파이썬과 scikit-learn을 이용해서 AUPRC 커브를 그려보기.
- 아래와 같이 그려보자. Sklearn 라이브러리를 활용해 그린다.
1. 라이브러리 호출하기
from sklearn.svm import SVC
from sklearn.metrics import precision_recall_curve, auc
from sklearn import metrics
import numpy as np
import pandas as pd
import sklearn
from sklearn import *
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier, GradientBoostingClassifier
from xgboost import XGBClassifier
from lightgbm import LGBMClassifier
from pytorch_tabnet.tab_model import TabNetClassifier
import matplotlib.pyplot as plt
from imblearn.over_sampling import SMOTE, BorderlineSMOTE, RandomOverSampler, ADASYN, SMOTEN
from sklearn.metrics import precision_recall_curve
from sklearn.metrics import average_precision_score
from itertools import cycle
from sklearn.metrics import PrecisionRecallDisplay2. 파일 읽기 및 간단한 전처리.
- csv 파일 불러오고 필요없는 feature 드랍하기.
- train test split하기
- for loop 돌리기 편하게 list안에 넣기
full_doc = pd.read_csv('./new_data/input_final.csv')
label = full_doc['Label']
full_doc.drop('PT Code', axis=1, inplace=True)
full_doc.drop('PT_term', axis=1, inplace=True)
full_doc.drop('Label', axis=1, inplace=True)
X_train, X_test, y_train, y_test = train_test_split(full_doc, label, test_size = 0.20, random_state=1)
clf_list = [XGBClassifier(n_estimators=5, learning_rate=0.1, max_depth=3), RandomForestClassifier(),
SVC(probability=True), TabNetClassifier()]
oversampling_list = [SMOTE(random_state=0), BorderlineSMOTE(sampling_strategy=1),
RandomOverSampler(sampling_strategy=1), ADASYN(sampling_strategy=1), SMOTEN(sampling_strategy=1)]
clf_name = ['XGB', 'RF', 'SVM', 'TabNet']
oversamp_name = ['SMOTE', 'B-SMOTE', 'Random', 'ADASYN', 'SMOTEN']
데이터 Fitting, 추론 및 그래프 그리기
-
본 코든느 oversampling 기법과 classifier들의 기법들을 한번에 plot하고 싶어 for loop안에 넣음.
-
n_class (제 데이터는 binary라서 2입니다) 만큼 precision recall, class별로 구한 후 list에 저장
-
PrecisionReCallDisplay 패키지를 사용해서 plotting 진행.
from sklearn.metrics import precision_recall_curve
from sklearn.metrics import average_precision_score
from itertools import cycle
n_classes = 2
for method in oversampling_list: # loop over oversampling methods
recall1 = []
precision1 = []
average_precision1=[]
X_train_samp, y_train_samp = method.fit_resample(X_train, y_train)
for idx, classifier in enumerate(clf_list):
if idx == 3:
classifier.fit(X_train_samp.values, y_train_samp.values)
y_score = classifier.predict_proba(X_test.values)[:,1]
else:
classifier.fit(X_train_samp, y_train_samp)
y_score = classifier.predict_proba(X_test)[:,1]
# print(y_score)
score.append(y_score)
precision = dict()
recall = dict()
average_precision = dict()
for i in range(n_classes):
precision[i], recall[i], _ = precision_recall_curve(y_test, y_score)
average_precision[i] = average_precision_score(y_test, y_score)
# A "micro-average": quantifying score on all classes jointly
precision["micro"], recall["micro"], _ = precision_recall_curve(
y_test.ravel(), y_score.ravel()
)
average_precision["micro"] = average_precision_score(y_test, y_score, average="micro")
recall1.append(recall["micro"])
precision1.append(precision["micro"])
average_precision1.append(average_precision["micro"])
# setup plot details
colors = cycle(["navy", "turquoise", "darkorange", "cornflowerblue", "teal"])
_, ax = plt.subplots(figsize=(7, 8))
for i, color in zip(range(len(clf_list)), colors):
display = PrecisionRecallDisplay(
recall=recall1[i],
precision=precision1[i],
average_precision=average_precision1[i],
)
display.plot(ax=ax, name=f"Precision-recall for method {clf_name[i]}", color=color)
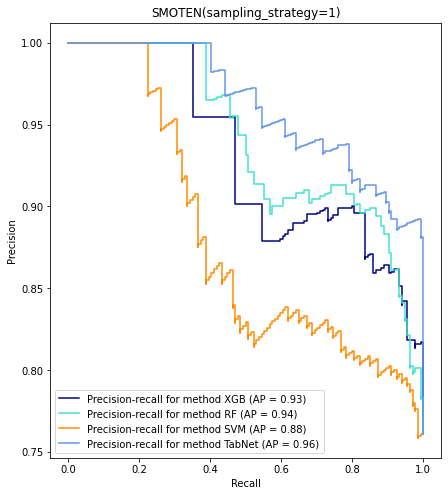
ax.set_title(method) 아래와 같이 plot이 나온다. X축은 Recall 이고 Y축은 Precision이며 제목도 따로 들어간다. 흑백이라서 안보이는듯...
References:

생명공학을 전공했지만 AI에 관심있는 사람