
이번 블로깅에서는 알고리즘에서 자주 나오는 탐색방법인 DFS(깊이우선탐색)과 BFS(너비우선탐색)에 대해 JS 기준으로 한번 쉽게 배워보려 한다.
탐색 알고리즘란?
DFS와 BFS는 탐색 알고리즘 중에 하나이다.
그렇다면 탐색 알고리즘이란 무엇인가?
그래프의 모든 정점들을 특정한 순서에 따라 방문하는 알고리즘이다.
당황스러울 수 있다. 그래프는 뭐고 정점은 뭐야,,??
그래프란?
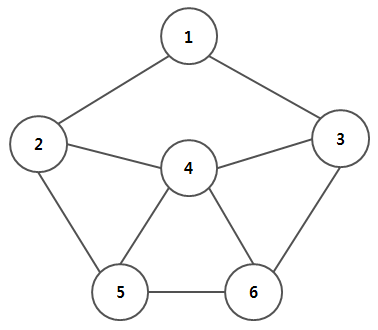
그래프란, 자료구조 중 하나인데 예시를 한번 봐보자.
한 나라에는 도시들이 여러개 존재하고 이들은 도로들이 연결지어주고 있다. 이때 이렇게 도시들과 그에 연결된 도로를 합쳐셔 자료구조로 만든 것이 그래프이다.
이때 정점은 도시들이 되고, 간선은 도로들이 된다.
이제 제대로된 정의를 보자.
그래프는 정점과 간선으로 구성된, 한정된 자료구조를 의미한다.
이때 각각의 지점을 정점이라고 하며, 정점과 정점을 연결지어주는 것을 간선이라고 부른다.
이제 그래프에 대해 이해가 갔을 것이다.
위에 그래프 자료구조를 탐색하는 방법이 DFS, BFS인 것이다.
우리가 왜 DFS,BFS를 공부해야 하는가?
오케이... 탐색알고리즘은 그래프를 탐색하는것이고만.. 근데 그냥 탐색하면 되는거 아니야? 뭐가 더 필요해...?? 그렇다면 아래와 같은 질문을 던지고 싶다.
- 한 정점에서 다른 정점으로 연결된 건 어떻게 알껀데?
- 위의 알고리즘이 없다면, 직접 효율적인 코드를 짜야할텐데 가능해? 그리고 정확도는 장담해?
그렇다... 그래프를 탐색하기 위해선 어느정도의 효율성과 체계성이 필요하다. 이 말은 아래에서 DFS와 BFS를 공부하다보면 무슨 말인지 이해가 갈 것이다.
DFS(깊이 우선 탐색) 이란?
DFS 개념 원리
DFS는 어떻게 탐색하는 방법이야?
시작점에서 갈 수 있는 정점부터 깊이 있게 파고 드는 알고리즘
현재 정점과 연결된 정점들을 하나씩 갈 수 있는지 검사하고, 특정 정점으로 갈 수 있다면 그 정점에 가서 같은 행위를 반복한다. 이때, 방문한 지점은 다시 방문하지 않기 위해 표시를 해둔다.
일단 개념에 대해서 써보았는데 이해가 절~대 안 갈 것이다. 아래 그림을 봐보자.
번호는 순서를 말하며 그 순서에 대해 잘 보자.
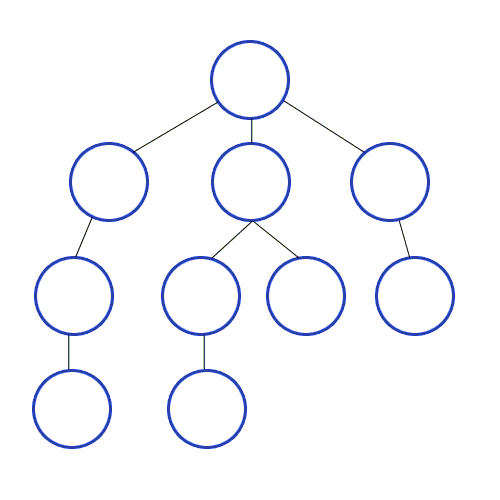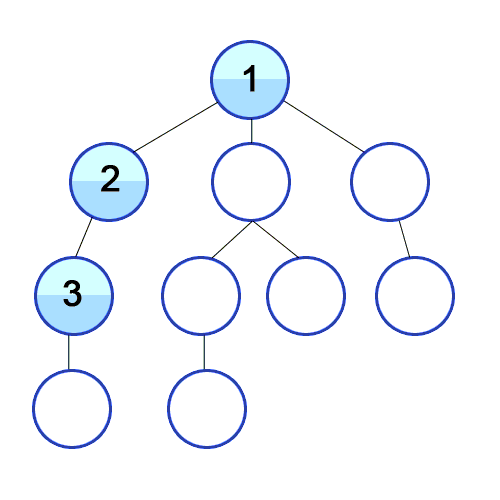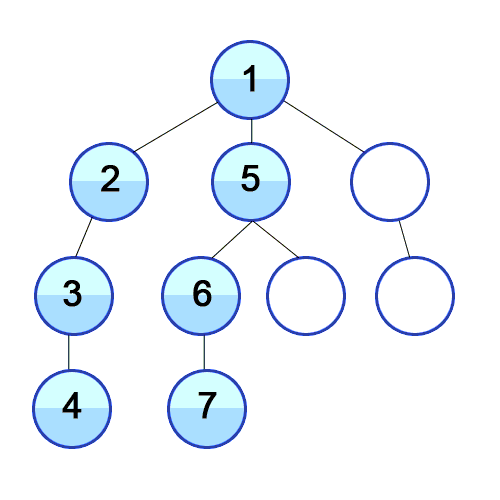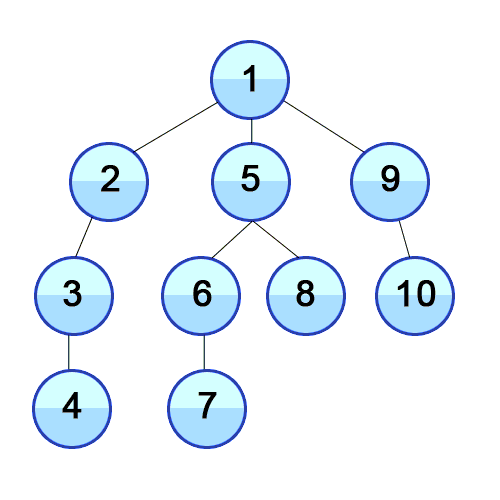
출처 https://developer-mac.tistory.com/64
기존 DFS의 원리
현재 정점과 연결돤 정점들을 하나씩 갈 수 있는지 검사하고, 특정 정점으로 갈 수 있다면 그 정점에 가서 같은 행위를 반복한다.(재귀함수 이용) 이때 방문한 곳을 다시 방문하지 않기 위해, 방문한 곳은 표시를 해둔다.
위의 그림을 보면서 아래 설명을 봐보자.
1. 시작 정점을 1로 설정
2. 1번 탐색 시작 1번과 연결되었고 방문 안한 정점이 어디지? 2번이 있네. 2번으로 가자.
3. 2번과 연결되었고, 방문 안한것? 3번이네. 3번으로 가자.
4. 3번은? 4번이 있네. 4번으로 가자.
5. 4번은? 없는데..?? 그러면 3번으로 다시 올라가자.
6. 3번은? 방문 안한곳이 없네.. 다시 2번... 다시 1번
7. 1번은? 5번이 있네. 5번으로 가자.
-> 이런 식으로 방문 안한 곳이 없을때까지 반복
이런식으로 쭉 탐색하게 된다. 이런 식으로 하다보면 한 길로 깊이 있게 파고들어가게 된다. 이래서 깊이 우선 탐색이라는 말이 나온 것이다.
DFS의 장단점
1) 장점
- 코드가 직관적이고, 구현하기 쉽다.
-> 사실 일정행동을 계속 반복하는데, 이를 만들어놓고 끝까지 계속 돌려 쓰는 것이기 때문에 비교적 간단하게 코드를 구현할 수 있다.
2) 단점
- 깊이가 엄청 깊어지면, 메모리 비용을 예측하기 어렵다.
-> 앞서 설명한 것처럼 깊이가 깊어질수록 함수가 하나씩 쌓이는 구조이다. 이 때문에 깊이가 엄청 깊어진다면 스택 메모리가 지나치게 커질 수 있다.- 최단 경로를 알 수 없다.
DFS 적용 코드 - JavaScript
JavaScript에선 이를 어떻게 구현할 수 있을까?
JS는 위와 조금 다르고 쉽게 구현이 가능하다.
JavaScript에서 DFS의 원리
- 큐에 시작 정점을 넣는다.
- 큐에서 가장 오래있던 것을 뽑아낸다.(shift) 그와 관련된 것을 큐에 넣는다. 이때 뒤에 넣는게 아니라 앞에 넣는다.
- 큐의 앞에 있는 정점을 뽑아내면서 또 위와 같은 과정으로 반복한다.
- 큐가 빌때까지 계속 반복한다.
- 처음엔 1번으로 시작, 1번에서 갈 수 있는 곳이 어디지? 2,5,9번이 있네! 이걸 큐에 넣어놓자.
큐: 2 5 9- 큐에 가장 먼저 있는게 뭐지?? 2번이네 2번 뽑아내고 연결된 정점이 뭐지? 3번이네 3번을 큐에 넣자.
큐: 3 5 9- 또 큐에 뭐가 먼저 있지? 3번이네 3번과 연결된 정점은 뭐지? 4번이네. 이를 큐에 넣자
큐: 4 5 9- 이 과정을 큐가 비어질 때까지 반복
이런식으로 스택을 활용하여 재귀함수를 쓰지않고 구현이 가능하다.
이를 어떻게 구현할지 아래 코드를 봐보자.
그래프 생성
아래 DFS를 쓰게 위해선 각 정점이 간선들로 어떻게 연결되어있는지 그래프 형태의 자료구조를 먼저 만들어줘야한다. 아래처럼 각 정점들이 어떤 정점들과 연결되어있는지 나타내면 된다.
const graph = {
A: ['B', 'C'],
B: ['A', 'D'],
C: ['A', 'G', 'H', 'I'],
D: ['B', 'E', 'F'],
E: ['D'],
F: ['D'],
G: ['C'],
H: ['C'],
I: ['C', 'J'],
J: ['I']
};DFS 구현 함수
// graph 자료구조와 startNode를 입력
const DFS = (graph, startNode) => {
const visited = []; // 탐색을 마친 노드들
let needVisit = []; // 탐색해야할 노드들
needVisit.push(startNode); // 노드 탐색 시작
while (needVisit.length !== 0) { // 탐색해야할 노드가 남아있다면
const node = needVisit.shift(); // queue이기 때문에 선입선출, shift()를 사용한다.
if (!visited.includes(node)) { // 해당 노드가 탐색된 적 없다면
visited.push(node);
needVisit = [...graph[node], ...needVisit];
}
}
return visited;
};BFS(너비 우선 탐색) 이란?
BFS 개념 원리
BFS는 어떻게 탐색하는 방법이야?
시작점에서 가까운 정점부터 순서대로 방문하는 탐색 알고리즘
출발점을 먼저 큐에 넣고, 큐가 빌 때까지 아래 과정을 반복한다.
1. 큐에 저장된 정점을 하나 Dequeue한다.
2. 그리고 뺀 정점과 연결된 모든 정점을 큐에 넣는다.
이또한 일단 개념에 대해서 써보았는데 이해가 절~대 안 갈 것이다. 아래 그림을 봐보자.
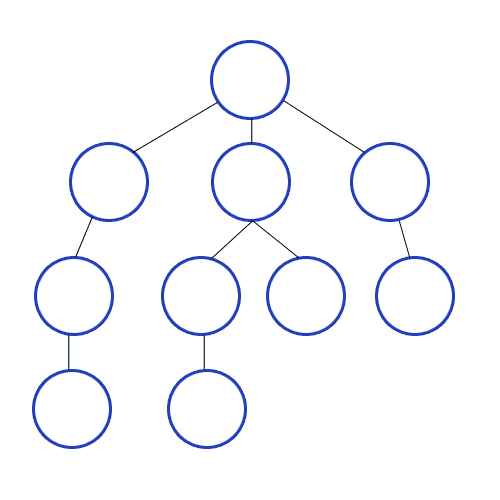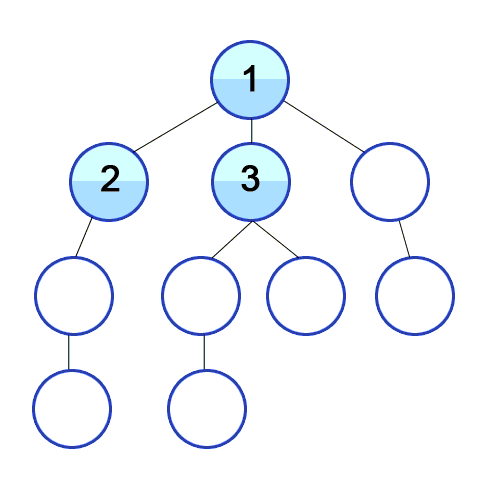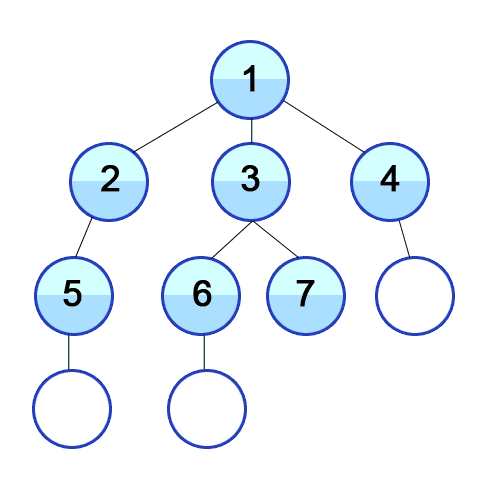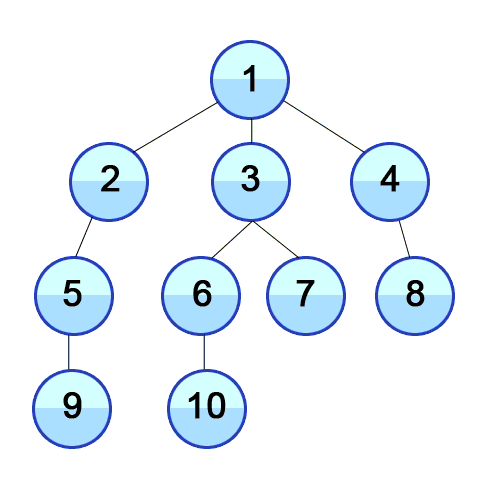
출처 https://developer-mac.tistory.com/64
기존 BFS의 원리
- 탐색을 시작하는 정점을 큐에 넣는다.
- 큐가 비어질 때까지 아래과정 반복
큐를 가장 앞에 있는 정점(큐에 가장 오래있던 정점)을 뽑아서 그와 연결된 정점을 모두 큐에 넣는다.
- 처음엔 1번으로 시작! 큐에 1을 넣자
큐: 1- 큐에 가장 앞에 있는걸 뽑자. 1번이네! 1번과 연결되어있는 정점은 뭐지? 2,3,4군. 이걸 큐에 넣자.
큐: 2 3 4- 이번에 가장 앞에 있는건 뭐지? 2번이네! 2번을 뽑고 그거랑 연결된 걸(5번) 큐에 넣자.
큐: 3 4 5- 이번엔 3번이 가장 앞에 있네. 이걸 뽑고 3번과 연결된 정점(6, 7번)을 큐에 넣자!
큐: 4 5 6 7
이런식으로 쭉 탐색하게 된다. 이런 식으로 하다보면 깊이 있게 본 DFS와 다르게 BFS는 단계별로 탐색하게 된다. 그래서 너비 우선 탐색이라는 말이 나온 것이다.
BFS의 장단점
1) 장점
- 비교적 효율적인 운영이 가능하고, 시간/공간 복잡도 면에서 안정적이다.
-> 깊이 우선 탐색 같은 경우에는 정답을 찾는데, 바로 구할 수 있는 것도 돌고 돌아서 찾아낼 수 있지만, BFS는 그래도 예상한 부분에서 나오게 된다.- 최단 경로를 구할 수 있다. (단, 간선의 비용이 같을 경우...)
-> 간선의 비용이 다른 경우가 있는데, 이 부분은 다른 알고리즘 블로깅에서 추가적으로 설명하겠다. 너무 깊은 부분이라..)
2) 단점
- 구현이 비교적 까다롭다.
- 모든 지점을 탐색한다는 가정하에 큐에 메모리가 어느정도 준비되어 있어야 한다. -> 정점이 100만개라면 큐 메모리가 100만개가 준비되어있어야 한다.
BFS 적용 코드 - JavaScript
JavaScript에선 이를 어떻게 구현할 수 있을까?
JavaScript에서 DFS의 원리
- 탐색 스택, 방문 배열을 생성
- 탐색을 시작하는 정점을 탐색스택에 쌓는다.
- 탐색스택이 없어질때까지 아래과정을 반복한다.
1) 스택 최상단에 있는 것을 없애고, 이를 탐색한다.
2) 탐색 시에 방문 했는지 체크, 했다면 패스
3) 방문 안했다면, 이를 방문 배열에 넣고 그 정점과 이어진 정점들을 배열에 다시 쌓는다.
이런식으로 스택을 활용하여 재귀함수를 쓰지않고 구현이 가능하다.
이를 어떻게 구현할지 아래 코드를 봐보자.
BFS 구현 함수
// graph 자료구조와 startNode를 입력
const BFS = (graph, startNode) => {
let visited = []; // 탐색을 마친 노드들
let needVisit = []; // 탐색해야할 노드들
needVisit.push(startNode); // 노드 탐색 시작
while (needVisit.length !== 0) { // 탐색해야할 노드가 남아있다면
const node = needVisit.shift(); // 가장 오래 남아있던 정점을 뽑아냄.
if (!visited.includes(node)) { // 해당 노드 방문이 처음이라면,
visited.push(node);
needVisit = [...needVisit, ...graph[node]];
}
}
return visited;
};정리
DFS, BFS 언제 써야해?
그렇다면 이렇게 생각할 수 있다. 두개 중 어느 상황에 뭐를 써야해?
-> BFS는 기본적인 메모리가 필요하지만, 가지고 있는 메모리를 효율적으로 관리할 수 있고, DFS는 전체적으로 적게 들지만 예상치 못한 값을 만나게 되면 메모리가 터질 수 있다.
이건 개인적인 생각인데, 예상치 못한 값이 나오지 않는 부분에서는 DFS를 사용하고, 예상치 못한 값이 나올 수도 있는 자료이며 메모리 공간이 그정도로 충분하다면 BFS를 쓰는 것이 안정적이라고 생각한다.
추가적으로 DFS는 깊이를 우선 탐색하기 때문에 길의 형태를 파악하기가 가능하다. 따라서 경로의 특징을 구할때 이를 사용하면 좋다.
또한 BFS는 너비를 우선 탐색하기 때문에 최단거리를 구하기가 가능하다. 따라서 최단거리 문제는 이를 사용하는 것이 좋다.
끄적끄적
이번 블로깅에선 코테나 알고리즘에서 자주 나오는 DFS, BFS에 대해 개념, 원리을 알아보았고, JS에서 이를 어떻게 구현하는지 알아보았다. 다음 블로깅에서는 관련 문제를 풀어보면서 이를 적용시켜보려 한다.
중요
DFS, BFS는 모두 문제마다 구현하는 코드가 매우 달라질 수 있다. 문제마다 원하는 것이 다르기 때문에 코드가 달라진다. 위에 예시 코드는 이해를 돕고자 쓴 코드이며, 개념적인 부분을 이해하고 여러 문제를 푸는 것이 이 알고리즘을 이해하는데 매우 도움이 될 것이다.

3개의 댓글


안녕하세요! 작성해주신 글 덕분에 DFS와 BFS의 개념을 잘 이해할 수 있었습니다. 좋은 글 공유해주셔서 감사합니다.
글을 읽으며 조금 헷갈렸던 부분이 있어 의견을 남깁니다.
DFS 관련 설명에서 큐 자료구조와 선입선출(FIFO)에 대한 내용이 나오는데, 실제로 작성하신 함수의 로직은 스택(후입선출, LIFO) 구조로 동작하는 것처럼 보입니다.
작성해주신 아래 내용에서
- 큐에 시작 정점을 넣는다.
- 큐에서 가장 오래있던 것을 뽑아낸다.(shift) 그와 관련된 것을 큐에 넣는다. 이때 뒤에 넣는 게 아니라 앞에 넣는다.
- 큐의 앞에 있는 정점을 뽑아내면서 또 위와 같은 과정으로 반복한다.
- 큐가 빌 때까지 계속 반복한다.
이 부분이 스택 구조와 혼동되신 것 같아요.
추가로 구현 함수의 주석에서
// queue이기 때문에 선입선출, shift()를 사용한다.라는 부분이 있는데, 실제 로직은 needVisit 배열을 [...graph[node], ...needVisit]로 갱신하면서, 새로운 노드를 앞쪽에 추가하고 있어 스택 형태로 작동합니다. 따라서 후입선출(LIFO)의 특징을 띠고 있다고 보는 게 맞는 것 같습니다.
혹시 제가 잘못 이해한 부분이 있다면 말씀 부탁드리고 이런 부분을 한 번 더 검토해 주시면 더 많은 분들에게 명확한 설명이 될 것 같아요. 감사합니다.
알고리즘 글들 잘 봤습니다. 도움되었습니다. 감사합니다.