 지난번에 1년 또는 3년으로 최대치 구매를 한 경우도 있을 거예요. 이런 경우 사업이 성장하고 있다면 최대한 분기별로 추가 구매를 하세요. 그리고 사업이 작아지는 경우라면 안타깝게도, 사실 다음 연도에 수량을 줄이는 방법 밖에는 저는 떠오르지는 않아요. 만약 RI라면 마켓에 RI를 판매하는 방법도 있는 것으로 알고 있어요. 다만 과정이 복잡하지만, 큰 손해를 입는 것보다는 판매하는 게 더 좋은 방법인 것 같긴 해요.
그럼 얼마나 구매해야 할까요?
전략을 세웠으니 그럼 얼마나 구매해야 하는지 확인해 보죠. 저는 이 문제를 풀기 위해 CUR 데이터를 이용했어요. CUR에는 시간 단위 많으면 수 억 row로 비용에 관한 데이터가 S3에 모두 저장돼요. 이 데이터를 Athena를 이용해 Query가 가능해요.
여기서 ProductCode를 AmazonElastiCache, AmazonES, AmazonEC2, AmazonRDS로 한정 짓고 NF를 이용해 사용량을 모두 small 기준 정량적인 숫자 값으로 나눴어요. 그런 다음 결과를 QuickSight를 통해 시간 단위로 그래프에 표현했어요. 그런 다음 최근 6개월의 min 값을 기준으로 구매를 했어요. trade off 지점을 찾을 수 있는 지표가 나와준다면 너무 고맙지만 그렇지 않은 경우라면 6개월에 min 값이라면 충분히 부담 없이 구매할 수 있을 것이라고 생각했어요. 또한 이런 조건들을 기준으로 Query를 통해 Target Report도 만들 수 있어요.
다만 ES, Cache의 경우 크게 수량이 변하지 않는다면 전사에 1년 변경 계획을 수집하고 그 수량에 70%를 구매했어요. 30%는 유격으로 두는 것이 안전하다고 판단했어요. 다만 최신 Family Type의 경우 최대치로 구매 했어요.
3. FinOps를 위한 Tag
비용을 추적하기 위해서는 Governance가 반드시 필요해요. Governance는 서비스에 규모에 유동적이고 조직의 성장에도 유동적으로 대응이 가능해야 해요. 말이 쉽지 정말 복잡하고 운영 비용이 많이 들어가요.
Tag 그 시작
Governance를 하기 위해서는 정말 많은 작업이 필요해요. 여기서는 모든 부분을 다루지는 않고 FinOps 관점에서 필요한 부분만 뽑아서 설명할게요. 우선 Governance의 시작은 Tag라고 생각해요. Tag에 대해서는 제가 지난번에 정리한 글이 있어요. 여기를 한번 읽어 보시면 좋을 것 같아요. 여기에 정말 상세하게 설명했지만 포인트만 정리해 볼게요.
Tag는 resource에 대한 meta 정보를 담는 용도로 주로 사용해요. FinOps에서는 Team, Service, ServiceGroup 등 비용을 묶는 용도로 주로 사용하고 있는데요. 중요한 포인트는 모든 meta 정보를 Tag로 관리하게 되면 Tag를 관리하는 인프라가 잘 구성되지 않은 경우 최신 화가 어려워요. 링크에서는 모든 프로세스를 자동화해 관리가 가능하지만 사실상 개발이 복잡하고 운영이 귀찮은 부분이 많아요.
그래서 저는 별도의 metadata로 관리를 하는 것으로 해결도 권장하는데요. 주로 Service, ServiceGroup 같은 경우는 변경되는 경우가 매우 적어요. 이런 값들은 대부분 Unique 값으로 사용되기 때문에 key로 사용할 수 있는데요. 그래서 Service와 ServiceGroup만 Tag로 할당하고 나머지 Team, Owner 등 변동이 있을 수 있는 값은 별도의 Metadata로 관리하고, Athena를 통해 join 형태로 Team 별 비용을 관리하고 있어요.
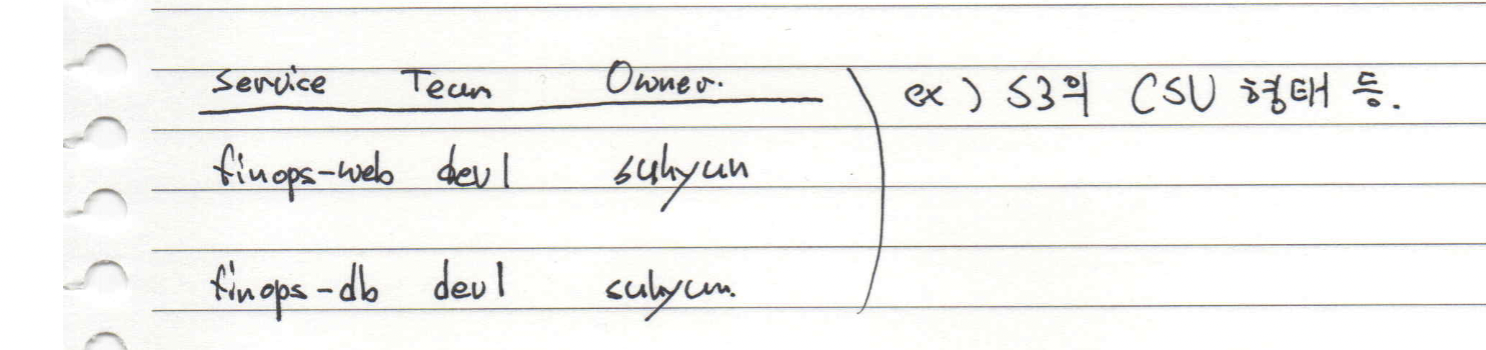
이런 형태라면 Tag에 변경을 최소화해서 관리 포인트를 크게 낮출 수 있어요. 수만 개의 서비스를 관리하는 조직이 아니라면 수백 개 정도는 충분히 관리가 되죠. resource로 관리한다면 수만 많으면 수십만 개가 될 테니까요.
Tag 누락 관리
Tag 누락을 어떻게 관리하면 좋을까요? 저는 이 부분도 CUR 데이터를 이용해요. CUR 데이터에는 Tag 정보도 담고 있어요. 그래서 Athena를 통해 Query를 진행할 때 특정 값이 null인 리스트를 출력해 별도로 관리할 수 있어요. 모든 리소스가 아니라 비용이 발생하는 리소스만 나온다는 점 참고해 주시면 될 것 같아요.
4. 대시보드 구성
대시보드를 보는 사용자에 따라서 실제 데이터 추출 방법이 조금씩 달라져요. 누가 보느냐에 따라 어떻게 데이터를 추출했는지 확인해 봐요.
Team 별 사용량 관리
자 이제 모든 사전 준비가 끝났고 Athena와 QuickSight를 이용해서 CUR 데이터를 분석해 Team 별 사용량을 관리하는 방법을 말씀드릴께요. CUR 데이터에는 여러 유형의 cost를 제공해 주고 있어요
unblendedcost : 실제 발생 비용
publicOnDemandCost : RI/SP가 적용되지 않았을 경우 발생하는 On-demand 비용
savingsplan_savingsplaneffectivecost : SP가 적용된 경우 할인이 적용된 비용
effectivecost : RI가 적용된 경우 할인이 적용된 비용
여기서 우리가 구매한 RI/SP는 수많은 instance에 적용이 되고 때에 따라서 지금은 적용되었지만 1시간 후에는 적용이 되지 않을 수 있어요. 이런 경우에 팀별 비용을 unblendedcost로만 산정한다면, RI/SP 적용 여부에 따라 각 팀의 instance의 사용량이 동일한 수량을 사용하더라도 팀마다 다르고 매일 달라질 수 있어요. 이런 데이터라면 사용량 증감 추이를 확인하기 많이 어려워요.
그래서 저는 Team이 확인하는 대시보드에는 publicOnDemandCost를 통해 모니터링하도록 대시보드를 구성했어요. 그러면 실제 사용한 infra 비용을 정량적으로 파악할 수 있어요.
법인별 RI/SP 사용량 관리
많은 기업에서 AWS OU 계정에 수많은 Account를 연결해서 사용하고 있어요. 그러다 법인이 분리되는 경우도 발생하게 되는데요. 그럼 이미 구매한 RI/SP는 어떻게 처리할까? 이런 고민하시는 분들이 있으세요.
이런 경우 RI/SP에 대해 서로 다른 법인이 사용하게 되기 때문에 문제가 발생할 수 있어요. 그럴 경우 우선 RI/SP를 구매하는 계정을 하나로 모으는 게 좋아요. 별도 계정을 생성해 하나의 계정에서 관리를 하면 RI/SP는 하나의 법인에서만 지불하게 돼요. 그런 다음 RI/SP를 구매한 계정에서 다른 법인으로 비용을 청구하는 방법으로 해결할 수 있어요.
그럼 어떤 기준으로 비용 청구 금액을 산정할까요? 그 해답은 아주 쉬워요. (savingsplan_savingsplaneffectivecost or effectivecost)-unblendedcost으로 비용을 뽑으면 타 법인에 청구할 비용이 나와요. 이를 통해서 각 법인 계정에서 사용한 금액을 합해서 그 법인에게 청구하면 됩니다.
RI/SP Utilization, Coverage, Unused 관리
그럼 왜 OU를 나누지 않고 대시보드를 구성하고 비용을 뽑아 다른 법인에 청구하는 방법을 저는 선택했을까요? 답은 규모에 있어요. AWS를 사용하는 규모가 클수록 구매한 RI/SP를 다른 계정에서 사용할 확률이 높아지고 미사용 발생률이 작아지게 되요.
그럼 RI/SP를 중앙에서 관리하기 위해서는 Utilization, Coverage, Unused 관리 대시보드가 필수 적이에요. Utilization은 실제 구매한 RI/SP를 얼마나 사용했는지에 대한 지표에요. Utilization 지표를 산출하기 위해서는 구매한 RI/SP 수량을 정량적으로 볼 수 있는 테이블이 필요해요.


먼저 RI를 살펴볼게요. 우선 RI List를 얻기 위해 CUR 데이터에서 lineitemtype 필드의 RIFee 값으로 조회하는 View 테이블을 생성했어요. 두 번째로 Athena는 시간 단위 데이터를 생성하는 내장함수가 없어 시간 매시간 값을 얻기 위해 CUR을 이용했어요. CUR은 매시간 연속적으로 비용이 발생하기 때문에 모든 시간 값을 가지고 있어요. 그렇게 두 결과를 join을 통해 전체 RI에 대해 매시간당 NF 값을 뽑았어요.
이 작업을 한 이유는 지난 분기 1년으로 구매한 c5.large 10대와 이번 분기 구매한 c5.xlarge 10대가 있다면 우리가 지금 사용해야 하는 c5의 총 NF 값은 (4(large) 10 ) + (8(xlarge) 10 ) = 120 이 나와요. 이 수량들을 실제 사용한 instance 시간 단위 NF 합계와 비교했을 때 사용 수량이 더 크다면 100% 사용하는 것이겠죠? 그리고 여기서 비율을 보면 Coverage가 나오고 더 적다면 Unused가 발생해요.
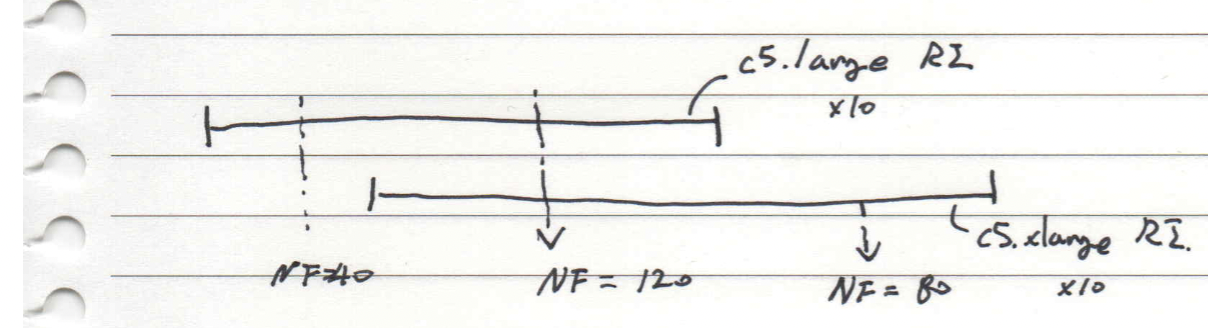
그럼 SP는 어떻게 진행했을까요? SP는 우선 Unused는 savingsplan_totalcommitmenttodate - savingsplan_usedcommitment를 통해 확인했어요. Utilization, Coverage은 productcategory가 'Savings Plan Covered Usage' 이면서 savingsplan_offeringtype 가 ComputeSavingsPlans인 경우 'SPC' 그리고 productcategory 가 Savings Plan Covered Usage면서 savingsplan_offeringtype 가 EC2InstanceSavingsPlans인 경우 'SPE'로 간주했어요. 그런 후 나머지를 On-demand로 보고 지표를 만들었어요. 이렇게 지표를 구성하면 모든 주요 지표들은 완성할 수 있어요.
5. 그 외의 작업들
--
글로 담지 못하는 정말 많은 내용들이 있어요. 일일 비용을 Athena로 쿼리 해 전일 대비 크게 상승한 서비스에 대해 알림을 보내는 작업. Unsued RI/SP 수량이 발생하면 알림을 보내는 작업. 그리고 전체 AWS 비용을 확인하고 다음 달 예산 산정 지표를 구성하는 작업. 트래픽 증가에 따른 비용 변화 추이를 모니터링하는 작업. CloudWatch or Prometheus 데이터를 가지고 와서 Right Sizing을 추천해 주는 방법. 등등 앞으로도 할 일이 많고 할 수 있는 일들은 정말 많아요.
마치며
많은 기업들이 아직은 비용에 관심 있다고 이야기는 하지만 실제 어떻게 해야 할지 몰라 하고 있어요. 이런 분들에게 조금이나마 도움이 되었으면 하는 마음에 글을 작성했어요. 많은 분들에게 조금이나마 도움이 됐으면 합니다. 긴 글 읽어주셔서 감사합니다. 문의사항이나 수정이 필요한 내용이 있다면 dev.sean.2016@gmail.com으로 문의 주세요.


잘 읽었습니다.